
- 1在win 11/win10 visual studio上安装.net 45_net45
- 2三、K8s常见操作命令_using json format to get metrics. next release wil
- 3利用面向AWS的Thales Sovereign解决方案保护AI之旅
- 4阿里P5-P7学习路线及薪资待遇
- 5基于微信小程序的网上商城设计与实现(源码+lw+部署文档+讲解等)_小程序商城设计
- 6Android 性能优化之启动优化
- 7金九银十收获阿里腾讯实习offer,学习、面试经验分享
- 8头歌MySQL数据库实训答案 有目录_头歌数据库实训作业答案
- 9Java学习笔记-SLF4J中的Profilers的性能记录分析_org.slf4j.profiler
- 10一个人的安全部之企业信息安全建设规划
深度学习和机器学习的区别_深度学习是端到端,传统机器学习是两段式
赞
踩
最近在听深度学习的课,老师提了一个基本的问题:为什么会出现深度学习?或者说传统的机器学习有什么问题。老师讲解的时候一带而过,什么维度灾难啊之类的,可能觉得这个问题太浅显了吧(|| Д)````不过我发现自己确实还不太明白,于是Google了一下,发现一篇很棒的科普文,这里翻译一下,分享给大家:翻译自文章:https://www.analyticsvidhya.com/blog/2017/04/comparison-between-deep-learning-machine-learning/
一、机器学习
首先看看机器学习的定义:
“A computer program is said to learn from experience E with respect to some class of tasksT and performance measureP if its performance at tasks inT, as measured by P, improves with experience E ”(这段话我真的是看了100遍才知道怎么断句啊!!(Д))
翻译过来就是:“一个电脑程序要完成任务(T),如果电脑获取的关于T的经验(E)越多就表现(P)得越好,那么我们就可以说这个程序‘学习’了关于T的经验。”
简单来说,就是解释什么叫“机器的学习”,如果输入的经验越多表现的越好,这就叫“学习”嘛。
这里有几个例子:
1.根据身高预测体重:
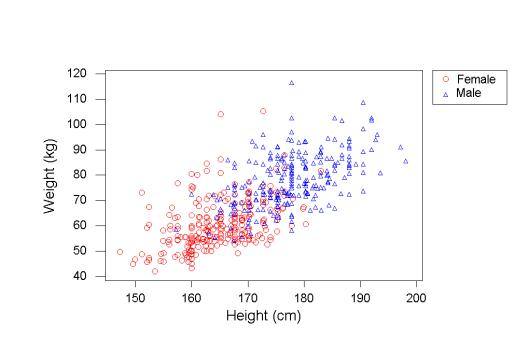 根据身高预测体重
根据身高预测体重
这个so easy,我也不想多解释了。我们高中都做过这样的题目,给你一堆点,你做出一条直线尽可能去拟合样本点,那这个直线就是你“学习”出来的,然后就可以用这个直线去预测未知点了。
2.风暴预测系统:
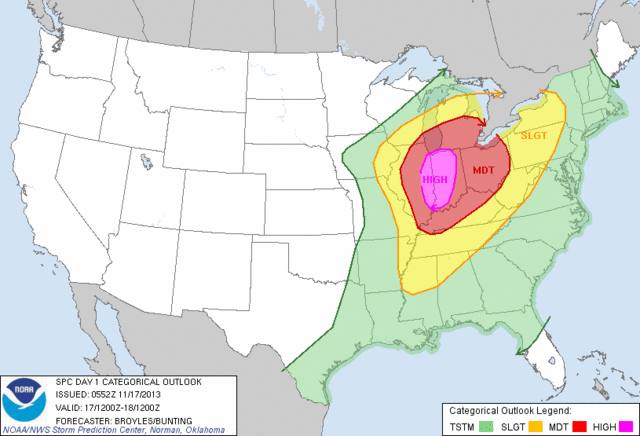 美国的风暴预测系统
美国的风暴预测系统
我们首先浏览所有的历史风暴数据,从这些大量的数据中学习出某些“模式”,这些“模式”包含了具体的哪些条件可以导致风暴。
比如我们也许可以通过学习历史数据发现:温度超过40度,湿度在80-100之间,就容易发生风暴。种种类似的模式。
这里注意了!“温度”、“湿度”等等指标,就是机器学习中的“特征”,而这些特征都是人工设置好的!就是说,我们在做这样一个预测系统的时候,首先由专家通过分析哪些“特征”是重要的,然后机器就通过分析历史数据中的这些特征的数据,来找到相应的模式,也就是怎样的特征的组合会导致怎样的结果。
理解上面这一点很重要,因为这是和深度学习的重要区别。
二、深度学习
还是首先看看深度学习的定义:
“Deep learning is a particular kind of machine learning that achieves great power and flexibility by learning to represent the world as nested hierarchy of concepts, with each concept defined in relation to simpler concepts, and more abstract representations computed in terms of less abstract ones.”(这个起码听起来像人话,但还是让人疑惑。。。)
我试着翻译一下:深度学习是一种特殊的机器学习,它可以获得高性能也十分灵活。它可以用概念组成的网状层级结构来表示这个世界,每一个概念更简单的概念相连,抽象的概念通过没那么抽象的概念计算。(有没有大佬帮忙指正一下?)
还是先通过例子说明,大家就慢慢理解了:
1.形状识别:
我们从一个简单的例子来看看我们认知层面上是如何区分物体的。比如我们要区分下面的形状,那个是圆的那个是方的:
 方形和圆形
方形和圆形
我们的眼睛第一件要做的事情,就是看看这个形状有没有4条边。如果有的话,就进一步检查,这4条边是不是连在一起,是不是等长的,是不是相连的互相垂直。如果满足上面这些条件,那么我们可以判断,是一个正方形。
从上面的过程可以看出,我们把一个复杂的抽象的问题(形状),分解成简单的、不那么抽象的任务(边、角、长度...)。深度学习从很大程度上就是做这个工作,把复杂任务层层分解成一个个小任务。
2.识别狗和猫:
如果是传统机器学习的方法,我们会首先定义一些特征,如有没有胡须,耳朵、鼻子、嘴巴的模样等等。总之,我们首先要确定相应的“面部特征”作为我们的机器学习的特征,以此来对我们的对象进行分类识别。
而现在,深度学习的方法则更进一步。深度学习自动地找出这个分类问题所需要的重要特征!而传统机器学习则需要我们人工地给出特征!
我觉得这是两者最重要的区别。
那么,深度学习是如何做到这一点的呢?
以这个猫狗识别的例子来说,按照以下步骤:
1●首先确定出有哪些边和角跟识别出猫狗关系最大;2●然后根据上一步找出的很多小元素(边、角等)构建层级网络,找出它们之间的各种组合;3●在构建层级网络之后,就可以确定哪些组合可以识别出猫和狗。
这里我没找到猫和狗的神经网络图片,倒是看到人像识别的一个示意图,觉得挺好的:
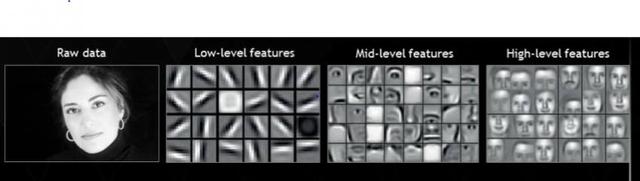 人脸识别
人脸识别
可以看到4层,输入的是Raw Data,就是原始数据,这个机器没法理解。于是,深度学习首先尽可能找到与这个头像相关的各种边,这些边就是底层的特征(Low-level features),这就是上面写的第一步;然后下一步,对这些底层特征进行组合,就可以看到有鼻子、眼睛、耳朵等等,它们就是中间层特征(Mid-level features),这就是上面写的第二步;最后,我们队鼻子眼睛耳朵等进行组合,就可以组成各种各样的头像了,也就是高层特征(High-level features)这个时候就可以识别出或者分类出各种人的头像了。
三、对比机器学习和深度学习
上面我们大概了解了机器学习和深度学习的工作原理,下面我们从几个重要的方面来对比两种技术。
1.数据依赖
随着数据量的增加,二者的表现有很大区别:
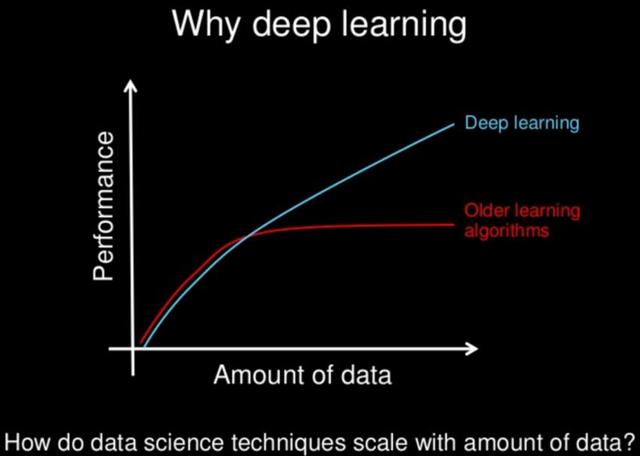 数据量对不同方法表现的影响
数据量对不同方法表现的影响
可以发现,深度学习适合处理大数据,而数据量比较小的时候,用传统机器学习方法也许更合适。
2.硬件依赖
深度学习十分地依赖于高端的硬件设施,因为计算量实在太大了!深度学习中涉及很多的矩阵运算,因此很多深度学习都要求有GPU参与运算,因为GPU就是专门为矩阵运算而设计的。相反,普通的机器学习随便给一台破电脑就可以跑。
3.特征工程
特征工程就是前面的案例里面讲过的,我们在训练一个模型的时候,需要首先确定有哪些特征。
在机器学习方法中,几乎所有的特征都需要通过行业专家在确定,然后手工就特征进行编码。
然而深度学习算法试图自己从数据中学习特征。这也是深度学习十分引人注目的一点,毕竟特征工程是一项十分繁琐、耗费很多人力物力的工作,深度学习的出现大大减少了发现特征的成本。
4.解决问题的方式
在解决问题时,传统机器学习算法通常先把问题分成几块,一个个地解决好之后,再重新组合起来。但是深度学习则是一次性地、端到端地解决。如下面这个物体识别的例子:
 物体识别
物体识别
如果任务是要识别出图片上有哪些物体,找出它们的位置。那么传统机器学习的做法是把问题分为两步:发现物体 和 识别物体。首先,我们有几个物体边缘的盒型检测算法,把所有可能的物体都框出来。然后,再使用物体识别算法,例如SVM在识别这些物体中分别是什么。
但是深度学习不同,给它一张图,它直接给出把对应的物体识别出来,同时还能标明对应物体的名字。这样就可以做到实时的物体识别。例如YOLO net就可以在视频中实时识别:
 实时检测
实时检测
5.运行时间
深度学习需要花大量的时间来训练,因为有太多的参数需要去学习。顶级的深度学习算法ResNet需要花两周的时间训练。但是机器学习一般几秒钟最多几小时就可以训练好。
但是深度学习花费这么大力气训练处模型肯定不会白费力气的,优势就在于它模型一旦训练好,在预测任务上面就运行很快。这才能做到我们上面看到的视频中实时物体检测。
6.可理解性
最后一点,也是深度学习一个缺点。其实也说不上是缺点吧,那就是深度学习很多时候我们难以理解。一个深层的神经网络,每一层都代表一个特征,而层数多了,我们也许根本就不知道他们代表的啥特征,我们就没法把训练出来的模型用于对预测任务进行解释。例如,我们用深度学习方法来批改论文,也许我们训练出来的模型对论文评分都十分的准确,但是我们无法理解模型到底是啥规则,这样的话,那些拿了低分的同学找你质问“凭啥我的分这么低啊?!”,你也哑口无言····因为深度学习模型太复杂,内部的规则很难理解。
但是机器学习不一样,比如决策树算法,就可以明确地把规则给你列出来,每一个规则,每一个特征,你都可以理解。
但是这不是深度学习的错,只能说它太牛逼了,人类还不够聪明,理解不了深度学习的内部的特征。
以上就是关于机器学习和深度学习的联系和区别了。首先说说感受吧,感觉很多国外的文章,尤其是这样的类似科普文章写的真心棒!很好理解,而且解释的非常详细,这是很多国内博客所不能比的。所以建议大家有问题可以多搜搜国外的文章读一读,而且其实英文也用的很简单。

