
- 1python中pip镜像源更换_pip国内换源
- 2双路E5平台PVE7.0系统GTX1060 显卡直通_bios 开启 vt-d x2apic
- 3Github访问速度慢,试试这样做
- 4Android全新UI编程 - Jetpack Compose 超详细教程_谷歌内部大佬根据实战编写的《jetpack compose最全上手指南》下载
- 5Qt中如何提升进程间数据通信的性能
- 6OceanBase部署(4.0版)_在服务器上如何根据oceanbase的压缩包部署oceanbase
- 7交互式计算机图形学 第六版 pdf,交互式计算机图形学:基于OpenGL的自顶向下..pdf-得力文库...
- 8HarmonyOS4.0系统性深入开发03UIAbility组件详解(中)
- 9现代软件越来越大、越来越慢、越来越烂!还有救吗?_软件变烂了。
- 10web前端学习(六):WebRTC实时通信,掌握WebSocket很实用_使用websocket进行实时通信,利用webrtc技术实时传输视频 面试
keras冻结_「火炉炼AI」深度学习007-Keras微调进一步提升性能
赞
踩
【火炉炼AI】深度学习007-Keras微调进一步提升性能
【火炉炼AI】深度学习007-Keras微调进一步提升性能
(本文所使用的Python库和版本号: Python 3.6, Numpy 1.14, scikit-learn 0.19, matplotlib 2.2, Keras 2.1.6, Tensorflow 1.9.0)
本文使用微调(Fine-tune)技术来提升模型的性能,是前面的两篇文章(编号为005和006)的延续。前面我们通过迁移学习(文章006)将这个猫狗大战二分类问题的预测准确率提升到了90%左右,但是还能不能进一步提升了?
前面我们没有对VGG16的卷积层进行参数的优化,那么我们这里就可以来优化这部分的参数,当然,优化是很细微的调整,所以称为Fine-tune。
微调也不是对VGG16的所有结构参数都进行调整,而是仅仅调整后面几个卷积层的参数,因为有很多学者发现,对不同的数据集,VGG16提取的特征在底层基本一样,主要区别在于高层,即卷积层的后面几层,所以只需要对这几层进行修改即可。如下我们要调整的层数为:
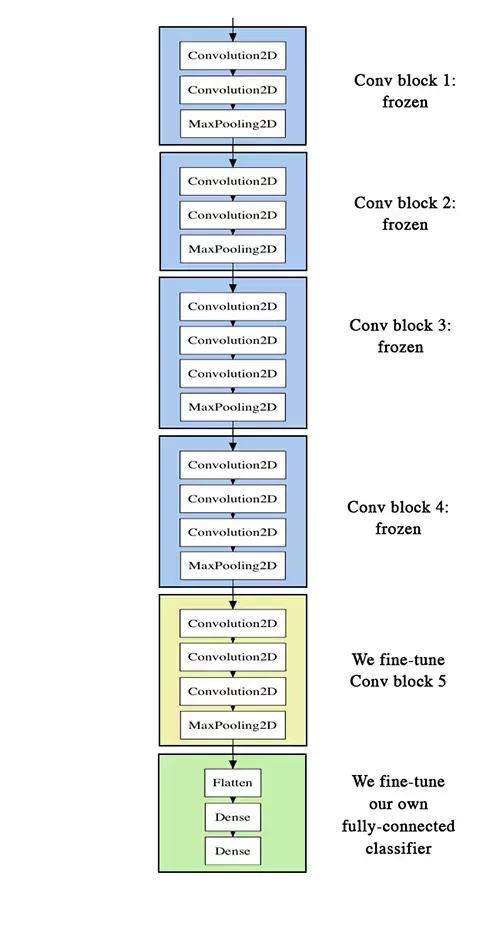
可以看出,主要调整Conv block 5,前面的4个block不需调整。
我这篇博文主要参考了:keras系列︱图像多分类训练与利用bottleneck features进行微调(三),这篇博文也是参考的Building powerful image classification models using very little data,但我发现这两篇博文有很多地方的代码跑不起来,主要原因可能是Keras或Tensorflow升级造成的,所以我做了一些必要的修改。
1. 准备数据集
这一部分和前面文章(编号005)一模一样,故而省略。
2. 构建模型
在模型的构建上,相当于是取VGG16模型的“身子”,再加上自己定义的模型作为“头”,将这两部分加在一起,组成一个完整的模型,“身子”模型仍然采用VGG16在ImageNet上得到的weights,而“头”模型则采用我们上一篇文章中训练得到的weights,然后用这个模型来训练和预测,将“身子”的一部分weights和“头”的全部weights都进行调整。
这里有几个注意点:
1,自己定义的分类器模型作为“头”,但是“头”的weights不能是随机初始值,而应该用已经训练好的weights,因为随机初始值会产生较大的梯队,会破坏前面VGG16卷积层的预训练后weights。
2,微调仅仅针对VGG16网络的后面几层卷积层,而不是全部卷积层,是为了防止过拟合,整个模型结构具有绝大的熵容量,因此有很高的过拟合倾向。并且底层的特征更加具有一般性,不需要调整。
3,在learning rate上,训练“头”的weights时可以用较大的lr,使其快速收敛,而在微调阶段,需要用较小的lr,使其性能达到最优,并且使用的optimizer也通常使用SGD而不是其他自适应学习率的优化算法,比如RMSProp,就是为了保证每次改进的幅度比较低,以免破坏VGG16提取的特征。
# 上面的build_model2中间的my_model.layers[:25]要修改为my_model.layers[:15],原博文此处也是错的。# 4,构建模型from keras.preprocessing.image import ImageDataGeneratorfrom keras.models import Sequentialfrom keras.layers import Dropout, Flatten, Densefrom keras import applicationsfrom keras import optimizersfrom keras.models import Modeldef build_model2(): base_model = applications.VGG16(weights='imagenet', include_top=False,input_shape=(IMG_W, IMG_H,IMG_CH)) # 此处我们只需要卷积层不需要全连接层,故而inclue_top=False,一定要设置input_shape,否则后面会报错 # 这一步使用applications模块自带的VGG16函数直接加载了模型和参数,作为我们自己模型的“身子” # 下面定义我们自己的分类器,作为我们自己模型的“头” top_model = Sequential() top_model.add(Flatten(input_shape=base_model.output_shape[1:])) # 如果没有设置input_shape,这个地方报错,显示output_shape有很多None top_model.add(Dense(256, activation='relu')) top_model.add(Dropout(0.5)) top_model.add(Dense(1, activation='sigmoid')) # 二分类问题 top_model.load_weights('E:PyProjectsDataSetFireAIDeepLearningFireAI006/top_FC_model') # 上面定义了模型结构,此处要把训练好的参数加载进来, my_model = Model(inputs=base_model.input, outputs=top_model(base_model.output)) # 将“身子”和“头”组装到一起 # my_model就是我们组装好的完整的模型,也已经加载了各自的weights # 普通的模型需要对所有层的weights进行训练调整,但是此处我们只调整VGG16的后面几个卷积层,所以前面的卷积层要冻结起来 for layer in my_model.layers[:15]: # 15层之前都是不需训练的,原博文此处也是错的。我晕。。。。 layer.trainable = False # 模型的配置 my_model.compile(loss='binary_crossentropy', optimizer=optimizers.SGD(lr=1e-4, momentum=0.9), # 使用一个非常小的lr来微调 metrics=['accuracy']) return my_model复制代码这个模型的构建中需要将不训练的层冻结,如上设置trainable=False即可,下面进行微调训练:
# 开始用train set来微调模型的参数print('start to train model2')my_model2=build_model2()history_ft2 = my_model2.fit_generator( train_generator, steps_per_epoch=train_samples_num // batch_size, epochs=epochs, validation_data=val_generator, validation_steps=val_samples_num // batch_size)复制代码-------------------------------------输---------出--------------------------------
start to train model2 Epoch 1/20 125/125 [==============================] - 727s 6s/step - loss: 0.3288 - acc: 0.8865 - val_loss: 0.2991 - val_acc: 0.9113 Epoch 2/20 125/125 [==============================] - 732s 6s/step - loss: 0.1822 - acc: 0.9395 - val_loss: 0.2988 - val_acc: 0.9113 Epoch 3/20 125/125 [==============================] - 724s 6s/step - loss: 0.1557 - acc: 0.9445 - val_loss: 0.2742 - val_acc: 0.9125
...
Epoch 18/20 125/125 [==============================] - 703s 6s/step - loss: 0.0260 - acc: 0.9905 - val_loss: 0.3304 - val_acc: 0.9313 Epoch 19/20 125/125 [==============================] - 704s 6s/step - loss: 0.0138 - acc: 0.9955 - val_loss: 0.3267 - val_acc: 0.9413 Epoch 20/20 125/125 [==============================] - 705s 6s/step - loss: 0.0103 - acc: 0.9960 - val_loss: 0.3551 - val_acc: 0.9325
--------------------------------------------完-------------------------------------
在我这个破笔记本上训练非常耗时,20个epoch花了将近四个小时,唉。所以就不打算继续训练下去了。看一下loss和acc的结果:

可以看出test上的acc还可以继续改进一下,train 和test上的loss也没有达到平台期,可以增大epoch继续训练。但是也可以看出有些过拟合现象。
########################小**********结###############################
1,Fine-Tune的核心是对原始的骨架网络(此处为VGG16)进行参数的微调,所以需要用非常小的学习率,而且要用SGD优化器。
2,在使用微调之后,准确率从90%左右提升到了约93%,增加epoch数目可以提升的更多。
#################################################################
注:本部分代码已经全部上传到(我的github)上,欢迎下载。

