
热门标签
热门文章
- 1flink Transformation算子(更新中)
- 2BERT架构的深入解析
- 32024年超详细JDK下载与安装步骤_jdk下载与安装教程(1),2024年最新面试加分的话_java的jdk下载
- 4基于STM32单片机智能家居安防系统无线APP产品云平台设计133_stm32智能家居系统软件
- 5【SOC估计】基于扩展卡尔曼滤波器实现锂离子电池充电状态估计附matlab代码和报告
- 6JS+CSS特效:HTML+JS+CSS 实现精致的带二级菜单的头部菜单
- 7网络互联设备_网络互联设备综述
- 82023-Python实现有道翻译接口加密解密_python有道翻译
- 9基于单片机zigbee无线智能家居光照温湿度监测系统_智能家居温湿度监测
- 10vue+uniapp音乐播放器系统 微信小程序hbpp0_uniapp免费音乐
当前位置: article > 正文
昇思25天学习打卡营第十四天|Vision Transformer图像分类
作者:盐析白兔 | 2024-07-26 20:19:08
赞
踩
昇思25天学习打卡营第十四天|Vision Transformer图像分类
VIT模型是自然语言处理和计算机视觉两个领域的融合结晶,在不依赖卷积操作的情况下,依然可以在图像分类任务上达到很好的效果。
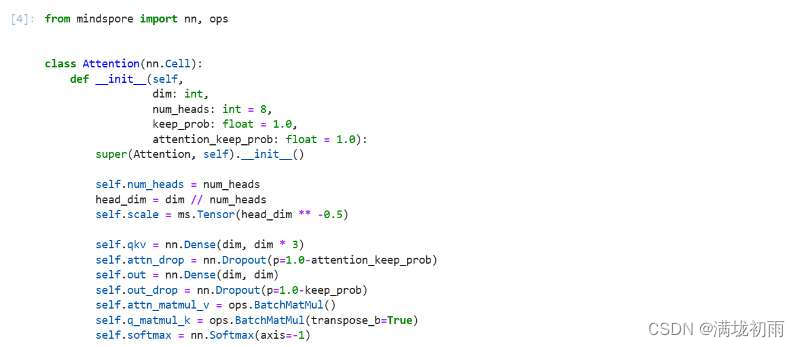
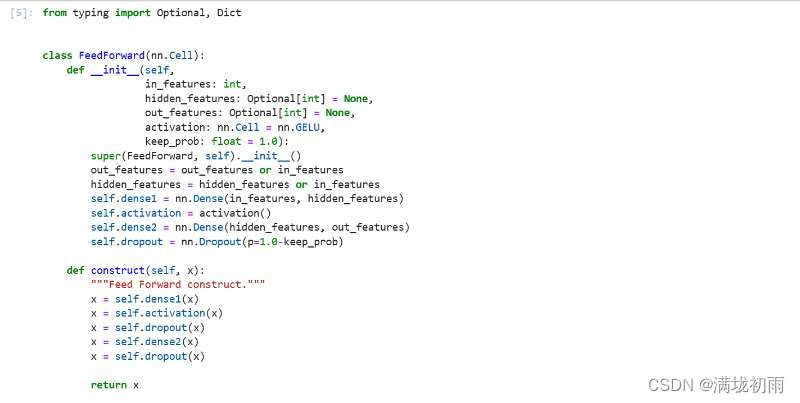
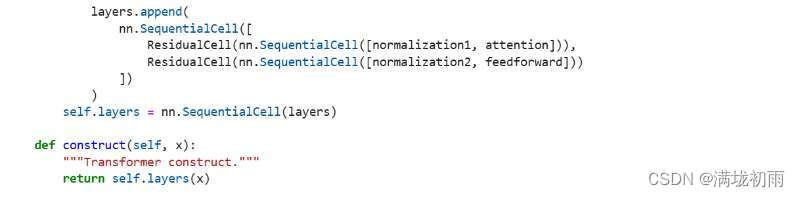
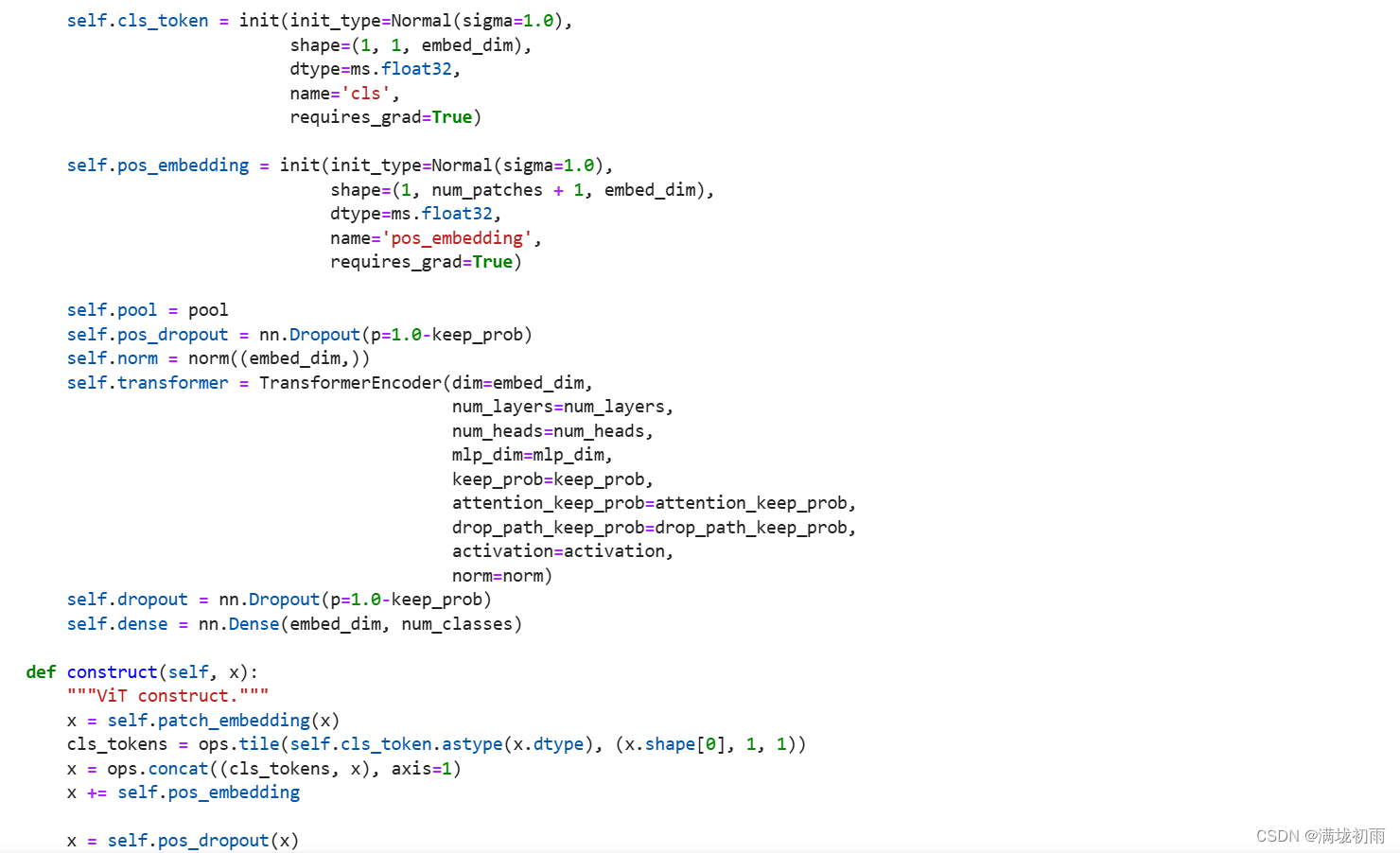
VIT模型的主体结构是基于Transform模型的Encoder部分(部分结构顺序有调整)。
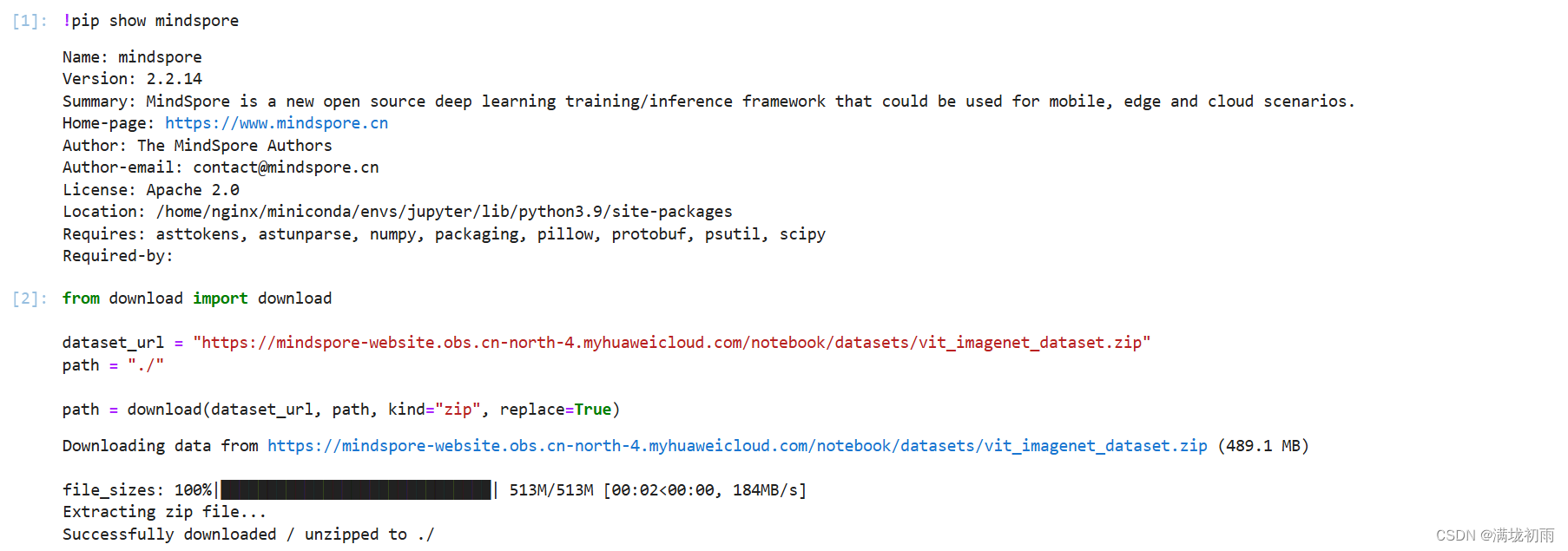
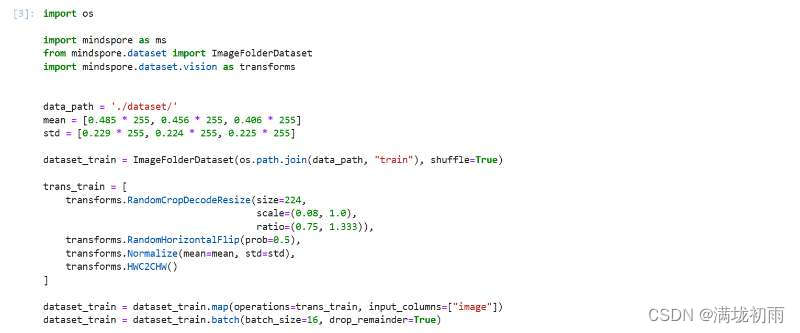
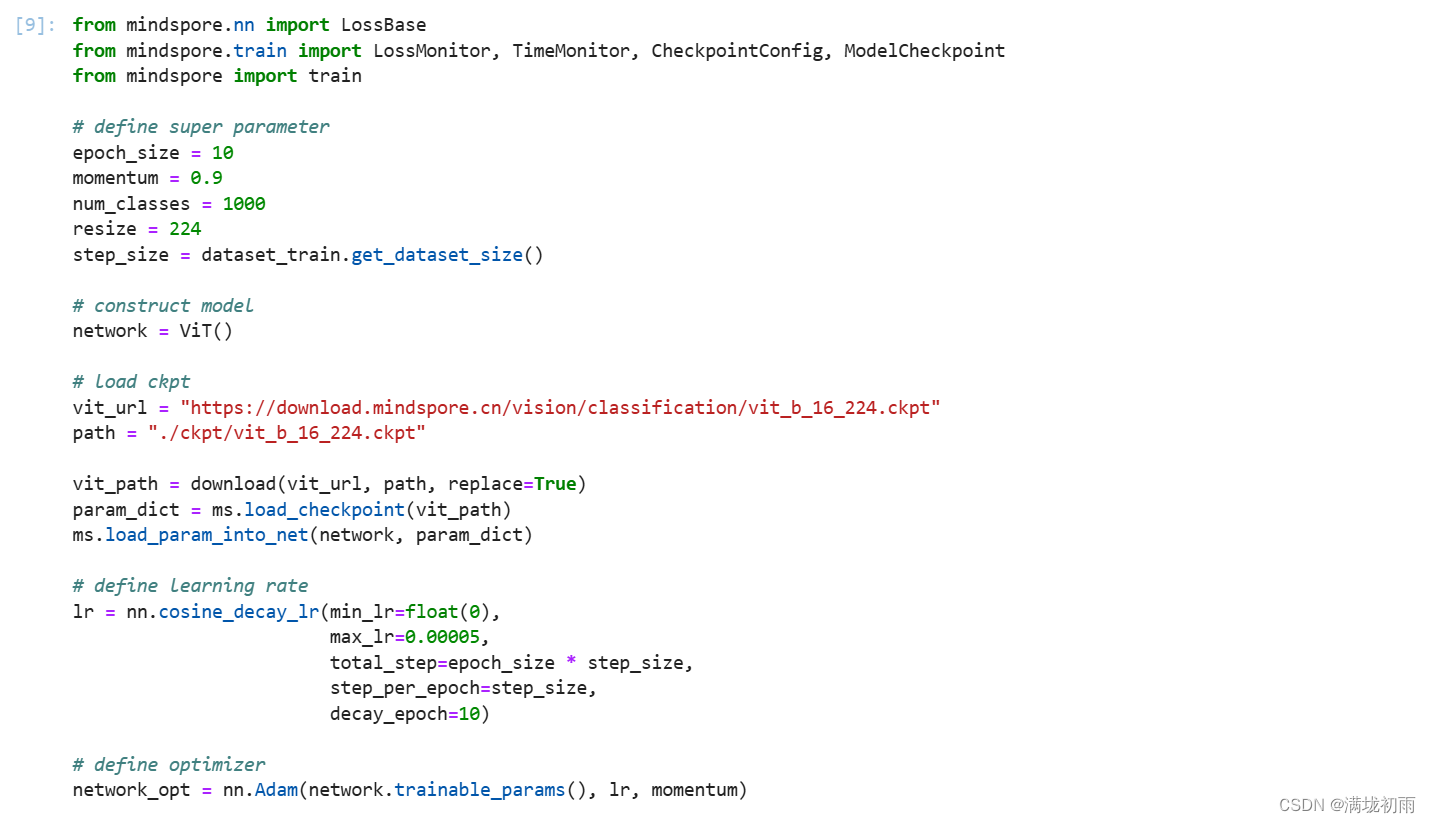
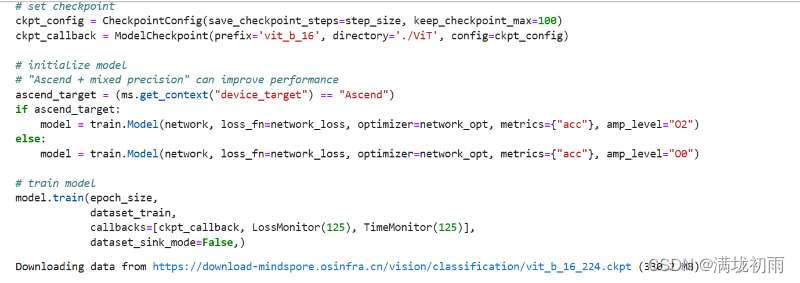
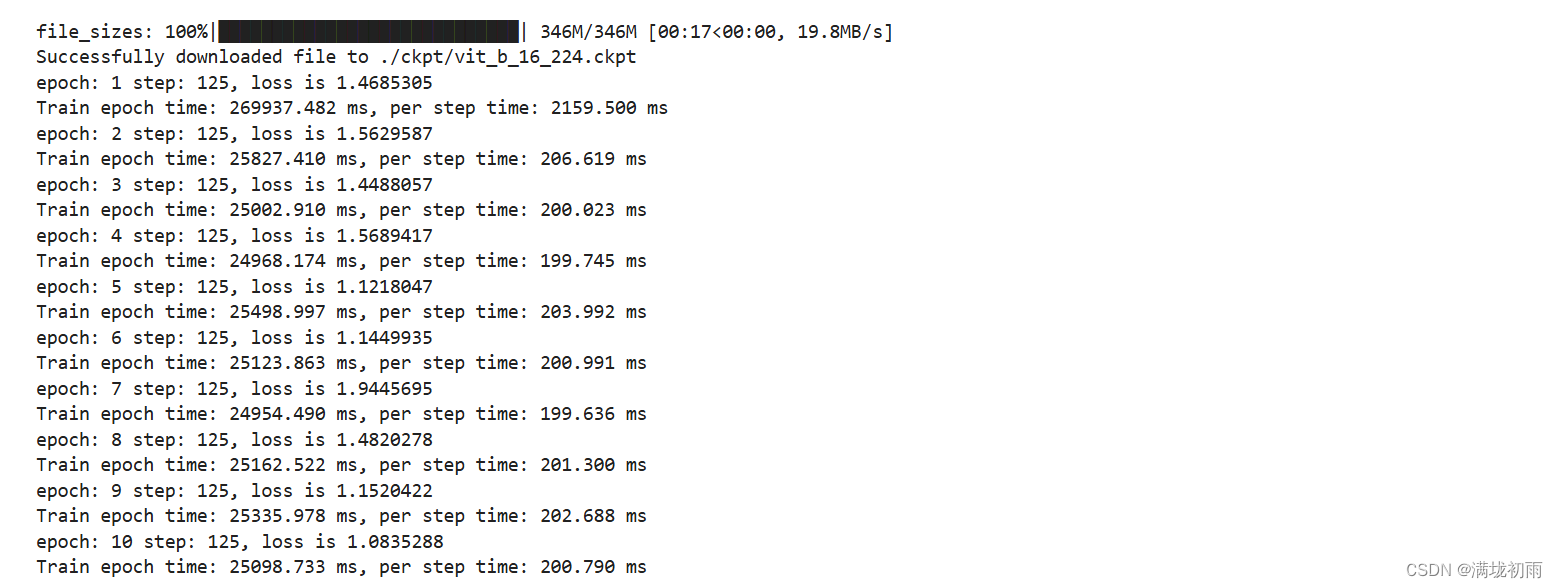
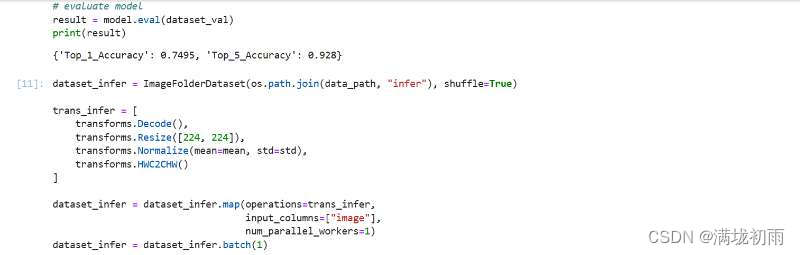
环境准备与数据读取,开始实验之前,需要确保本地已经安装了Python环境并安装了MindSpore。请确保你的数据集路径如下结构。





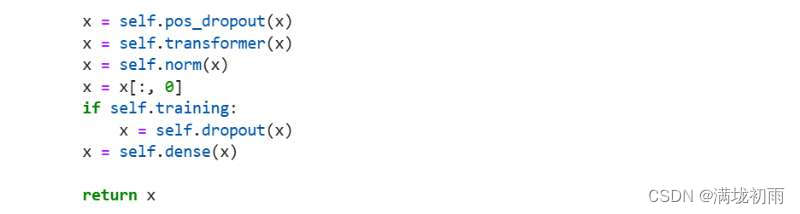





声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/887068
推荐阅读
相关标签

