
- 1STM32控制电机的PID基础_pid stm32_stm32 pid
- 2MySQL子查询的注意事项知识点详解_子查询临时表_mysql不支持带子查询创建临时表
- 3最新区块链论文录用资讯CCF B— IWQOS 2024 共4篇_iwqos 2024接收论文
- 4基于Unity3D的AR射击游戏设计与实现 毕业论文+项目源码
- 52024年Java面经(附答案)
- 6Hadoop(二)答辩问题+答案_旅游酒店数据分析项目实战(hadoop)答辩
- 7python清洗数据教程_数据分析入门系列教程-数据清洗
- 8正确解决ModuleNotFoundError: No module named ‘cv2’异常的有效解决方法_modulenotfounderror: no module named 'cv2
- 9绿色水利,智慧未来:数字孪生技术在智慧水库建设中的应用,助力实现水资源的可持续利用与环境保护的双赢
- 10Spring Boot、kafka、spring-kafka 生产者消费者实践(从搭建kafka集群开始)_auto.create.topics.enable springboot
Python网络爬虫基础_dd.items
赞
踩
目录
目录
4.2通过name属性(getElementsByName)
4.3通过标签名(getElementsByTagName)
4.4通过类名(getElementsByClassName)
3.6 编写 Pipeline 来存储提取到的Item(即数据)
5. scrapy 使用 CrawlSpider 爬取百度百科
5.scrapy-redis项目的 settings.py 配置文件:
6. scrapy-redis项目的 爬取文件 文件(以爬取百度百科为例):
一、HTML基础
1.HTML相关概念&发展历史
1.1HTML及相关概念的介绍
HTML 指的是超文本标记语言 (Hyper Text Markup Language) 万维网的描述性语言。
XHTML指可扩展超文本标记语言(标识语言)(EXtensible HyperText Markup Language)是一种置标语言,表现方式与超文本标记语言(HTML)类似,不过语法上更加严格。
HTML5指的是HTML的第五次重大修改(第5个版本)(HTML5 是 W3C 与 WHATWG 合作的结果)
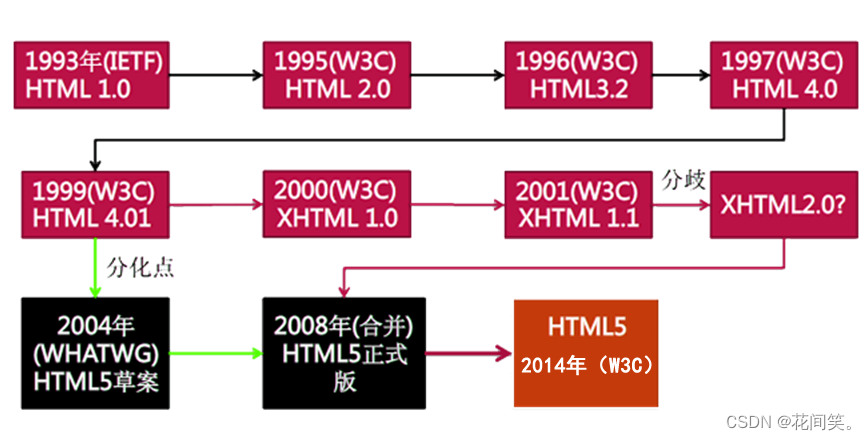
1.2HTML发展历史
 2.WEB标准、W3C/ECMA相关概念
2.WEB标准、W3C/ECMA相关概念
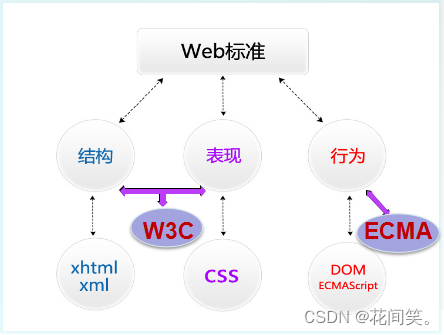
2.1WEB标准的概念及组成
2.2组织解析
W3C( World Wide Web Consortium )万维网联盟,创建于1994年是Web技术领域最具权威和影响力的国际中立性技术标准机构。W3C (制定了结构(html)和表现(css)的标准,非赢利性的。)
ECMA(European Computer Manufactures Association) 欧洲电脑场商联合会。ECMA制定了行为(DOM(文档对象模型),ECMAScript)标准
3.相关软件的应用以及站点的创建
3.1站点的作用
用来归纳一个网站上所有的网页、素材以及他们之间的联系
规划网站的所有内容和代码 整合资源
3.2创建站点的步骤
创建网页所需各个文件夹 css、js、images、html、font
3.3文件的命名规则
文件命名规则:用英文,不用中文
名称全部用小写英文字母、数字、下划线的组合,其中不得包含汉字、空格和特殊字符;必须以英文字母开头。
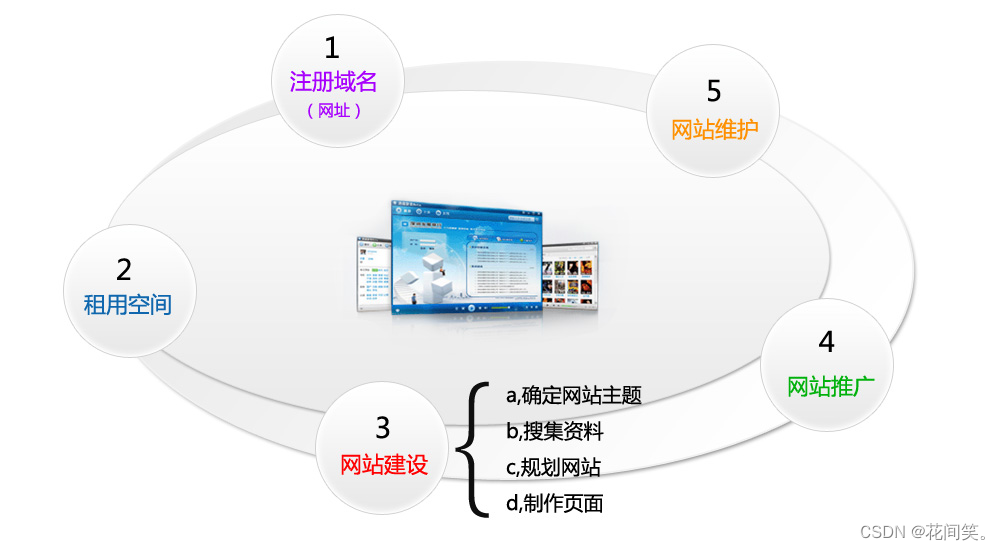
3.4网站建站流程
4.HTML基本结构和HTML基本语法
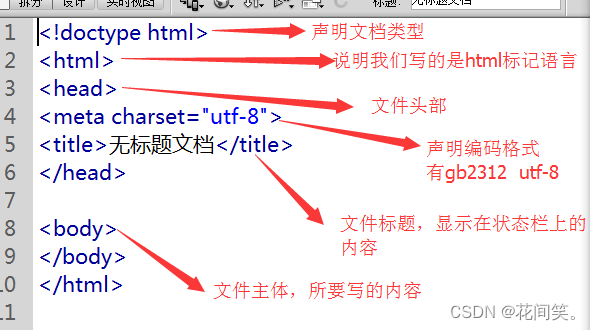
4.1HTML基本结构
4.2HTML基本语法
双标记/常规标记 <标记 属性=“属性值” 属性=“属性值”></标记> 例如:<head></head>
<div id="box"></div>单标记/空标记 <标记 属性=“属性值” /> 例如:<meta charset="utf-8" >
说明:
写在<>中的第一个单词叫做标记或标签或元素。
标记和属性用空格隔开,属性和属性值用等号连接,属性值必须放在“”号内。
一个标记可以没有属性也可以有多个属性,属性和属性之间不分先后顺序。
空标记没有结束标签,用“/”代替。
5.HTML常用标记
5.1文本标题
- <h1>一级标题</h1>
- <h2>二级标题</h2>
- <h3>二级标题</h3>
- <h4>二级标题</h4>
- <h5>二级标题</h5>
- <h6>六级标题</h6>
5.2段落文本
<p>段落文本内容</p>标识一个段落(段落与段落之间有段间距)
5.3空格
所占位置没有一个确定的值,这与当前字体字号都有关系.
5.4换行
<br />换行是一个空标记(强制换行)
5.5加粗
- <b>加粗内容</b>
- <strong>加粗内容</strong>
5.6倾斜
- <em>倾斜内容</em>
- <i>倾斜内容</i>
5.7水平线
<hr /> 5.8列表
HTML中有三种列表分别是:无序列表,有序列表,自定义列表
无序列表ul(unordered list)
- <ul>
- <li></li>
- <li></li>
- ...
- </ul>
有序列表ol(ordered list)
- <ol>
- <li></li>
- <li></li>
- ...
- </ol>
自定义列表dl(definition list)
- <dl>
- <dt>名词</dt>
- <dd>解释definition description</dd>
- ...
- </dl>
知识扩展: 有序列表的属性
type: 规定列表中的列表项目的项目符号的类型
语法:
<ol type="a"></ol>
说明:
1 数字顺序的有序列表(默认值)(1, 2, 3, 4)。
a 字母顺序的有序列表,小写(a, b, c, d)。
A 字母顺序的有序列表,大写(A,B,C,D)
i 罗马数字,小写(i, ii, iii, iv)。
I 罗马数字,大写(I, ii, iii, iv)。
start 属性规定有序列表的开始点。
语法:
<ol start="5"></ol>5.9插入图片
<img src="目标文件路径及全称" alt="图片替换文本" title="图片标题" />
title的作用:
在你鼠标悬停在该图片上时显示一个小提示,鼠标离开就没有了,HTML的绝大多数标签都支持title属性,title属性就是专门做提示信息的
alt的作用:
alt属性是在你的图片因为某种原因不能加载时在页面显示的提示信息,它会直接输出在原本加载图片的地方
相对路径的写法:
当当前文件与目标文件在同一目录下,写法如下:
直接书写目标文件文件名+扩展名: <img src="abc.jpg" />
当当前文件与目标文件所处的文件夹在同一目录下,写法如下:
文件夹名/目标文件全称+扩展名;<img src="images/abc.jpg" />
当当前文件所处的文件夹和目标文件所处的文件夹在同一目录下,写法如下:
../目标文件所处文件夹名/目标文件文件名+扩展名: <img src="../images/abc.jpg"/>5.10超链接
- <a href="目标文件路径及全称/连接地址" title="提示文本">链接文本/图片</a>
- <a href="#">空链接</a>
- <a href="#" target="_blank">新页面打开</a>
说明:
target: 页面打开方式,默认属性值_self
_blank: 新窗口打开
5.11表格
- <table width="value" height="value" border="value" bgcolor="value" cellspacing="value" cellpadding="value">
- <tr>
- <td></td>
- <td></td>
- </tr>
- </table>
说明:
一个tr表示一行;
一个td表示一列(一个单元格)
表格的相关属性:
width="表格的宽度"
height="表格的高度"
border="表格的边框"
bgcolor="表格的背景色" bg=background
bordercolor="表格的边框颜色"
cellspacing="单元格与单元格之间的间距"
cellpadding="单元格与内容之间的空隙"
对齐方式:align="left/center/right";
合并单元格属性:
colspan=“所要合并的单元格的列数"合并列;
rowspan=“所要合并单元格的行数”合并行;
5.12表单
表单的作用:
用来收集用户的信息的;
表单框
单行文本框
<input type="text" value="按钮内容" placeholder="默认提示文字" />密码框
<input type="password" placeholder="请输入密码" />按钮
单选框
说明:同一组单选框的name属性值必须一样, 相同name的单选框只能选择一个
checked: 默认选中
disabled: 禁用
复选框
说明:同一组复选框的name属性值必须一样, 相同name的复选框可以选择多个
下拉菜单
说明:
selected: 默认选中
文本域
5.13 div和span的用法
<div></div>说明:
块标签,没有具体含义
用来设置文档区域,是文档布局常用标签
<span></span>说明:
内联标签
可以是某一小段文本,或是某一个字。
5.14扩展知识点
<form name="表单名称" method="post/get" action=""></form>form中的获取数据的两个方式get和post的区别:
get主要是从服务器上获取数据,post主要是向服务器传送数据
get是把参数数据队列加到提交表单的action属性所指的url中,值和表单内各个字段一一对应,在url中可以看到; post是通过HTTP post机制,将表单内各个字段与其内容放置在HTML header 内一起传送到action属性所指的URL地址, 用户看不到这个过程, 安全性相对get较高
get传送的数据量较小,不能大于2KB; post传送的数据量较大,一般被默认为不受限制
get安全性非常低,post安全性较高
get执行效率比post方法好
建议:
get方式的安全性较post方式要差些,包含机密信息的话,建议用post数据提交方式;
在做数据查询时,建议用get方式;而在做数据添加、修改或删除时,建议用post方式;
二、CSS基础
1.CSS简介和CSS语法
1.1CSS简介
CSS英文全名:Cascading Style Sheets层叠样式表, WEB标准中的表现标准语言, 表现标准语言在网页中主要对网页信息的显示进行控制,简单说就是如何修饰网页信息的显示样式。 目前推荐遵循的是W3C发布的CSS3.0
1.2CSS语法
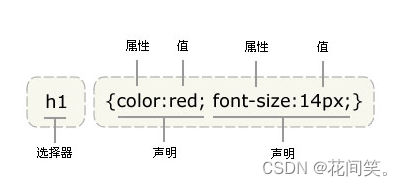
CSS语法:选择器 {属性:属性值;属性:属性值;}
说明:
每个CSS样式由两部分组成,即选择器和声明,声明又分为属性和属性值;
属性必须放在花括号中,属性与属性值用冒号连接。
每条声明用分号结束。
当一个属性有多个属性值的时候,属性值与属性值不分先后顺序。
在书写样式过程中,空格、换行等操作不影响属性显示。
2.引入CSS的三种方式及优先级
2.1引入CSS的三种方式
内联样式
语法:
说明:
使用style标签创建样式时,最好将该标记写在
<head></head>;外部样式
语法
<link rel="stylesheet" type="text/css" href="目标文件的路径及文件名全称" />说明:
使用link元素导入外部样式表时,需将该元素写在文档头部,即
<head></head>中间。rel(relation):用于定义文档关联,表示关联样式表;
type:定义文档类型;
行内样式 (或称:行间样式,行内样式,嵌入式样式)
<标签 style="属性:属性值;属性:属性值;"></标签>
2.2样式表的优先级
行内样式的优先级别最高
内联样式表与外部样式表的优先级和书写的顺序有关,后书写的优先级别高。
3.CSS选择器及选择器的权重
3.1CSS选择器
标签选择器/元素选择器
语法:
标签名 {属性:属性值;}
说明:
标签选择器就是以文档语言对象类型作为选择器,即使用结构中元素名称作为选择器
所有的页面元素都可以作为选择器
id选择器
语法:
#id名 {属性:属性值;}
说明:
当我们使用id选择器时,应该为每个元素定义一个id属性
如:
<div id="div1"></div>id选择器的语法格式是“#”加上自定义的id名
如:
#box{width:300px; height:300px;}起名时要取英文名,不能用关键字:(所有的标记和属性都是关键字)
如:head标记
一个id名称只能对应文档中一个具体的元素对象,因为id只能定义页面中某一个唯一的元素对象。
最大的用处:创建网页的外围结构。
class选择器
语法:
.class名 {属性:属性值;}
说明:
当我们使用class选择器时,应先为每个元素定义一个类名称
class选择器的语法格式是:如:
<div class="top"></div>用法:
页面中应大量使用class选择器定义样式;
通配符
语法:
*{属性:属性值;} 说明:
通配选择器的写法是“*”,其含义就是所有元素。 用法:
常用来重置样式。
群组选择器
语法:
选择器1,选择器2,选择器3{属性:属性值;}
说明:
当有多个选择器应用相同的样式时,可以将选择器用“,”分隔的方式,合并为一组。
包含选择器
语法:
选择器1 选择器2{属性:属性值;} 说明:
选择器1和选择器2用空格隔开,含义就是选择器1中包含的所有选择器2;
伪类选择器
语法 : a:link{属性:属性值;}超链接的初始状态; a:visited{属性:属性值;}超链接被访问后的状态; a:hover{属性:属性值;}鼠标悬停,即鼠标划过超链接时的状态; a:active{属性:属性值;}超链接被激活时的状态,即鼠标按下时超链接的状态; 说明:
当这4个超链接伪类选择器联合使用时,应注意他们的顺序,正常顺序为:
a:link,a:visited,a:hover,a:active,错误的顺序有时会使超链接的样式失效;
为了简化代码,可以把伪类选择器中相同的声明提出来放在a选择器中;
例如:a{color:red;} a:hover{color:green;} 表示超链接的三种状态都相同,只有鼠标划过变颜色。
3.2CSS选择器的权重
CSS中用四位数字表示权重,权重的表达方式如:0,0,0,0
标签选择符的权重为0001
class选择符的权重为0010
id选择符的权重为0100
属性选择符的权重为0010
伪类选择符的权重为0010
包含选择符的权重:为包含选择符的权中之和
内联样式的权重为1000
说明:
当不同选择器的样式设置有冲突的时候,高权重选择器的样式会覆盖低权重选择器的样式。
例如:b.demo的权重是1+10=11 .demo的权重是10 所以经常会发生.demo的样式失效
相同权重的选择器,样式遵循就近原则:哪个选择器最后定义,就采用哪个选择器样式。
4.浮动及清浮动
4.1浮动的使用
语法:
float: none/left/right;
三个取值:
left:元素活动浮动在文本左面 right:元素浮动在右面 none:默认值,不浮动。
浮动的目的:
就是让竖着的东西横着来
示例:
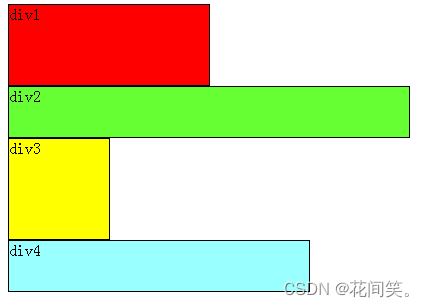
如下图, 首先要知道,div是块级元素,在页面中独占一行,自上而下排列,也就是传说中的流
可以看出,即使div1的宽度很小,页面中一行可以容下div1和div2,div2也不会排在div1后边,因为div元素是独占一行的
注意:
以上这些理论,是指标准流中的div。
无论多么复杂的布局,其基本出发点均是:“如何在一行显示多个div元素”。
显然标准流已经无法满足需求,这就要用到浮动。
浮动可以理解为让某个div元素脱离标准流,漂浮在标准流之上,和标准流不是一个层次。
4.2清浮动
元素浮动之前,也就是在标准流中,是竖向排列的,而浮动之后可以理解为横向排列 清除浮动可以理解为打破横向排列。 清除浮动的关键字是clear,语法: clear : none | left | right | both none : 默认值。允许两边都可以有浮动对象 left : 不允许左边有浮动对象 right : 不允许右边有浮动对象 both : 不允许有浮动对象
对于CSS的清除浮动(clear),一定要牢记:这个规则只能影响使用清除的元素本身,不能影响其他元素。
5.CSS核心属性
5.1CSS文本属性
文本大小:
{font-size: value;}
说明:
属性值为数值型时,必须给属性值加单位,属性值为0时除外。
单位还可以是pt,9pt=12px
文本颜色:
{color:颜色值;}
文本字体:
{font-family: 字体1,字体2,字体3;}
说明:
浏览器首先会寻找字体1、如在字体1不存在的情况下,则会寻找字体2,如字体2也不存在,按字体3显示内容,如果字体3 也不存在;则按系统默认字体显示;
文字加粗
{font-weight: bolder(更粗的)/bold(加粗)/normal(常规)/100—900;} 说明:
在css规范中,把字体的粗细分为9个等级,分别为100——900,其中100对应最轻的字体变形,而900对应最重的字体变形,
100-400 一般
500常规字体 600-900加粗字体
文字倾斜
{font-style:italic/oblique/normal(取消倾斜,常规显示);} 说明:
italic和oblique都是向右倾斜的文字, 但区别在于Italic是指斜体字,而Oblique是倾斜的文字,对于没有斜体的字体应该使用Oblique属性值来实现倾斜的文字效果.
水平对齐方式
{text-align:left/right/center/justify(两端对齐中文不起作用);}
文字行高 {line-height:normal/value;}
说明:
当单行文本的行高等于容器高时,可实现单行文本在容器中垂直方向居中对齐;
文本修饰
{text-decoration:none/underline/overline/line-through;} 说明:
none:没有修饰
underline:添加下划线
overline:添加上划线
line-through:添加删除线
首行缩进:
{text-indent:value;}
说明:
text-indent可以取负值;
text-indent属性只对第一行起作用。
字间距
{letter-spacing:value;}
说明:
控制英文字母或汉字的字距。(英文字母和字母)
5.2CSS列表属性
定义列表符号样式
list-style-type:disc(实心圆)/circle(空心圆)/square(实心方块)/none(去掉列表符号);
使用图片作为列表符号
list-style-image:url(所使用图片的路径及全称);
去掉列表符号
list-style:none;
5.3CSS背景属性
背景颜色
语法:
background-color:颜色值;
背景图片的设置
语法:
background-image:url(背景图片的路径及全称);
说明:
网页上有两种图片形式:插入图片、背景图;
插入图片:属于网页内容,也就是结构。
背景图:属于网页的表现,背景图上可以显示文字、插入图片、表格等。
背景图片的显示原则:
容器尺寸等于图片尺寸,背景图片正好显示在容器中
容器尺寸大于图片尺寸,背景图片将默认平铺,直至铺满元素;
容器尺寸小于图片尺寸,只显示元素范围以内的背景图。
背景图片平铺属性
语法:
background-repeat:no-repeat/repeat/repeat-x/repeat-y
说明:
no-repeat:不平铺 repeat:平铺 repeat-x:横向平铺 repeat-y :纵向平铺
背景图的固定
语法:
{background-attachment:scroll(滚动)/fixed(固定);
说明:
fixed; 固定,不随内容一块滚动;
scroll: 随内容一块滚动。
背景图片的位置
语法:
{background-position:left/center/right/数值 top/center/bottom/数值;}
说明:
水平方向上的对齐方式(left/center/right)或值
垂直方向上的对齐方式(top/center/bottom)或值
background-position:值1 值2;
两个值 :第一个值表示水平位置的值,第二个值:表示垂直的位置。
当两个值都是center的时候写一个值就可以代表的是水平位置和垂直位置
向左方向,向上方向是负值
定位
position属性: 表示设置元素的定位
属性值:
relative: 表示 相对于元素自身原来的位置做定位
absolute: 表示 相对于父元素的位置做定位
6.盒子模型
6.1认识盒子模型
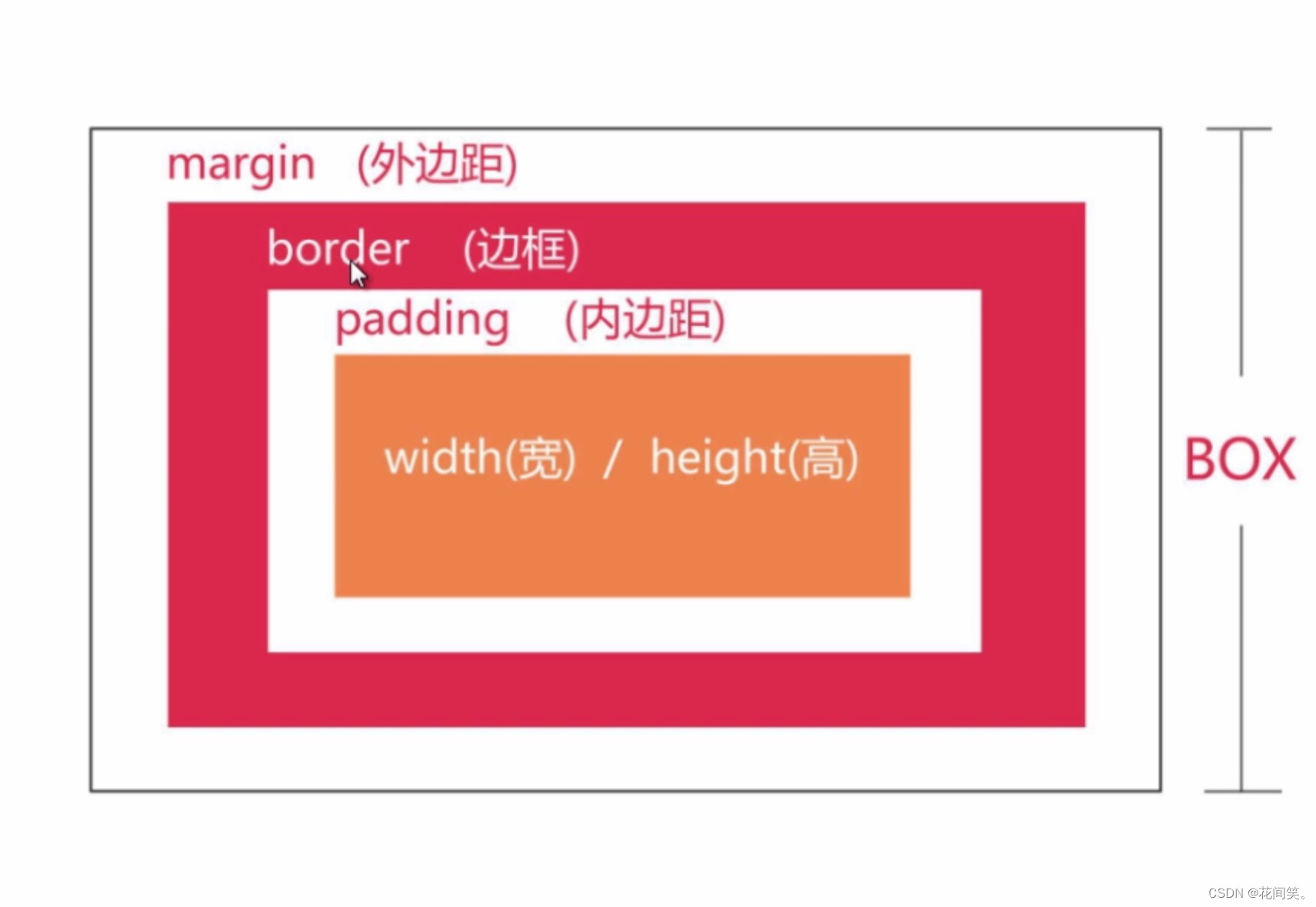
盒模型是css布局的基石,它规定了网页元素如何显示以及元素间相互关系。css定义所有的元素都可以拥有像盒子一样的外形和平面空间,即都包含边框、边界、补白、内容区,这就是盒模型。
6.2盒子模型的相关元素
边框属性border
语法:
{border: 边框宽度 边框风格 边框颜色;}
例如:
{border:5px solid #ff0000;} 说明:
边框宽度:border-width 边框样式:border-style:solid(实线)/dashed(虚线)dotted(点划线)double(双线)
边框颜色:border-color
可单独设置一方向边框
border-bottom:边框宽度 边框风格 边框颜色;底边框 border-left:边框宽度 边框风格 边框颜色;左边框 border-right:边框宽度 边框风格 边框颜色;右边框 border-top:边框宽度 边框风格 边框颜色;上边框
内边距padding
语法:
四个值:上 右 下 左 {padding:0px 0px 0px 40px;}
三个值:上 左右 下 {padding:10px 20px 30px ;}
二个值:上下 左右 {padding:10px 20px ;}
一个值:四个方向 padding:2px;/定义元素四周填充为2px/
说明:可单独设置一方向填充,如:上方向padding-top:10px; 右方向padding-right:10px; 下方向padding-bottom:10px; 左方向padding-left:10px;
用法:
用来调整内容在容器中的位置关系
用来调整子元素在父元素中的位置关系。
padding属性需要添加在父元素上。
padding值是额外加在元素原有大小之上的,如想保证元素大小不变,需从元素宽或高上减掉后添加的padding属性值
外边距margin
语法:
四个值:上 右 下 左
三个值:上 左 右 下
二个值:上下 左 右
一个值:四个方向 如:margin:2px;
说明:
可单独设置一方向边界,如:margin-top:10px;
margin-left:左边界
margin-right:右边界
margin-top:上边界
margin-bottom:下边界
水平居中:
margin:0 auto;
6.3盒子的实际大小
宽 =左右margin+左右border+左右padding+width,
高 =上下margin+上下border+上下padding+height,
例如:一个盒子的 margin 为 20px,border 为 1px,padding 为 10px,content 的宽为 200px、高为 50px,
宽=margin2 + border2 + padding2 + content.width = 202 + 12 + 102 +200 = 262px,
高=margin2 + border2 + padding2 + content.height = 202 + 12 +102 + 50 = 112px
三、JavaScript基础
1.JavaScript介绍和引入
1.1JavaScript介绍
JavaScript 的诞生
JavaScript 诞生于 1995 年。由Netscape(网景公司)的程序员Brendan Eich(布兰登)与Sun公司联手开发一门脚本语言, 最初名字叫做Mocha,1995年9月改为LiveScript。12月,Netscape公司与Sun公司(Java语言的发明者)达成协议,后者允许将这种语言叫做JavaScript。这样一来,Netscape公司可以借助Java语言的声势。1996年3月, Netscape公司的浏览器Navigator 2.0浏览器正式内置了JavaScript脚本语言. 此后其他主流浏览器逐渐开始支持JavaScript. 谷歌浏览器,火狐浏览器, IE浏览器, 欧朋浏览器, Safari浏览器
JavaScript组成:
ECMAScript : 包含JS语法
BOM : Brower Object Model 和浏览器相关的操作
DOM : Document Object Model 和页面内容相关的操作
JavaScript版本:
ES5, ES6, ES2020
1.2JavaScript引入
导入内部JavaScript:
<script type="text/javascript"></script>
在标签中间写js代码:
第一句javascript代码:alert(“hello world!”) ;
第二句javascript代码:document.write(“亲,我在页面上,跟alert不一样噢!”);
第三句javascript代码:console.log(“我是在控制台打印的, 以后常用我!”);
注意: document.write可以输出任何HTML的代码
script标签
script标签可以出现多次, 且可以出现在html文件的任何地方
同一个文件中Javascript和HTML代码, 它们的执行顺序都是自上而下,谁在前就谁先执行, 谁在后就后执行.
JavaScript的注释
单行注释: //
多行注释 /* */
外部javaScript文件引入:
<script type="text/javascript" src="demo1.js" ></script>注意:
在引入了外部文件的标签中写代码会无效
src 表示要引入的外部文件
2.JavaScript变量和数据类型
2.1JavaScript变量
变量定义(使用var关键字或者let):
赋值:
age = 20;定义的同时赋值:
var age = 20;可以一次定义多个变量:
var name="zhangsan", age=18, weight=108;JS是弱数据类型的语言,容错性较高, 在赋值的时候才确定数据类型
变量的命名规范
变量名可以是数字,字母,下划线_和 美元符
$组成;第一个字符不能为数字
不能使用关键字或保留字
标识符区分大小写,如:age和Age是不同的变量。但强烈不建议用同一个单词的大小写区分两个变量。
变量命名尽量遵守驼峰原则: myStudentScore小驼峰, 大驼峰MyStudentScore
变量命名尽量见名知意, age, users 数组
2.2JavaScript数据类型
- <!DOCTYPE html>
- <html>
- <head>
- <meta charset="utf-8">
- <title></title>
- </head>
- <body>
- </body>
- <script type="text/javascript">
- // 1.在js中声明变量,一般使用var关键字
- var age = 18
- // 不使用var关键字声明变量
- num = 98
- console.log(age)
- console.log(num)
- // 使用var关键字一次性声明多个变量
- var name1 = 'zhangsan'; sex = '男';
- console.log(name1,sex)
-
-
- // 2.js中常见的数据类型
- // a.布尔类型:true、false
- var bool = true;bool1 = false;
- console.log(bool,bool1)
-
- // b.undefined 表示未定义,声明了一个变量但是没有给变量赋值,那这个变量的值就是undefined
- var height
- console.log(height)
-
- // c.空类型 null
- null1 = null
- console.log(null1)
-
- // d.String 字符串类型,使用单引号或者双引号包裹的文字或字符串
- str1 = 'nihao'
- str2 = '世界'
- console.log(str1,str2)
-
- // e.Number类型
- num1 = 98
- float1 = 9.8
- console.log(num1, float1)
-
- // f.Array类型, 表示数组 类似于python中的列表
- arr = ['zhangsan','李四',true,1,1.1,false]
- console.log(arr)
-
- // g.Object类型 表示对象 类似于python中的字典
- obj = {"姓名":"张三","年龄":18,"性别":"男"};
- console.log(obj)
-
- // h.NaN not a number 不是一个数字
- num2 = 0/0
- console.log(num2)
-
- </script>
- </html>

3.js中的循环和函数
- for循环
- /* for 循环 */
-
- /* for(var i=1;i<=10;i++){
- console.log(i);
- } */
-
- /* for in 循环 */
- var arr = [12,34,"hello",true,null,3.23]
- for(i in arr){
- console.log(i,arr[i]);
- }
-
- /*
- js中的函数使用function 关键词声明
- js中函数调用可以在函数声明之前调用
- */
-
- function 函数名(){
- 函数体
- }
-
- demo()
- function demo(){
- console.log("在js中声明函数使用function关键词");
- }
- demo()
-
4.js中获取元素的方式
4.1通过ID获取(getElementById)
document.getElementById('id')
上下文必须是document。
必须传参数,参数是string类型,是获取元素的id。
返回值只获取到一个元素,没有找到返回null。
4.2通过name属性(getElementsByName)
document.getElementsByName('name')
上下文必须是document。内容
必须传参数,参数是是获取元素的name属性。
返回值是一个类数组,没有找到返回空数组。
4.3通过标签名(getElementsByTagName)
上下文可以是document,也可以是一个元素,注意这个元素一定要存在。
参数是是获取元素的标签名属性,不区分大小写。
返回值是一个类数组,没有找到返回空数组
4.4通过类名(getElementsByClassName)
上下文可以是document,也可以是一个元素。
参数是元素的类名。
返回值是一个类数组,没有找到返回空数组。
- <!DOCTYPE html>
- <html lang="en">
- <head>
- <meta charset="UTF-8">
- <meta http-equiv="X-UA-Compatible" content="IE=edge">
- <meta name="viewport" content="width=device-width, initial-scale=1.0">
- <title>Document</title>
- </head>
- <body>
- <div id="box">我是来演示js获取元素的方式的</div>
- <p class="wrap">我是演示class方式获取元素的</p>
- <span>无意义的标签</span>
-
- <div name="box1">我是name属性</div>
- </body>
- <script>
- /* 第一种:通过id属性获取元素 */
- var box = document.getElementById("box")
- console.log(box);
-
- /* 第二种:通过class属性获取元素 获取到的是一个集合 */
- var wrap = document.getElementsByClassName("wrap")[0]
- console.log(wrap);
-
- /* 第三种: 通过标签名获取元素 获取到是一个集合 */
- var span = document.getElementsByTagName("span")[0]
- console.log(span);
-
- /* 第四种:通过name属性获取元素 获取到的是一个集合 */
- var box1 = document.getElementsByName("box1")[0]
- console.log(box1);
- </script>
- </html>
5.js中的常用的事件
1.点击事件 click
2.鼠标移入事件 mouseover
3.鼠标移出事件 mouseout
4.获取焦点事件 focus
5.失去焦点事件 blur
四、爬虫基础
1.爬虫介绍
1.1什么是爬虫
爬虫:网络爬虫又称为网络蜘蛛Spider,网络蚂蚁,网络机器人等,可以自动化浏览网络中的信息,当然浏览信息的时候需要按照我们的规定的规则进行,这些规则称之为网络爬虫算法,使用python可以很方便的写出爬虫程序,进行互联网信息的自动化检索
网 : 互联网
蜘蛛网: 互联网理解为蜘蛛网
爬虫: 蜘蛛为什么学习爬虫
百度, 谷歌, 360搜索, bing搜索, ...
私人定制一个搜索引擎, 并且可以对搜索引擎的数采集工作原理进行更深层次地理解
获取更多的数据源,并且这些数据源可以按我们的目的进行采集,去掉很多无关数据
更好的进行seo(搜索引擎优化)
网络爬虫的组成
控制节点: 叫做爬虫中央控制器,主要负责根据URL地址分配线程,并调用爬虫节点进行具体爬行
爬虫节点: 按照相关算法,对网页进行具体爬行,主要包括下载网页以及对网页的文本处理,爬行后会将对应的爬行结果存储到对应的资源库中
资源库构成: 存储爬虫爬取到的响应数据,一般为数据库
爬虫设计思路
首先确定需要爬取的网页URL地址
通过HTTP协议来获取对应的HTML页面
提取html页面里的有用数据
如果是需要的数据就保存起来
如果是其他的URL,那么就执行第二部
1.2python爬虫的优势
PHP: 虽然是'世界上最好的语言',但是天生不是干爬虫的命,php对多线程,异步支持不足,并发不足,爬虫是工具性程序,对速度和效率要求较高。
Java: 生态圈完善,是Python最大的对手,但是java本身很笨重,代码量大,重构成本比较高,任何修改都会导致大量的代码的变动.最要命的是爬虫需要经常修改部分代码
# 爬虫 => 反爬 => 反反爬 => 反反反爬...C/C++: 运行效率和性能几乎最强,但是学习成本非常高,代码成型较慢,能用C/C++写爬虫,说明能力很强,但不是最正确的选择.
# SQL: 专门用于关系型数据库的
# Shell: 运维
# JavaScript: DOM,事件,Ajax
Python: 语法优美,代码简洁,开发效率高, 三方模块多,调用其他接口也方便, 有强大的爬虫Scrapy [:i],以及成熟高效的scrapy-redis分布策略
1.3爬虫需要掌握什么
Python基础语法
HTML基础 CSS基础1.如何抓取页面:
HTTP请求处理,urllib处理后的请求可以模拟浏览器发送请求,获取服务器响应文件
2.解析服务器响应的内容:
re,xpath,BeautifulSoup4,jsonpath,pyquery
目的是使用某种描述性语法来提取匹配规则的数据
如何爬取动态html,验证码处理:
通用的动态页面采集, Selenium+headless(无界面浏览器),模拟真实浏览器加载js,ajax等非静态页面数据Scrapy框架
国内常见的框架Scrapy, Pyspider
高定制性高性能(异步网络框架twisted),所以数据下载速度非常快,提供了数据存储,数据下载,提取规则等组件
(异步网络框架twisted类似tornado(和Django,Flask相比的优势是高并发,性能较强的服务器框架))分布式策略
scrapy-redis
在Scrapy的基础上添加了一套以redis数据库为核心的一套组件,让scrapy框架支持分布式的功能,主要在redis里做请求指纹去重,请求分配,数据临时存储
MySql(持久化), Redis, Mongodb(缓存,速度快)
2.Python3中开发爬虫
2.1urllib库和Requests库
Python urllib 库用于操作网页 URL,并对网页的内容进行抓取处理。
urllib 库 包含以下几个模块:
urllib.request - 打开和读取 URL。
urllib.error - 包含 urllib.request 抛出的异常。
urllib.parse - 解析 URL。
urllib.robotparser - 解析 robots.txt 文件。# 用户代理,是http协议的一部分,属于请求头的一部分.
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36"
Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库。与urllib相比,Requests更加方便,可以节约我们大量的工作,建议爬虫使用Requests库。
安装requests库
pip install requestsrequests提供的请求各个请求方式:
import requests
requests.get(url)
requests.post(url)
requests.put(url)
requests.delete(url)
requests.head(url)
requests.options(url)
2.2get请求
get请求核心代码是requests.get(url),具体例子如下:
- import requests
- url = 'http://baidu.com'
- response = requests.get(url)
- print(response)
- # 打印出来的结果是:<Response [200]>。<>表示这是一个对象,也就是我们这里获取的是一个response的对象,200表示状态码。
2.3post请求
post请求核心代码是requests.post(url,data={请求体的字典}) (有道翻译案例)如下:
- import requests
- content = input("请输入要翻译的内容:")
-
- # 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule' 这个地址中 translate_o 中的_o是做反爬处理的.
- url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
- payload = {
- 'i': content,
- 'from': 'AUTO',
- 'to': 'AUTO',
- 'smartresult': 'dict',
- 'client': 'fanyideskweb',
- 'salt': '16602050495227',
- 'sign': '38d3f52fdb8952994ef7a90415db53d0',
- 'lts': '1660205049522',
- 'bv': '6de9a02717bddd1865a0f73c00d7db8c',
- 'doctype': 'json',
- 'version': '2.1',
- 'keyfrom': 'fanyi.web',
- 'action': 'FY_BY_REALTlME'
- }
- r = requests.post(url,data=payload) #post请求,并提交表单数据
- trans_json = r.json() #由F12能看出返回的数据是json格式,但python不知道,所以这边定义了返回来的数据为json格式,方便之后操作
- res = trans_json["translateResult"][0][0]['tgt']
- print("翻译的结果是:") #打印看返回来的数据对不对
- print(res)
2.4response方法
- '''
- 获取网页的解码字符串
- 不管是get请求还是post请求,我们得到的返回都是一个Response[200]的对象,但是我们想要得到的,应该是与网页response下一样的字符串对象,这时就需要用到response的方法了。
- 在这里我总结了一下三种获取网页源码的三种方式,通过这三种方式,一定可以获取到网页正确解码之后的字符串:
- '''
- response.content.decode()
- response.content.decode('gbk')
- response.text
获取其他属性
- import requests
- response = requests.get("https://www.baidu.com")
- print(type(response.request.headers),response.request.headers) #获取请求头
- print(type(response.headers),response.headers) #获取响应头
- print(type(response.cookies),response.cookies)#获取响应cookie
- print(type(response.url),response.url) #获取响应url
- print(type(response.request.url),response.request.url) #获取请求url
2.5示例: urllib库爬取百度
- import urllib
- from urllib import request
-
- headers = {
- "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"
- }
-
- # 创建请求对象
- req = urllib.request.Request("http://www.baidu.com", headers=headers)
-
- response = urllib.request.urlopen(req)
- print(response.info()) # 响应信息
- print(response.read()) # 二进制
- print(response.read().decode('utf-8')) # 字符串
2.6示例:urllib库模拟百度搜索
- import urllib.request
- import urllib.parse
-
- # 模拟百度搜索
- def baiduAPI(params):
- headers = {
- "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"
- }
-
- url = "https://www.baidu.com/s?" + params
- req = urllib.request.Request(url, headers=headers)
- response = urllib.request.urlopen(req)
- return response.read().decode('utf-8')
-
- if __name__ == "__main__":
- kw = input("请输入你要查找的内容:")
- wd = {"wd": kw}
- params = urllib.parse.urlencode(wd)
- # print(params) # 'wd=aa'
-
- response = baiduAPI(params)
- print(response)
2.7示例: urllib库爬取前程无忧岗位数量
- import urllib.request
- import re
-
- headers = {
- "Cookie":"", # 设置用户登录账户信息
- "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36"
- }
-
- url = 'https://search.51job.com/list/040000,000000,0000,00,9,99,python,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare='
-
- # 发送请求获取51job的数据
-
- req = urllib.request.Request(url,headers=headers)
- res = urllib.request.urlopen(req)
- result = res.read().decode("gbk")
-
- # print(result)
-
- # 通过正则表达式获取岗位的总数量 jobid_count
- job = re.findall('"jobid_count":"(.*?)"',result,re.S)
- print(job)
2.8urllib库下载文件
- # 参数1: 需要下载的url
- # 参数2: 需要写入的文件路径
- request.urlretrieve("http://www.baidu.com", r"baidu.html")
- request.urlcleanup() # 清除缓存
-
- # 下载图片
- request.urlretrieve("https://www.baidu.com/img/bd_logo1.png", r"baidu.png")
- request.urlcleanup() # 清除缓存
2.9抓取ajax数据
示例:抓取豆瓣电影
- import urllib
- from urllib import request
- import json
-
- headers = {
- 'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
- }
-
- url = "https://movie.douban.com/j/new_search_subjects?sort=T&range=0,10&tags=&start=0"
-
- req = urllib.request.Request(url, headers=headers)
- response = urllib.request.urlopen(req)
- content = response.read().decode() # json数据
-
- data = json.loads(content)
- movie_list = data.get('data')
-
- for movie in movie_list:
- title = movie.get('title')
- casts = movie.get('casts')
- print(title, casts)
-
2.10使用requests库爬取猫眼电影
- import requests
- import re
-
- url = 'https://maoyan.com/films?offset=0'
- headers = {
- # 用户代理
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'
- }
-
- res = requests.get(url, headers=headers)
-
- #定义正则表达式
- dl = re.findall('<dl class="movie-list">(.*?)</dl>', res.text, re.S)
- # print(dl)
- #电影名
- name_list = re.findall('<div class="channel-detail movie-item-title" title="(.*?)">', dl[0], re.S)
- # print(name_list)
- #评分
- score_list = re.findall('<div class="channel-detail channel-detail-orange">(.*?)</div>', dl[0], re.S)
- # print(score_list)
-
- s_score = []
- for score in score_list:
- if score == "暂无评分":
- s_score.append(score)
- else:
- score1 = re.findall('<i class="integer">(.*?)</i>', score, re.S)[0]
- score2 = re.findall('<i class="fraction">(.*?)</i>', score, re.S)[0]
- s_score.append(score1 + score2)
- # print(name_list)
- # print(s_score)
- m_dict = {}
- count = 0
- for i in name_list:
- m_dict[i] = s_score[count]
- count += 1
- for k,v in m_dict.items():
- print(f"{k}:{v}")
3.Cookie
Cookie 是指某些网站服务器为了辨别用户身份和进行会话跟踪,而储存在用户浏览器上的文本文件,Cookie可以保持登录信息到用户下次与服务器的会话。
Cookie原理
HTTP是无状态的协议, 为了保持连接状态, 引入了Cookie机制 Cookie是http消息头中的一种属性,包括:
Cookie名字(Name)
Cookie的值(Value)
Cookie的过期时间(Expires/Max-Age)
Cookie作用路径(Path)
Cookie所在域名(Domain),
使用Cookie进行安全连接(Secure)。前两个参数是Cookie应用的必要条件,另外,还包括Cookie大小(Size,不同浏览器对Cookie个数及大小限制是有差异的)。
Cookie由变量名和值组成,根据 Netscape公司的规定,Cookie格式如下:
Set-Cookie: NAME=VALUE;Expires=DATE;Path=PATH;Domain=DOMAIN_NAME;SECURE
4.代理ip的使用
- import requests
-
- # 1.未使用ip代理
-
- #http://httpbin.org/ip 可以查看使用的访问ip
- url = 'http://httpbin.org/ip'
- #
- req = requests.get(url)
-
- print(req.text)
-
- # 2。使用代理ip
-
- # 定义要使用的ip地址
- proxy = {
- 'http': 'http://' + '119.249.47.166:4231',
- 'https': 'http://' + '119.249.47.166:4231'
- }
-
- #在真实的项目中,只需要将在请求的地方添加proxies参数即可
- req = requests.get(url,proxies=proxy)
- print(req.text)
5.HTTP响应状态码参考
1xx:信息
100 Continue
服务器仅接收到部分请求,但是一旦服务器并没有拒绝该请求,客户端应该继续发送其余的请求。
101 Switching Protocols
服务器转换协议:服务器将遵从客户的请求转换到另外一种协议。
2xx:成功200 OK
请求成功(其后是对GET和POST请求的应答文档)
201 Created
请求被创建完成,同时新的资源被创建。
202 Accepted
供处理的请求已被接受,但是处理未完成。
203 Non-authoritative Information
文档已经正常地返回,但一些应答头可能不正确,因为使用的是文档的拷贝。
204 No Content
没有新文档。浏览器应该继续显示原来的文档。如果用户定期地刷新页面,而Servlet可以确定用户文档足够新,这个状态代码是很有用的。
205 Reset Content
没有新文档。但浏览器应该重置它所显示的内容。用来强制浏览器清除表单输入内容。
206 Partial Content
客户发送了一个带有Range头的GET请求,服务器完成了它。
3xx:重定向300 Multiple Choices
多重选择。链接列表。用户可以选择某链接到达目的地。最多允许五个地址。
301 Moved Permanently
所请求的页面已经转移至新的url。
302 Moved Temporarily
所请求的页面已经临时转移至新的url。
303 See Other
所请求的页面可在别的url下被找到。
304 Not Modified
未按预期修改文档。客户端有缓冲的文档并发出了一个条件性的请求(一般是提供If-Modified-Since头表示客户只想比指定日期更新的文档)。服务器告诉客户,原来缓冲的文档还可以继续使用。
305 Use Proxy
客户请求的文档应该通过Location头所指明的代理服务器提取。
306 Unused
此代码被用于前一版本。目前已不再使用,但是代码依然被保留。
307 Temporary Redirect
被请求的页面已经临时移至新的url。
4xx:客户端错误400 Bad Request
服务器未能理解请求。
401 Unauthorized
被请求的页面需要用户名和密码。
401.1
登录失败。
401.2
服务器配置导致登录失败。
401.3
由于 ACL 对资源的限制而未获得授权。
401.4
筛选器授权失败。
401.5
ISAPI/CGI 应用程序授权失败。
401.7
访问被 Web 服务器上的 URL 授权策略拒绝。这个错误代码为 IIS 6.0 所专用。
402 Payment Required
此代码尚无法使用。
403 Forbidden
对被请求页面的访问被禁止。
403.1
执行访问被禁止。
403.2
读访问被禁止。
403.3
写访问被禁止。
403.4
要求 SSL。
403.5
要求 SSL 128。
403.6
IP 地址被拒绝。
403.7
要求客户端证书。
403.8
站点访问被拒绝。
403.9
用户数过多。
403.10
配置无效。
403.11
密码更改。
403.12
拒绝访问映射表。
403.13
客户端证书被吊销。
403.14
拒绝目录列表。
403.15
超出客户端访问许可。
403.16
客户端证书不受信任或无效。
403.17
客户端证书已过期或尚未生效。
403.18
在当前的应用程序池中不能执行所请求的 URL。这个错误代码为 IIS 6.0 所专用。
403.19
不能为这个应用程序池中的客户端执行 CGI。这个错误代码为 IIS 6.0 所专用。
403.20
Passport 登录失败。这个错误代码为 IIS 6.0 所专用。
404 Not Found
服务器无法找到被请求的页面。
404.0
没有找到文件或目录。
404.1
无法在所请求的端口上访问 Web 站点。
404.2
Web 服务扩展锁定策略阻止本请求。
404.3
MIME 映射策略阻止本请求。
405 Method Not Allowed
请求中指定的方法不被允许。
406 Not Acceptable
服务器生成的响应无法被客户端所接受。
407 Proxy Authentication Required
用户必须首先使用代理服务器进行验证,这样请求才会被处理。
408 Request Timeout
请求超出了服务器的等待时间。
409 Conflict
由于冲突,请求无法被完成。
410 Gone
被请求的页面不可用。
411 Length Required
"Content-Length" 未被定义。如果无此内容,服务器不会接受请求。
412 Precondition Failed
请求中的前提条件被服务器评估为失败。
413 Request Entity Too Large
由于所请求的实体的太大,服务器不会接受请求。
414 Request-url Too Long
由于url太长,服务器不会接受请求。当post请求被转换为带有很长的查询信息的get请求时,就会发生这种情况。
415 Unsupported Media Type
由于媒介类型不被支持,服务器不会接受请求。
416 Requested Range Not Satisfiable
服务器不能满足客户在请求中指定的Range头。
417 Expectation Failed
执行失败。
423
锁定的错误。
5xx:服务器错误500 Internal Server Error
请求未完成。服务器遇到不可预知的情况。
500.12
应用程序正忙于在 Web 服务器上重新启动。
500.13
Web 服务器太忙。
500.15
不允许直接请求 Global.asa。
500.16
UNC 授权凭据不正确。这个错误代码为 IIS 6.0 所专用。
500.18
URL 授权存储不能打开。这个错误代码为 IIS 6.0 所专用。
500.100
内部 ASP 错误。
501 Not Implemented
请求未完成。服务器不支持所请求的功能。
502 Bad Gateway
请求未完成。服务器从上游服务器收到一个无效的响应。
502.1
CGI 应用程序超时。 ·
502.2
CGI 应用程序出错。
503 Service Unavailable
请求未完成。服务器临时过载或当机。
504 Gateway Timeout
网关超时。
505 HTTP Version Not Supported
服务器不支持请求中指明的HTTP协议版本
五、bs4&XPath
1.bs4
1.1Beautiful Soup 4 文档
Beautiful Soup 4.2.0 文档 — Beautiful Soup 4.2.0 documentation
1.安装beautifulsoup4
pip install beautifulsoup42.安装解析器
pip install lxml
1.2bs4基本使用
- '''
- 1.安装beautifulsoup4
- pip install beautifulsoup4
- 2.安装解析器
- pip install lxml
- '''
- from bs4 import BeautifulSoup
- import re
-
- html = '''
- <html>
- <head>
- <title>hello world</title>
- </head>
- <body>
- <p class="title"><b>The Dormouse's story</b></p>
- <p class="story">Once upon a time there were three little sisters; and their names were
- <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
- <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
- <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
- and they lived at the bottom of a well.</p>
- <p class="story">...</p>
- </body>
- </html>
- '''
-
- # 创建bs4对象
- soup = BeautifulSoup(html, "lxml") #或者使用 html.parser 解析
- # print(soup.prettify(),type(soup)) # <class 'bs4.BeautifulSoup'>
-
- # 通过标签名获取元素
- # print(soup.head)
- # print(soup.p) # 文档中有多个p标签,默认匹配第一个p标签
- # print(soup.p.b)
-
- # 获取标签中的文本内容
- # print(soup.p.b.text)
- # print(soup.head.title.text)
- # print(soup.head.title.string)
-
- # 属性 attributes
- # print(soup.p.attrs) # {'class': ['title']}
- # print(soup.a.attrs) # {'href': 'http://example.com/elsie', 'class': ['sister'], 'id': 'link1'}
-
- # print(soup.a.attrs['id']) # link1
- # print(soup.a['id']) # link1
-
- ''' find_all():匹配所有的节点 '''
-
- # print(soup.find_all('p'))
- # print(soup.find_all("a"))
- # print(soup.find_all("a", attrs={"id":"link1"})) # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
-
- # print(soup.find_all("a",id="link1"))
- # print(soup.find_all("a",href=re.compile("cie$")))
-
- # print(soup.find_all(class_="sister"))
-
- # print(soup.find_all("a",limit=2)) # 表示取前两个a标签
-
- # print(soup.find_all(["a","b"])) # 同时获取所有的a标签和b标签
- # print(soup.p.find_all("b"))
-
- '''
- select() 需要使用选择器
- id选择器 class选择器 标签选择器 伪类选择器 群组选择器 子元素选择器
- '''
- print(soup.select("#link2"))
- print(soup.select(".sister"))
- print(soup.select("p a"))
1.3示例:bs4 爬取猫眼电影
- import requests
- from bs4 import BeautifulSoup
- import lxml
-
- headers = {
- "user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"
- }
- url = "https://maoyan.com/films?offset=0"
- res = requests.get(url,headers = headers)
- # print(res.text)
-
- # 创建bs4对象
- soup = BeautifulSoup(res.text,'lxml')
-
- dd_list = soup.select('.movie-list dd')
- # print(dd_list)
-
- for dd in dd_list:
- # 电影名称:
- movie_name = dd.select('.movie-item-title')[0]['title']
-
- # 评分
- scores = dd.select('.channel-detail-orange')[0].text
- # print(scores)
-
- with open('maoyan.csv','a',encoding='utf-8') as fp:
- str = f"{movie_name},{scores}\n\n"
- fp.write(str)
- fp.flush()
1.4示例:爬取股票基金
- import urllib
- from urllib import request
- from bs4 import BeautifulSoup
-
- stockList = []
-
- def download(url):
- headers = {"User-Agent": "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0);"}
- request = urllib.request.Request(url, headers=headers) # 请求,修改,模拟http.
- data = urllib.request.urlopen(request).read() # 打开请求,抓取数据
-
- soup = BeautifulSoup(data, "lxml", from_encoding="gb2312")
- mytable = soup.select("#datalist")
- for line in mytable[0].find_all("tr"):
- print(line.get_text()) # 提取每一个行业
- print(line.select("td:nth-of-type(3)")[0].text) # 提取具体的某一个
-
- if __name__ == '__main__':
- download("http://quote.stockstar.com/fund/stock.html")
-
1.5存入数据库
- import pymysql
-
- # 存入数据库
- def save_job(tencent_job_list):
- # 连接数据库
- db = pymysql.connect(host="127.0.0.1", port=3306, user='XXX', password="XXX",database='tencent1', charset='utf8')
- # 游标
- cursor = db.cursor()
- # 遍历,插入job
- for job in tencent_job_list:
- sql = 'insert into job(name, address, type, num) VALUES("%s","%s","%s","%s") ' % (job["name"], job["address"], job["type"], job["num"])
- cursor.execute(sql)
- db.commit()
-
- cursor.close()
- db.close()
2.XPath
XPath即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言。XPath基于XML的树状结构,有不同类型的节点,包括元素节点,属性节点和文本节点,提供在数据结构树中找寻节点的能力。
2.1什么是 XPath?
XPath 使用路径表达式在 XML 文档中进行导航
XPath 包含一个标准函数库
XPath 是 XSLT 中的主要元素
XPath 是一个 W3C 标准
2.2使用xpath
2.2.1 安装lxml
pip install lxml
import lxml
from lxml import etree
2.2.2 XPath 术语
1)节点(Node)
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。XML 文档是被作为节点树来对待的。树的根被称为文档节点或者根节点。
请看下面这个 XML 文档:
2)基本值(或称原子值,Atomic value)
基本值是无父或无子的节点。
3)项目(Item)
项目是基本值或者节点。
4)节点关系
父(Parent)
每个元素以及属性都有一个父。
子(Children)
元素节点可有零个、一个或多个子。
同胞(Sibling)
拥有相同的父的节点
先辈(Ancestor)
某节点的父、父的父,等等。
后代(Descendant)
某个节点的子,子的子,等等。
2.3 选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。 下面列出了最有用的路径表达式:
表达式 描述 / 表示的是从根节点开始定位,表示的是一个层级. // 表示的是多个层级,可以表示从任意位置开始定位. . 选取当前节点。 .. 选取当前节点的父节点。 @ 选取属性。 /text() 获取的是标签中直系的文本内容 //text() 获取标签中的非直系的文本内容(所有的文本内容) 在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
路径表达式 结果 /bookstore 选取根元素 bookstore。注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! /bookstore/book 选取属于 bookstore 的子元素的所有 book 元素。 //book 选取所有 book 子元素,而不管它们在文档中的位置。 /bookstore//book 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 //@lang 选取名为 lang 的所有属性。 谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
路径表达式 结果 /bookstore/book[1] 选取属于 bookstore 子元素的第一个 book 元素。 /bookstore/book[last()] 选取属于 bookstore 子元素的最后一个 book 元素。 /bookstore/book[last()-1] 选取属于 bookstore 子元素的倒数第二个 book 元素。 /bookstore/book[position()<3] 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 //title[@lang] 选取所有拥有名为 lang 的属性的 title 元素。 //title[@lang='eng'] 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 /bookstore/book[price>35.00] 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 /bookstore/book[price>35.00]/title 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
通配符 描述 * 匹配任何元素节点。 @* 匹配任何属性节点。 node() 匹配任何类型的节点。 在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
路径表达式 结果 /bookstore/* 选取 bookstore 元素的所有子元素。 //* 选取文档中的所有元素。 //title[@*] 选取所有带有属性的 title 元素。
选取若干路径
通过在路径表达式中使用"|"运算符,您可以选取若干个路径。
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
路径表达式 结果 //book/title | //book/price 选取 book 元素的所有 title 和 price 元素。 //title | //price 选取文档中的所有 title 和 price 元素。 /bookstore/book/title | //price 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。
- from lxml import etree
-
- xml = """
- <!DOCTYPE html>
- <html lang="en">
- <head>
- <meta charset="UTF-8">
- <title>Title</title>
- </head>
- <body>
- <div class="box">hello world</div>
- <p class="wrap">
- <b>hello 树先生!</b>
- </p>
- <p class="haha">
- <a href="https://www.baidu.com" id="baidu">百度一下</a>
- <a href="https://www.baidu.com" id="sina">新浪财经</a>
- <a href="https://www.baidu.com" id="fenghuang">凤凰新闻</a>
- </p>
- </body>
- </html>
- """
- # 创建xpath对象
- mytree = etree.HTML(xml)
- # print(mytree)
-
- # 1./ 子节点 //后代节点
- # 子节点演示
- # print(mytree.xpath("/html/head"))
- # 后代节点的样式 // 表示从全文件中查找节点
- # print(mytree.xpath("//head"))
- # 查找p标签里面的a标签
- # print(mytree.xpath("//p/a"))
-
- # 2.获取标签中的内容 text()
- #print(mytree.xpath("//p/a/text()")) # ['百度一下', '新浪财经', '凤凰新闻']
- # print(mytree.xpath("//p/b/text()")) # ['hello 树先生!']
-
- # 3.获取标签的属性 @属性
- # 获取p标签的class属性的值
- # print(mytree.xpath("//p/@class")) # ['wrap', 'haha']
- # 获取a标签的id属性的值
- # print(mytree.xpath("//a/@id")) # ['baidu', 'sina', 'fenghuang']
-
- # 4.谓语 添加过滤条件 注意:下标从1开始
- # print(mytree.xpath('//p/a[@id="sina"]/text()')) # ['新浪财经']
- # print(mytree.xpath('//p/a[2]/text()')) # ['新浪财经']
- # last() 表示最后一个
- # print(mytree.xpath("//p/a[last()]/text()")) # ['凤凰新闻']
- # last()-1 表示倒数第二个
- # print(mytree.xpath("//p/a[last()-1]/text()")) # ['新浪财经']
- # 表示获取前两个a标签中的内容
- # print(mytree.xpath("//p/a[position() < 3]/text()"))
-
- # 5.通配符 * 表示可以匹配任意节点
- print(mytree.xpath('//*[@id="baidu"]/text()')) # ['百度一下']
-
2.4 xpath解析猫眼电影
- from lxml import etree
- import requests
- from fake_useragent import UserAgent
- # 设置访问头
- header = {
- 'User-Agent': UserAgent().random
- }
- # 定义访问地址
- url = "https://www.maoyan.com/films?offset=0"
- # 发起请求
- res = requests.get(url, headers=header)
- # 声明对象
- mytree = etree.HTML(res.text)
- # 获取电影名称
- names = mytree.xpath('//*[@class="channel-detail movie-item-title"]/a/text()')
- # print(names)
- # 获取评分对象
- scores = mytree.xpath('//*[@class="channel-detail channel-detail-orange"]')
- # print(scores)
- # 用于存储电影评分
- scores_list = []
- # 解析评分对象
- for i in scores:
- if i.xpath('./text()'):
- scores_list.append('暂无评分')
- else:
- int1 = i.xpath('./i[1]/text()')[0]
- float1 = i.xpath('./i[2]/text()')[0]
- scores_list.append(int1 + float1)
- # print(scores_list)
- # 将电影名及对应的评分写入文件中
- for key, value in enumerate(names):
- with open('maoyan1.csv', 'a', encoding='utf-8') as f:
- str1 = f"{value},{scores_list[key]}\n"
- f.write(str1)
- f.flush()
六、Scrapy 框架介绍
1.robots协议
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。robots.txt文件是一个文本文件。当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。
- User-agent: * 这里的*代表的所有的搜索引擎种类,*是一个通配符
- Disallow: /admin/ 这里定义是禁止爬寻admin目录下面的目录
- Disallow: /require/ 这里定义是禁止爬寻require目录下面的目录
- Disallow: /ABC/ 这里定义是禁止爬寻ABC目录下面的目录
- Disallow: /cgi-bin/*.htm 禁止访问/cgi-bin/目录下的所有以".htm"为后缀的URL(包含子目录)。
- Disallow: /*?* 禁止访问网站中所有包含问号 (?) 的网址
- Disallow: /.jpg$ 禁止抓取网页所有的.jpg格式的图片
- Disallow:/ab/adc.html 禁止爬取ab文件夹下面的adc.html文件。
- Allow: /cgi-bin/ 这里定义是允许爬寻cgi-bin目录下面的目录
- Allow: /tmp 这里定义是允许爬寻tmp的整个目录
- Allow: .htm$ 仅允许访问以".htm"为后缀的URL。
- Allow: .gif$ 允许抓取网页和gif格式图片
- Sitemap: 网站地图 告诉爬虫这个页面是网站地图
- 实例分析:淘宝网的 robots.txt文件
- http://www.taobao.com/robots.txt
-
- 内容如下:
- User-agent: Baiduspider
- Disallow: /
-
- User-agent: baiduspider
- Disallow: /
-
- 很显然淘宝不允许百度的机器人访问其网站下其所有的目录。
-
- 51job的robots协议
- https://www.51job.com/robots.txt
2.Scrapy框架
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
Scrapy框架:用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
Scrapy 使用了Twisted(其主要对手是Tornado)多线程异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
Scrapy架构图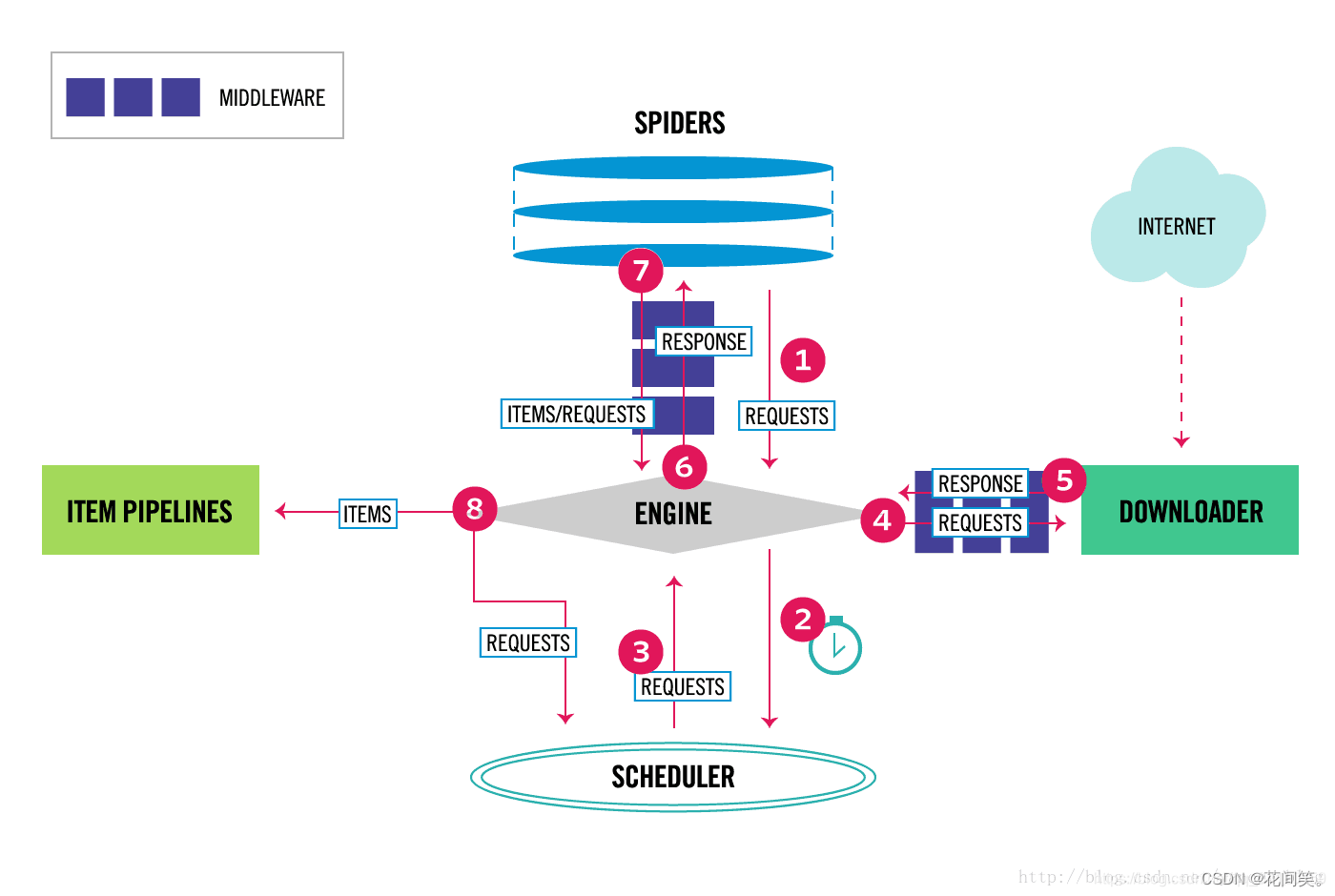
Scrapy主要包括了以下组件:
Scrapy Engine(引擎):
负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。Scheduler(调度器):
它负责接受`引擎`发送过来的Request请求,并按照一定的方式进行整理排列,入队,当`引擎`需要时,交还给`引擎`。Downloader(下载器):
负责下载`Scrapy Engine(引擎)`发送的所有Requests请求,并将其获取到的Responses交还给`Scrapy Engine(引擎)`,由`引擎`交给`Spider`来处理,Spider(爬虫):
它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给`引擎`,再次进入`Scheduler(调度器)`,Item Pipeline(管道):
它负责处理`Spider`中获取到的Item,并进行后期处理(详细分析、过滤、存储等)的地方.Downloader Middlewares(下载中间件):
你可以当作是一个可以自定义扩展下载功能的组件。Spider Middlewares(Spider中间件):
你可以理解为是一个可以自定扩展和操作`引擎`和`Spider`中间`通信`的功能组件(比如进入`Spider`的Responses和从`Spider`出去的Requests)
scrapy调度流程:
1、引擎说:在吗?爬虫老弟,搞起来啊!
2、Spider说:在的,引擎大哥,来来来,开始吧。今天就爬xxx网站怎么样
3、引擎:没问题,入口URL发过来!
4、Spider:嗯呐,入口URL是https://ww.xxx.com。
5、引擎:调度器老弟,我这有request请求你帮我排序入队一下吧。
6、调度器:引擎老哥,这是我处理好的request请求。
7、引擎:下载器老弟,你按照下载中间件的设置帮我下载一下这个request请求,可以吗?。
8、下载器:收到,引擎大哥,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)
9、引擎:爬虫老弟,这是下载好的东西,下载器已经按照下载中间件处理过了,你自己处理一下吧。
10、Spider:引擎老哥,我的数据处理完毕了,这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。
11、引擎:管道老弟,我这儿有个item你帮我处理一下!
12、引擎:调度器老弟,这是需要跟进URL你帮我处理下。(然后从第四步开始循环,直到获取完需要全部信息)
2.1安装Scrapy
Scrapy的安装介绍
Scrapy框架官方网址:http://doc.scrapy.org/en/latest
Scrapy中文维护站点:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html
安装方式:
pip install scrapy
如果安装出现错误,可以按照下面的顺序先安装依赖包:
1、安装wheel
pip install wheel
2、安装lxml
pip install lxml
3、安装pyopenssl
pip install pyopenssl
4、安装Twisted
需要我们自己下载Twisted,然后安装。这里有Python的各种依赖包。选择适合自己Python以及系统的Twisted版本:https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
# 3.6版本(cp后是python版本)
pip install Twisted-18.9.0-cp36-cp36m-win_amd64.whl
5、安装pywin32
pip install pywin32
6、安装scrapy
pip install scrapy
安装后,只要在命令终端输入 pip show scrapy 来检测是否安装成功
2.2使用Scrapy
使用爬虫可以遵循以下步骤:
创建一个Scrapy项目
定义提取的Item
编写爬取网站的 spider 并提取 Item
编写 Item Pipeline 来存储提取到的Item(即数据)
3. 新建项目(scrapy startproject)
创建一个新的Scrapy项目来爬取 最近更新的美剧-美剧天堂 中的数据,使用以下命令:
scrapy startproject meiju(项目名字)
若发生报错 No module named '_cffi_backend'
解决方法: 查看是否安装了cffi模块,若未安装则执行 pip install cffi
或者 pip -vvv install --upgrade --force-reinstall cffi
3.1创建爬虫程序
cd meiju(项目名)
scrapy genspider mymeiju(爬虫文件名) meijutt.net其中:
mymeiju为爬虫文件名
meijutt.net为爬取网址的域名
创建Scrapy工程后, 会自动创建多个文件,下面来简单介绍一下各个主要文件的作用:
scrapy.cfg:
项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py:
设置数据存储模板,用于结构化数据,如:Django的Model
pipelines:
数据处理行为,如:一般结构化的数据持久化
settings.py:
配置文件,如:递归的层数、并发数,延迟下载等
spiders:
爬虫目录,如:创建文件,编写爬虫规则
注意:一般创建爬虫文件时,以网站域名命名
3.2运行scrapy框架:
第一种方式:
scrapy crawl mymeiju 或者
# nolog模式 不显示日志的方式运行爬虫
scrapy crawl mymeiju --nolog
第二种方式:
或者在项目中新建一个启动文件 然后直接运行该start.py文件也可以
start.py
- import scrapy.cmdline
- # scrapy.cmdline.execute("scrapy crawl mymeiju --nolog".split())
-
- # scrapy.cmdline.execute("scrapy crawl mymeiju -o meiju.json".split()) # 将爬取的数据直接保存到meiju.json文件中
- # scrapy.cmdline.execute("scrapy crawl mymeiju -o meiju.xml".split()) # 将爬取的数据直接保存到meiju.xml文件中
- # scrapy.cmdline.execute("scrapy crawl mymeiju -o meiju.csv".split()) # 将爬取的数据直接保存到meiju.csv文件中
第三种方式:
或者执行下面的简写方式,也可以将爬取到的数据保存到文件或者数据库中
scrapy保存信息的最简单的方法主要有这几种,-o 输出指定格式的文件,命令如下:
scrapy crawl mymeiju -o meiju.json
scrapy crawl mymeiju -o meiju.csv
scrapy crawl mymeiju -o meiju.xml
settings.py
- 修改信息如下,原有的注释信息保留
- # 项目名称
- BOT_NAME = 'meiju'
-
- # 爬虫模块
- SPIDER_MODULES = ['meiju.spiders']
- NEWSPIDER_MODULE = 'meiju.spiders'
-
- # Crawl responsibly by identifying yourself (and your website) on the user-agent
- USER_AGENT = 'meiju (+http://www.yourdomain.com)'
-
- # Obey robots.txt rules 不遵守
- ROBOTSTXT_OBEY = False # 值为True表示遵循robots.txt中爬取协议 False表示不遵守
-
- # 请求的时间间隔
- DOWNLOAD_DELAY = 1
-
- # 配置管道
- # Configure item pipelines
- # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
- ITEM_PIPELINES = {
- # 300表示优先级, 数字取值范围是0-1000之间, 值越小优先级越高
- 'meiju.pipelines.MeijuPipeline': 300,
- }
3.3. 编写爬虫 mymeiju.py
- # 要想使用管道保存数据,需要引入自己的管道文件
- from ..items import MeijuItem
- import scrapy
-
- # 一定要继承:scrapy.Spider
- class MymeijuSpider(scrapy.Spider):
- # 爬虫的名字 一定要唯一
- name = 'mymeiju'
- # 允许的域名
- allowed_domains = ['meijutt.tv']
- # 起始的爬取的url列表
- start_urls = ['https://www.meijutt.tv/new100.html']
-
- # 获取响应数据
- '''
- 1.解析数据 re xpath bs4
-
- '''
- # response表示响应的内容
- def parse(self, response,**kwargs):
- pass
- # print(response.text) # 文本内容
- # print(response.json) # json格式
- # print(response.body # 二进制格式
-
- # 解析网页数据
- li_list = response.xpath('//*[@class="top-list fn-clear"]/li')
- for li in li_list:
- # name = li.xpath("./h5/a/text()")[0].extract() #获取所有的美剧名称
- # name = li.xpath("./h5/a/text()").extract_first() #获取所有的美剧名称
- # name = li.xpath("./h5/a/text()").get()
- # name = li.xpath("./h5/a/text()").getall()
- # print(name)
- name = li.xpath("./h5/a/text()").get()
- tv = li.xpath('./span[@class="mjtv"]/text()').get()
- # print(name,tv)
- # 2.将解析完成的数据传入到管道中:yield
- # 注意:先把settings.py中的管道配置信息打开
- '''
- ITEM_PIPELINES = {
- 'meiju.pipelines.MeijuPipeline': 300,
- '''
- yield MeijuItem(name=name,tv=tv)
3.4. 定义Item
Item是保存爬取到的数据的容器;其使用方法和python字典类似,虽然我们可以在Scrapy中直接使用dict,但是 Item提供了额外保护机制来避免拼写错误导致的未定义字段错误;
类似ORM中的Model定义字段,我们可以通过scrapy.Item 类来定义要爬取的字段。
- import scrapy
-
- class MeijuItem(scrapy.Item):
- name = scrapy.Field()
- tv = scrapy.Field()
3.5启用一个Item Pipeline组件
为了启用Item Pipeline组件,必须将它的类添加到 settings.py文件ITEM_PIPELINES 配置修改settings.py,并设置优先级,分配给每个类的整型值,确定了他们运行的顺序,item按数字从低到高的顺序,通过pipeline,通常将这些数字定义在0-1000范围内(0-1000随意设置,数值越低,组件的优先级越高)
- ITEM_PIPELINES = {
- 'meiju.pipelines.MeijuPipeline': 300,
- }
设置UA
在setting.py中设置USER_AGENT的值 使用默认的值也可以
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36''运行3.6 编写 Pipeline 来存储提取到的Item(即数据)
- class SomethingPipeline(object):
- def __init__(self):
- # 可选实现,做参数初始化等
-
- def process_item(self, item, spider):
- # item (Item 对象) – 被爬取的item
- # spider (Spider 对象) – 爬取该item的spider
- # 这个方法必须实现,每个item pipeline组件都需要调用该方法,
- # 这个方法必须返回一个 Item 对象,被丢弃的item将不会被之后的pipeline组件所处理。
- # 保存到meiju.txt文件中去
- with open("meiju.txt","a",encoding="utf-8") as fp:
- fp.write(f"{str(item)} \n")
- fp.flush()
- '''
- return item
- def open_spider(self, spider):
- # spider (Spider 对象) – 被开启的spider
- # 可选实现,当spider被开启时,这个方法被调用。
- def close_spider(self, spider):
- # spider (Spider 对象) – 被关闭的spider
- # 可选实现,当spider被关闭时,这个方法被调用
-
4.scrapy爬取新浪新闻
链接:http://roll.news.sina.com.cn/news/gnxw/gdxw1/index_1.shtml
文件布局结构:
settings.py文件
- # Scrapy settings for sina project
- #
- # For simplicity, this file contains only settings considered important or
- # commonly used. You can find more settings consulting the documentation:
- #
- # https://docs.scrapy.org/en/latest/topics/settings.html
- # https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
- # https://docs.scrapy.org/en/latest/topics/spider-middleware.html
-
- BOT_NAME = 'sina'
-
- SPIDER_MODULES = ['sina.spiders']
- NEWSPIDER_MODULE = 'sina.spiders'
-
-
- # Crawl responsibly by identifying yourself (and your website) on the user-agent
- USER_AGENT = 'sina (+http://www.yourdomain.com)'
-
- # Obey robots.txt rules
- ROBOTSTXT_OBEY = False
-
- # Configure maximum concurrent requests performed by Scrapy (default: 16)
- #CONCURRENT_REQUESTS = 32
-
- # Configure a delay for requests for the same website (default: 0)
- # See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
- # See also autothrottle settings and docs
- DOWNLOAD_DELAY = 2
- # The download delay setting will honor only one of:
- #CONCURRENT_REQUESTS_PER_DOMAIN = 16
- #CONCURRENT_REQUESTS_PER_IP = 16
-
- # Disable cookies (enabled by default)
- #COOKIES_ENABLED = False
-
- # Disable Telnet Console (enabled by default)
- #TELNETCONSOLE_ENABLED = False
-
- # Override the default request headers:
- #DEFAULT_REQUEST_HEADERS = {
- # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
- # 'Accept-Language': 'en',
- #}
-
- # Enable or disable spider middlewares
- # See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
- #SPIDER_MIDDLEWARES = {
- # 'sina.middlewares.SinaSpiderMiddleware': 543,
- #}
-
- # Enable or disable downloader middlewares
- # See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
- #DOWNLOADER_MIDDLEWARES = {
- # 'sina.middlewares.SinaDownloaderMiddleware': 543,
- #}
-
- # Enable or disable extensions
- # See https://docs.scrapy.org/en/latest/topics/extensions.html
- #EXTENSIONS = {
- # 'scrapy.extensions.telnet.TelnetConsole': None,
- #}
-
- # Configure item pipelines
- # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
- ITEM_PIPELINES = {
- 'sina.pipelines.SinaPipeline': 300,
- }
-
- # Enable and configure the AutoThrottle extension (disabled by default)
- # See https://docs.scrapy.org/en/latest/topics/autothrottle.html
- #AUTOTHROTTLE_ENABLED = True
- # The initial download delay
- #AUTOTHROTTLE_START_DELAY = 5
- # The maximum download delay to be set in case of high latencies
- #AUTOTHROTTLE_MAX_DELAY = 60
- # The average number of requests Scrapy should be sending in parallel to
- # each remote server
- #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
- # Enable showing throttling stats for every response received:
- #AUTOTHROTTLE_DEBUG = False
-
- # Enable and configure HTTP caching (disabled by default)
- # See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
- #HTTPCACHE_ENABLED = True
- #HTTPCACHE_EXPIRATION_SECS = 0
- #HTTPCACHE_DIR = 'httpcache'
- #HTTPCACHE_IGNORE_HTTP_CODES = []
- #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
mysina.py文件
- import scrapy
- from ..items import SinaItem
-
-
-
- class MysinaSpider(scrapy.Spider):
- name = 'mysina'
- allowed_domains = ['sina.com.cn']
- start_urls = ['http://roll.news.sina.com.cn/news/gnxw/gdxw1/index_1.shtml']
-
- def parse(self, response):
- # 使用xpath解析网页
- li_list = response.xpath('//ul[@class="list_009"]/li')
- # print(li_list)
- for li in li_list:
- # print(li)
- # 获取新闻标题
- title = li.xpath('./a/text()').get()
- # 获取新闻发布时间
- date1 = li.xpath('./span/text()').get()
- # print(title,date1)
- yield SinaItem(title=title, date1=date1)
items.py文件
- # Define here the models for your scraped items
- #
- # See documentation in:
- # https://docs.scrapy.org/en/latest/topics/items.html
-
- import scrapy
-
-
- class SinaItem(scrapy.Item):
- # define the fields for your item here like:
- # name = scrapy.Field()
- title = scrapy.Field()
- date1 = scrapy.Field()
pipelines.py文件
- # Define your item pipelines here
- #
- # Don't forget to add your pipeline to the ITEM_PIPELINES setting
- # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
-
-
- # useful for handling different item types with a single interface
- from itemadapter import ItemAdapter
-
-
- class SinaPipeline:
- def process_item(self, item, spider):
- with open('sina.txt', 'a', encoding='utf-8') as fp:
- str = f"标题:{item['title']}---发布时间:{item['date1']}\n"
- fp.write(str)
- fp.flush()
- print(item['title'], '爬取完成.....')
- return item
5.scrapy多页爬取新浪新闻
链接:http://roll.news.sina.com.cn/news/gnxw/gdxw1/index_1.shtml
文件结构布局
mysinas.py文件
- import scrapy
- from ..items import SinasItem
-
- class MysinasSpider(scrapy.Spider):
- name = 'mysinas'
- allowed_domains = ['sina.com.cn']
- start_urls = ['http://roll.news.sina.com.cn/news/gnxw/gdxw1/index_1.shtml']
- # 定义一个变量,表示页码数
- page = 1 # 表示第一页
-
- def parse(self, response):
- li_list = response.xpath('//ul[@class="list_009"]/li')
- # print(li_list)
- for li in li_list:
- # print(li)
- # 获取新闻标题
- title = li.xpath('./a/text()').get()
- # 获取新闻发布时间
- date1 = li.xpath('./span/text()').get()
- # print(title,date1)
- yield SinasItem(title=title, date1=date1)
- print(f"第{self.page}页数据爬取完毕......")
-
- # 需求:爬取前10页的数据
- if self.page < 10:
- self.page += 1
- # 定义要爬取的新页码的数据
- url = f"http://roll.news.sina.com.cn/news/gnxw/gdxw1/index_{self.page}.shtml"
- '''
- yield 关键字后面执行的程序分成两种情况:
- 1.直接返回item 将爬取成功的数据保存到管道中 比如:yield SinafenyeItem(title=title,date1=date1)
-
- 2.可以发起一次新的请求 返回Request
- 2.1 GET请求(常用)
- scrapy.Request(url,callback):
- url表示要爬取的网址
- callback:表示回调函数. 当接收url地址后,使用callback对应的函数对响应的结果进行解析
-
- 2.2 POST请求
- FormRequest(url,callback)
- '''
- yield scrapy.Request(url, self.parse)
-
items.py
- # Define here the models for your scraped items
- #
- # See documentation in:
- # https://docs.scrapy.org/en/latest/topics/items.html
-
- import scrapy
-
-
- class SinasItem(scrapy.Item):
- # define the fields for your item here like:
- # name = scrapy.Field()
- title = scrapy.Field()
- date1 = scrapy.Field()
pipelines.py
- # Define your item pipelines here
- #
- # Don't forget to add your pipeline to the ITEM_PIPELINES setting
- # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
-
-
- # useful for handling different item types with a single interface
- from itemadapter import ItemAdapter
-
-
- class SinasPipeline:
- def process_item(self, item, spider):
- with open('sinafenye.txt','a',encoding='utf-8') as fp:
- str = f'标题:{item["title"]}---发布时间:{item["date1"]}\n'
- fp.write(str)
- fp.flush()
- return item
七、scrapy框架进阶
1.Scrapy Shell
Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码
启动Scrapy Shell
scrapy shell "https://www.baidu.com"
response.text
2.Selectors选择器
Scrapy Selectors 内置 XPath 和 CSS Selector 表达式机制
Selector有四个基本的方法,最常用的还是xpath:
xpath(): 传入xpath表达式,返回该表达式所对应的所有节点的selector list列表
extract(): 序列化该节点为Unicode字符串并返回list, extract_first() => get()
css(): 传入CSS表达式,返回该表达式所对应的所有节点的selector list列表,语法同 BeautifulSoup4中soup.select()
re(): 根据传入的正则表达式对数据进行提取,返回Unicode字符串list列表
# 使用xpath
response.xpath('//title')
3.Spider类
Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。 换句话说,Spider就是你定义爬取的动作及分析某个网页(或者是有些网页)的地方。
scrapy.Spider是最基本的类,所有编写的爬虫必须继承这个类。
主要用到的函数及调用顺序为:
__init__():
初始化爬虫名字和start_urls列表
start_requests()
调用make_requests_from_url():生成Requests对象交给Scrapy下载并返回response
parse(self, response):
解析response,并返回Item或Requests(需指定回调函数)。
Item传给Item pipline持久化,而Requests交由Scrapy下载,并由指定的回调函数处理(默认parse()),一直进行循环,直到处理完所有的数据为止。
3.1Spider类源码参考
- #所有爬虫的基类,用户定义的爬虫必须从这个类继承
- class Spider(object_ref):
- # 定义spider名字的字符串(string)。
- # spider的名字定义了Scrapy如何定位(并初始化)spider,所以其必须是唯一的。
- # name是spider最重要的属性,而且是必须的。
- # 一般做法是以该网站(domain)(不加后缀 )来命名spider。 例如,如果spider爬取 mywebsite.com ,该spider通常会被命名为 mywebsite
- name = None
-
- # 初始化,提取爬虫名字,start_urls
- def __init__(self, name=None, **kwargs):
- if name is not None:
- self.name = name
- # 如果爬虫没有名字,中断后续操作则报错
- elif not getattr(self, 'name', None):
- raise ValueError("%s must have a name" % type(self).__name__)
-
- # python 对象或类型通过内置成员__dict__来存储成员信息
- self.__dict__.update(kwargs)
-
- #URL列表。当没有指定的URL时,spider将从该列表中开始进行爬取。 因此,第一个被获取到的页面的URL将是该列表之一。 后续的URL将会从获取到的数据中提取。
- if not hasattr(self, 'start_urls'):
- self.start_urls = []
-
- # 打印Scrapy执行后的log信息
- def log(self, message, level=log.DEBUG, **kw):
- log.msg(message, spider=self, level=level, **kw)
-
- # 判断对象object的属性是否存在,不存在则断言处理
- def set_crawler(self, crawler):
- assert not hasattr(self, '_crawler'), "Spider already bounded to %s" % crawler
- self._crawler = crawler
-
- @property
- def crawler(self):
- assert hasattr(self, '_crawler'), "Spider not bounded to any crawler"
- return self._crawler
-
- @property
- def settings(self):
- return self.crawler.settings
-
- #该方法将读取start_urls内的地址,并为每一个地址生成一个Request对象,交给Scrapy下载并返回Response
- #该方法仅调用一次
- def start_requests(self):
- for url in self.start_urls:
- yield self.make_requests_from_url(url)
-
- #start_requests()中调用,实际生成Request的函数。
- #Request对象默认的回调函数为parse(),提交的方式为get
- def make_requests_from_url(self, url):
- return Request(url, dont_filter=True)
-
- #默认的Request对象回调函数,处理返回的response。
- #生成Item或者Request对象。用户必须实现这个
- def parse(self, response):
- raise NotImplementedError
-
- @classmethod
- def handles_request(cls, request):
- return url_is_from_spider(request.url, cls)
-
- def __str__(self):
- return "<%s %r at 0x%0x>" % (type(self).__name__, self.name, id(self))
-
- __repr__ = __str__
3.2主要属性和方法
name
定义spider名字的字符串。唯一
allowed_domains
包含了spider允许爬取的域名(domain)的列表,可选。
start_urls
初始URL元祖/列表。当没有制定特定的URL时,spider将从该列表中开始进行爬取。
start_requests(self)
该方法必须返回一个可迭代对象(iterable)。该对象包含了spider用于爬取(默认实现是使用 start_urls 的url)的第一个Request。
当spider启动爬取并且未指定start_urls时,该方法被调用。
parse(self, response)
当请求url返回网页没有指定回调函数时,默认的Request对象回调函数。用来处理网页返回的response,以及生成Item或者Request对象。
log(self, message[, level, component])
使用 scrapy.log.msg() 方法记录日志信息。
4.CrawlSpider
CrawlSpider是Spider的派生类,Spider类的设计原则是只爬取start_urls列表中的网页,而CrawlSpider类定义了一些规则(rule)来提供跟进link的方便的机制,从爬取的网页中获取link并继续爬取的工作更适合。
4.1CrawlSpider类源码参考
- class CrawlSpider(Spider):
- rules = ()
- def __init__(self, *a, **kw):
- super(CrawlSpider, self).__init__(*a, **kw)
- self._compile_rules()
-
- #首先调用parse()来处理start_urls中返回的response对象
- #_parse()则将这些response对象传递给了_parse_response()函数处理,并设置回调函数为parse_start_url()
- #设置了跟进标志位True
- #parse将返回item和跟进了的Request对象
- def _parse(self, response):
- return self._parse_response(response, self.parse_start_url, cb_kwargs={}, follow=True)
-
- #处理start_url中返回的response,需要重写
- def parse_start_url(self, response):
- return []
-
- def process_results(self, response, results):
- return results
-
- #从response中抽取符合任一用户定义'规则'的链接,并构造成Resquest对象返回
- def _requests_to_follow(self, response):
- if not isinstance(response, HtmlResponse):
- return
- seen = set()
- #抽取之内的所有链接,只要通过任意一个'规则',即表示合法
- for n, rule in enumerate(self._rules):
- links = [l for l in rule.link_extractor.extract_links(response) if l not in seen]
- #使用用户指定的process_links处理每个连接
- if links and rule.process_links:
- links = rule.process_links(links)
- #将链接加入seen集合,为每个链接生成Request对象,并设置回调函数为_repsonse_downloaded()
- for link in links:
- seen.add(link)
- #构造Request对象,并将Rule规则中定义的回调函数作为这个Request对象的回调函数
- r = Request(url=link.url, callback=self._response_downloaded)
- r.meta.update(rule=n, link_text=link.text)
- #对每个Request调用process_request()函数。该函数默认为indentify,即不做任何处理,直接返回该Request.
- yield rule.process_request(r)
-
- #处理通过rule提取出的连接,并返回item以及request
- def _response_downloaded(self, response):
- rule = self._rules[response.meta['rule']]
- return self._parse_response(response, rule.callback, rule.cb_kwargs, rule.follow)
-
- #解析response对象,会用callback解析处理他,并返回request或Item对象
- def _parse_response(self, response, callback, cb_kwargs, follow=True):
- #首先判断是否设置了回调函数。(该回调函数可能是rule中的解析函数,也可能是 parse_start_url函数)
- #如果设置了回调函数(parse_start_url()),那么首先用parse_start_url()处理response对象,
- #然后再交给process_results处理。返回cb_res的一个列表
- if callback:
- #如果是parse调用的,则会解析成Request对象
- #如果是rule callback,则会解析成Item
- cb_res = callback(response, **cb_kwargs) or ()
- cb_res = self.process_results(response, cb_res)
- for requests_or_item in iterate_spider_output(cb_res):
- yield requests_or_item
-
- #如果需要跟进,那么使用定义的Rule规则提取并返回这些Request对象
- if follow and self._follow_links:
- #返回每个Request对象
- for request_or_item in self._requests_to_follow(response):
- yield request_or_item
-
- def _compile_rules(self):
- def get_method(method):
- if callable(method):
- return method
- elif isinstance(method, basestring):
- return getattr(self, method, None)
-
- self._rules = [copy.copy(r) for r in self.rules]
- for rule in self._rules:
- rule.callback = get_method(rule.callback)
- rule.process_links = get_method(rule.process_links)
- rule.process_request = get_method(rule.process_request)
-
- def set_crawler(self, crawler):
- super(CrawlSpider, self).set_crawler(crawler)
- self._follow_links = crawler.settings.getbool('CRAWLSPIDER_FOLLOW_LINKS', True)
4.2LinkExtractors
- '''
- 使用LinkExtractors 的目的: 提取链接。每个LinkExtractor有唯一的公共方法是 extract_links(),它接收一个 Response 对象,并返回一个 scrapy.link.Link 对象。
- '''
- scrapy.linkextractors.LinkExtractor(
- allow = (),
- deny = (),
- allow_domains = (),
- deny_domains = (),
- deny_extensions = None,
- restrict_xpaths = (),
- tags = ('a','area'),
- attrs = ('href'),
- canonicalize = True,
- unique = True,
- process_value = None
- )
- '''
- 主要参数:
- allow:满足括号中“正则表达式”的值会被提取,如果为空,则全部匹配。
- deny:与这个正则表达式(或正则表达式列表)匹配的URL一定不提取。
- allow_domains:会被提取的链接的domains。
- deny_domains:一定不会被提取链接的domains。
- restrict_xpaths:使用xpath表达式,和allow共同作用过滤链接。
- '''
4.3rules
- '''
- 在rules中包含一个或多个Rule对象,每个Rule对爬取网站的动作定义了特定操作。如果多个rule匹配了相同的链接,则根据规则在本集合中被定义的顺序,第一个会被使用。
- '''
- scrapy.spiders.Rule(
- link_extractor,
- callback = None,
- cb_kwargs = None,
- follow = None,
- process_links = None,
- process_request = None
- )
- '''
- link_extractor:是一个Link Extractor对象,用于定义需要提取的链接。
- callback: 从link_extractor中每获取到链接时,参数所指定的值作为回调函数,该回调函数接受一个response作为其第一个参数。
- 注意:当编写爬虫规则时,避免使用parse作为回调函数。由于CrawlSpider使用parse方法来实现其逻辑,如果覆盖了parse方法,crawlspider将会运行失败。
- follow:是一个布尔(boolean)值,指定了根据该规则从response提取的链接是否需要跟进。 如果callback为None,follow默认设置为True ,否则默认为False。
- process_links:指定该spider中哪个的函数将会被调用,从link_extractor中获取到链接列表时将会调用该函数。该方法主要用来过滤。
- process_request:指定该spider中哪个的函数将会被调用, 该规则提取到每个request时都会调用该函数。 (用来过滤request)
- '''
5. scrapy 使用 CrawlSpider 爬取百度百科
爬取文件 mybaidubaike.py
- import scrapy
- from scrapy.spiders import CrawlSpider, Rule
- from scrapy.linkextractors import LinkExtractor
-
-
- class MybaidubaikeSpider(CrawlSpider):
- name = 'mybaidubaike'
- allowed_domains = ['baike.baidu.com']
- start_urls = ['https://baike.baidu.com/']
- # 定义规则
- rules = [
- Rule(
- LinkExtractor(
- # 表示允许爬取的范围
- allow=('/item/.*?',)
- ),
- # 表示回调函数
- callback='parse_item',
- follow=True
- )
- ]
-
- def parse_item(self, response):
- title = response.xpath('//*[@class="lemmaWgt-lemmaTitle-title J-lemma-title"]/span/h1/text()').get()
- print(title)
八、 Scrapy-Redis分布式爬取
1.Scrapy和Scrapy-Redis的区别
Scrapy 是一个通用的爬虫框架,但是不支持分布式,
Scrapy-Redis 是为了更方便地实现Scrapy分布式爬取,而提供了一些以redis为基础的组件(仅有组件)
2.安装Scrapy-Redis
pip install scrapy-redis
3.Scrapy-Redis介绍
提供了下面四种组件(components):(四种组件意味着这四个模块都要做相应的修改)
Scheduler
Duplication Filter
Item Pipeline
Base Spider
3.1Scrapy流程图
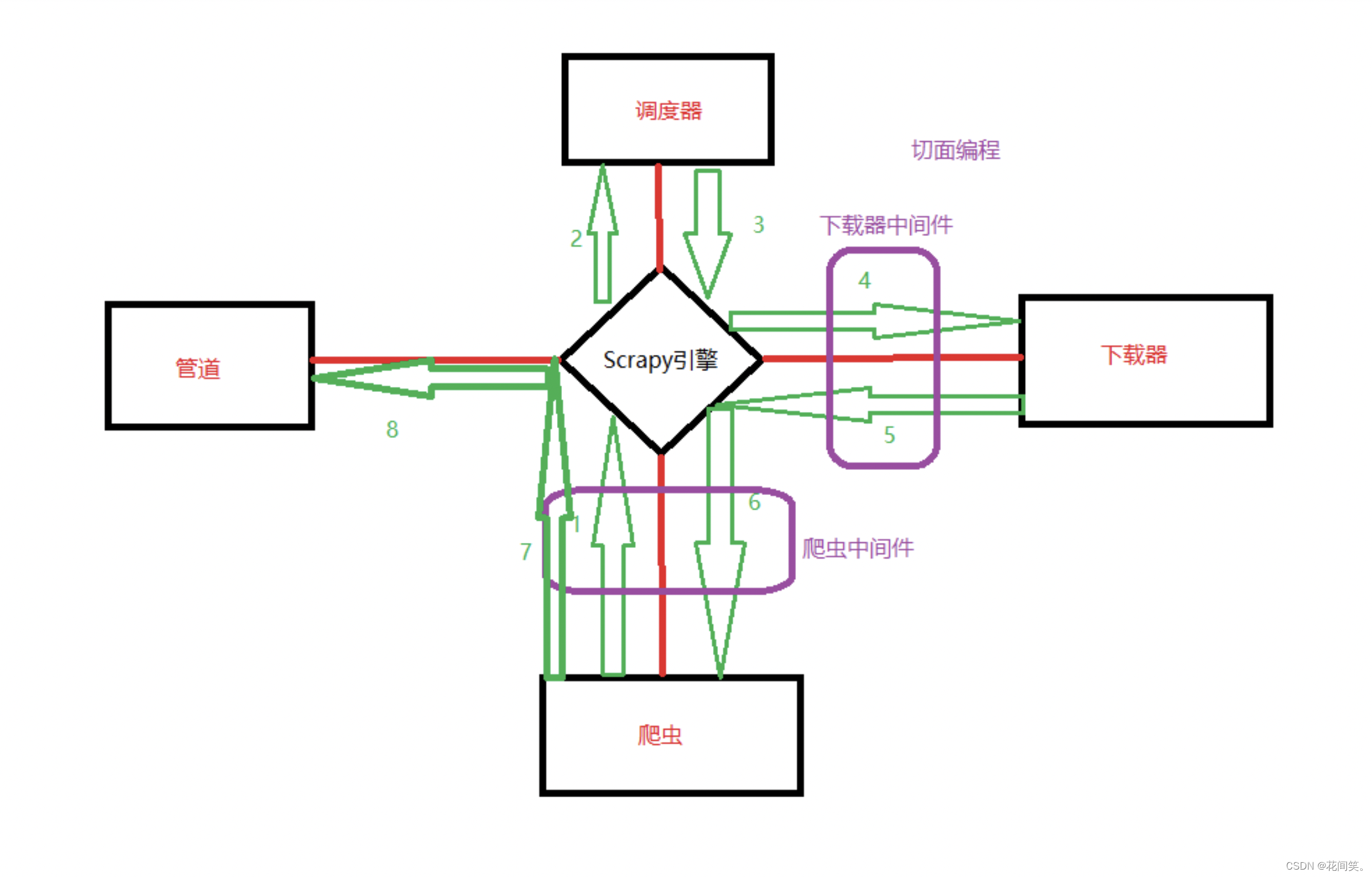
3.2Scrapy-Redis框架图
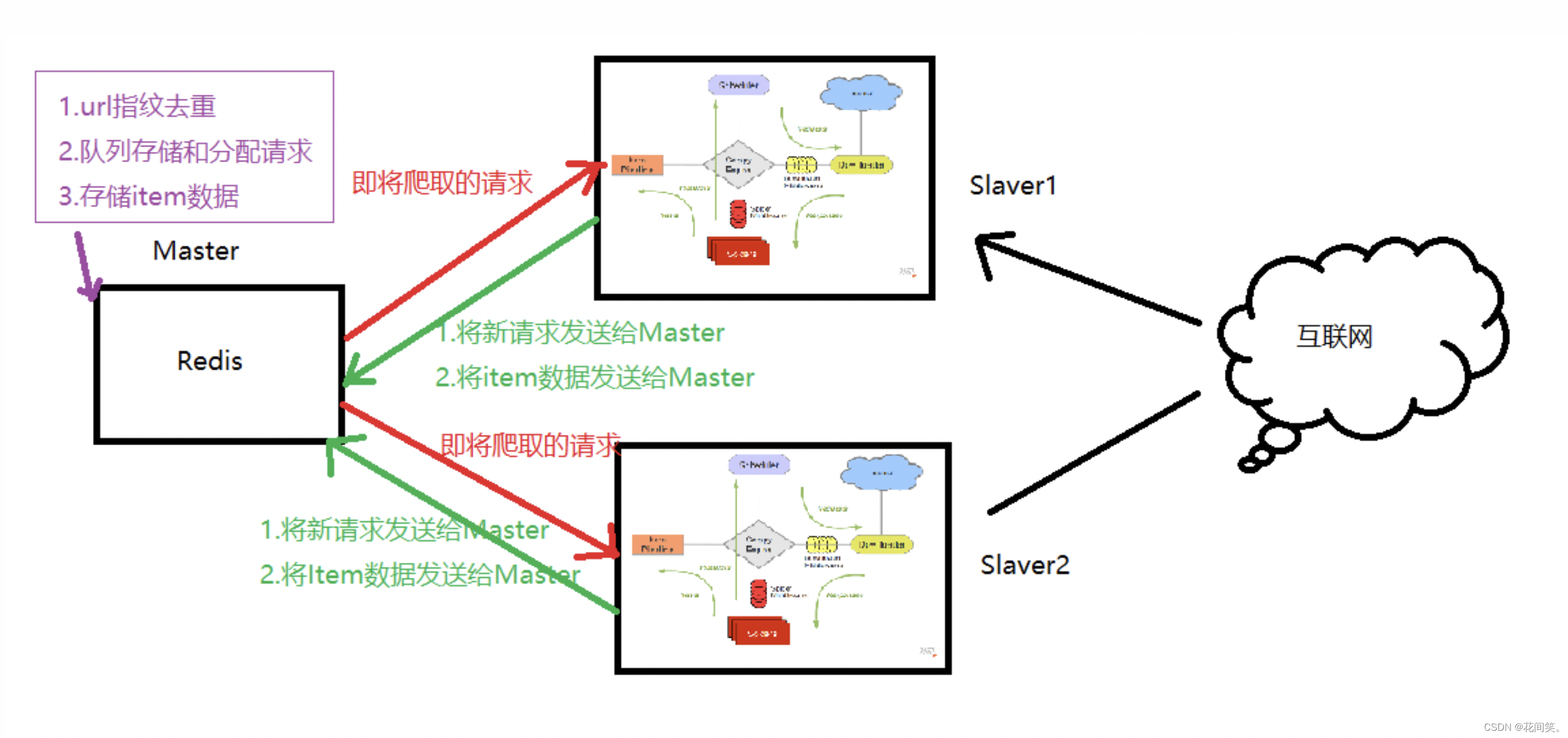
4.Scrapy-Redis分布式策略
假设有四台电脑:Windows 10、Mac OS X、Ubuntu 16.04、CentOS 7.2,任意一台电脑都可以作为 Master端 或 Slaver端,比如:
Master端(核心服务器) :使用 Windows 10,搭建一个Redis数据库,不负责爬取,只负责url指纹判重、Request的分配,以及数据的存储
Slaver端(爬虫程序执行端) :使用 Mac OS X 、Ubuntu 16.04、CentOS 7.2,负责执行爬虫程序,运行过程中提交新的Request给Master
首先Slaver端从Master端拿任务(Request、url)进行数据抓取,Slaver抓取数据的同时,产生新任务的Request便提交给 Master 处理;
Master端只有一个Redis数据库,负责将未处理的Request去重和任务分配,将处理后的Request加入待爬队列,并且存储爬取的数据。
Scrapy-Redis默认使用的就是这种策略,我们实现起来很简单,因为任务调度等工作Scrapy-Redis都已经帮我们做好了,我们只需要继承RedisSpider、指定redis_key就行了。
缺点是,Scrapy-Redis调度的任务是Request对象,里面信息量比较大(不仅包含url,还有callback函数、headers等信息),可能导致的结果就是会降低爬虫速度、而且会占用Redis大量的存储空间,所以如果要保证效率,那么就需要一定硬件水平。
5.scrapy-redis项目的 settings.py 配置文件:
-
- BOT_NAME = 'baike'
- SPIDER_MODULES = ['baike.spiders']
- NEWSPIDER_MODULE = 'baike.spiders'
- # Crawl responsibly by identifying yourself (and your website) on the user-agent
- USER_AGENT = 'baike (+http://www.yourdomain.com)'
-
- # 去重的过滤器
- DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
- # 使用scrapy_redis的调度器
- SCHEDULER = "scrapy_redis.scheduler.Scheduler"
- # 是否允许暂停
- SCHEDULER_PERSIST = True
-
- # Obey robots.txt rules
- ROBOTSTXT_OBEY = False
-
- # Configure a delay for requests for the same website (default: 0)
- # See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
- # See also autothrottle settings and docs
- DOWNLOAD_DELAY = 1
-
- # Configure item pipelines
- # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
- ITEM_PIPELINES = {
- 'baike.pipelines.BaikePipeline': 300,
- # 使用redis管道,自动存入redis,默认存入本机的redis
- 'scrapy_redis.pipelines.RedisPipeline': 400,
- }
- LOG_LEVEL = 'DEBUG'
6. scrapy-redis项目的 爬取文件 文件(以爬取百度百科为例):
mybaikefenbu.py
- import scrapy
- from scrapy.spiders import CrawlSpider, Rule
- from scrapy.linkextractors import LinkExtractor
- from scrapy_redis.spiders import RedisSpider, RedisCrawlSpider
- from baikeFenBu.items import BaikefenbuItem
- # RedisSpider ====> Spider
- # RedisCrawlSpider ===> CrawlSpider
- class MybaikefenbuSpider(RedisCrawlSpider):
- # 爬虫项目名称
- name = 'mybaikefenbu.py'
- allowed_domains = ['baike.baidu.com']
- # start_urls = ['https://baike.baidu.com/']
- # 在分布式爬取中,设置redis_key 将需要爬取的url地址保存到redis数据库中
- redis_key = 'mybaike:start_urls'
- # 设置rules规则
- rules = [
- Rule(
- LinkExtractor(
- allow=('/item/.*?',)
- ),
- callback='parse_item',
- follow=True
- )
- ]
- # 在scrapy-redis分布式爬取中,已经废弃了 make_requests_from_url() 该方法,我们需要重写
- def make_requests_from_url(self,url):
- return scrapy.Request(url,dont_filter=True)
- def parse_item(self, response):
- # 获取词条
- title = response.xpath('//dd[@class="lemmaWgt-lemmaTitle-title J-lemma-title"]/span/h1/text()').get()
- print('词条为:',title)
- yield BaikefenbuItem(title=title)
-
7.scrapy-redis项目之从redis读取数据
redisToFile.py
- # 将爬取到的数据从redis中读取出来并保存
-
- import redis
- import time
- import json
-
- # 1.链接redis数据库
- db = redis.StrictRedis()
-
- # 通过死循环的方式不断从redis数据库中读取数据
- while True:
- # 2.将数据从redis中读取出来 key的名字取决于redis中定义的名字 Blpop 命令移出并获取列表的第一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
- key, value = db.blpop("mybaikefenbu.py:items")
- # print(db.blpop("mybaikefenbu.py:items")) # (b'mybaikefenbu.py:items', b'{"title": "\\u6cf0\\u5b81\\u6885\\u6797\\u620f"}')
- # 将获取的数据进行解码
- print(json.loads(value.decode()))
- # 每隔两秒从redis数据库中读取一条数据,防止读取速度超过redis写入数据
- time.sleep(2)
8.scrapy-redis项目启动:
1)开启redis数据库:redis-server
2)开启redis客户端:redis-cli
3)启动爬取文件:分布式爬取的时候,指令不是scrapy crawl xx,而是进入到baikeFenBu/baikeFenBu/spiders文件夹:
scrapy runspider mybaikefenbu.py
4)在redis客户端中往队列中添加起始url:
lpush mybaike:start_urls "https://baike.baidu.com/"
九、动态的爬取网页
1.selenium的基本使用
- from selenium import webdriver
- import time
-
- # 1.创建浏览器驱动
- driver = webdriver.Chrome()
- # print(driver)
-
- # get() 表示打开制定网页
- # driver.get("https://www.baidu.com") # 打开百度
- driver.get("https://www.jd.com") # 打开京东
-
- # page_source 获取网页源代码
- print(driver.page_source)
-
- # 10秒钟后自动关闭浏览器
- time.sleep(10)
- # close() 表示关闭网页
- driver.close()
2.selenium 从网页中提取元素
- from selenium import webdriver
- import time
- from selenium.webdriver import Keys
-
- # 1.创建浏览器驱动对象
- driver = webdriver.Chrome()
-
- # 2.访问网站
- driver.get("https://www.baidu.com")
-
- # 需求 通过程序的方式向百度搜索框输入内容并点击"百度一下"按钮实现搜索功能
-
- # id属性获取网页元素
- '''
- 第一种方式:
- 通过id属性获取网页中的元素 find_element(by='id', value='id属性的值')
- # 通过IDs属性获取百度搜索框
- input = driver.find_element(by='id', value='kw')
- # print(input)
- # 通过id属性获取"百度一下"按钮
- btn = driver.find_element(by='id', value='su')
- print(btn)
- # 向百度搜索框中写入搜索内容 send_keys('用搜索的内容')
- input.send_keys('小黄人')
- # 给百度一下按钮绑定点击事件
- btn.click()
- '''
-
- '''
- 第二种方式
- 通过id属性获取到输入框后,输入要搜索的内容,直接按enter键实现搜索
- # 通过IDs属性获取百度搜索框
- input = driver.find_element(by='id', value='kw')
- #通过id属性获取到输入框后,输入要搜索的内容,直接按enter键实现搜索
- input.send_keys('小黄人', Keys.ENTER)
- '''
-
-
-
-
- # class属性获取元素 find_elements(by='class name',value="class属性值")
- # 需求 通过selenium获取百度中所有标题
- span_list = driver.find_elements(by='class name', value='title-content-title')
- # print(span_list) # 是一个列表
- for span in span_list:
- # print(span)
- # get_attribute(innerText) 表示获取标签中的文本信息
- print(span.get_attribute('innerText'))
-
-
- # close() 表示关闭网页
- # driver.close()
3.selenium实现简单的js效果
- from selenium import webdriver
- import time
-
- # 创建浏览器去驱动
- driver = webdriver.Chrome()
-
- # 打开指定的网页
- driver.get("https://www.jd.com")
-
- # 5秒中之后让页面滚动到指定位置
- time.sleep(5)
- # execute_script(script, *args): 执行脚本
- # scrollTo() 表示滚动条滚动指定距离
- # scrollBy是在上一次移动的位置的(mScrollX和mScrollY)基础上进行逸动的;
- # scrollTo是直接移动到(x,y)的位置
-
- driver.execute_script("scrollTo(0,500)") # 将滚动条向下滚动500个像素
-
- # 将当前界面截图保存
- time.sleep(1)
- driver.save_screenshot("jd.png") # 将当前界面截图并存储为 jd.png
4.selenium操作知乎登录界面
- from selenium import webdriver
- import time
- from selenium.webdriver.common.by import By
-
- # 创建浏览器驱动
- driver = webdriver.Chrome()
-
- # 定义知乎网址
- url = "https://www.zhihu.com/signin?next=%2F"
-
- # 打开知乎登录页面
- driver.get(url)
- time.sleep(5)
-
- # 解析网页中QQ登录按钮,通过xpath解析网页 注意:xpath下标以1开始
- driver.find_element(by=By.XPATH, value='//button[@class="Button Login-socialButton Button--plain"][2]').click()
- time.sleep(10)
-
- # 刷新页面
- driver.refresh()
-
- # 获取网页源代码
- print(driver.page_source)
5.验证码破解
5.1打码平台:超级鹰
超级鹰网址: 超级鹰验证码识别-专业的验证码云端识别服务,让验证码识别更快速、更准确、更强大
注册并登录超级鹰账号
查看价格体系
下载官方文档和代码
5.2chaojiying.py 文件
- #!/usr/bin/env python
- # coding:utf-8
-
- import requests
- from hashlib import md5
-
- class Chaojiying_Client(object):
-
- def __init__(self, username, password, soft_id):
- self.username = username
- password = password.encode('utf8')
- self.password = md5(password).hexdigest()
- self.soft_id = soft_id
- self.base_params = {
- 'user': self.username,
- 'pass2': self.password,
- 'softid': self.soft_id,
- }
- self.headers = {
- 'Connection': 'Keep-Alive',
- 'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
- }
-
- def PostPic(self, im, codetype):
- """
- im: 图片字节
- codetype: 题目类型 参考 http://www.chaojiying.com/price.html
- """
- params = {
- 'codetype': codetype,
- }
- params.update(self.base_params)
- files = {'userfile': ('ccc.jpg', im)}
- r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
- return r.json()
-
- def PostPic_base64(self, base64_str, codetype):
- """
- im: 图片字节
- codetype: 题目类型 参考 http://www.chaojiying.com/price.html
- """
- params = {
- 'codetype': codetype,
- 'file_base64':base64_str
- }
- params.update(self.base_params)
- r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, headers=self.headers)
- return r.json()
-
- def ReportError(self, im_id):
- """
- im_id:报错题目的图片ID
- """
- params = {
- 'id': im_id,
- }
- params.update(self.base_params)
- r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
- return r.json()
-
-
- if __name__ == '__main__':
- chaojiying = Chaojiying_Client('超级鹰账号', '账户密码', ' 用户中心的软件ID') #用户中心>>软件ID 生成一个替换 96001
- im = open('a.jpg', 'rb').read() #本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
- print(chaojiying.PostPic(im, 1902)) #1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
- #print chaojiying.PostPic(base64_str, 1902) #此处为传入 base64代码

