
- 1与 Josh Bloch 探讨 Java 未来
- 2Docker 实战:使用 Docker Desktop 在 MacOS 上安装 Docker_mac docker desktop
- 3通过域名访问文件共享服务器,域名访问共享文件夹
- 4《我十年的程序员生涯》系列之二:我写BITLOK的这七年
- 5java操作RabbitMQ添加队列、消费队列和三个交换机_java amqptemplate动态创建交换机 队列 和发送消息
- 6三分钟搞懂git patch 补丁的使用,小学生也能看懂
- 7MySQL数据库——存储过程练习
- 8【idea】idea 中 git 分支多个提交合并一个提交到新的分支_idea中已经push到远端的提交记录合并成一个
- 9创建repo服务器及使用_repo init -u ssh:
- 10vscode git 切换和隐藏分支_vscode切换分支
移动和嵌入式人体姿态估计(Mobile and Embedded Human Pose Estimation)_articulated part-based model for joint object dete
赞
踩
移动和嵌入式人体姿态估计
- 1. 背景
- 2. 移动应用模型
- 2.1 MobileNet -V1 (2017 Google)
- 2.2 MobileNetV2
- 2.3 MobileNetV3
- 2.4 设计网络设计空间 (DNDS)
- 3. 基于深度图的位姿估计
- 参考
1. 背景
-
现有的大部分模型都是在PC(带有超级强大GPU)上进行的,所以在嵌入式设备上基本无法使用
-
人体姿态估计
- 人体姿态估计主要是指在图像或者视频中找到人体的重要关节的位置(比如头,手、脚、肩部、膝盖、肘部等)
-
姿态相似性度量
- 利用各个关节点的位置进行适当的组合构造出的人体姿态特征
-
实现方案
- 优化模型:大大地减少参数
- 使用ARM中的GPU和NEON
-
实现方法
-
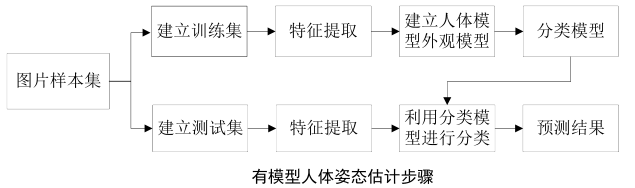
生成方法(Generative Methods)/有模型方法
- 先预定义身体部件模型,然后与输入的深度图像进行匹配
- 使用PSO, ICP最小化手工特征(hand-crafted)代价函数
- 通过将人体分为多个部件组合成模型,通过部件检测器检测部件的位置,进行部件之间的概率计算,从而对图像中的人体进行姿态估计
- 优势:不需要建立庞大的数据库,同时在模型建立完毕以后对于符合模型视角的姿态具有较高的识别率
- 劣势:复杂的人体模型构建较为困难,并且在实际情况中由于人体姿态具有多样性,使得很难构建出具有很强代表性的人体模型;所以此方法很难面对具有庞大数据量的真实情况
- 经典论文
- Therepresentationand matching of pictorial structures (1973)
- Cascaded models for articulated pose estimation (2010)
- Multi-view Pictorial Structures for 3D Human Pose Estimation (2013)
- Articulated part-based model for joint object detection and pose estimation (2013)
- Expanded parts model for human attribute and action recognition in still images (2013)
- 基于约束树形图结构外观模型的人体姿态估计 (2014)
- 一种基于图结构模型的人体姿态估计算法 (2013)
- 人体姿态估计步骤
- 常用特征提取方法
- 尺度不变特征变换法(SIFT:Scale Invariant Feature Transform)
- 梯度方向直方图特征(HOG:Histogram of Oriented Gradient)
-
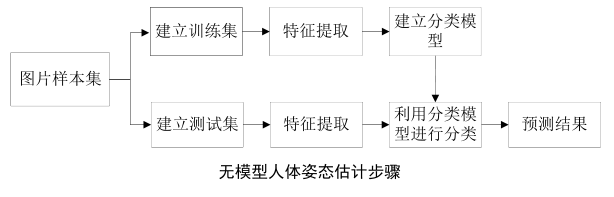
判别方法(Discriminative Methods)/无模型方法
- 根据输入的深度图像,直接定位关节位置
- 大多数基于深度学习的方法
- 通过对每张图像的像素点进行分析,通过先进的特征提取方法来估计人体部件的位置
- 优势:不需要建立复杂的人体模型,从而使用得此方法不受模型的约束,可以适用于真实应用场景中
- 劣势:
- 为适应现实生活中,需要建立庞大的数据库
- 对硬件条件具有较高的要求
- 经典论文
- Real-time human pose recognition in parts from single depth images (2013, Kinect, Shotton)
- Efficient regression of general-activity human poses from dept images (2011)
- Accurate 3d pose estimation from a single depth images (2011)
- 人体姿态估计步骤
- 常用特征提取方法
- 人体部件尺度特征
- 赵文闯 《深度图像中基于的人体识别方法》 2012
- 四维特征向量 ( d 0 , d 45 , d 90 , d 135 ) (d_0, d_{45}, d_{90}, d_{135}) (d0,d45,d90,d135)通过除以图像中人体身高进行归一化
- 优势:不同尺度下的人体姿态估计有着天然的优势
- 劣势:由于此特征没有很好的运用到部件在空间中处于不同位置,且不同部件的区分效果并不明显
- 深度图像偏移比较特征
- Shotton J (Kinect)
- 优势:运算简单、效果较好
- 劣势:由于此特征维数较低、在部件内部反应较小,所以使用在实际应用中偏移比较特征的鲁棒性和准确性并不是很好
- 深度图像方向梯度特征
- 方向梯度特征:像素点所在平面与深度相机所在平面的夹角
- 传统的深度图像方向梯度(DGoD:Directional Gradient of Depth)
D G o D p ( x , y ) = t a n − 1 d y d x = t a n − 1 p ( x , y + 1 ) − p ( x , y − 1 ) p ( x + 1 , y ) − p ( x − 1 , y ) DGoD_{p(x,y)} = tan^{-1} \frac{dy}{dx} = tan^{-1}\frac{p(x,y+1) - p(x, y-1)}{p(x+1, y) - p(x-1, y)} DGoDp(x,y)=tan−1dxdy=tan−1p(x+1,y)−p(x−1,y)p(x,y+1)−p(x,y−1)- p ( x , y ) p(x,y) p(x,y):是深度图像在x列y行处的深度值
- 方向梯度取值范围: [ 0 ° , 360 ° ] [0°, 360°] [0°,360°]
- d x = 0 a n d d y = 0 dx=0 \quad and \quad dy=0 dx=0anddy=0,则DGoD=0
- d x > 0 a n d d y = 0 dx > 0 \quad and \quad dy=0 dx>0anddy=0,则DGoD = 360°
- d x < 0 a n d d y = 0 dx < 0 \quad and \quad dy=0 dx<0anddy=0,则DGoD = 180°
- 优化的深度图像方向梯度
D G o D p ( x , y ) = t a n − 1 d y d x = t a n − 1 p ( x , y + i ) − p ( x , y − i ) p ( x + i , y ) − p ( x − i , y ) DGoD_{p(x,y)} = tan^{-1} \frac{dy}{dx} = tan^{-1}\frac{p(x,y+i) - p(x, y-i)}{p(x+i, y) - p(x-i, y)} DGoDp(x,y)=tan−1dxdy=tan−1p(x+i,y)−p(x−i,y)p(x,y+i)−p(x,y−i)- i ∈ ( i m i n , i m a x ) i \in (i_{min}, i_{max}) i∈(imin,imax)
- 目的:解决dx=0或 dy=0过多的问题
- 不同部件可能位于同一平面,也可能位于不同平面,此方法不能区分位于同一平面但不同部件的点,量级梯度特征可解决此问题
- 深度图像量级梯度特征
- 传统的深度图像量级梯度(MGoD:Magnitude Gradient of Depth)
M G o D p ( x , y ) = [ p ( x + 1 , y ) − p ( x − 1 , y ) ] 2 + [ p ( x , y + 1 ) − p ( x , y − 1 ) ] 2 MGoD_{p(x,y)} = \sqrt {[p(x+1, y) - p(x-1, y)]^2 + [p(x,y+1) - p(x, y-1)]^2} MGoDp(x,y)=[p(x+1,y)−p(x−1,y)]2+[p(x,y+1)−p(x,y−1)]2 - p(x,y):是深度图像在x列y行处的深度值
- 优化的深度图像量级梯度
M G o D ( I , x ) = d I ( x + u d I ( x ) ) − d I ( x + v d I ( x ) ) MGoD_{(I,x)} = d_I(x + \frac {u}{d_I(x)}) - d_I(x + \frac {v}{d_I(x)}) MGoD(I,x)=dI(x+dI(x)u)−dI(x+dI(x)v)- $MGoD_{(I,x)} : 表 示 深 度 图 像 :表示深度图像 :表示深度图像I 中 位 置 为 中位置为 中位置为x$的像素点的量级梯度特征值
- d ( ⋅ ) d({\cdot}) d(⋅):此点的深度信息
- u 和 v u和v u和v:分别为 x x x点在水平和垂直方向的偏移量
- 传统的深度图像量级梯度(MGoD:Magnitude Gradient of Depth)
- 人体部件尺度特征
-
混合方法(Hybrid Methods)
- 把生成方法和判别方法结合使用
- 使用自动编码器学习潜在空间
-
-
研究现状
- 基于RGB彩色图像
- 易受光照变化、背景、阴影和噪声等的影响
- 基于深度图像
- 逐像素分类的方法
- 基于概率图模型的方法
- 基于特征点的方法
- 基于深度学习的方法
- 结合RGB彩色图像和深度图像
- 基于RGB彩色图像
-
逐像素分类的方法
- 将深度图像上邻近区域内像素对的深度差值作为部位特征,来区分身体的不同部位,然后再结合随机决策森林的方法,将每一个像素进行分类
- 在逐像素分类的方法中,首次发表于2011 年的内置于Kinect 中使用的方法最具有代表性,该方法由Shotton 等提出,他们的做法是将一个区域内人体的像素对应的深度之间的差值作为特征,然后利用随机决策森林进行训练,对于每一个像素进行分类贴上部位标签,然后利用部位的信息再将这些特征回归到关节点。
- 这种方法实时性很好,并且在准确性上也有很好的表现,但是这种方法需要海量的带标签的数据进行很长时间的训练才能达到良好的效果。基于Shotton 等提出逐像素分类方法的开拓,越来越多的研究人员受到该方法的启发,并在该方向上取的了一定的进步。逐像素分类的方法目前只能应用于深度图像。
- 流程图

- 优点
- 基本思想:设计像素或者像素对之间的特征,将人体像素通过分类方法对应到人体不同部位,然后再将人体对应部位信息优化到人体关节点信息。
- 这种方法的准确性比较高
- 缺点
- 需要大量的带标签的训练数据进行模型的训练才能达到能够接受的效果
- 训练时间也很长,工作量极大,只能应用在特定场景中
- 相关论文
- Multi-task forest for human pose estimation in depth images (Lallemand J)
- 提出了一种新颖的方法,在进行随机森林训练时,除了将深度图像中人体的每一个像素对应到相应的三维关节点位置,还将每一个像素与人体的运动状态进行关联,将人体运动信息整合到目标函数中,改善了人体姿态预测的精度
- The Vitruvian manifold: inferring dense correspondences for one-shot human pose estimation (Taylor J)
- 使用回归森林来使深度图像与身体模型相对应,对于输入的深度图像,通过回归森林推断出对应的人体模型,然后优化模型参数,得到优化后的关节点位置,得到最终人体姿态
- An adaptable system for RGB-D based human body detection and pose estimation (Buys K)
- 使用随机森林将深度图像中每一个像素与身体部位联合起来,并通过在部位中聚类中以及人体关节点间的约束关系得到初始骨架模型,然后再结合外观模型,将人体从彩色图像中分割出来,逐步迭代得到最终人体姿态
- Human body part estimation from depth images via spatiallyconstrained deep learning (Jiu M)
- 基于卷积神经网络使用身体部位的空间特征进行逐像素分类,而且像素分类的性能有了极大提高
- Accurate realtime full-body motion capture using a single depth camera (Wei X)
- 使用混合动作捕捉系统将3D 姿态跟踪与人体检测结合,并做到
了实时人体姿态估计的效果
- 使用混合动作捕捉系统将3D 姿态跟踪与人体检测结合,并做到
- Multi-task forest for human pose estimation in depth images (Lallemand J)
-
基于概率图模型的方法
- 是指把人体模型用刚体或者非刚体的部件来表示,这些部件之间用相连接的边来约束,最终能够用人体部件分配的先验概率优化问题定位人体的每一个部件,识别人体姿态并达到识别人体每一个关节的目的
- 这种方法在彩色图像和深度图像中都可以应用,有许多的实现。
- 基于概率图模型来解决问题,实质上是指通过概率模型来推理结果,整个过程包括学习模型和基于模型进行推理两个部分。
- 概率图模型指的是结合了概率论和图论相关知识,用图形的方式去表达变量之间的关系的模型的一类总称
- 概率图模型中的图主要是由点和边构成:
- 点代表随机变量
- 边指的是与边连接的点之间的概率关系
- 常见的概率图模型主要包括:
- 马尔科夫模型
- 贝叶斯模型
- 隐马尔科夫模型
- 实际应用中为了克服有时候单个模型对于问题的描述不够准确的情况,出现了混合模型,这种模型由概率图模型与其他模型或者理论相结合而形成。
- 相关论文
- Controlled human pose estimation from depth image streams (Zhu Y)
- 人使用飞行时间成像装置来获取深度图像,并在深度图像上提取特征来估计人体姿态。其中这些特征是基于概率推断的方法来进行检测和跟踪的
- Bayesian 3D human body pose tracking from depth image sequences (Fujimura K)
- 使用深度图像和人体模型之间的对应关系,进行局部优化得到身体部位,进而得到当前帧的人体关节点。并通过贝叶斯推断的方法来跟踪图像序列中的人体关节点
- Real time motion capture using a single time-offlight camera (Ganapathi V)
- 通过结合生成模型和判别模型来表示身体部位,并使用爬山搜索来解决最大后验推理问题
- Real-time simultaneous pose and shape estimation for articulated objects using a single depth camera
- 将关节形变模型嵌入到高斯混合模型中,并提出了一种用于将模板形状映射到主体形状的形状自适应算法。
- Controlled human pose estimation from depth image streams (Zhu Y)
- 综合以上提到几种概率图模型的方法,在人体姿态估计领域使用范围最广的是贝叶斯模型,此外基于混合概率图模型的方法也比较常见。基于概率图模型的方法主要是基于样本数据进行训练,学习模型的参数以及模型的结构,也即模型中各个节点之间的关系和概率密度函数等。训练好模型后即可基于已知参数进行变量取值的推断。
-
基于特征点的方法
-
是指在深度图像上找到人体的目标点(通常为在人体深度图像上求测地距离,并将求得的极值点作为感兴趣的目标点)
-
常常利用深度图像中像素点的空间几何特点,首先将深度图像数据转换成点云数据,再利用空间中相邻点之间约束关系等,将点连接成连通图,然后将中心点作为起始点计算测地距离[38],通常挑选最大测地距离的点或者其他特征的极值点作为特征点
-
测地距离(Geodesic Distance):就是在曲面上从A点走到B点(不允许离开曲面)的最短距离, G e o d e s i c _ D i s t a n c e = d 12 + d 23 + d 34 + d 45 Geodesic\_Distance = d_{12} + d_{23} + d_{34} + d_{45} Geodesic_Distance=d12+d23+d34+d45
-
欧氏距离(Euclidean Distance):即两点之间的最短距离, E u c l i d e a n _ D i s t a n c e = d 15 Euclidean\_Distance = d_{15} Euclidean_Distance=d15
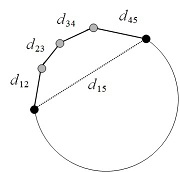
-
处理流程:
- 深度图像预处理:剔除背景,提取前景,然后进行中值滤波去噪
- 把深度图像转换成点云 (根据相机内参)
- 得到点云数据后,可以利用空间中点的约束关系来构建边,进而连接成整张网格图,即ijx 与klx 两点之间是否有边连接,需要考察空间中两点之间的欧氏距离是否满足一定阈值,而且在2D 深度图像上两点是否是邻接关系,即点云中点包含边的原则是两点在深度图像上相邻,而且空间中两点的距离也在阈值范围内
- 求身体极值点的通常做法是:取人体点云中的重心作为起点,然后计算起点到其他所有点的测地距离,最后选取其中的几个具有极大测地距离的点作为特征点

-
在得到目标点后,不同的学者提出了不同的方案:
- Human skeleton tracking from depth data using geodesic distances and optical flow (Schwarz L A)
- 是利用测地极值求出5个身体部位,分别是头部、左手、右手、左脚、右脚,然后将这几个点跟关节点进行拟合,得出最终关节点,如果存在没有检测到的部位,则利用上一帧的彩色图像信息,求取光流变化并推断出这一帧丢失的部位
- Accurate static pose estimation combining direct regression and geodesic extrema (Holt B)
- 首先使用随机决策森林对身体上每一个像素进行分类,估计出身体的刚性部位,然后通过Dijkstra 算法求测地距离,并结合测地极值点将身体具体部位划分出来,最终估计出人体姿态;同时发布了一个包含对齐的彩色图像和深度图像的全新的数据集,用来评估不同方法的效果
- Real-time identification and localization of body parts from depth images (Plagemann C)
- 在身体上通过测地距离计算大约20 个感兴趣点,并提取每个点的方向向量,并确定该点属于的身体部位,从而识别人体姿态。
- Human skeleton tracking from depth data using geodesic distances and optical flow (Schwarz L A)
-
基于特征点的方法目前只能应用于深度图像
-
仅仅依靠测地极值点作为人体的全部特征,往往不能刻画全部的人体姿态,鲁棒性不够好
-
-
基于深度学习的方法
- 基于深度学习提出了一种新的深度推理嵌入式(deep inference-embedded)多任务学习框架,用于从静态深度图像中预测人体姿态
- 相关论文:
- Human pose estimation from depth images via inference embedded multi-task learning (Wang K)
- 使用全卷积网络来生成身体部位的热度(置信度)图 (heatmap)
- 利用此heatmap将身体关键部位检测出来
- 基于检测到的关键部位使用嵌入的匹配网络(MatchNet)来推断当前身体部位的具体位置,得到最终人体关节位置

- Reconstruction of 3D human body pose from stereo image sequences based on top-down learning (Yang H D)
- 是将输入的深度图像用事先准备好的数据库中的多张深度图像线性组合而成
- 求出组合系数
- 将数据库中的深度图像对应的3D 人体模型进行线性组合即可得到输入的深度图像对应的人体模型
- Accurate 3d pose estimation from a single depth image (Ye M)
- 将深度图像对应的点云剔除背景、去除噪声
- 将点云的坐标正则化,使之与视角无关
- 在本地数据库中搜索相似姿态并进行适当修正,得到最终人体关节点位置
- Real-time posture reconstruction for Microsoft Kinect (Shum H)
- 利用Kinect SDK 给出的关节点位置进行评估
- 对于存在遮挡的情况,在本地离线的动作数据库中进行最近邻搜索
- 查找与当前姿态最相似的姿态,并通过姿态优化合成得到最终模拟人物

- Human pose estimation from depth images via inference embedded multi-task learning (Wang K)
1.1 获取小型网络的方法
- 收缩(shrinking),分解(factorizing)或压缩(compressing)预训练的网络
- 压缩:基于乘积量化(product quantization)、哈希(hashing)以及修剪(pruning)的压缩,提出了向量量化和霍夫曼编码
- 蒸馏:它使用较大的网络来教授较小的网络
1.2 判断模型的指标
- 准确度(accuracy)
- 通过乘法加法(MAdd)度量的操作数(number of operations measured by multiply-adds (MAdd))
- 实际延迟(处理耗时: actual latency)
- 参数数量(number of parameters)
- MACs/MADDs:乘法和加法操作数量(the number of multiply-accumulates)
1.3 经典网络结构
- 移动和嵌入式平台
- ShuffleNet:利用分组卷积和通道打乱操作进一步减少MAdds
- SqueezeNet:广泛使用1x1卷积与挤压和扩展模块,主要集中于减少参数的数量
- MobileNetV1:采用深度可分离卷积,大大提高了计算效率 ( 1 K 2 \frac {1}{K^2} K21)
- MobileNetV2:避免丢失低维空间的特征信息
- 在MobileNetV1基础上引入了一个具有反向残差和线性瓶颈的资源高效模块
- MobileNetV3:减少操作的数量(MAdds)和实际测量的延迟
- CondenseNet:在训练阶段学习组卷积,以保持层与层之间有用的紧密连接,以便功能重用
- ShiftNet:提出了与点向卷积交织的移位操作,以取代昂贵的空间卷积
- 专业GPU/TPU平台
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
1.4 源码
1.5 读论文的正确方法
- 论文+代码
- 明白论文的常用手法
- 每篇论文都不会说自己的缺点,只会放大优点。但是引用别人的论文时,却总放大别人工作的缺点。当你对比阅读时,形成一个知识串,才会对某个问题有更清晰的认识。
- 论文为了出成果,一般只会选择对自己模型有力的数据集验证。对某一领域数据集特征了解,再也不会被作者蒙蔽双眼了。比如NAS(Neural Architecture Search),很多论文喜欢在CIFAR-10/ CIFAR-100/SVHN等小数据集比实验结果,ImageNet性能表现避重就轻避而不谈;很多论文写state-of-art的性能,对实时性不谈;论文没有说的没有做的可能是个大坑。
- 论文因为要投稿和发表顶会,故意会云里雾里引入很多概念和公式,当对比代码,关键trick,才能返璞归真。Code+paper,才是论文最佳的阅读方式。
- 对于自己关注的领域,可能每篇有影响的,实验结果不是state-of-art也要关注,因为工作可能会撞车。对横向领域的论文,要关注state-of-art,说不定很多trick可以直接迁移到自己的工作。
- 拒绝二手知识。阅读一篇论文,直接从原文阅读思考、和作者邮箱联系寻找答案。
1.6 分组卷积(Group Convolution)
- Group Convolution:AKA(also known as) Filter groups
- 常规卷积
- 如果输入feature map尺寸为C∗H∗W,卷积核有N个
- 输出feature map与卷积核的数量相同也是N
- 每个卷积核的尺寸为C∗K∗K
- N个卷积核的总参数量为N∗C∗K∗K
- 分组卷积
- 对输入feature map进行分组,然后每组分别卷积。
- 假设输入feature map的尺寸仍为C∗H∗W,输出feature map的数量为N个,
- 如果设定要分成 G G G个groups,则每组的输入feature map数量为 C G \frac {C}{G} GC,每组的输出feature map数量为 N G \frac {N}{G} GN,每个卷积核的尺寸为 C G ∗ K ∗ K \frac{C}{G}∗K∗K GC∗K∗K,卷积核的总数仍为N个
- 每组的卷积核数量为 N G \frac{N}{G} GN,卷积核只与其同组的输入map进行卷积,卷积核的总参数量为 N ∗ C G ∗ K ∗ K N∗\frac{C}{G}∗K∗K N∗GC∗K∗K,可见,总参数量减少为原来的 1 G \frac{1}{G} G1
- group1输出map数为2,有2个卷积核,每个卷积核的channel数为4,与group1的输入map的channel数相同,卷积核只与同组的输入map卷积,而不与其他组的输入map卷积。

- 分组卷积的用途
- 减少参数量,分成G组,则该层的参数量减少为原来的 1 G \frac{1}{G} G1
- 分组卷积可以看成是structured sparse,每个卷积核的尺寸由 C ∗ K ∗ K C∗K∗K C∗K∗K变为 C G ∗ K ∗ K \frac{C}{G}∗K∗K GC∗K∗K,可以将其余 ( C − C G ) ∗ K ∗ K (C−\frac{C}{G})∗K∗K (C−GC)∗K∗K的参数视为0,有时甚至可以在减少参数量的同时获得更好的效果(相当于正则)
- 分组卷积=>深度可分离卷积
- 当分组数量等于输入map数量,输出map数量也等于输入map数量,即
G
=
N
=
C
G=N=C
G=N=C、
N
N
N个卷积核每个尺寸为
1
∗
K
∗
K
1∗K∗K
1∗K∗K时,分组卷积(Group Convolution)就成了深度可分离卷积(Depthwise Convolution),参见MobileNet,参数量进一步减少。

- 当分组数量等于输入map数量,输出map数量也等于输入map数量,即
G
=
N
=
C
G=N=C
G=N=C、
N
N
N个卷积核每个尺寸为
1
∗
K
∗
K
1∗K∗K
1∗K∗K时,分组卷积(Group Convolution)就成了深度可分离卷积(Depthwise Convolution),参见MobileNet,参数量进一步减少。
- 分组卷积=>全局深度可分离卷积
- Global Depthwise Convolution(GDC):全局深度可分离卷积
- 更进一步,如果分组数G=N=C,同时卷积核的尺寸与输入map的尺寸相同,即K=H=W,则输出map为C∗1∗1即长度为C的向量,此时称之为Global Depthwise Convolution(GDC),见MobileFaceNet
- 可以看成是全局加权池化,与 Global Average Pooling(GAP) 的不同之处在于,GDC 给每个位置赋予了可学习的权重(对于已对齐的图像这很有效,比如人脸,中心位置和边界位置的权重自然应该不同),而GAP每个位置的权重相同,全局取个平均

2. 移动应用模型
- MobileNet家族
| MobileNet版本 | 主要特点 |
|---|---|
| V1 | 深度可分离卷积 |
| V2 | 1) 反向残差 2) 线性瓶颈 |
| V3 | 1) 网线结构搜索:基于块搜索的NAS, 基于层搜索的NetAdapt 2) 使用的新的激活函数 h-swish(x) 3) 基于squeeze and excitation 结构的轻量级注意力机制 |
2.1 MobileNet -V1 (2017 Google)
2.1.1 深度可分离卷积概念
- MobileNet模型:基于深度可分离卷积
- 深度可分离卷积
- (DSC:Depthwise Separable Convolution)
- 它是分解卷积的一种形式,可将标准卷积分解为深度卷积和1×1卷积 (点式卷积)
- 使用DSC创建了一个轻量级神经网络
- 使用两个简单的全局超参来控制性能(计算量)和准确性之间的平衡
- 标准卷积:一步实现以下两个功能:
- 滤波器
- 将输入合并为一组新的输出
- 深度可分离卷积(MobileNet):分步实现以下两个功能:
- 深度卷积(depthwise convolution):将单个滤波器应用于每个输入通道
- 逐点卷积 (pointwise convolution):使用1×1卷积合并深度卷积的输出
- 深度可分离卷积把标准卷积分为以下两个独立的层:
- 滤波器层(filtering)
- 合并层(combing)
- 这样大大减小于模型的大小和计算量
2.1.2 深度可分离卷积流程
- 标准卷积流程:

- 把标准卷积分解为深度卷积和逐点卷积的流程如下图所示:

- 深度可分离卷积示意图

2.1.3 深度可分离卷积计算成本
- 计算参数数量
- 参数说明:
- 输入特征图(Input Feature Map) F : D F × D F × M F:D_F \times D_F \times M F:DF×DF×M
- 输出特征图(Output Feature Map) G : D F × D F × N G:D_F \times D_F \times N G:DF×DF×N
- M M M:输入特征图的通道数(input channels / input depth)
- N N N:输出特征图的通道数(output channels / output depth)
- D F D_F DF:特征图的宽度和高度
- 标准卷积
- 卷积Kernel
K
K
K的参数数量:
D
K
⋅
D
K
⋅
M
⋅
N
D_K \cdot D_K \cdot M \cdot N
DK⋅DK⋅M⋅N
- D K D_K DK:方形Kernel的边长
- M M M:输入特征图的通道数(深度)
- N N N:输出特征图的通道数(深度),也即卷积Kernel D K ⋅ D K ⋅ M D_K \cdot D_K\cdot M DK⋅DK⋅M 的个数
- 输出特征图(stride 1 and padding 1):
G k , l , n = ∑ i , j , m K i , j , m , n ⋅ F k + i − 1 , l + j − 1 , m G_{k,l,n} = \sum_{i,j,m}K_{i,j,m,n} \cdot F_{k+i-1, l+j-1,m} Gk,l,n=i,j,m∑Ki,j,m,n⋅Fk+i−1,l+j−1,m - 计算成本: 标 准 卷 积 计 算 成 本 c o s t = D K ⋅ D K ⋅ M ⋅ D F ⋅ D F ⋅ N 标准卷积计算成本cost = D_K\cdot D_K \cdot M \cdot D_F\cdot D_F \cdot N 标准卷积计算成本cost=DK⋅DK⋅M⋅DF⋅DF⋅N
- 卷积Kernel
K
K
K的参数数量:
D
K
⋅
D
K
⋅
M
⋅
N
D_K \cdot D_K \cdot M \cdot N
DK⋅DK⋅M⋅N
- 深度可分离卷积
- 深度卷积Kernel
K
^
\hat{K}
K^ (Kernel数量=输入层的深度值)
- 参数数量**: D K ⋅ D K ⋅ M D_K\cdot D_K \cdot M DK⋅DK⋅M
- D K D_K DK:方形Kernel的边长
- M M M:输入特征图的通道数(深度)
- 深度卷积Kernel K ^ \hat{K} K^的第m个Filter应用于输入特征图 F F F的第m个通道(channel),且生成输出特征图 G ^ \hat{G} G^的第m个通道
- 深度卷积计算成本: c o s t 1 = D K ⋅ D K ⋅ M ⋅ D F ⋅ D F cost_1 = D_K \cdot D_K \cdot M \cdot D_F \cdot D_F cost1=DK⋅DK⋅M⋅DF⋅DF
- 逐点卷积 (Kernel数量=输出层的深度值) :
- 通过 1 × 1 1 \times1 1×1卷积计算深度卷积输出的线性组合,产生新的特征图 G G G
- 计算成本: c o s t 2 = M ⋅ D F ⋅ D F ⋅ N cost_2 = M \cdot D_F\cdot D_F\cdot N cost2=M⋅DF⋅DF⋅N
- 深度可分离卷积计算成本: 深 度 可 分 离 卷 积 计 算 成 本 c o s t = D K ⋅ D K ⋅ M ⋅ D F ⋅ D F + M ⋅ D F ⋅ D F ⋅ N 深度可分离卷积计算成本cost = D_K \cdot D_K \cdot M \cdot D_F \cdot D_F + M \cdot D_F\cdot D_F\cdot N 深度可分离卷积计算成本cost=DK⋅DK⋅M⋅DF⋅DF+M⋅DF⋅DF⋅N
- 深度卷积Kernel
K
^
\hat{K}
K^ (Kernel数量=输入层的深度值)
- 参数说明:
- 计算成本之比(深度可分离卷积/标准卷积): r a t i o = D K ⋅ D K ⋅ M ⋅ D F ⋅ D F + M ⋅ D F ⋅ D F ⋅ N D K ⋅ D K ⋅ M ⋅ D F ⋅ D F ⋅ N = 1 N + 1 D K 2 ratio = \frac {D_K \cdot D_K \cdot M \cdot D_F \cdot D_F + M \cdot D_F\cdot D_F\cdot N} {D_K\cdot D_K \cdot M \cdot D_F\cdot D_F \cdot N} = \frac {1}{N} + \frac{1}{D_K^2} ratio=DK⋅DK⋅M⋅DF⋅DF⋅NDK⋅DK⋅M⋅DF⋅DF+M⋅DF⋅DF⋅N=N1+DK21
- 当使用 3 × 3 3 \times 3 3×3卷积核(Kernel),深度可分离卷积的计算量是标准卷积计算量的 1 8 \frac{1}{8} 81
2.1.4 网络结构
- 标准卷积与深度可分离卷积

- MobileNet网络结构

- 不同类型层的资源消耗

2.1.5 超参
- 为进一步减少计算量,引入以下两个超参
- 宽度乘数
α
\alpha
α(Width Multiplier):使模型更小
- 作用于输入输出通道数,即把输入通道数 M M M变为 α M \alpha M αM,把输出通道数 N N N变为 α N \alpha N αN,从而减少模型的参数数量及计算量
- α ∈ ( 0 , 1 ] \alpha \in (0,1] α∈(0,1],其典型值为0.25, 0.50, 0.75, 1.0
- 宽度乘数可以应用于任何模型结构,以合理的精度,等待时间和尺寸折衷来定义新的较小模型
- 它用于定义新的简化结构,需要从头开始进行训练
- 新计算量为原计算量的 α 2 \alpha^2 α2倍
- 分辨率乘数
ρ
\rho
ρ(Resolution Multiplier):简化表示
- 其作用是减少输入图像的分辨率,即把输入 D F D_F DF修改为 ρ D F \rho D_F ρDF
- 新计算量为原计算量的
ρ
2
\rho^2
ρ2倍

2.1.6 实验结果




2.1.7 局限性
- 优点:使用深度可分享卷积,以在牺牲较小性能的前提下大大地减少参数数量
- 局限:深度卷积的Kernel数量取决于输入的Depth,且无法改变
2.2 MobileNetV2
- 论文:反向残差和线形瓶颈 (MobileNetV2: Inverted Residuals and Linear Bottlenecks) Google Inc. (2019)
- 目标:
- 减少计算量的同时避免特征损失(线性瓶颈)
- 减少内存消耗
- 提高AP (线性瓶颈和反向残差)
- 主要贡献:
- 一个创新的层模块:具有线性瓶颈的反向残差(the inverted residual with linear bottleneck)
- 通过使用【反向残差和线形瓶颈】的结构,解决了MobileNetV1在深度卷积中存在的输入层Kernel数据固定的瓶颈
- 在准度性与性能间最得最佳平衡(strike an optimal balance between accuracy and performance)
- 测试数据集
- ImageNet classification
- COCO objection detection
- VOC image segmentation
- 概念
- 感兴趣的信息:manifold of interest
2.2.1 深度可分离卷积
- Depthwise Separable Convolutions
- 与MobileNetV1中的一样,在MobileNetV2中继续使用
2.2.2 线性瓶颈 (Linear Bottlenecks)
- 起因:
- 在MobileNetV1中引入了超参Width Multiplier参数缩减模型的输入和输出通道(channels),其结果为特征信息就更加集中在缩减后的通道中,如果在缩减后的特征图上使用非线性激活层(如ReLU),就会有较大的信息丢失。为了减少信息丢失,就引入了本文中的“线性瓶颈 (Linear Bottlenecks)”
- 深度网络仅在输出域的非零体积部分具有线性分类器的能力,因为ReLU留下的非0体积内的点都是通过线性变换得来的,其它的值被丢掉了
- ReLU变换保留哪些信息?
- 1)如果感兴趣的信息在ReLU变换后仍保持非零体积内,则它对应于线性变换 (即ReLU的作用就是一个线性变换)
- 2)ReLU能够保留有关输入信息的完整信息,但前提是输入信息位于输入空间的低维子空间中

- 上图的实验表明:
- 把初始信号嵌入到n维空间中,然后通过ReLU变换之后,再进行逆变换,最后恢复出原始信号
- 若n=2或3,恢复的信息相比原始信息损失较多
- 若n=15或30,恢复的信息相比原始信息损失较少
- 结论:低维经过ReLU之后信息(特征)损失最大
- 什么是瓶颈(Bottlenects)?
- 输出维度(深度)减少的层就是一个Bottleneck,类似一个沙漏
- 什么是线性瓶颈(Linear Bottleneck)?
- Bottleneck层不接非线性激活函数 (如ReLU),就是一个Linear Bottleneck
- 实验证据表明,使用线性层至关重要,因为它可以防止非线性破坏过多的信息。
2.2.3 卷积块的变体

2.2.4 反向残差(Inverted residuals)
- 传统残差:维度变化规则:先缩小后增加
- 反向残差:维度变化规则:先增加后缩小
- 思路:瓶颈实际上包含所有必要的信息,而扩展层仅充当张量的非线性转换的实现细节,我们直接在瓶颈之间使用短路连接,以实现残差学习

2.2.5 网络结构
- ReLU6
- 定义: f ( x ) = m i n ( m a x ( x , 0 ) , 6 ) f(x) = min(max(x,0),6) f(x)=min(max(x,0),6)
- 用途:在低精度计算时能压缩动态范围,算法更稳健
2.2.5.1 线性瓶颈深度可分离卷积结构 (bottleneck depth-separable convolution)

- 在深度卷积之前增加了一层逐点卷积,如下图所示

- 深度卷积输入的通道数由逐点卷积的Kernel个数决定,从而可任意设置深度卷积Kernel的个数
2.2.5.2 不同架构的卷积块比较

2.2.5.3 最大的通道数/内存比较
- channels/memory (in Kb)

2.2.6 实验结果
2.2.6.1 不同网络的性能曲线

2.2.6.2 线性瓶颈和反向残差对Top 1 Accuracy的影响

2.2.6.3 性能比较(基于COCO数据集)

2.2.6.4 性能比较(基于ImageNet数据集)

2.3 MobileNetV3
- 论文:Searching for MobileNetV3 Google AI, Google Brain (2019)
- 目标:
- 在移动手机CPU上达到实时性能
- 将关注点从减少参数转移到减少操作的数量(MAdds)和实际测量的延迟
- 目标:Accuracy and Latency
- 主要贡献
- 探索自动化网络搜索和人工设计如何协同互补
- 网络搜索
- 网络架构搜索:Network/Neural Architecture Search (NAS)
- 通过NAS优化每个网络块,以搜索全局最优网络架构
- NetAdapt算法:NetAdapt Algorithm
- 用NetAdapt算法搜索每层滤波器(Filter)的数量
- 网络架构搜索:Network/Neural Architecture Search (NAS)
- 人工设计
- 新的SE模块
- 新的H-Swish激活函数
- 更改末端计算量大的层,将增维的1x1层移到平均池化之后
- 更改初始端为16个卷积核
- 应用场景
- MobileNetV3-Large:用于高端手机
- MobileNetV3-Small:用于低端手机
2.3.1 在Pexel 1手机上的性能

2.3.2 高效的移动构建块(Efficient Mobile Building Blocks)

2.3.3 网络搜索(Network Search)
- 网络搜索(Network Search)
- 是一个用于探索和优化网络结构(Network Architecture)的强大工具
- Platform-Aware NAS
- 通过优化每一个网络块(Network Block)搜索全局网络结构(Global Network Structure)
- NetAdapt
- 用于搜索每一层的filters个数
- 结论
- 以上2种技术是互补的,可以组合起来有效地找到给定硬件平台的优化模型
2.3.3.1 探索空间增强
- 高效的特征提取方法
- 神经网络模型的特征提取能力可以通过改进网络结构来提高,而无需通过更多的监督学习方式来提高

- 神经网络模型的特征提取能力可以通过改进网络结构来提高,而无需通过更多的监督学习方式来提高
- Goolge Inception
- 嵌入了多尺度信息,聚合多种不同感受野上的特征来获得性能增益
- Inside-Outside 网络
- 考虑了空间中的上下文信息
2.3.3.2 SENet (Squeeze-and-Excitation Networks)
- 核心思想
- 通过网络根据loss去学习特征权重,使得有效的feature map权重大,无效或效果小的feature map权重小的方式训练模型达到更好的结果
- 通过学习的方式来自动获取到每个特征通道的重要程度
- 然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征
- 特点
- 并不是一个完整的网络结构,而是一个子结构,可以嵌到其他模型中
- Squeeze 和 Excitation 是两个非常关键的操作
- 动机是希望显式地建模特征通道之间的相互依赖关系
- SENet模块

- 给定一个输入 x \mathbf x x,其特征通道数为 c 1 c_1 c1,通过一系列一般卷积变换后得到一个特征通道数为 c 2 c_2 c2 的特征图。与传统的 CNN 不一样的是,接下来我们通过三个操作来重标定前面得到的特征
- Squeeze 操作 F s q ( ⋅ ) F_{sq}(\cdot) Fsq(⋅):我们顺着空间维度来进行特征压缩,将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。它表征着在特征通道上响应的全局分布,而且使得靠近输入的层也可以获得全局的感受野,这一点在很多任务中都是非常有用的。
- Excitation 操作 F e x ( ⋅ , w ) F_{ex}(\cdot, w) Fex(⋅,w):它是一个类似于循环神经网络中门的机制。通过参数 w 来为每个特征通道生成权重,其中参数 w 被学习用来显式地建模特征通道间的相关性。
- Reweight 的操作 F s c a l e ( ⋅ ) F_{scale}(\cdot) Fscale(⋅):将 Excitation 的输出的权重看做是经过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。
2.3.4 感知平台的NAS用于逐块搜索 (Block-wise Search)
- 大的移动模型(Large Mobile Model)
- 首先:使用MnasNet-A1生成初始的Large Mobile Model (Latency: 80ms)
- 然后:使用NetAdapt优化初始模型
- 小的移动模型(Small Mobile Model)
- 使用近似帕累托(approximate Pareto-optimal)求最优解
- 在模型(m)的Accuracy与Latency之间取得一个较佳的平衡
- 目标函数
f ( m , w ) = A C C ( m ) × [ L A T ( m ) T A R ] w f(m,w) = ACC(m) \times [ \frac{LAT(m) }{TAR}]^w f(m,w)=ACC(m)×[TARLAT(m)]w- m m m:模型
- A C C ( m ) ACC(m) ACC(m):模型的精确度(model accuracy)
- L A T ( m ) LAT(m) LAT(m):模型的耗时(model latency)
- T A R TAR TAR:模型的目标耗时(target latency)
- w w w:权重因子 (为负数:-0.15)
- 产品需求:准确度越高越好,耗时(延时)越低越好,且不同的耗时对准确度影响不大
- 实现步骤:
- 首先:让 w w w为0初始化种子模型
- 然后:应用NetAdapt和其它优化获得最后的MobileNetV3-Small模型
2.3.5 NetAdapt用于逐层搜索(Layer-wise Search)
- NetAdapt用途
- 在MobileNetV3中作为具有平台感知功能的NAS的补充
- 依次为网络(全局网络架构由NAS负责)的每一层做优化
- 实现步骤
- 第一步:从NAS输出的种子网络结构开始
- 第二步:
- 1、产生一个新的候选集合。每一个侯选都是对架构的一次修改,此修改比上一步的耗时(Latency)至少减少了 δ \delta δ, 设 δ = 0.01 ∣ L ∣ , L \delta = 0.01|L|, L δ=0.01∣L∣,L为种子模型的耗时(Latency)
- 2、对于每一个候选:使用前一步输出的预训练模型进行训练,并输出新的候选;每一个侯选训练 T T T步以获得精确度的初步估计
- 3、根据指定的指标选取最好的候选 (最大化准确度变化与耗时变化的比率)
m e t r i c = Δ A c c ∣ Δ l a t e n c y ∣ metric = \frac {\Delta Acc}{| \Delta latency|} metric=∣Δlatency∣ΔAcc- Δ A c c \Delta Acc ΔAcc:一般为负数,所以 ∣ Δ l a t e n c y ∣ |\Delta latency| ∣Δlatency∣越大,则 m e t r i c metric metric 越大
- 第三步:迭代第二步,直至达到目标耗时(Target Latency)
- 候选类型
- 减少任何扩展层的尺寸
- 减少所有块中的瓶颈(bottleneck),这些瓶颈具有相同的尺寸以支持残差连接
2.3.6 网络改善
- 除了网络搜索之外,MobileNetV3还有以下几方面改进
- 重新设计计算耗时的层(首层和尾层)
- 引入一个新的非线性函数(h-swish):计算速度更快,且更易于量化
2.3.6.1 重新设计耗时的层
- 最后 阶段的优化

- 方法:把AVG Pooling层前移
- 结果:减少了两个计算耗时的卷积层,节约了7ms (11%的计算量、30 Millions MAdds),且准确度没有损失
- 初始阶段的优化
- 现状: 原来的初始阶段使用32个Filters (3x3卷积) ,以用于边缘检测,其结果是这些Filter生成的特征图为相互镜像
- 方法: 减少Filters个数至16个,且使用不同的非线性函数以减少冗余
- 结果:节约了2ms (10 millions MAdds)
2.3.6.2 非线性(激活)函数
- Swish激活函数
- 定义
S w i s h x = f ( x ) = x ⋅ σ ( x ) = x ⋅ S i g m o i d ( x ) = x ⋅ 1 1 + e − x Swish x = f(x) = x \cdot \sigma (x) = x \cdot Sigmoid(x) = x \cdot \frac{1}{1+e^{-x}} Swishx=f(x)=x⋅σ(x)=x⋅Sigmoid(x)=x⋅1+e−x1 - 特性
- 与 ReLU 不同的是,Swish 是平滑且非单调的函数
- Swish 的非单调特性把它与大多数常见的激活函数区别开来
- 结果
- 无上界有下界、非单调且平滑的特性使得它的测试准确度比ReLU高
- 比ReLU慢20%~30%



- 定义
- h-swish激活函数
- 定义
h − s w i s h [ x ] = x ⋅ R e L U 6 ( x + 3 ) 6 = x ⋅ m i n ( m a x ( 0 , x + 3 ) , 6 ) 6 h-swish[x] = x \cdot \frac {ReLU6(x+3)}{6} = x \cdot \frac {min(max(0, x+3),6)}{6} h−swish[x]=x⋅6ReLU6(x+3)=x⋅6min(max(0,x+3),6)- R e L U ( x ) = m a x ( 0 , x ) ReLU(x) = max(0, x) ReLU(x)=max(0,x):相当于无限多个伯努利分布,即无限多个硬币 ,有可能造成激活后的值太大,影响模型的稳定性
- R e L U 6 ( x ) = m i n ( m a x ( 0 , x ) , 6 ) ReLU6(x) = min (max(0,x), 6) ReLU6(x)=min(max(0,x),6):相当于6个伯努利分布,即6个硬币,同时抛出正面的概率,这样鼓励网络学习到稀疏特征,网络里面每一个输出n,相当于n个伯努利分布的叠加,通过实验发现,用6,效果比较好,所以选用了6
- 特性
- 与平滑的swish有较好的匹配

- 与平滑的swish有较好的匹配
- 结果
- 精确度与swish没有明显的差异
- ReLU6在所有的软硬件架构上均可实现
- 在量化模式下,它消除了由于sigmoid函数不同的近似实现引起的数字精度损失
- h-swish可以作为一个分段函数(a piece-wise function)来实现,以减少内存访问的次数,从而显著降低延迟
- 定义
2.3.7 网络模型
- MobileNetV3-Large Model

- MobileNetV3-Small Model

2.3.8 实验结果
2.3.8.1 分类(Classification)


2.3.8.2 检测 (Detection)

2.3.8.3 语义分割 (Semantic Segmentation)

2.4 设计网络设计空间 (DNDS)
- 论文:Designing Network Design Spaces - 2020 (FAIR:Facebook AI Research )
- 代码和预训练模型
- 目标:
- 帮助加深对网络设计的理解,发现可广泛适用于各种设置的设计原则
- 不是设计单个网络实例,而是设计一个可参数化的网络设计空间
- 探索网络结构(如:width, depth, groups等)
- RegNet
- 由简单的常规网络组成的低维设计空间,我们称其为RegNet (Regular Networks)
- RegNet设计空间的核心很简单:每个阶段(stage)的宽度和深度由量化的线性函数决定
- 在移动设备上令人意外地有效
- 核心思想
- RegNet参数化的核心思想:好网络的宽度和深度可以用量化的线性函数来解释
- 结果
- RegNet设计空间提供了简单且快速的网络,可以在各种各样环境下正常工作
- 在GPU上,比EfficientNet快5倍
- 提高了神经网络的有效性以及我们对网络设计的理解
- 专注讨论网络设计规则
- NAS (Neural Architecture Search)
- 优势:给定一个确定的可能的网络搜索空间,NAS在此空间中自动找到一个好的模型
- 不足:搜索的结果是将单个网络实例调整为特定设置(如:硬件平台)
- 为什么叫设计空间(design space),而不是搜索空间(search space)
- 不是在空间中搜索一个网络实例
- 而是在设计空间本身( 规则)
- 发现
- 最好且稳定模型的深度约20 blocks
- 最好的模型不需要瓶颈(bottleneck)或反向瓶颈(inverted bottleneck)
2.4.1 网络设计进化史
- 手动网络设计(Manual Network Design)
- 目标:提高准确性(Accuracy)
- AlexNet
- VGG
- Inception
- ResNet
- ResNeXt
- DenseNet
- MobileNet
- 自动网络设计(Automated Network Design)
- NAS:
- 专注于搜索算法
- 在一个固定且手动设计的搜索空间中,找到一个最好的网络实例
- NAS:
| 方法 | 输入 | 输出 |
|---|---|---|
| NAS | 手动设计的搜索空间 | 网络实例 |
| DNDS | 范例 (paradigm) | 创新的设计空间 |
2.4.2 设计“设计空间” (Design Space Design)
- RegNet特点:
- 简化允许的尺寸和网络配置的类型
- 高性能模型具有更高的水平
- 更易于分析和解释
2.4.2.1 设计空间设计的工具(Tools for Design Space Design)
- error EDF
- 量化设计空间的质量:
- 从设计空间采样并训练 n n n个模型 (训练10 epochs)
- 特征化结果模型的误差经验分布函数
- error empirical distribution function (EDF)
- 直觉:比较分布比搜索(手动或自动)更健壮且信息更丰富
-
n
n
n个模型的error EDF如下:
F ( e ) = 1 n ∑ i = 1 n 1 [ e i < e ] F(e) = \frac{1}{n} \sum_{i=1}^n \mathbf1 [e_i < e] F(e)=n1i=1∑n1[ei<e]- F ( e ) F(e) F(e):表示误差小于 e e e的模型所占的比率
- EDF、网络属性与网络误差关系如下图所示 :

- 量化设计空间质量的步骤:
- 第一步:从设计空间中采样并训练 n n n 个模型, 然后生成模型的分布
- 第二步:计算误差EDF并图形化,以获得设计空间的质量
- 第三步:可视化设计空间的各种属性,并使用empirical bootstrap获得规律
- 第四步:使用这些规律优化设计空间
2.4.2.2 AnyNet设计空间(The AnyNet Design Space)
- 焦点
- 探索神经网络的结构,且神经网络包含标准的、固定的网络块
- 网络结构参数:
- blocks数量(如:网络深度)
- blocks宽度(如:通道数量)
- 其它参数:瓶颈比率、组宽度(group widths)
- 网络结构决定以下因素:
- 参数娄量
- 计算量
- 内存消耗
- 准确度(accuracy)
- 效率(efficiency)
- 设计空间的网络结构
- 输入分辨率默认为:
r
=
224
r = 224
r=224

- 输入分辨率默认为:
r
=
224
r = 224
r=224
- 块(X block)的定义

- w i w_i wi:特征图的通道数
- r i r_i ri:特征图的分辨率
- b i b_i bi:瓶颈比率(bottleneck ratio)(用于确定block内部的特征图数量)
- g i g_i gi: 组宽度(group width)
- AnyNetX设计空间有16个自由度
- 每个网络有4个stage
- 每个stage有4个参数
- blocks的数量 d i d_i di (the number of blocks d i d_i di)
- blocks的通道数 w i w_i wi (block width w i w_i wi)
- 瓶颈比率 b i b_i bi (bottleneck ratio b i b_i bi)
- 组宽度 g i g_i gi (group width g i g_i gi)
- 自由度总数: 4 × 4 = 16 4 \times 4 = 16 4×4=16
- 找到这16个参数的最优设置,就是本文所完成的工作。
- 计算模型配置数量
- 每个stage的参数取值范围:
- d i ≤ 16 d_i \le 16 di≤16
- w i ≤ 1024 w_i \le 1024 wi≤1024,可以被8整除
- b i ∈ { 1 , 2 , 4 } b_i \in \{1,2,4\} bi∈{1,2,4}
- g i ∈ { 1 , 2 , 4 , 8 , 16 , 32 } g_i \in \{1,2,4,8,16,32 \} gi∈{1,2,4,8,16,32}
- 配置总数= ( 16 × 128 × 3 × 6 ) 4 ≈ 1 0 18 (16 \times 128 \times 3 \times 6)^4 \approx 10^{18} (16×128×3×6)4≈1018
- AnyNetX进化史
- 每个stage的参数取值范围:
| 序号 | 名称 | 来源 | 自由度及解空间 | 结果 |
|---|---|---|---|---|
| 1 | A n y N e t X A AnyNetX_A AnyNetXA | 参数没有任何约束 | 16/ 1.8 × 1 0 18 1.8 \times10^{18} 1.8×1018 | 初始解空间 |
| 2 | A n y N e t X B AnyNetX_B AnyNetXB | 在 A n y N e t X A AnyNetX_A AnyNetXA的基础上,所有stage i i i共享 b i = b b_i=b bi=b | 13/ 6.8 × 1 0 16 6.8 \times10^{16} 6.8×1016 | 共享bottleneck ratio时,模型的精度没有损失 |
| 3 | A n y N e t X C AnyNetX_C AnyNetXC | 在 A n y N e t X B AnyNetX_B AnyNetXB的基础上,所有stage i i i共享 g i = g g_i=g gi=g | 10/ 3.2 × 1 0 14 3.2 \times10^{14} 3.2×1014 | 共享group width时,模型的精度没有损失 |
| 4 | A n y N e t X D AnyNetX_D AnyNetXD | A n y N e t X D = A n y N e t X C + w i + 1 ≥ w i AnyNetX_D=AnyNetX_C + w_{i+1} \ge w_i AnyNetXD=AnyNetXC+wi+1≥wi | 10/ 1.3 × 1 0 13 1.3 \times10^{13} 1.3×1013 | 每个stage递增widths(通道数),性能提升 |
| 5 | A n y N e t X E AnyNetX_E AnyNetXE | A n y N e t X E = A n y N e t X D + d i + 1 ≥ d i AnyNetX_E=AnyNetX_D + d_{i+1} \ge d_i AnyNetXE=AnyNetXD+di+1≥di | 10/ 5.5 × 1 0 11 5.5 \times10^{11} 5.5×1011 | 每个stage递增depths(网络深度),性能提升 |


- 网络设计目标
- 简化设计空间的结构
- 改善设计空间的可解释性
- 改善设计空间的质量
- 保持设计空间的多样性
2.4.2.3 RegNet设计空间
-
符号说明
- i i i:表示第 i i i个stage
- j j j:表示第 j j j个block
-
块通道数(block widths)的线性参数化
u j = w 0 + w a ⋅ j , f o r 0 ≤ j < d ( 2 ) u_j = w_0 + w_a \cdot j, \quad for \quad 0 \leq j \lt d \quad \quad (2) uj=w0+wa⋅j,for0≤j<d(2)- u j u_j uj: b l o c k j block_j blockj的width(通道数), j < d j<d j<d
- d d d:深度
- w 0 w_0 w0:初始width(通道数), w 0 > 0 w_0 > 0 w0>0
- w a w_a wa:斜率, w a > 0 w_a > 0 wa>0
-
为每个 b l o c k j block_j blockj计算 s j s_j sj:为量化 u j u_j uj,引入参数 w m w_m wm以控制量化
u j = w 0 ⋅ w m s j , w m > 0 ( 3 ) u_j = w_0 \cdot w_m^{s_j}, \quad w_m > 0 \quad \quad (3) uj=w0⋅wmsj,wm>0(3) -
计算每一个block的量化widths w j w_j wj(通道数):为量化 u j u_j uj,对 s j s_j sj取整 ⌊ s j ⌉ \lfloor s_j \rceil ⌊sj⌉
w j = w 0 ⋅ w m ⌊ s j ⌉ , ( 4 ) w_j = w_0 \cdot w_m^{\lfloor s_j \rceil}, \quad \quad (4) wj=w0⋅wm⌊sj⌉,(4) -
计算stage i i i中的block的width w i w_i wi (通道数)
w i = w 0 ⋅ w m i w_i = w_0 \cdot w_m^i wi=w0⋅wmi -
计算stage i i i中的block的数量 d i d_i di (通道数)
d i = ∑ j 1 [ ⌊ s j ⌉ = i ] d_i = \sum_j \mathbf 1 [\lfloor s_j \rceil = i] di=j∑1[⌊sj⌉=i] -
RegNetX设计空间
- 有6个参数: d , w 0 , w a , w m , b , g d, w_0, w_a, w_m, b, g d,w0,wa,wm,b,g
- 根据方程(2)-(4)计算block的depths(深度)和每个block的widths(通道数)
- RegNet包含简单、规则的模型
- 参数范围:
- d < 64 , w 0 , w a < 256 , 1.5 ≤ w m ≤ 3 d \lt 64, w_0,\quad w_a \lt 256,\quad 1.5 \le w_m \le 3 d<64,w0,wa<256,1.5≤wm≤3
- b i ∈ { 1 , 2 , 4 } , g i ∈ { 1 , 2 , 4 , 8 , 16 , 32 } b_i \in \{1,2,4\},\quad g_i \in \{1,2,4,8,16,32 \} bi∈{1,2,4},gi∈{1,2,4,8,16,32}$
-
RegNetX的误差EDF
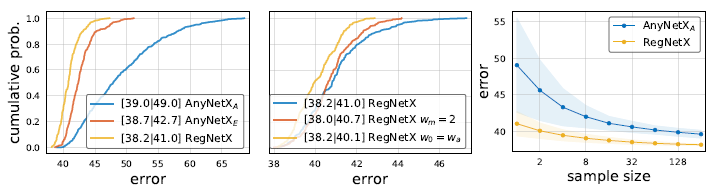
- 根据上图的Sample size, 搜索32个随机模型就可能产生一个好的模型
-
设计空间对比

2.4.3 在移动设备上的性能比较

3. 基于深度图的位姿估计
- 基于深度图像的位姿估计的优势:
- 受光照影响小(超强光除外)
- 没有尺度(scale)疑问
- 颜色和纹理不变性
- 解决了轮廓模糊性问题
- 大大简化了背景去除问题
3.1 数据集
| 论文 | 方法 | 代码 | 数据集 |
|---|---|---|---|
| Efficient Human Pose Estimation from Single Depth Images (第三方实现) | Random Tree Walks(RTW) | code | CAD-60 |
| Efficient Human Pose Estimation from Single Depth Images (第三方实现) | Offset-Joint Regression (OJR) | code | CAD-60 |
| Human3.6M | |||
| Efficient Human Pose Estimation from Single Depth Images 2012 MSRA | BPC & OJR | CMU mocap database | |
3.2 基于单深度图的有效人体姿态估计
- 论文:Efficient Human Pose Estimation from Single Depth Images (2012)
- 作者单位:Microsoft Research, Cambridge, in collaboration with Xbox
- 目标:鲁棒性和计算效率
- 两种实现方法 :
- 身体部位分类(BPC:Body Part Classification)
- 偏移关节回归(OJR:Offset Joint Regression)
- 原理:
- BPC和OJR都使用有效的决策森林,该决策森林应用于图像中的每个像素
- 分别评估每个像素对每个关节的贡献可避免对身体关节进行任何组合搜索
- 通过评估每个像素处的滑动窗口决策森林,为人体关节的位置投票
- 决策森林使用简单但有区别的深度比较图像特征(depth comparison image features),这些特征可提供3D平移不变性,同时保持较高的计算效率。

3.2.1 数据
- 使用真实人类演员的基于标记的运动捕捉来获取基准位姿数据(ground truth pose data)
- 数据量:500K frames
- 动作:驾驶,跳舞,踢脚,跑步
- MoCap: Motion Capture
- 数据采集方式:采用MoCap采集的真实数据和合成数据
3.2.2 实现方案
3.2.2.1 深度图像特征(Depth image features)
- 特征:将深度图像上邻近区域内像素对的深度差值作为部位特征,来区分身体的不同部位
- 单个特征虽然只能提供微弱的判别信号,但是结合随机森林和大量的样本数据,这些特征有足够的表征能力去判断当前像素属于哪一个身体部位。而且这种特征计算方式简单,很容易在计算机上并行实现。
- 像素
u
u
u的特征响应:
f ( u ∣ ϕ ) = z ( u + δ 1 z ( u ) ) − z ( u + δ 2 z ( u ) ) ( 3 ) f(\mathbf u | \phi) = z(\mathbf u+\frac{\mathbf \delta_1}{z(\mathbf u)}) - z(\mathbf u+\frac{\delta_2}{z(\mathbf u)}) \quad\quad (3) f(u∣ϕ)=z(u+z(u)δ1)−z(u+z(u)δ2)(3)- ϕ = ( δ 1 , δ 2 ) \phi=(\delta_1, \delta_2) ϕ=(δ1,δ2):特征参数,用于描述2D像素的偏移量(offsets) δ \delta δ,在训练树结构期间,在固定大小的盒子内随机采样偏移量 δ \delta δ
- 函数 z ( u ) z(u) z(u):在指定图像中查询像素 u = ( u , v ) T \mathbf u=(u, v)^T u=(u,v)T的深度值
-
1
z
(
u
)
\frac{1}{z(\mathbf u)}
z(u)1作用:归一化(对于身体上给定的一个像素点,无论该像素点的深度值是大还是小,都能保证深度差值在一定范围内),保证了深度特征的不变性。因此,这些特征具有三维空间中的平移不变性。如果像素位于人体背景或者图像范围外,深度值设为无穷大。

3.2.2.2 随机森林( Randomized forests)

-
随机森林里每一棵树都是一个分类器,包含分支节点和叶子节点
-
每个分支节点(split node)都包含一个弱的学习器(weak learner),此学习器通过参数 θ = ( ϕ , τ ) \theta=(\phi, \tau) θ=(ϕ,τ)表示
-
2D偏移量 ϕ = ( δ 1 , δ 2 ) \phi = (\delta_1, \delta_2) ϕ=(δ1,δ2):用于特征评估
-
τ \tau τ:是一个标量阈值、
-
Weak Learner函数:
h ( u ; θ n ) = [ f ( u ; ϕ n ) ≥ τ n ] ( 4 ) h(\mathbf u; \theta_n) = [ f(\mathbf u; \phi_n) \ge \tau_n] \quad \quad (4) h(u;θn)=[f(u;ϕn)≥τn](4) -
对于深度图像上的某一像素 u \mathbf u u,首先根据公式(2-3),计算出当前的特征,然后比较 f ( u ∣ ϕ ) f(\mathbf u | \phi) f(u∣ϕ)与阈值 τ \tau τ的大小,来决定将当前节点更新到左边还是右边的孩子节点,这个过程一直持续到叶子节点,叶子节点中存储了训练学习到的当前像素分布在身体部位的概率分布 P ( c ∣ I , u ) P( c |I, \mathbf u) P(c∣I,u)
-
当随机决策森林中每一颗树(每一个分类器)都计算出当前像素身体部位的概率,通过以下公式来计算像素 u \mathbf u u的最终部位概率
P ( c ∣ I , u ) = 1 T ∑ t = 1 T P t ( c ∣ I , u ) P( c |I, \mathbf u) = \frac{1}{T} \sum_{t=1}^T P_t( c |I, \mathbf u) P(c∣I,u)=T1t=1∑TPt(c∣I,u) -
训练过程:将全部训练样本分为k 个样本集合,每一个集合对应一个树形分类器,这些分类器共同组成了随机森林
-
推断过程:对于一个测试样本,计算特征后,输入到随机森林中,统计森林中每一棵树的结果,最终通过投票来对当前样本进行分类
3.2.2.3 叶节点预测模型(Leaf node prediction models)
3.2.2.4 汇总预测(Aggregating predictions)
3.3 基于推理嵌入多任务学习的深度图像人体姿态估计
-
论文:Human Pose Estimation from Depth Images via Inference Embedded Multi-task Learning (2016)
-
作者单位:中山大学
-
目标:解决Kinect V2 (Shotten)不能识别的一些动作以及遮挡问题
-
贡献:
- 100K深度图像数据集(包含各种动作) Kinect2 Human Pose Dataset (K2HPD)
- 19个关节
- 30个测试人员
- 每个人10种不同的场景动作,包括经常性动作和很少做的动作
- 基于深度学习,实现了从静止深度图像预测人体关节的最新性能
- 动态规划推理与深度神经网络的集成是独创的
- 100K深度图像数据集(包含各种动作) Kinect2 Human Pose Dataset (K2HPD)
-
基于RGB与Depth图像的位姿估计差异:
- 深度图像包含传感器噪声且外观细节粗糙
- 第一步:生成关节部位的热图 heat (confidence) maps (CNN->提取特征)
- 第二步:基于生成的候选身体部位预测人体关节
3.3.1 框架
- 由于深度图像的分辨率低和不连续,因此生成的身体部位建议包括许多错误
- 把身体部位建议输入到内置推理MatchNet,以寻求最佳的身体关节位置
- MatchNet(基于Patch匹配)的用途:
- 测量身体部位建议与标准模板间的一元外观兼容性
- 在3-D坐标中测量两个身体部位的几何一致性 (可以解决旋转问题吗?)
- 给定所有优化参数,从基于树的动力学结构的叶节点(手或脚)到根节点(head)的顺序计算最优值

3.3.2 网络结构
3.3.2.1 全连接网络 (FCN: Fully Convolutional Network)
- FCN的输出:HeatMap (Confidence Map)
- 热图中每个像素的值:表示此像素属于身体部位的可能性(likelihood)
- 热图中局部最大值的坐标为第
k
k
k(总共有K个)个身体部位的中心位置
k = [ 1 , . . . , K ] k = [1, ..., K] k=[1,...,K]
( x k ∗ , y k ∗ ) = max x k , y k z ( k ∣ I ; θ c ) (x_k^*, y_k^*) = \max_{x_k, y_k} z(k|I; \theta_c) (xk∗,yk∗)=xk,ykmaxz(k∣I;θc)- θ c \theta_c θc:深度网络的参数
- I I I:输入深度图像
- z ( k ∣ I ; θ c ) z(k|I; \theta_c) z(k∣I;θc):输出的热图
- 第
k
k
k个候选的身体部位表示为
b i k = [ x i , y i , w i , h i , k ] b_i^k = [x_i, y_i, wi, hi, k] bik=[xi,yi,wi,hi,k]- ( x i , y i ) (x_i,y_i) (xi,yi):第 k k k个候选区域的中心位置
- w i , h i w_i, h_i wi,hi:第 k k k个候选区域的宽度和高度

3.3.2.2 用于推理的内置MatchNet (Inference Built-in MatchNet)
- 内置推理由外观匹配和相邻关节的几何匹配组成
-
b
i
k
b_i^k
bik是第
k
k
k个关节的得分
F ( g ^ ∣ I ) = ∑ k = 1 K U ( b i k ∣ I ) + ∑ m ∈ Ω k R ( b i k , b j m ∣ I ) F(\hat g | I) = \sum_{k=1}^K U(b_i^k | I) + \sum_{m \in \Omega_k} R(b_i^k, b_j^m|I) F(g^∣I)=k=1∑KU(bik∣I)+m∈Ωk∑R(bik,bjm∣I)- i , j ∈ 1 , . . . , n i,j \in {1,...,n} i,j∈1,...,n
- n n n:身体部位候选总数
- I I I:指有 K K K个身体部位的输入深度图像
- U ( b i k ∣ I ) U(b_i^k | I) U(bik∣I):身体部位 k k k位于第 i i i个候选区域的中心
- R ( b i k , b j m ∣ I ) R(b_i^k, b_j^m|I) R(bik,bjm∣I):第 k k k个与第 m m m个身体部位间的几何关系, m m m属于 k k k的邻居
- m ∈ Ω k m \in \Omega_k m∈Ωk: k k k的邻居的集合
- g ^ \hat g g^:超参
- 外观匹配( appearance similarity) 以获得外观证据(一元项)
- 运动约束(3D kinematic constraint) 以满足人的结构特征(二元素项)
- 结构推断以最大化得分函数F
max g ^ w ⋅ F ( g ^ ∣ I ) \max_{\hat g} w \cdot F(\hat g | I) g^maxw⋅F(g^∣I)- 为简单起见,
w
w
w表示推理内置MatchNet的所有参数


- 为简单起见,
w
w
w表示推理内置MatchNet的所有参数
3.3.2.3 训练
- 训练FCN以获取热图
- 目标函数
min θ c ∑ l = 1 N ∑ k = 1 K ∣ ∣ z ( k , ∣ I l ; θ c ) − H ( g k ∣ I l ) ∣ ∣ 2 2 ( 6 ) \min_{\theta_c} \sum_{l=1}^N \sum_{k=1}^K || z(k,|I_l;\theta_c) - H(g_k|I_l) ||_2^2 \quad \quad (6) θcminl=1∑Nk=1∑K∣∣z(k,∣Il;θc)−H(gk∣Il)∣∣22(6)- H:Ground Truth的高斯分布,取一个小的方差,均值为关节位置
- N N N:学习样本个数
- K K K:每个样本关节数
- I l I_l Il:一个学习样本
- g l g_l gl:第 l l l个样本的ground truth值
- 测量两个概率分布的相似性
- 目标函数
- 外观匹配 ( appearance similarity)
- 目标函数(交叉熵)

- 目标函数(交叉熵)
- 结构化推断(Structural Inference)
- 目标函数 (学习参数
w
w
w)

- 目标函数 (学习参数
w
w
w)
- 算法描述

3.3.2.4 实验结果

- 实验环境及性能
- Intel 3.4 GHz and a NVIDIA GTX-980Ti GPU

- Intel 3.4 GHz and a NVIDIA GTX-980Ti GPU
3.4 基于单个深度图的实时3D位置估计
- 论文:Real-time 3D Pose Estimation from Single Depth Images (2019)
- 作者:Honda Research Institute Europe GmbH
- 目标:
- 移动机器人上可运行
- 基于CNN的二维姿态估计结构优化,以获取高帧率
- 贡献
- 提出了大幅度减小参数和提高速度的优化步骤
- 扩展结构直接进行3D位姿估计
- 数据集
3.4.1 方法
3.4.1.1 第一阶段(估计2D位置)
- 使用SSHG(Slim Stacked Hourglass CNN) 2D 生成2D关节 Heatmap (置信度图)
- 2D置信度图
H
j
H_j
Hj
H j ∈ R 64 × 64 H_j \in \mathbb R^{64 \times 64} Hj∈R64×64 - 每个关节
j
j
j
j ∈ { 1... J } j \in \{1 ... J\} j∈{1...J} - 通过计算置信度图的权重中心,获得每个关节的2D位置
p
j
2
D
\mathbf p_j^{2D}
pj2D
p j 2 D = { x j , y j } \mathbf p_j^{2D} = \{x_j, y_j \} pj2D={xj,yj}
- 2D置信度图
H
j
H_j
Hj
3.4.1.2 第二阶段(估计3D位置)
- 使用精细的深度图(refined depth map)用于估计3D关节位姿
- 与输入的深度图像相比,精细的深度图可提供更高的精度
- 原始深度图
D
j
\mathbf D_j
Dj,关节的深度值
d
j
d_j
dj
d j = D j , x j , y j d_j= \mathbf D_{j, x_j, y_j} dj=Dj,xj,yj - 关节位置(摄像机坐标系):
{ x j , y j , d j } \{ x_j, y_j, d_j \} {xj,yj,dj} - 关节位置(世界坐标系),使用投影矩阵
M
(
x
j
,
y
j
,
d
j
,
C
M
)
,
C
M
:
摄
像
机
矩
阵
\mathbf M(x_j, y_j, d_j, CM),CM:摄像机矩阵
M(xj,yj,dj,CM),CM:摄像机矩阵:
p j 3 D = { x j w , y j w , z j w } \mathbf p_j^{3D} = \{x_j^w, y_j^w, z_j^w\} pj3D={xjw,yjw,zjw}
3.4.1.3 实现流程

3.4.2 Slim Hourglass Block (SHB) for Faster Inference
- 通过多分辨率计算特征,然后依次组合在一起,堆叠式沙漏实质上是一个递归的多分辨率残差模块
- SHB不仅保留了相当好的细节信息,而且有大的感知域(large receptive field)
- 用于生成关节heatmap
- 首先检测头
- 不足
- 左右经常出错
- 估计多人位姿效果不佳 (不能处理两人靠得近或重叠的情况)
- 不能处理遮挡问题
- 关节不可见,但明显可推出,如手放在背后
- 无信息可推出关节位置,如下半身不见

3.4.3 用于人体姿势估计的堆叠沙漏网络
- 论文:Stacked Hourglass Networks for Human Pose Estimation (2016)
- 作者:University of Michigan, Ann Arbor
- 创新点:
- 处理多尺度
- 捕获最好的人体空间关系
- 将重复的自下而上(bottom-up),自上而下(top-down)的处理与中间监督一起使用,以改善网络的性能
- 基于stacked hourglass网络, 连续使用pooling和upsampling产生最后的预测
- 网络结构

3.4.3.1 相关工作
- DeepPose (by Toshev)
- 第一个从传统方法迁移到深度网络
- 使用网络直接回归关节的(x,y)坐标
- 使用ConvNet和图模型
- 使用图模型学习关节的空间位置关系
- Joint training of a convolutional network and a graphical model for human pose estimation. (Tompson)
- 通过捕获不同尺度(分辨率)的特征,然后生成heatmaps
- 通过级联来优化预测,提升了效率和减少了内存的使用
- SHB
- 在不同的尺度上捕获特征
- 把不同分辨率的特征组合起来
- 不使用图模型和明显的人体模型
- 基于RGB图像,实现单个人的关节定位
- bottom-up处理:从高分辨率到低分辨率
- top-down处理:从低分辨率到高分辨率
3.4.3.2 网络结构
- Hourglass设计
- 技术洞见:捕获每个尺度的信息
- 局部特征:用于识别脸和手的局部特征是必须的,最后的位置估计需要理解整个身体
- 人的方位、四肢的排列和相邻关节的关系是在图像中不同尺度下最容易识别的线索
- 沙漏(Hourglass)是一个简单,最小的设计,有能力捕捉所有这些特征,并将它们结合起来,输出像素级的预测
- 网络必须高效处理和融合不同尺度的特征
- 网络的输出是一组热图,其中对于给定的热图,网络预测每个像素处存在关节的概率
- 层实现
- 在保持Hourglass形状的前提下,层的实现具有很多灵活性
- 本设计大量使用残差网络
- 本设计的Filter不大于3x3
- 输入分辨率:256x256
- 最大输出分辨率:64x64
- 所有残差模块输出256个特征
- 残差网络和中间监督

3.4.3.3 具有中间监督的堆叠沙漏
- 上 一个沙漏的输出作为下一个沙漏的输出
- 本网络提供了重复的高到低、低到高分辨率的推断机制,此机制允许在整个图像中重新评估初始估计和特征
- 本方案的关键是中间热图的预测,基于此预测可计算其损失
- 每经过一个沙漏产生一个预测,且网络有处理局部和全局特征的机会;下一个沙漏再次处理这些高级特征,以进一步评估更高阶的空间关系
- 这种在尺度之间来回移动的方法特别重要,因为保持特征的空间位置对于最终定位至关重要
- 对于位姿估计这类结构化问题,输出是不同特征的相互作用,这些特征应该组合在一起形成对场景的一致性理解
- 我们通过使用1x1卷积将中间预测映射到更多的通道,将它们重新整合到特征空间
- 不同的沙漏使用不同的权重
- 使用相同的ground truth计算每一个沙漏预测的损失
3.4.3.4 训练细节
- 此方法在FLIC(5003个图像: 3987个训练+1016个测试)和MPII(25K个图像:28K训练+11K测试)两个benchmark数据集中进行了测试
- 在给定的输入图像中,通常有多个人可见,但如果没有图形模型或其他后处理步骤,图像必须传达所有必要的信息,以便网络确定哪个人对应标注信息;通过训练网络专门标注直接中心的人来解决此问题
- 数据扩增:旋转:+/-30度,缩放:0.75/1.25
- 优化方法:RMSProp + 学习率(2.5e-4)
- 损失函数(监督方法):Mean-Squared Error (MSE)用于比较预测的热图与ground-truth热图
- 训练设备:一个12 GB NVIDIA TitanX GPU
- 训练时长:3天
- 调整学习率:在验证准确性稳定后,将学习率降低5倍
- 前向预测计算需要:75ms
- 为计算最后的预测值,把原图和翻转之后的图像分别通过网络计算其热图,然后取两个热图的平均值
- 一个关节在网络中的预测值为热图中的最大激活位置
3.4.3.5 实验结果
- 评价指标:关键点正确估计的比例(PCK: Percentage of Correct Keypoints)
- 计算检测的关键点与其对应的groundtruth间的归一化距离小于设定阈值的比例
- FLIC:以躯干尺寸(torso size) 作为归一化参考.
- MPII:以头部长度(head length) 作为归一化参考,即 PCKh
- 在FLIC数据上的测试结果

- 在MPII数据集上的测试结果

3.4.3.6 不同网络的训练过程
- HG不同但残差模块数相同,其训练性能差异不大
- HG (a single long hourlglass):一个HG包含8个残差模块
- HG-Stacked (without Intermediate supervision):两个HG, 每个HG包含4个残差模块
- 有无中间监督的比较
- 有中间监督的效果更佳

3.5 基于RGB-D的地面检测
3.5.1 基于RGB-D的新型地面检测方法
- 论文:A Novel Ground Plane Detection Method Using an RGB-D Sensor(2019)
- 作者:杭州河海大学机电工程学院
- 目标:
- 在不同的场景下生成精确的地面
- 使用占用栅格地图检测地平面
- 步骤
- 数据预处理
- 构造栅格占用地图
- 地面分割
- RGB-D在以下环境下表现不好
- 强光照射
- 透明物体
- 反射
- 吸收红外线的表面
3.5.1.1 数据预处理
- 目的:解决深度图像中的噪声和黑洞, 参考代码
- 滤波方法:weight median filter (WM)
- 行填充(row filling)

- 权重中值填充 (weight median filling)
w = e ( − ( ( u − u 0 ) 2 + ( v − v 0 ) 2 ) s i g _ w n d − ( d e p t h − d e p t h 0 ) 2 s i g _ d i s ) w= e^{(-\frac{((u-u_0)^2 + (v-v_0)^2)}{sig\_wnd} - \frac{(depth-depth_0)^2}{sig\_dis})} w=e(−sig_wnd((u−u0)2+(v−v0)2)−sig_dis(depth−depth0)2)- s i g _ w n d sig\_wnd sig_wnd:表示窗口尺寸的一半
- s i g _ d i s sig\_dis sig_dis:常量
- ( u 0 , v 0 ) (u_0, v_0) (u0,v0):窗口的中心
- 行填充(row filling)
3.5.1.2 图像坐标系变换为世界坐标系
- 把深度图转换为点云图
{ x k = i k − c x f x z k y k = j k − c y f y z k z k = z k⎩⎪⎨⎪⎧xk=fxik−cxzkyk=fyjk−cyzkzk=zk⎧⎩⎨⎪⎪⎪⎪⎪⎪xk=ik−cxfxzkyk=jk−cyfyzkzk=zk - z k z_k zk:深度图中 ( i k , j k ) (i_k, j_k) (ik,jk)的深度值
- ( c x , c y ) (c_x, c_y) (cx,cy):图像的中心坐标,以像素为单位
- ( f x , f y ) (f_x, f_y) (fx,fy):表示摄像机的焦距
- 相机内参:确定摄像机从三维空间到二维图像的投影关系(比如相机的焦距、像素大小)
- 相机外参:决定摄像机坐标与世界坐标系之间相对位置关系(比如相机的位置、旋转方向)
P c = R P w + T P_c = RP_w + T Pc=RPw+T- T = ( t x , t y , t z ) T T= (t_x, t_y, t_z)^T T=(tx,ty,tz)T:是平移向量
- R = R ( α , β , γ ) R = R(\alpha, \beta, \gamma) R=R(α,β,γ):是旋转矩阵
3.5.1.3 地面检测算法
- 地面检测算法包含以下三步:
- 构造栅格占用地图
- 地面拟合
- 地面分割

- 构造栅格占用地图
- 使用二进制Bayes Filter更新栅格占用地图
- 栅格占用计算方法

- 分割地面
- 使用Jann Poppinga方法计算地面的法向量
- 假设地面的点集为: r i = ( x i , y i , z i ) T , i = 1 , . . . , k r_i = (x_i, y_i, z_i)^T, i = 1, ..., k ri=(xi,yi,zi)T,i=1,...,k
- 计算地面上点集的法向量 (求特征值):
数 据 集 的 熏 心 : r G = 1 k ∑ i = 1 k r i 数据集的熏心:r_G = \frac{1}{k} \sum_{i=1}^k r_i 数据集的熏心:rG=k1i=1∑kri
M k = ∑ i = 1 k ( r i − r G ) ( r i − r G ) T M_k = \sum_{i=1}^k (r_i-r_G)(r_i - r_G)^T Mk=i=1∑k(ri−rG)(ri−rG)T- 最小的特征值对应的特征向量即为地面的法向量
3.5.1.4 实验结果
- 权重中值(WM)滤波

- 不同场景下的检测结果

- detect1:表示基于occupancy滤波之后的点
- detect2:表示基于距离滤波之后的点
- origin:表示原始位于地面上的点
3.5.1.5 结论
- 把3D点云数据转换为2D栅格占用地图,与PCL相比,减少了很多计算量
- 可检测出地面上95%的点
- 可检测出准确的地面
- 计算高效且鲁棒性好
3.5.2 基于RGB-D Sensor的地面检测
- 论文:Ground Plane Detection Using an RGB-D Sensor (2014)
- 作者:Robotics and Autonomous Vehicles Laboratory
3.5.2.1 提供的解决方案
- 通过指数曲线拟合地面模型
- 解决方案一:
- 简单且健状的
- 前提条件:
- 俯仰角(Pitch)不变
- 没有翻滚(Roll)
- 解决方案二:
- 俯仰角(Pitch)动态变化
- 翻滚(Roll)角度动态变化
- 效果:
- 优于垂直视差法(vertical disparity approach)
- 在复杂场景(包括许多障碍物、不同的地板表面、楼梯和狭窄的走廊)下,生成精确的地平面以割障碍物分
3.5.2.2 俯仰角(Pitch)不变场景下检测地平面
- 应用场景
- 俯仰角(Pitch)不变
- 翻滚角(Roll)为0 (此条件要求较高,且为此算法的必要条件)
- 算法的基础洞见
- 在单位长度范围内,距摄像机越近,像素数越多
- 线性距离投影到深度图时变成了有理函数
- 对于深度图像的任何一列,深度值非线性地增加
- 只有地面上点的深度值,在所有列是相等的(是Roll角为0作为基础)
- 地面的深度图的任何一列的深度值可表示为:
f ( x ) = a e b x + c e d x f(x) = ae^{bx} + ce^{dx} f(x)=aebx+cedx- f ( x ) f(x) f(x):像素的深度值
- x x x:像素所在的行
- 系数 ( a , b , c , d ) (a,b,c,d) (a,b,c,d):由深度相机内参、俯仰角和深度相机的安装高度决定,通过最小二乘法求得这4个系数
- 根据上面的方程即可得到参考曲线( C R C_R CR : reference ground plane curve)
- 把所得的深度图像与此 C R C_R CR相比,即可获得地平面像素和障碍物像素
- 不同的俯仰角(Pitch Angle)创建不同的投影和不同的 C R C_R CR曲线,如下图中的(e)
- 一帧 只有一个
C
R
C_R
CR

3.5.2.3 俯仰角(Pitch)和翻滚角(Roll)变化场景下检测地平面
-
移动机器人属于此种场景
-
此场景可通过IMU来进行校正
-
本方法不使用IMU,仍然通过估计 C R C_R CR的方法实现
-
由于Roll角不为0,所以深度图像不同的列具有不同的 C R C_R CR
- 俯仰角越大(), C R C_R CR曲线的斜率越大
- 在深度图的一端显示出高俯仰角的曲线,而在另一端我们观察到低俯仰角的曲线
- 这使得使用单一 C R C_R CR变得复杂化
-
Roll角不为0的解决方案
- 旋转深度图,使其与地平面正交
- 如果传感器与地平面正交,则应沿每条水平线(即行)产生相等或非常相似的深度值
- 此相似性可以简单地通过计算行的直方图来捕获,即较高的直方图峰值表示此行上更相似的深度值
-
深度图像的旋转角度 θ ∗ {\theta}^* θ∗表示如下:
θ ∗ = arg max θ ( ∑ i = 1 R arg max i ( h r ( i , D θ ) ) \theta^* = \argmax_{\theta} (\sum_{i=1}^R \argmax_i(h_r(i, D_{\theta}) ) θ∗=θargmax(i=1∑Riargmax(hr(i,Dθ))- 角度 θ \theta θ:属于预定义集中的一个,如 { − 30 , − 20 , − 10 , 0 , 10 , 20 , 30 } {-30, -20,-10, 0, 10, 20, 30 } {−30,−20,−10,0,10,20,30}
- h r h_r hr:表示深度图 D D D(共有 R R R行)第 r r r行的直方图
- 深度图翻滚角度 θ \theta θ和直方图 h r h_r hr基于每一行进行计算,求使直方图峰值之和最大的翻滚角 θ \theta θ
- 计算一个
θ
\theta
θ直方图峰值步骤:
- 第一步:从角度集合中取一个元素 θ \theta θ
- 第二步:把深度图像旋转 θ \theta θ角度
- 第三步:对旋转之后深度图,计算每一行(即 r r r行)的直方图 h r h_r hr
- 第四步:把所有行的直方图相加,得到一个新的直方图,则取求和直方图的峰值作为与此角度 θ \theta θ对应的估计值
- 对于集合中的每个 θ \theta θ(设共有n个)计算一次,便可获取n个求和直方图的峰值,然后从这n个求和直方图的峰值中选择一个最大的,最后把与此对应的 θ \theta θ作为深度图像的旋转角度
- 通过此种方法去除了翻滚角的影响
-
分割步骤
- 旋转深度图像 θ ∗ \theta^* θ∗ 角度
- 使用3.5.2.2中的方法计算 C R C_R CR (地平面估计曲线)
- 每一列与参考曲线 C R C_R CR进行比较,然后通过阈值 T T T再次进行比较以确定哪些像素属于地平面,哪些不属于地平面
-
当场景中有障碍物时,如何估计地面的曲线?
- 除非障碍物覆盖了整行,否则深度图一行的直方图最大值一定是地面
- 障碍物比它遮挡的地面更靠近深度相机
- 深度包络(E:depth envelope):每一行的最大值 (注:不是直方图的最大值)
E ( r ) = max i ( D ( c i , r ) ) E(r) = \max_i (D(c_i, r)) E(r)=imax(D(ci,r))- c i c_i ci:表示第 i i i列
- D ( c i , r ) D(c_i, r) D(ci,r):表示第 r r r行的第 i i i个像素
- 在进行曲线拟合之前,需进行中值滤波以平滑深度包络(depth envelope)
- 当场景以墙面或一组障碍物结束时,在深度包络中将出一个平台(plateau);从右到左扫描包络线(E),并且由于最高峰值之后的值不能是地平面的一部分,因此不进行拟合
-
影响地面曲线拟合的不利因素
- 当一个或多个物体覆盖整行时,深度图中将产生一个平台;如果“整行覆盖对象或组”的行不构成图像中的最高平台,则地平面在平台之后继续,并且对象不会影响曲线估计
- 任何下降(drop-offs)处(如孔、楼梯)的深度值都比地平面高,下降在深度包络中导致突然的升高(如一座小山),如果在深度包络中存在小山,则估计的指数曲线将产生更大的拟合误差
- 解决方案:
- 为了确保在深度包络上中可见的对象上不进行拟合,将应用排除规则
- 只要地平面继续,从场景底部向上的深度值会一直增加,最大深度值之后的深度值从深度包络的左边被丢弃,如下图所示:

- 如果场景中存在行覆盖对象,则可以在深度包络中将其视为不连续。为了检测行覆盖物,采用深度包络的一阶导数,然后搜索一个负峰,紧跟着是一个正峰,表示行覆盖对象,一阶导数如下图所示

- 在如上两个峰值(一正一负)间的行被排除掉,如下图所示

3.5.2.4 实验结果

3.6 基于单个深度图精确位姿估计
- 论文:Accurate 3D Pose Estimation From a Single Depth Image (2011)
- 作者:肯塔基大学
- 思路:
- 包括位姿检测和位姿优化两个阶段
- 把深度图与一组预先捕获的运动样本相匹配,以生成姿态估计
- 创新点
- 点云平滑技术 (降噪)
- 点云对齐和位姿搜索算法与视角无关
3.7 基于超像素聚类人体姿态识别 (深度图)
- 创新点:
- 基于部位聚类特征点设计的人体姿态特征也能够很好的表征不同的人体姿态
- 相比于基于关节点构造的人体姿态特征,免去了训练回归模型从聚类特征点回归到关节点的步骤,减少了计算量,提高了效率
- 主要流程
- 提取人体特征(部位聚类特征点)
- 学习人体特征与人体骨骼的映射(求解人体的部位聚类特征点与关节点之间的映射矩阵)
- 成功指标
- 精度
- 召回率
3.7.1 深度图像中的人体特征点提取
-
将深度图像数据剔除背景、去除噪声
-
利用深度相机参数将深度图像数据转换为点云数据
-
使用SLIC 超像素思想处理点云数据,得到稀疏点云数据后,构建人体连通图
-
利用测地距离确定人体肢端点,然后根据肢端点将人体分为几个部位
-
最后在每一个部位内进行k-means 聚类,将聚类中心点作为人体的特征点
-
k-means聚类:
- 一定要在聚类前需要手工指定要分成几类,K-Means 聚类算法的大致逻辑就是“物以类聚,人以群分”:
- 1、输入 k 的值,即我们指定希望通过聚类得到 k 个分组
- 2、从数据集中随机选取 k 个数据点作为初始大佬(质心)
- 3、对集合中每一个小弟,计算与每一个大佬的距离,离哪个大佬距离近,就跟定哪个大佬
- 4、这时每一个大佬手下都聚集了一票小弟,这时候召开选举大会,每一群选出新的大佬(即通过算法选出新的质心)
- 5、如果新大佬和老大佬之间的距离小于某一个设置的阈值(表示重新计算的质心的位置变化不大,趋于稳定,或者说收敛),可以认为我们进行的聚类已经达到期望的结果,算法终止
- 6、如果新大佬和老大佬距离变化很大,需要迭代3~5步骤

3.7.1.1 点云数据的超像素处理
-
SLIC(Simple Linear Iterative Clustering)即简单线性迭代聚类方法
- 将不同像素相似的特征将像素分组,最终用相对少量的超像素块代替原来的像素来刻画图像特征
- 本文将人体点云数据中具有相似深度距离以及图像上相邻像素的点融合为一个像素块,大大降低点云规模,充分减少人体图模型的边数和顶点数
- 将人体模型图构造为稀疏的图能够大大提高计算测地距离的效率
- SLIC处理流程:
- 首先通过经验值设定预分割的超像素块的个数 K K K (如果选取过大,虽然图像表征能力较强但是计算复杂度提高;如果选取过小,虽然效率提高,但是图像包含的特征将减少),假设点云数据构成的整张图像共有N 个像素点,均匀分配超像素聚类中心(种子点)的话,那么每一个超像素块占有的像素数为 N K \frac{N}{K} KN,即每个像素块的边长: S = N K S= \sqrt {\frac{N}{K}} S=KN
- 将k 个聚类中心位置确定位置后,为了避免聚类中心点的位置出现在梯度较大的边界位置上,影响后续聚类的效果,在聚类中心点 n ∗ n n*n n∗n 邻域内,首先计算邻域内每个点的梯度,最终将聚类点移动到 n ∗ n n*n n∗n 邻域内梯度值最小的位置(一般n 取3)
- 为每一个在聚类点周围邻域内的像素点分配类别标签,用来标注当前像素属于哪个聚类中心
- 确定了每一个聚类中心点后,对于每一个在聚类中心范围内的像素,通过计算当前像素点与聚类中心的距离关系,确定当前像素所属的聚类标签。与传统的k-means 聚类在整张图像中搜索的策略不同,为了加快算法的收敛速度,本文在实验中将SLIC 算法的搜索范围限制为 3 S ∗ 3 S 3S*3S 3S∗3S
- 迭代进行上述步骤。在实验中发现大部分点云数据下,进行10 次循环迭
代对就可以达到理想效果

-
SLIC特点
- SLIC 算法生成的超像素块整齐
- 能够很好的将相似特征像素分到一起,而且生成超像素块在轮廓保持方面也很理想
- SLIC 算法需要设置的外部参数非常少
-
SLIC与k-means的区别
- 标准k-means 搜索整张图像
- SLIC 算法只搜索有限区域
-
提取特征点的步骤:
- 先将深度图像中的点,利用邻域关系等连接成一张连通图
- 利用几何关系,求得人体中心点
- 使用Dijkstra 算法从人体中心点出发求整个人体的5 个肢端点
- 根据肢端点位置将人体肢体分为5 个部位
- 得到部位信息后,然后在每一个部位内部进行k-means 聚类,聚类结束后,最后将部位内部得到的所有聚类中心点作为人体的特征点
3.7.1.2 人体肢端点的提取
- 得到稀疏点云数据后,可以利用空间中点的约束关系来构建边,进而连接成整张网格图,即
G
t
=
(
V
t
,
E
t
)
G_t = (V_t, E_t)
Gt=(Vt,Et)
- V t = X t V_t = X_t Vt=Xt:表示图中的顶点集合,即3D点云集合
- E t = V t × V t E_t = V_t \times V_t Et=Vt×Vt:代表图中边的集合
- 两个点云 ( x i j , x k , l ) (x_{ij}, x_{k,l}) (xij,xk,l)间是否有边连接:需要考察空间中两点之间的欧氏距离是否满足一定阈值,而且在2D 深度图像上两点是否是邻接关系,即点云中点包含边的原则是两点在深度图像上相邻,而且空间中两点的距离也在阈值范围内
- 得到整张图后,可以求图中任意两点之间的测地距离, 图中两点
x
,
y
∈
V
t
x, y \in V_t
x,y∈Vt之间的测地距离(通过Dijkstra算法求测地距离)为:
d G ( x , y ) = ∑ e ∈ S P a t h ( x , y ) w ( e ) d_G(x,y) = \sum_{e \in SPath(x,y)} w(e) dG(x,y)=e∈SPath(x,y)∑w(e)- S P a t h ( x , y ) SPath(x,y) SPath(x,y):表示点 x x x和 y y y之间的最短路径上所有边的集合
- w ( e ) w(e) w(e):表示边的长度
- 中心到其他点的测地距离不变的特性(即与运动无关),能够很方便地定位人体的肢端点 (oa:为欧氏距离,oha:为测地距离)

- 基于测地距离的迪杰斯特拉算法,定位一级骨架点的具体步骤:
- 首先在构建好稀疏图的基础上,利用点云中所有点的横坐标与纵坐标的均值找到人体的中心点O
- 然后从O 出发计算人体连通图上各个点到中心点O 的测地距离
- 构建一个记录每个点相对于中心点O 测地距离的map,选取一个合适的测地阈值(一般为中心点到肩膀附近的距离),将人体分为5 个独立的区域
- 基于洪水填充算法(flood fill algorithm)分割出每一个区域,并将每个区域内最大的测地值点作为肢端点

3.7.1.3 人体部位的提取
- 经过上述步骤求得人体肢端点位置后,分别计算每一个肢端点到人体连通图上其他所有点的距离,最后根据身体上每一个像素到5 个肢端点的测地距离,利用KNN(k-Nearest Neighbor,邻近算法,K 最近邻)算法判断该像素属于哪一个肢端点所在的部位
- K表示距离自己最近的点的个数,在这K个点中,哪个类别的点最多,自己就跟着属于哪个类别,即随大流

- K表示距离自己最近的点的个数,在这K个点中,哪个类别的点最多,自己就跟着属于哪个类别,即随大流
3.7.1.4 聚类特征点的提取
- 得到身体部位信息后,本文的方案是在部位内进行k-means 聚类,并将聚类中心作为刻画人体姿态的特征
- 传统k-means 通过随机初始化聚类中心点的方式,无法保证聚类的效率,与传统k-means 初始化聚类中心点采取的策略不同
- 本文事先将每一个部位内的数据按照像素行从小到大的关系排列起来,平均选取k 个聚类中心点,然后进行聚类迭代操作,经过验证本文提出的策略相比于随机选取聚类中心点迭代次数明显减少,提高了聚类效率

- 得到聚类中心点后,本文按照身体部位顺序将聚类点排序为一个向量。身体部位信息则基于肢端点信息由SVM 训练学习得到。
3.7.2 基于稀疏回归模型的骨骼点提取
- 求解一个聚类特征点与骨架点之间的稀疏回归模型,求解此模型需要用到拉格朗日乘子法。
3.7.2.1 基于拉格朗日乘子法的约束问题求解
- 对于如下问题:
目 标 函 数 : m i n f ( x , y ) 目标函数:min\; \mathit f\,(x,y) 目标函数:minf(x,y)
s . t . g ( x , y ) = c s.t. \quad g(x,y) = c s.t.g(x,y)=c -
z
=
f
(
x
,
y
)
的
等
高
线
z=f(x,y)的等高线
z=f(x,y)的等高线

- 如果目标函数
f
(
x
,
y
)
f (x, y)
f(x,y)的等高线和约束条件轨迹相切,则他们切点的梯度在一
条 直 线 上 ( 也 即 f f f 和 g g g 的 斜 率 平 行 : ∇ f ( x , y ) = λ ( ∇ g ( x , y ) − C ) \nabla f(x,y) = \lambda (\nabla g(x,y) -C) ∇f(x,y)=λ(∇g(x,y)−C) ) 即:
∇ [ f ( x , y ) + λ ( g ( x , y ) − C ) ] = 0 , λ ≠ 0 \nabla [f(x,y) + \lambda (g(x,y) -C)] = 0, \quad \lambda \neq 0 ∇[f(x,y)+λ(g(x,y)−C)]=0,λ=0 - 则拉格朗日函数为:
F ( x , y ) = f ( x , y ) + λ ( g ( x , y ) − C ) F(x,y) = f(x,y) + \lambda (g(x,y) -C) F(x,y)=f(x,y)+λ(g(x,y)−C)- 此函数达到极值时与 f ( x , y ) f(x,y) f(x,y)相等,因为 F ( x , y ) F(x,y) F(x,y)取得极值时 ( g ( x , y ) − C ) (g(x,y) - C) (g(x,y)−C) 一定等于0
- 对于
n
n
n维带约束的优化问题:
目 标 函 数 : m i n f ( x 1 , x 2 , . . . , x n ) 目标函数:min\; \mathit f\,(x_1, x_2, ..., x_n) 目标函数:minf(x1,x2,...,xn)
s . t . h k ( x 1 , x 2 , . . . , x n ) ( k = 1 , 2 , . . . , l ) s.t. \quad h_k(x_1, x_2, ..., x_n) \quad (k=1,2,...,l) s.t.hk(x1,x2,...,xn)(k=1,2,...,l) - 拉格朗日乘子法的方法:是把原目标函数
f
(
x
)
f (x)
f(x)改写成具有如下形式的新目标函数:
F ( x , λ ) = f ( x ) + ∑ k = 1 l λ k h k ( x ) F(x, \lambda) = f(x) + \sum_{k=1}^l \lambda_kh_k(x) F(x,λ)=f(x)+k=1∑lλkhk(x)- h k ( x ) h_k(x) hk(x):为目标函数 f ( x ) f(x) f(x)的等式约束条件
- 系数 λ k \lambda_k λk:为拉格朗日乘子
- 对
F
(
x
,
λ
)
F(x,\lambda)
F(x,λ)中的未知数(
x
i
,
、
λ
k
x_i, 、\lambda_k
xi,、λk)求偏导,在极值处所有偏导为0,利用方程求出未知数的解即为最优解。
{ ∂ F ∂ x i = 0 , i=1,2, ..., n ∂ F ∂ λ k = 0 , k=1,2,...l{∂xi∂F=0,∂λk∂F=0,i=1,2, ..., nk=1,2,...l{∂F∂xi=0,∂F∂λk=0,i=1,2, ..., nk=1,2,...l
3.7.2.2 稀疏回归模型的求解
- 目标:找到一个投影矩阵B ,使得由X 预测Y 的误差最小
- 前提设定:
- X = { x 1 , x 2 , . . . , x n } X = \{x_1, x_2, ..., x_n \} X={x1,x2,...,xn}:表示 n n n个样本的集合, x i x_i xi表示第 i i i个样本的聚类特征点
- Y = { y 1 , y 2 , . . . , y n } Y=\{y_1, y_2, ..., y_n \} Y={y1,y2,...,yn}:表示 n n n个样本的集合, y i y_i yi表示第 i i i个样本的骨架点
- X 与 Y X与Y X与Y中的样本一 一对应,即 x i 和 y i x_i和y_i xi和yi分别表示第 i i i个样本的聚类特征点和骨骼点
- 求解投影矩阵
B
B
B:
y i = x i B i = 1 , 2 , 3... , n y_i=x_iB \quad i=1,2,3..., n yi=xiBi=1,2,3...,n- y i j y_{ij} yij:表示第 i i i个样本的第 j j j个关节, j = 1 , 2 , . . . , 16 j=1,2,..., 16 j=1,2,...,16
- 只有在该骨架点位置附近的特征点能够足够影响该骨架点的位置
- 对于距离该骨架点位置比较远的特征点,则对当前骨架点的位置影响比较小
- 对于非刚性的人体来说,人体动作千变万化,尤其是双手和双脚的位置动作幅度很大,所以对于手部和脚部关节点位置,需要进行一些先验的约束
- 手部骨架点对于肘部的骨架点而言,两个骨架点之间的距离应当在一个范围之内
- 在脚部的骨架点中,距离膝盖位置的骨架点也应该在一定范围之内
- 目标函数
min B ∥ X B − Y ∥ F 2 + α ∥ B ∥ 1 + β ∥ X B h a n d − X B e l b o w − C 1 ∥ F 2 + λ ∥ X B f o o t − X B k n e e − C 2 ∥ F 2 \min_B \Vert XB-Y \Vert_F^2 + \alpha \Vert B \Vert_1 + \beta \Vert XB_{hand} - XB_{elbow} - C_1\Vert_F^2 + \lambda \Vert XB_{foot}-XB_{knee}-C_2 \Vert_F^2 Bmin∥XB−Y∥F2+α∥B∥1+β∥XBhand−XBelbow−C1∥F2+λ∥XBfoot−XBknee−C2∥F2- B h a n d B_{hand} Bhand:映射矩阵中对应手关节的那一列
- B e l b o w B_{elbow} Belbow:映射矩阵中对应肘关节的那一列
- C C C:事先统计的用来训练的记录骨架点之间的距离信
- 模型中出现的映射矩阵
B
B
B 的
1
1
1 范数,是为了保证
B
B
B 的稀疏性,后面两项
F
F
F范数的平方项是关于骨架点距离的约束,是为了保证手或者脚部位骨架点之间相对位置的稳定性
∥ A ∥ 1 = max j ∑ i = 1 m ∣ a i , j ∣ \Vert A \Vert_1 = \max_j \sum_{i=1}^m |a_{i,j}| ∥A∥1=jmaxi=1∑m∣ai,j∣- 列和范数,即所有矩阵列向量绝对值之和的最大值
- 矩阵
A
A
A的Frobenius范数定义为矩阵
A
(
m
×
n
)
A(m \times n)
A(m×n)各项元素的绝对值平方的总和,再开平方
∥ A ∥ F = ∑ i = 1 m ∑ j = 1 n ∣ a i j ∣ 2 \Vert A \Vert_F = \sqrt { \sum_{i=1}^m \sum_{j=1}^n |a_{ij}|^2} ∥A∥F=i=1∑mj=1∑n∣aij∣2
- 将无约束问题转变为有约束问题:
min B ∥ X B − Y ∥ F 2 + α ∥ A ∥ 1 + β ∥ X B h a n d − X B e l b o w − C 1 ∥ F 2 + λ ∥ X B f o o t − X B k n e e − C 2 ∥ F 2 \min_B \Vert XB-Y \Vert_F^2 + \alpha \Vert A \Vert_1 + \beta \Vert XB_{hand} - XB_{elbow} - C_1\Vert_F^2 + \\ \lambda \Vert XB_{foot}-XB_{knee}-C_2 \Vert_F^2 Bmin∥XB−Y∥F2+α∥A∥1+β∥XBhand−XBelbow−C1∥F2+λ∥XBfoot−XBknee−C2∥F2
s . t . A = B s.t. \quad A=B s.t.A=B - 转变为增广拉格朗日问题,等价于使用乘子法求解优化如下问题:
min B ∥ X B − Y ∥ F 2 + α ∥ A ∥ 1 + β ∥ X B h a n d − X B e l b o w − C 1 ∥ F 2 + λ ∥ X B f o o t − X B k n e e − C 2 ∥ F 2 + μ 2 ∥ A − B ∥ F 2 − < L , A − B > \min_B \Vert XB-Y \Vert_F^2 + \alpha \Vert A \Vert_1 + \beta \Vert XB_{hand} - XB_{elbow} - C_1\Vert_F^2 + \\ \lambda \Vert XB_{foot}-XB_{knee}-C_2 \Vert_F^2 + \frac{\mu}{2} \Vert A-B \Vert_F^2- <L, A-B> Bmin∥XB−Y∥F2+α∥A∥1+β∥XBhand−XBelbow−C1∥F2+λ∥XBfoot−XBknee−C2∥F2+2μ∥A−B∥F2−<L,A−B>- L L L:为随机矩阵,最小化此公式,等价于求解如下问题:
参考
-
论文及代码:基于Depth
- Efficient Human Pose Estimation from Single Depth Images 2012 MSRA 【code】
- 3D Human Pose Estimation in RGBD Images for Robotic Task Learning
- A2J: Anchor-to-Joint Regression Network for 3D Articulated Pose Estimation from a Single Depth Image : 使用ITOP数据集
- V2V-PoseNet: Voxel-to-Voxel Prediction Network for Accurate 3D Hand and Human Pose Estimation from a Single Depth Map
-
论文及代码:基于RGB
- https://yinguobing.com/bottlenecks-block-in-mobilenetv2/
- Real-time 2D Multi-Person Pose Estimation on CPU: Lightweight OpenPose
- Real-time-3D-Human-Pose-Estimation-with-a-Single-RGB-Camera
- Awesome Human Pose Estimation
- VNect: Real-time 3D Human Pose Estimation with a Single RGB Camera 利用了骨头长度
- Realtime multi-person 2D pose estimation using part affinity fields. 利用了身体部位间的关系
-
人体姿态估计Depth数据集
- 迈向视点不变的3D人类姿势估计 (ITOP: Towards Viewpoint Invariant 3D Human Pose Estimation) - Fei-Fei Li
Stanford University
- 迈向视点不变的3D人类姿势估计 (ITOP: Towards Viewpoint Invariant 3D Human Pose Estimation) - Fei-Fei Li
-
基于深度图像的人体姿态估计及相似性度量

