
- 1解决主机有网络但虚拟机没网络连接问题----记录
- 2Linux安装hadoop
- 3Python中selenium库的用法详解_python selenium
- 4Git 打patch (打补丁)的使用_git patch怎么用
- 5android基础知识12:android自动化测试03—基于junit的android测试框架02
- 6Matlab生成随机数的一些命令_matlab随机生成数 并输出
- 7《Python自然语言处理》第二章 习题解答 练习6
- 8借助PLC-Recorder,西门子PLC S7-200SMART实现2ms周期采集的方法(带时间戳采集)_200smart时间超过一天怎么比较
- 9无人机在水利行业的应用
- 10VRay Next (4.0) for SketchUp之AO通道的设置与输出_su渲染ao图参数设置
AI Infra论文阅读之通过打表得到训练大模型的最佳并行配置_efficient parallelization layouts for large-scale
赞
踩
0x0. 前言
这次阅读一篇mlsys的一篇新论文,《Efficient Parallelization Layouts
for Large-Scale Distributed Model Training》,虽然该论文还处于open review阶段,但作者在 Megatron-LM 基础上通过对各种训练调优方法进行组合打表获得了一些比较有趣的结论和发现,地址:https://openreview.net/pdf?id=Y0AHNkVDeu 。作者的详细实验表格在:https://github.com/Aleph-Alpha/NeurIPS-WANT-submission-efficient-parallelization-layouts
paper中基于大量搜索实验,最后得出来以下几个训练大模型的建议:
- 使用Micro Batch大小为1,以实现最小程度的模型并行化,避免Activation Checkpointing,并减少流水线bubble。
- 优先使用TP和PP,而不是Activation Checkpointing。
- 只有在无法进一步降低模型并行化程度时,才扩大Micro Batch大小。
- 对于参数超过30B且序列长度超过2k的模型,使用Sequence Parallelism。
然后在Paper的第4节还有几个有趣的发现,比如应该优先流水并行而不是模型并行,以及Flash Attention自带Activation Checkpointing,只对FFN进行Activation Checkpointing能获得更好的MFU。
这篇文章的解读力求精简,基本没有翻译任何原文,所以节奏非常快只写了核心要点,感兴趣也可以阅读原文,但干货应该都在这里了。
0x1. 摘要
摘要指出了现在训练大语言模型的一些高效的训练方法。包括:1) 需要跨多个硬件加速器进行并行处理和采用计算及内存优化;2) 之前的研究未涉及最新的优化技术,如Flash Attention v1/v2或Sequece Parallel;3) 作者进行了全面的训练配置打表研究,并提出了一些关键的建议以提高训练效率;4) 发现使用 micro-batch=1 能提高训练效率,但较大的micro-batch需要Activation Checkpointing或更高程度的模型并行大小,同时也会导致更大的pipeline bubble;5) 作者得到的最高效的配置在不同模型大小上实现了先进的训练效率,特别是在训练13B LLAMA模型时,达到了70.5%的MFU。
0x2. 介绍
这里对当前训练LLM的一些流行的技术做了简介,比如Zero,Activation Checkpointing,3D Parallel,Flash Attention,Sequence Parallel等等。然后paper的贡献就是把这些技术进行组合打表,最终得到了几个结论。
0x3. 背景
背景里面对Data Parallel,Tensor Parallel,Pipline Paralle,3D Parallel,Sequence Parallel,Activation Checkpointing,Fused Kernels,Flash Attention做了简要介绍,这些都是AI Infra的常见技术大家可以在 https://github.com/BBuf/how-to-optim-algorithm-in-cuda/tree/master/large-language-model-note 这里找到每一种技术的更多介绍资料。
这里需要关注的应该只有下面这张表:
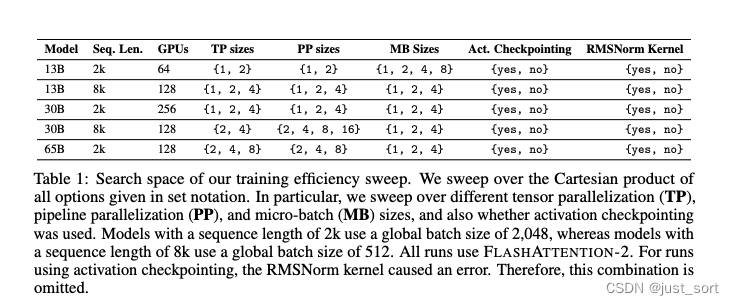
这个表格是paper的搜索空间,大家可以看一下。这里的RMSNorm Kernel指的是Flash Attention2里实现的kernel。
0x4. 实验设置
实验在32个NVIDIA DGX A100节点上进行,每个节点有8个NVIDIA A100 80GB GPU,总共256个GPU。每个节点内的GPU通过第三代NVLink互联,提供600GB/s的带宽。 跨节点通信由NVIDIA Mellanox 200Gb/s HDR Infiniband连接实现。选择的训练模型为LLAMA,训练设置遵循LLAMA2。然后按照上一节的Table1的配置进行扫描,每次扫描的时候运行10次,并只记录后9次的平均MFU。然后在遍历表格的时候DP和Acc由其他指定的参数自动计算,比如128张GPUs并且TP=4,PP=2时,DP被自动计算为128 / 4 / 2 = 16。实验的扫描配置见B.1表:
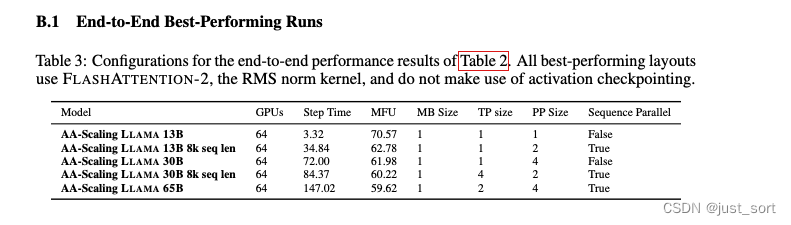 可以看到LLAMA 13B最高达到了70%的MFU。
可以看到LLAMA 13B最高达到了70%的MFU。
0x5. 高效的LLM训练分析
这篇paper的干货在这一节展示。
0x5.1 Fused Kernels 和 Flash Attention
paper里对Fasl Attention进行了更大规模模型的测试,此外还测试了一下Meagtron-LM自带的fused softmax attention kernel以及Faslh Attention v2里面的Fused RMSNorm kernel。
0x5.1.1 Attention
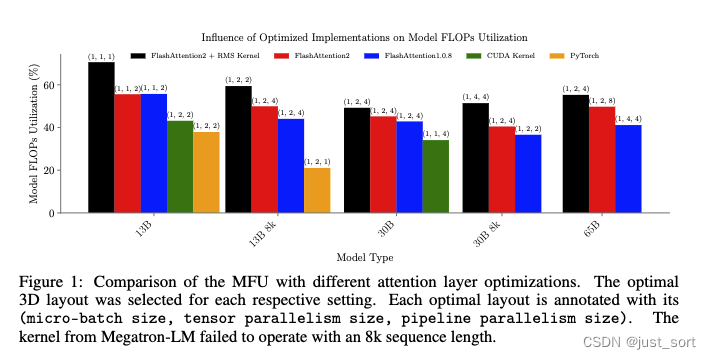
Figure1中展示了不同注意力实现的扫描结果,可以看到MFU最高的配置是Flash Attention2+RMS Kernel,然后micro-size=TP=PP=1,这样可以达到最佳MFU。需要特别注意的是Figure1中的测试都没有使用Activation Checkpointing(但Falsh Attention内部自己是有重计算的)。
0x5.1.2 RMSNorm Kernel
在Figure1厘米还展示了Flash Attention库里面优化的RMSNorm kernel在在训练效率上得到了很多的提升,和没用这个RMS Kernel相比可以提升14个百分点的MFU。当然有很大的原因是因为这个kernel更加节省内存,可以让并行配置从pp2变成纯数据并行,减少了通信开销。这里还提了一句,RMSNorm和Activation Checkpointing一起用会出错。
0x5.2 Activation Checkpointing
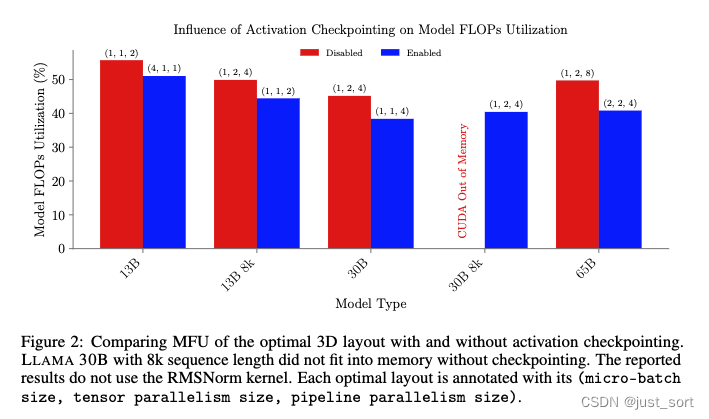
在Figure2里面报告了不同模型大小最佳配置的MFU,包含对每一层使用以及不使用Activation Checkpointing。结论就是在不使用Activation Checkpointing并且通过较小的micro-batch或者更高程度的模型并行来补偿因此产生的内存成本,可以实现最佳的训练MFU。这里没有使用Flash Attention提供的RMSNorm Kernel。
对于LLAMA 30B模型,序列长度为8k,在训练过程中即使TP Size大小达到4,PPO Size达到16,Activation Checkpointing也是将模型装入内存的必要条件。因为LLAMA 30B模型有52个注意力头,不能被8整除,所以我们无法增加TP Size。在paper的4.1节中,展示了添加RMSNorm kernel进一步降低了所需内存,使得Activation Checkpointing不再必要。在这种情况下,我们再次看到,不使用Activation Checkpointing的设置实现了最佳吞吐量。
另外,这里提到Flash Attention由于本身就自带重计算,所以一个更加合理的方法是对于一个Transformer Block来说,只对FFN这部分用重计算,避免多余的重复计算。
0x5.3 Micro-Batch 大小
这一小节评估了Micro-Batch 大小与所需模型(张量或流水线)并行度和Activation Checkpointing之间的权衡。之前已经有工作基准测试了不同的Micro-Batch大小,并固定了张量和流水线并行度,显示出更大的Micro-Batch大小带来更高的吞吐量。但是,较小的Micro-Batch大小可能使得不同的、更高效的并行化配置成为可能。此外,张量和流水线并行度在实践中也往往不是固定的。
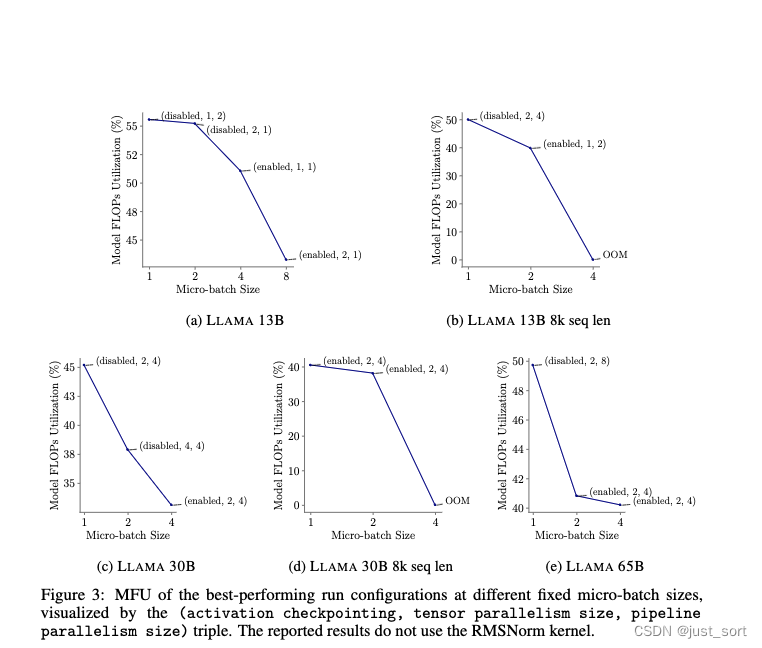
在图3中,paper展示了评估的每种模型类型的最佳表现(Activation Checkpointing、张量并行度大小、流水线并行度大小)配置。为了公平地评估 Activation Checkpointing,没有包括使用 Flash Attention2 的 RMSNorm Kernel,因为该kernel与Activation Checkpointing结合使用时会导致错误。最终发现对于所有模型类型,Micro-Batch大小为1的情况下达到了最佳MFU。一般来说是:Micro-Batch大小越小,MFU越好。使用大于2的Micro-Batch大小时,序列长度为8k的模型在任何并行配置下都无法塞进内存。
因此,这里得出结论,选择Micro-Batch大小为1在大多数情况下是有益的。Micro-Batch大小为1的卓越性能可归因于以下三个因素。
- 最小程度的模型并行化:最高效的训练通常需要最少量的模型(张量或流水线)并行化,这在Micro-Batch大小最小时实现。
- 避免Activation Checkpointing:对于某些模型(例如,LLAMA 65B),微批量大小为1是唯一允许无Activation Checkpointing训练的配置。正如前一节所讨论的,不使用Activation Checkpointing通常允许最高吞吐量的配置。LLAMA 30B 8k模型在不使用RMSNorm kernel的情况下无法装入内存。
- 减少流水线bubble时间:较小的Micro-Batch大小减少了在批处理开始和结束时在流水线bubble中花费的时间。这里使用的是1F1B流水线并行调度算法。Meagtron支持这种实现。
0x5.4 Tensor Parallelism和Pipline Parallelism
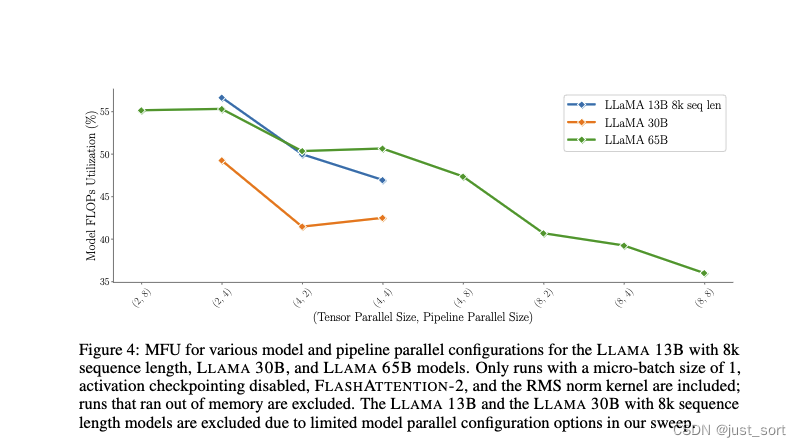
这一节的内容主要就是看Figure4,结论就是流水并行比张量并行更容易获得更高的MFU,应该优先流水并行。
0x5.5 Sequence Parallelism
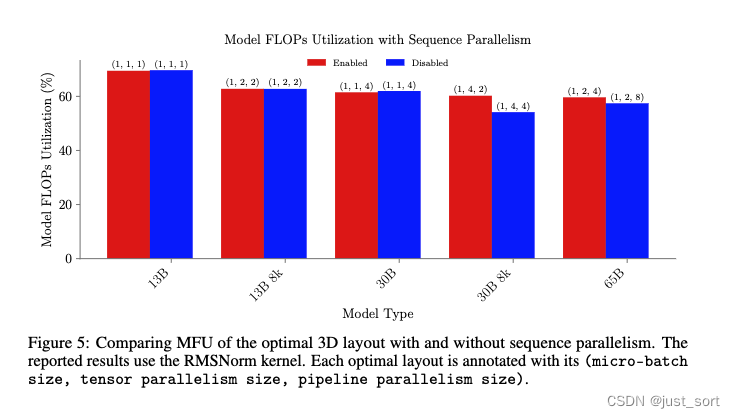
这一节就是看Figure5,对于LLAMA 13B和30B模型,序列长度为2k时,最佳配置是不使用任何张量并行,因此激活 Sequence Parallelism 没有效果。在序列长度为8k的13B模型中,最佳配置采用了2的张量并行大小;然而,没有观察到训练效率的提升。对于最大的模型和序列长度,即序列长度为8k的30B和65B模型,我们可以看到在使用Sequence Parallelism时有2-6个百分点的MFU提升。在这两种情况下,Sequence Parallelism由于减少了内存需求,使得模型并行化程度降低,从而提高了训练效率。
结论是,当与本工作中探索的其他几种优化结合使用时,Sequence Parallelism的使用只有在模型大小超过30B参数或序列长度超过2k时,才能显著提高训练效率。
0x5.6 端到端性能
实际上就是对下面这张表的解读:
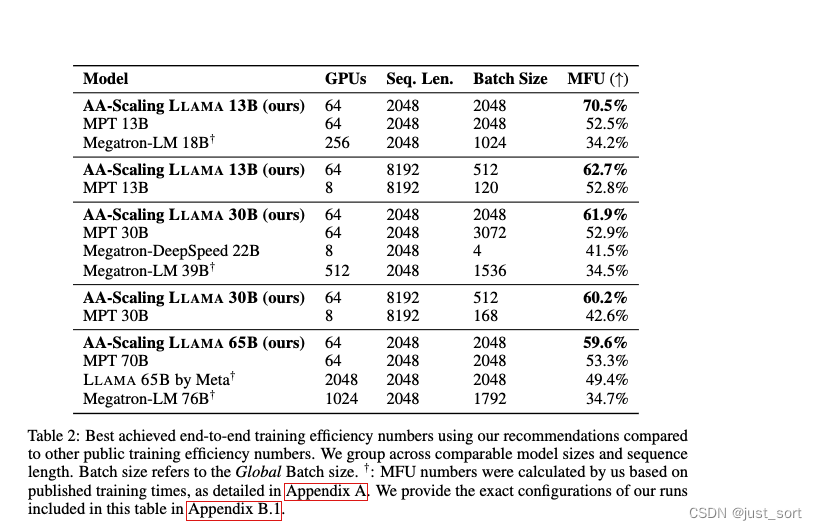
这里的AA-Scaling是作者团队内部的基于Megatron-LM开发的仓库,然后就是说基于本文搜索的最佳并行配置以及相关技术组合可以获得相比于公开框架和模型更高的MFU。
0x6. 结论
基于paper的大量搜索实验,最后得出来以下几个训练大模型的建议。
- 使用Micro Batch大小为1,以实现最小程度的模型并行化,避免Activation Checkpointing,并减少流水线bubble。
- 优先使用TP和PP,而不是Activation Checkpointing。
- 只有在无法进一步降低模型并行化程度时,才扩大Micro Batch大小。
- 对于参数超过30B且序列长度超过2k的模型,使用Sequence Parallelism。
0x7. 附录里面一些有用的公式
应该就是7.1和7.2可以认真看下,7.3可以忽略。
0x7.1 MFU计算公式

模型浮点运算量利用率(MFU)的计算遵循PaLM的方法。我们考虑理论上的矩阵乘法峰值吞吐量为P FLOPs每秒(例如,A100 GPU的峰值矩阵乘法TFLOPs为312)。然后,模型的FLOPs利用率是实际达到的每秒处理的token数与理论峰值吞吐量R = P/(6N + 12LHQT)的比率,其中L是层数,H是注意力头的数量,Q是注意力头的大小,T是序列长度。注意,L × H等于模型的隐藏层大小。N是参数量。计算的代码如下:

0x7.2 LLaMA训练的MFU估计

0x7.3 Megatron-LM MFU


这个可能参考意义不是很大,不太了解这个end2end的训练时间是怎么估记出来的,没看21所引用的paper。

