
- 1【机器学习实战1】泰坦尼克号:灾难中的机器学习(一)数据预处理_泰坦尼克数据预处理
- 2opencv-python——通过cv2.distanceTransform()函数将距离转换成热力图
- 3sklearn.neighbors.KNeighborsClassifier()函数解析_kneighborsclassifier函数是干什么的
- 4【windows|008】DNS服务详解
- 5vscode 快捷键 在终端 和工作区 切换_vscode切换工作区
- 6C++11常用特性_c++11 常用特性有哪些
- 7linux磁盘管理(永久挂载)_linux磁盘管理永久挂载
- 8ASIC&FPGA&SOC_fpga asic soc
- 9Sharding-JDBC之ComplexKeysShardingAlgorithm(复合分片算法)
- 10vscode中使用终端响应卡顿_vscode终端卡住了怎么办
【Paper】Few-Shot Charge Prediction with Discriminative Legal Attributes
赞
踩
传送门:
Abstract
- Automatic charge prediction:根据刑事案件(criminal cases )的事实描述预测最终的charges,在法律助理系统中起着至关重要的作用。
- 存在问题:(1)现有的charge prediction工作可以对那些高频charges充分发挥作用,但尚不能在有限案件下预测出 few-shot charges。(2)存在许多事实描述相当相似的charges pairs。
- 解决方法:引入了一些charge的区分属性(discriminative attributes),作为事实描述和charges用之间的内部映射。这些属性为few-shot charges提供额外的信息,及用于区分confusing charges(混淆罪名)的有效标志。更具体地说,提出一个attribute-attentive charge prediction 模型,以同时推断 attributes 和 charges 。
- 实验结果:在真实数据集上比 state-of-the-art 有显著和持续的提升。具体来讲,本方法在 few-shot 场景中优于其他 baselines 超过 50%。
1 Introduction
- 目标:训练机器judge,以确定刑事案件中被告的最终charges(指控)(eg: 盗窃、抢劫或违反交通规章罪)。
- 作用:它是法律判断预测(legal judgment prediction) 的典型子任务,在法律辅助系统中起着重要的作用,可以造福许多实际应用。例如:为法律人士提供方便的参考以提升工作效率;为不熟悉法律术语和复杂程序的普通人提供法律咨询。
- 现状:大多数工作以文本分类为框架。
- 早期:侧重于从text或case profiles中提取有效特征,但是需要耗费手工设计特征和标准训练数据的人力,且难以扩展到其他场景。
- 近期:应用深度神经网络来建模legal documents,例如:Luo et al. (2017) 提出 attention-based 的神经网络,通过整合相关law articles进行charge prediction。
- 两个主要挑战:
- Few-Shot Charges:
- 数据不平衡:在实际中,各种charges的案例数量高度不平衡。根据我们在一个真实数据的统计,最常见的10项 charges (盗窃、故意伤害和交通违章行为) 涵盖78.1%的案件。相反,最低频 50 项charges (倒卖文物,扰乱法院秩序,逃税) 只涵盖不到0.5%的案件,而大多数这些charges只拥有约10个相关案件。
- 先前的工作通常侧重于这些常见的charges,而忽略 few-shot Charges。虽然深度神经模型促进了基于特征工程的 charge prediction 方法,但由于需要足够的训练数据,它们无法很好地处理 few-shot charges。
- 如何在 limited cases情况下处理这些 charges 对于建立鲁棒而有效的 charge prediction 系统至关重要。
- Confusing Charges:
- 存在许多易混淆的 charges pairs,对于每个易混淆的 charges pairs两项 charges 的定义在核实具体行为时才不同,而相应案件下的情况通常相似。
- ==》如何捕捉区分混淆 charges 的关键因素是 charge prediction 的另一个挑战。
- Few-Shot Charges:
- 解决方法:
- 引入 charges 具有区分性的 legal attributes (法律属性),并将这些属性作为fact与charges之间的内部映射。更具体地说,选择 10 个具有代表性的charges属性,包括:暴力、盈利目的、买卖等。之后,我们进行低成本的类别级注释,即对每个charge,标注每个属性的值(包括yes、no 或 not available),此注释指示属性是否是一个charge的必要条件。
- 结合charges的属性注释,提出了一种多任务学习框架,以同时预测每个案例的属性和charges。 在该模型中,我们使用attribute attention mechanism (属性注意力机制) 来捕捉与特定属性相关的关键事实信息。在那之后,我们将这些 attribute-aware(属性感知)表示 与 attribute-free(无属性)事实表示 相结合,以预测最终charges。
- 引入 legal attributes 的两个原因:(1) 提供有关如何区分混淆charges的明确知识;(2) 这些属性由所有charges共享,并且知识可以从high-frequency charges 转换为 low-frequency charges。即使对于few-shot charges,也可学习用于预测的有效 attribute-aware 表示。
- 实验:验证 few-shot 和 confusing charges 的有效性,在三个真实的中国刑事案件数据集实验。实验结果表明本方法在所有数据集和评估指标上可显著并持续优于 state-of-the-art 模型。值得注意的是,我们的模型在 few-shot charges 方面优于其他baselines 50% 以上。
- 三方面贡献:
- 第一个关注 charge prediction 中的 few-shot 和 confusing 问题。 并首次在 charge prediction 任务中引入 legal attributes。
- 提出一个新颖的多任务学习框架,共同推断案件的属性和charges。具体来讲,使用 attribute attention mechanism 来学习 属性感知(attribute-aware) 的事实表示。
- 在几个真实数据集上进行有效实验,本方法显著优于其他 baselines 并在 few-shot charges 提升 50%。
2 Related Work
2.1 Zero-Shot Classification
我们的工作与CV中的 Zero-Shot Classification(零样本分类) 有关。
- attribute-based 的模型:由于属性可在不同类之间共享并且可以提供中间表示,因此已经提出了许多 attribute-based 的模型。
- Lampert et al. (2014)介绍了direct attribute prediction(DAP) 和 indirect attribute prediction(IAP),并提出 attribute classifiers,它可以预先训练,在寻找新的合适的类别时不需要重新训练。
- Akata et al. (2013) 提出将基于属性的分类任务转化为 label-embedding 任务。
- Jayaraman and Grauman (2014) 引入随机森林方法,stress the unreliability of attribute prediction for unseen classes(强调看不见类别的属性预测的不可靠性)。他们还将其扩展到few-shot场景。
- 其他外部信息
- Elhoseiny et al. (2014) 利用类别标签的文字描述在文本特征与视觉特征之间传输知识。
- 应用:目标识别、行为识别、事件识别
2.2 Charge Prediction
- 早期阶段:
- 例如:Kort (1957) 使用定量方法(quantitative methods) 通过计算事实元素的数值来预测判决;Nagel (1963) 利用相关分析对重新分配的案例做出预测;Keown (1980) 引入了用于法律预测的数学模型,如线性模型、KNN。
- 评价:这些方法通常是数学或定量的,并且它们仅限于标签很少的小型数据集。
- 机器学习阶段:视为一个文本分类任务来考虑。
- 一些工作通常侧重于从案例事实中提取特征。Lin et al. (2012)获取 21 个legal factor labels (法律因素标签) 用于案件分类。Mackaay and Robillard (1974) 提取
- 评价:这些方法只提取浅层文本特征或手工标签,难以扩展到较大的数据集上;此外,不能捕捉类似犯罪之间的 subtle difference(微妙区别),因此,当类别数量增加、出现更多类似的犯罪时,它们的表现就不好了。
- 神经网络阶段:Luo et al. (2017) 提出一个 hierarchical attentional network (分层注意力网络) 同时预测 charges 并提取相关 articles。然而,该方法仅关注高频charges,而没有关注 few-shot and confusing ones.
==》解决方法:提出一个基于注意力的神经网络模型,通过引入干具有区分性的法律属性。
3 Method
本文提出 few-shot 神经网络模型,使用一个统一的框架对charge prediction任务和 legal attribute prediction任务同时建模。
3.1 Discriminative Charge Attributes
为了区分易混淆的 charges 并为 few-shot charges 提供额外信息,针对中国刑法中的所有charges,我们引入 10 个具有区分性的属性,图表1所示。对于每个 (charge, attribute) pair,它会标记为 Yes、No 或 NA。
- 例如:过失杀人(manslaughter)罪名 在 故意犯罪(Intentional Crime) 属性上标记为
No,在死亡(Death)上为Yes,在国家机关(State Organ)上为NA。注意:具体案件的事实调查结果只能标记为Yes或No。
判定某人犯有某种罪行时,事实应符合对特定指控的描述。因此,对于特定属性,特定案件的标签和相应charge的标签应相同或不冲突。换句话说,对于某个属性,案件和charge的标签只能是 (Yes, Yes), (No, No), (Yes, NA) 或 (No, NA)。
- 实现:我们进行低成本注释,并手动注释 149 种不同charges的属性。然后,我们为每个案件分配其相应charge的相同属性。

3.2 Formalizations
3.2.1 Charge Prediction
一个案件的事实描述可当作一个单词序列(word sequence) x = { x 1 , x 2 , . . . , x n } \mathbf{x}=\{x_1,x_2,...,x_n\} x={x1,x2,...,xn},其中 n n n 表示序列长度, x i ∈ T x_i\in{T} xi∈T, T T T是a fixed vocabulary(固定词汇表)。给定事实描述 x \mathbf{x} x, charge prediction任务是预测一个 charge y ∈ Y y\in{Y} y∈Y,其中 Y {Y} Y 是一个charge集合。
3.2.2 Attributes Prediction
attributes prediction任务可视为一个二分类任务。输入与charge prediction任务一样都是事实描述 x \mathbf{x} x,其目标是根据事实预测属性的 fact-findings p = { p 1 , p 2 , . . . , p k } \mathbf{p}=\{p_1,p_2,...,p_k\} p={p1,p2,...,pk}。其中, k k k 是所选择属性的数量, p i ∈ { 0 , 1 } p_i\in{\{0,1\}} pi∈{0,1} 是一个确定属性的标签。
3.3 Fact Encoder

如图2所示,fact encoder 将离散输入序列编码为连续隐藏状态。由于可以提取语义含义,采用 LSTM 作为 fact encoder。LSTM是RNN的一个变体,它可以捕捉长期依赖关系。
- 首先,LSTM 编码器将每个单词 x i ∈ x x_i\in{\mathbf{x}} xi∈x 转换为其word embedding x i ∈ R d {\mathbf{x}_i}\in{\mathbb{R}^d} xi∈Rd,其中 d d d 是 word embedding 的维度。
- 之后,所得到的相关 word embedding 序列作为
x
^
=
{
x
1
,
x
2
,
.
.
.
,
x
n
}
\hat\mathbf{x}=\{\mathbf{x}_1,\mathbf{x}_2,...,\mathbf{x}_n\}
x^={x1,x2,...,xn}。在每个时间 step
t
∈
[
1
,
n
]
t\in{[1,n]}
t∈[1,n],LSTM cell 输入
x
t
\mathbf{x}_t
xt,重新计算 memory cell
c
t
\mathbf{c}_t
ct,输出 new hidden state
h
t
\mathbf{h}_t
ht 如下:
f t = σ ( W f x t + U f h t − 1 + b f ) , i t = σ ( W i x t + U i h t − 1 + b i ) , o t = σ ( W o x t + U o h t − 1 + b o ) , c ^ t = tanh ( W c x t + U c h t − 1 + b c ) , c t = f t ⊙ c t − 1 + i t ⊙ c ^ t , h t = o t ⊙ tanh ( c t ) (1)\begin{aligned} \mathbf{f}_t &= \sigma{(W_f\mathbf{x}_t+\mathbf{U}_{f}\mathbf{h}_{t-1}+\mathbf{b}_{f})}, \\ \mathbf{i}_{t} &= \sigma{(W_i\mathbf{x}_t+\mathbf{U}_{i}\mathbf{h}_{t-1}+\mathbf{b}_{i})}, \\ \mathbf{o}_{t} &= \sigma{(W_o\mathbf{x}_t+\mathbf{U}_{o}\mathbf{h}_{t-1}+\mathbf{b}_{o})}, \\ \hat\mathbf{c}_{t} &= \tanh{(W_c\mathbf{x}_t+\mathbf{U}_{c}\mathbf{h}_{t-1}+\mathbf{b}_{c})}, \\ \mathbf{c}_{t} &= \mathbf{f}_{t}\odot \mathbf{c}_{t-1}+\mathbf{i}_{t}\odot \hat\mathbf{c}_{t}, \\ \mathbf{h}_{t} &= \mathbf{o}_{t} \odot \tanh(\mathbf{c}_t) \tag{1} \end{aligned}ftitotc^tctht=σ(Wfxt+Ufht−1+bf),=σ(Wixt+Uiht−1+bi),=σ(Woxt+Uoht−1+bo),=tanh(Wcxt+Ucht−1+bc),=ft⊙ct−1+it⊙c^t,=ot⊙tanh(ct)(1)
其中, f t , i t and o t \mathbf{f}_t, \mathbf{i}_t \text{ and } \mathbf{o}_t ft,it and ot 分别表示 forget gate、input gate 和 output gate。 ⊙ \odot ⊙ 表示按元素乘法, σ \sigma σ 表示 sigmoid 激活函数。 W , U and b W, U \text{ and } b W,U and b分别是权重矩阵和偏置向量。处理完所有时间 steps 后,我们得到一个hidden state序列 h = { h 1 , h 2 , . . . , h n } \mathbf{h}=\{\mathbf{h}_1,\mathbf{h}_2,...,\mathbf{h}_n\} h={h1,h2,...,hn}。 - 最后,将其输入一个max-pooling层来获得 无属性(attribute-free) 表示
e
=
[
e
1
,
.
.
.
,
e
s
]
\mathbf{e}=[e_1,...,e_s]
e=[e1,...,es] :
e i = max ( h 1 , i , . . . , h n , i ) , ∀ i ∈ [ 1 , s ] (2) e_i=\max(\mathbf{h}_{1,i},...,\mathbf{h}_{n,i}), \forall{i}\in{[1,s]}\tag{2} ei=max(h1,i,...,hn,i),∀i∈[1,s](2)
其中, s s s 表示 hidden states 的维数。
3.4 Attentive Attribute Predictor
给定事实描述 x \mathbf{x} x,attribute predictor 要预测每个属性的标签。受(Yang et al., 2016)启发,使用一个 attention mechanism 从事实中选择相关信息并生成 attribute-aware(属性感知) 事实表示。
如图2所示,attribute predictor 使用 hidden states 序列
h
=
{
h
1
,
h
2
,
.
.
,
h
n
}
\mathbf{h}=\{\mathbf{h}_1,\mathbf{h}_2,..,\mathbf{h}_n\}
h={h1,h2,..,hn} 作为输入。之后 attribute predictor 对所有属性计算 注意力权重
a
=
{
a
1
,
a
2
,
.
.
,
a
k
}
\mathbf{a}=\{\mathbf{a}_1,\mathbf{a}_2,..,\mathbf{a}_k\}
a={a1,a2,..,ak},其中
a
i
=
{
a
i
,
1
,
a
i
,
2
,
.
.
,
a
i
,
n
}
.
∀
i
∈
[
1
,
k
]
and
j
∈
[
1
,
n
]
,
a
i
,
j
\mathbf{a}_i=\{\mathbf{a}_{i,1},\mathbf{a}_{i,2},..,\mathbf{a}_{i,n}\}. \forall{i}\in{[1,k] \text{ and } j\in{[1,n]}, a_{i,j}}
ai={ai,1,ai,2,..,ai,n}.∀i∈[1,k] and j∈[1,n],ai,j 计算公式如下:
a
i
,
j
=
exp
(
tanh
(
W
a
h
j
)
T
u
i
)
∑
t
exp
(
tanh
(
W
a
h
t
)
T
u
i
)
(3)
a_{i,j}=\frac{\exp(\tanh(\mathbf{W}^a\mathbf{h}_j)^T\mathbf{u}_i)}{\sum_t{\exp(\tanh(\mathbf{W}^a\mathbf{h}_t)^T\mathbf{u}_i)}}\tag{3}
ai,j=∑texp(tanh(Waht)Tui)exp(tanh(Wahj)Tui)(3)
其中,
u
i
\mathbf{u}_i
ui 表示第
i
i
i 个属性的上下文向量,用于计算一个元素对属性
i
i
i 的 informative(提供有用信息),
W
a
\mathbf{W}^a
Wa 表示所有属性共享的权重矩阵。之后,我们获得事实
g
=
{
g
1
,
.
.
.
,
g
k
}
\mathbf{g}=\{\mathbf{g}_1,...,\mathbf{g}_k\}
g={g1,...,gk} 属性感知(attribute-aware) 表示,and
g
i
=
∑
t
a
i
,
t
h
t
\mathbf{g}_i=\sum_t{a_{i,t}\mathbf{h}_t}
gi=∑tai,tht。最后,使用表示
g
g
g 将其投影到标签空间中,并使用softmax函数来获取最后的预测结果
p
=
[
p
1
,
p
2
,
.
.
.
,
p
k
]
\mathbf{p}=[p_1,p_2,...,p_k]
p=[p1,p2,...,pk],其中
p
i
p_i
pi 是属性
i
i
i 的预测结果,其计算方法如下:
z
i
=
s
o
f
t
m
a
x
(
W
i
p
g
i
+
b
i
p
)
p
i
=
a
r
g
max
(
z
i
)
(4)
其中,
z
i
\mathbf{z}_i
zi 表示 Yes and No 上的预测概率分布。
W
i
p
and
b
i
\mathbf{W}_i^p \text{ and }\mathbf{b}_i
Wip and bi 是属性
i
i
i 的权值矩阵和偏移向量。
3.5 Output Layer
为了整合事实描述和所有属性的 fact-findings,我们使用 无属性(attribute-free) 和 属性感知(attribute-aware) 表示来预测输出层案件最终预测的charge。所有 charges 的预测分布
y
y
y 计算如下:
r
=
∑
i
g
i
k
,
v
=
e
⊕
r
,
y
=
softmax
(
W
y
v
+
b
y
)
.
(5)
其中,
r
\mathbf{r}
r 表示属性感知表示的均值。
r
\mathbf{r}
r 与
e
\mathbf{e}
e 串联形成最终的事实表示
v
\mathbf{v}
v。
W
y
and
b
y
\mathbf{W}^y \text{ and }\mathbf{b}^y
Wy and by 是输出层的权值矩阵和偏移向量。
3.6 Optimization
本模型的训练目标函数由两部分组成。
- charge损失:最小化预测charge分布
y
y
y 与 ground-truth 分布
y
^
\hat{y}
y^ 之间的交叉熵。 charge预测损失函数如下所示:
L c h a r g e = − ∑ i = 1 C y i ⋅ log y ^ i (6) \mathcal{L}_{charge}=-\sum_{i=1}^Cy_i·\log{\hat{y}_i}\tag{6} Lcharge=−i=1∑Cyi⋅logy^i(6)
其中, y i y_i yi 表示ground-truth标签, y ^ i \hat{y}_i y^i 表示预测概率, C C C 表示charges的数量。 - 属性损失:最小化每一个属性的预测分布与ground-truth fact-founding 之间的交叉熵。 由于每个属性在模型中都同等重要,所以可将所有属性的交叉熵相加来计算属性损失。但是,当具体charge的属性为
NA时,相应案件的标签可以为Yes或No。因此,仅当 charge 的属性是Yes或No时,才将交叉熵加到属性损失上。最后,属性损失表示如下:
L a t t r = − ∑ i = 1 k I i ∑ j = 1 2 z i j ⋅ log ( z ^ i j ) , (7) \mathcal{L}_{attr}=-\sum_{i=1}^kI_i\sum_{j=1}^2z_{ij}·\log(\hat{z}_{ij}),\tag{7} Lattr=−i=1∑kIij=1∑2zij⋅log(z^ij),(7)
其中, I i I_i Ii 表示一个指示函数。若当前charge的第 i i i 个属性标记为Yes或No,则 I i = 1 I_i=1 Ii=1,否则 I i = 0 I_i=0 Ii=0。显然, z i z_i zi 表示ground-truth 标签, z ^ i \hat{z}_i z^i 表示在Yes或No上的预测概率分布。
最终的损失函数
L
\mathcal{L}
L 是通过
L
c
h
a
r
g
e
\mathcal{L}_{charge}
Lcharge 加
L
a
t
t
r
\mathcal{L}_{attr}
Lattr 实现的:
L
=
L
c
h
a
r
g
e
+
α
⋅
L
a
t
t
r
(8)
\mathcal{L}=\mathcal{L}_{charge}+\alpha·\mathcal{L}_{attr}\tag{8}
L=Lcharge+α⋅Lattr(8)
其中,
α
\alpha
α 是一个超参数,用于平衡损失函数中两个部分的权重。
4 Experiments
4.1 Dataset Construction
数据获取:由于以前 works 中没有公开可用的数据集来进行 charge 预测,我们从中国裁判文书网(China Judgments Online)收集中国政府公布的刑事案件。由于每个案件具有 well-structured,可以分为事实(fact)、法院观点(court view) 和 处罚结果(penalty result)等几个部分,我们选择每个案件的事实部分作为输入。此外,我们可以通过正则表达式轻松地从惩罚结果中提取 charge。我们已手动检查了提取的 charge,几乎没有错误。
数据过滤:一些真实的案件包含多个被告和多项charges,由于其过于复杂,所以我们删除了判决中包含一项以上charges的案件。此外,为了检查我们的方法在 few-shot charges 中的性能,我们保留了 149 个不同的 charges (比 (Luo et al., 2017) 高出3倍),少有10个案例。
预处理:随机选择约40万个案件并构建三个不同规模的数据集,定义为 Criminal-S(small), Criminal-M(medium) 和 Criminal-L(large)。这三个不同的数据集包含相同数量的 charges,但案件数量却不同。详细统计信息如表2所示。
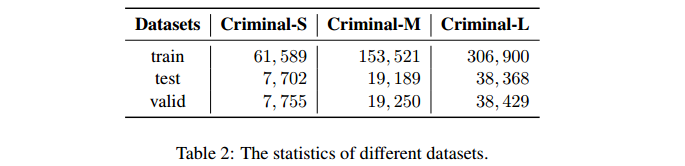
4.2 Attribute Selection and Annotation
如前一部分所述,我们提出引入鉴别性属性来增强charge预测能力。为了选择这些属性,
- 首先,训练一个基于 LSTM 的charge预测模型并获得验证集上预测charges的混淆矩阵。
- 然后,筛选出令人困惑的charge对,并将其提供给三名犯罪专业的硕士生。
- 最后,根据这些混乱的charge对,他们定义了10个代表性属性来区分这些混乱的charge对。
使用选定的10个属性,我们对所有charges进行低成本注释。具体来讲,只需要手动为 149 个charges (而不是所有案件) 的 10 个属性进行标注。由于选择的属性具有区分性和明确性,我们要求这些注释者为每个注释达成协议。总共,我们花了不到10个小时进行注释。
4.3 Baselines
baselines:包括典型的文本分类模型和一个charge预测模型。
- TFIDF+SVM:TFIDF用于特征提取,SVM用于分类。
- CNN:使用 multiple filter widths 的CNN作为文本分类器。
- LSTM:一个两层的LSTM和一个max-pooling作为事实encoder。
- Fact-Law Attention Model:Luo et al. (2017)提出一个基于注意力的 charge 预测模型,通过整合相关 law articles。
4.4 Experiment Settings and Evaluation Metrics
- 所有案件文件:中文且没有进行分词。
- 分词:THULAC (Sun et al., 2016)
- 最大文本长度(maximum document length):500
模型设置:
- TFIDF+SVM:feature size 为 2000;
- 其他神经网络模型:使用 Skip-Gram model (Mikolov et al., 2013)预训练词向量,且embedding size为100。
- LSTM 的 hidden state size:100
- CNN 的 filter widths:(2, 3, 4, 5) 且每个过滤器尺寸都设置为25以保持一致性。
- 属性损失的 α \alpha α 权重:1
- 注意:串联后,模型的特征大小将变为 200。为公平比较,在 CNN 和 LSTM 的池化层之后,添加一个 100 × 200 FC layer,被定义为 CNN-200 和 LSTM-200。
- 优化器(optimizer):Adam (Kingma and Ba, 2015)
- 学习率(learning rate):0.001
- Dropout:0.5
- batch size:64
- 评价指标:accuracy (Acc.), macro-precision (MP), macro-recall (MR) and macro-F1
4.5 Results and Analysis

- 本模型显著且始终优于所有基线。现有方法在 macro-F1 上表现不佳,这表明缺乏预测 few-shot charges 的能力。相反地,本模型有所提升,证明了我们的模型的鲁棒性和有效性。
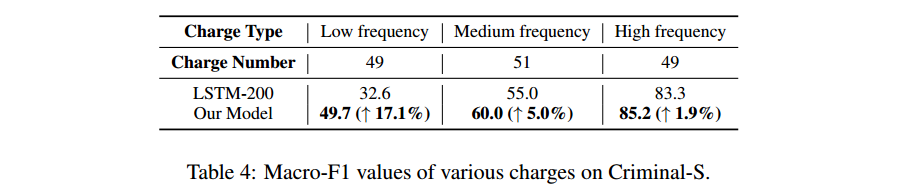
- 进一步验证 few-shot charges 上的性能,我们显示不同频率的charges的性能,如图4所示。我们根据频率将 charges 分为三个parts,即 小于10个案例的 charges 为 low-frequency,高于100个案例的 charges 为 high-frequency。
- 我们的模型实现了比 baseline 在 low-frequency charges 50%以上的提升,证明本方法在处理 few-shot 问题上的有效性。
4.6 Ablation Test
我们的方法的特点是将注意力机制(attention mechanism)和属性感知(attribute-aware)表示相结合。因此,分别设计 ablation test(消融试验) 来研究这些模块的有效性。
- 当不使用注意力机制:对于每个属性,用一个FC layer 代替 attention mechanism。
- 当不使用属性感知表示(即,不串联平均属性感知表示形式):将模型分解为一个基于LSTM的多任务学习,用于 charge 和属性预测。

- 在移除注意力层或连接层之后,性能明显下跌。macro-F1 最少减少4%。
==》注意力机制和属性感知表示在模型中扮演不可替代的角色。
4.7 Case Study
在本部分中,利用一个代表性的案件,以直观地说明预测属性如何帮助提高charge预测的性能。在本案中,被告被判犯有intentional injury(故意伤害罪)。通常很难判断案件是 affray(滋事罪(打架斗殴类)) 还是intentional injury(故意伤害),因为它们都与暴力有关。两者的一个重要区别是intentional injury具有physical injury(身体伤害)的特征,而affray则没有。
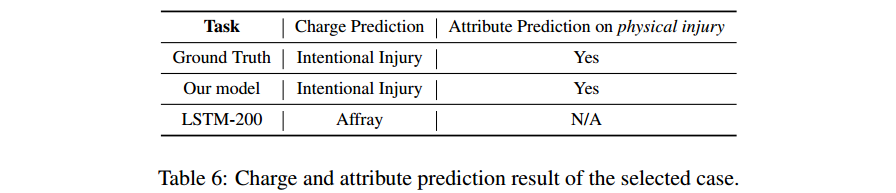
所以,我们认为,身体伤害的属性是本案的charge预测中必不可少的。如图6所示,本方法正确地预测身体伤害的标签为 Yes,从而将charge预测为故意伤害。相反,LSTM-200模型预测不正确,其预测为 affray。此外,在预测属性故意伤害时,我们直观地看到此案例的热图。背景颜色较深的单词具有较高的关注度。从下图中,我们观察到注意机制可以捕获与当前属性相关的关键 patterns and semantics。

5 Conclusion
本文关注根据刑事案件的事实描述对charge预测。为了解决 few-shot 和易混淆 charges 的问题,我们引入具有辨别力的法律属性,并提出一个新颖的基于属性的多任务学习模型来进行charge预测。具体来讲,我们的模型通过利用基于属性的注意力机制来联合学习无属性和属性感知事实表示。
未来方向:
- 对于复杂的刑事案件,例如多被告和charges。因此,处理这种一般形式的charges预测是具有挑战性的;
- 本方法仅利用charge的几个简单属性,而存在更复杂的charges必要条件。如何充分利用charges必要条件,有望提高charge预测模型的可解释性。

