
- 1VsCode使用EmmyLua插件调试Unity工程Lua代码_vscode emmy launch debug
- 2Hadoop3.2.0 YARN ResourceManager restart_尝试在个人yarn集群配置resourcemanager restart
- 3Android 本地广播 LocalBroadcastManager_android localbroadcastmanager
- 4Ansible学习笔记
- 5【人工智能】百度文心一言智能体:AI领域的新里程碑_文心一言 智能体
- 6国外免考硕士值得读吗?弄明白了再报考!
- 7微信开发者工具的使用
- 8Eureka注册中心无法感知到实例下线_eureka无感下线
- 9Kafka_06_CMAR 管理Kafka_cmak 创建 cluster
- 10vue + element ui 实现侧边栏导航栏折叠收起_element ui 侧边栏菜单
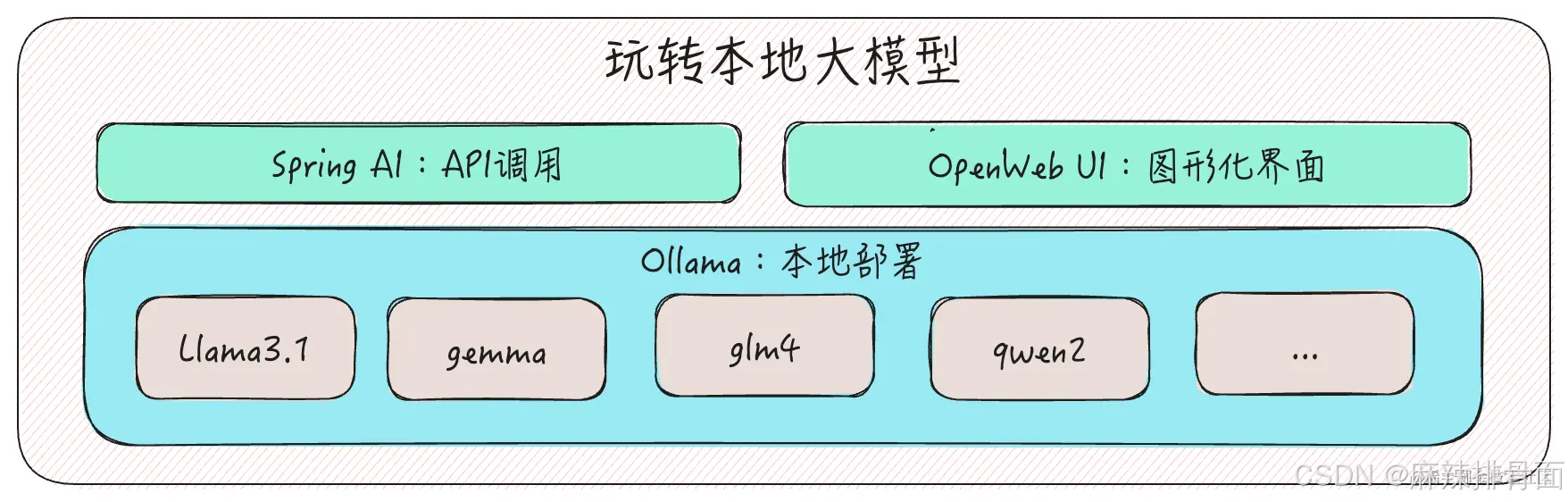
本地部署 Llama 3.1:Ollama、OpenWeb UI 和 Spring AI 的综合指南本文介绍如何使用
赞
踩
本文介绍如何使用 Ollama 在本地部署 Llama 3.1:8B 模型,并通过 OpenWeb UI 和 Spring AI 来增强模型交互体验和简化 API 的调用过程。
Ollama
Ollama 是一个开源的大语言模型服务工具,旨在简化大模型的本地部署和运行过程。用户只需要输入一行命令(如: ollama run llama3.1 ),即可在本地硬件环境中部署和使用大语言模型。Ollama 还提供了 REST API 接口,下文中会介绍如何使用 Spring AI 集成 Ollama,实现与大模型 API 接口的交互。
Ollama 支持下载 Llama、Gemma、qwen 和 glm4 等多种主流大语言模型和代码语言模型,我们可以在 官网 查看 Ollama 支持的所有模型及其相关信息和使用命令。 本机运行 7B 参数量的模型至少需要 8GB 内存,运行 13B 参数量的模型至少需要 16GB 内存,运行 33B 参数量的模型至少需要 32GB 内存。
| 模型 | 参数 | 大小 | 使用命令 |
|---|---|---|---|
| Llama 3.1 | 8B | 4.7GB | ollama run llama3.1 |
| Llama 3.1 | 70B | 40GB | ollama run llama3.1:70b |
| Llama 3.1 | 405B | 231GB | ollama run llama3.1:405b |
| Gemma 2 | 9B | 5.5GB | ollama run gemma2 |
| Gemma 2 | 27B | 16GB | ollama run gemma2:27b |
| qwen2 | 7B | 4.4GB | ollama run qwen2 |
| qwen2 | 72B | 41GB | ollama run qwen2:72b |
| glm4 | 9B | 5.5GB | ollama run glm4 |
下载
访问 Ollama 官网,选择操作系统,然后点击 download 按钮进行下载。操作系统要求 MacOS 11 和 Windows 10 及以上版本。下载完成后的 Ollama 其实是一个命令行工具,我们可以直接在终端中使用 Ollama。(执行 ollama --help 可查看 Ollama 提供的的命令)

部署 Llama 3.1
在终端中执行命令 ollama run llama3.1 ,即可下载 Llama3.1:8B 模型。模型下载完成后,会自动启动大模型,进入命令行交互模式,直接输入指令,就可以和模型进行对话了。

通过 Ollama,我们轻松的实现了本地大模型的部署和命令行式的交互,但是为了更好的使用大模型,以及对大模型进行管理和配置等方面的需求,就需要借助 Ollama 社区中一些强大的工具了,其中代表性的工具之一是 OpenWeb UI(之前称为 Ollama WebUI)。
OpenWeb UI
OpenWeb UI 是一个功能丰富且易于使用的大模型管理工具,它为用户提供了一个直观的图形化界面,以及广泛的功能和灵活的配置选项。
- 方便部署:使用 Docker 实现简单快捷的部署。
- 用户友好的页面:国际化多语言支持,提供多种主题样式,响应式设计,模型参数、Prompt 等便捷配置。
- 功能丰富:本地 RAG 支持,Web 浏览功能(可以在对话中访问网站),语音交互等。
- API 支持:支持 OpenAI API 和其他兼容 API。
- 多模型支持:支持同时管理和操作多个大语言模型。
下载
部署 OpenWeb UI 需要使用 Docker 环境,我本机的 Docker 版本是 24.0.2。OpenWeb UI 提供了集成 Ollama 的部署方式, 因为 Ollama 已经下载到我本机上了,所以只需要执行以下命令即可完成部署。
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
- 1
- 2
容器启动成功后,可以访问 3000 端口,查看页面。首次登陆需要先填写邮箱和密码注册账号。登陆进来后,可以看到,OpenWeb UI 已经自动加载到了我们本地部署的 Llama3.1 模型。

在模型编辑页面,我们可以修改模型的配置参数和 Prompt 等信息,并利用 Document 和 Tools 等工具来增强模型的能力和使用体验。

Spring AI
Spring AI 是 Spring 生态里人工智能方向的应用框架,它提供了与各种大语言模型交互的高级抽象接口,极大地简化了Java 人工智能应用程序的开发过程,让 Java 开发者也能够开发 AI 应用。
接下来将详细介绍 Spring AI 的使用流程,以及如何调用 Ollama 的 API 接口,与我们本地的 Llama 3.1 进行交互。
集成 Ollama
- 创建一个新的 Spring Boot 项目,版本要求 Spring Boot 3 + JDK 17。
- 引入 Spring AI + Ollama 依赖。
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>3.3.1</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>com.cleaner</groupId> <artifactId>culture-ai</artifactId> <version>0.0.1-SNAPSHOT</version> <name>Cleaner-ai</name> <description>culture-ai</description> <properties> <java.version>17</java.version> <spring-ai.version>1.0.0-SNAPSHOT</spring-ai.version> </properties> <dependencies> <!-- ollama --> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-ollama-spring-boot-starter</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> </dependencies> <dependencyManagement> <dependencies> <!-- spring ai --> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-bom</artifactId> <version>${spring-ai.version}</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build> <repositories> <!-- spring ai --> <repository> <id>spring-milestones</id> <name>Spring Milestones</name> <url>https://repo.spring.io/milestone</url> <snapshots> <enabled>false</enabled> </snapshots> </repository> <repository> <id>spring-snapshots</id> <name>Spring Snapshots</name> <url>https://repo.spring.io/snapshot</url> <releases> <enabled>false</enabled> </releases> </repository> </repositories> </project>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 编写 application.yaml 配置文件,添加 Ollama 的相关配置。
server: port: 8888 spring: application: name: Cleaner-AI ai: ollama: # ollama API Server 地址 base-url: http://localhost:11434 chat: enabled: true # 使用的模型名称 model: llama3.1:8b options: temperature: 0.7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 编写接口。
package com.cleaner.ai.controller; import jakarta.annotation.Resource; import org.springframework.ai.chat.messages.UserMessage; import org.springframework.ai.chat.model.ChatResponse; import org.springframework.ai.chat.prompt.Prompt; import org.springframework.ai.ollama.OllamaChatModel; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RequestParam; import org.springframework.web.bind.annotation.RestController; import reactor.core.publisher.Flux; @RestController @RequestMapping("/ollama") public class OllamaController { @Resource private OllamaChatModel ollamaChatModel; /** * 流式对话 * * @param message 用户指令 * @return */ @GetMapping("/streamChat") public Flux<ChatResponse> generateStream(@RequestParam("message") String message) { message = "请使用中文简体回答:" + message; Prompt prompt = new Prompt(new UserMessage(message)); return ollamaChatModel.stream(prompt); } /** * 普通对话 * @param message 用户指令 * @return */ @GetMapping("/chat") public String generate(@RequestParam("message") String message) { message = "请使用中文简体回答:" + message; Prompt prompt = new Prompt(new UserMessage(message)); ChatResponse chatResponse = ollamaChatModel.call(prompt); String content = chatResponse.getResult().getOutput().getContent(); System.out.println("content = " + content); return chatResponse.toString(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 调用接口,可以看到 API 接口调用成功。(8B 模型生成的回答内容还是比较有限)

总结
本地部署的大模型可以脱离网络离线使用,但是要达到实际使用的要求,还需要对模型进行细致化的配置,当然部署模型的参数量越大,使用效果会更好,但也要考虑本机电脑的配置限制。对于学习了解大模型及其相关的技术知识而言,在条件允许的情况下,本机部署确实是一个不错的选择。
那么,如何系统的去学习大模型LLM?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~

篇幅有限,部分资料如下:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/991231
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

