
热门标签
热门文章
- 1Unity中脚本中Start函数的两种执行方式_unity start其他函数能调用吗start吗?
- 2下载安装MinGW-w64详细步骤(c/c++的编译器gcc的windows版,win10真实可用)
- 3Python123练习【序列操作,程序控制结构】_使用程序计算整数n到整数n+100
- 4VUE+SpringBoot运行原理_springboot和vue项目运行
- 5关于Chrome谷歌浏览器开发者工具(f12)中Network中Name空白的解决方案_chrome浏览器name不显示sug
- 6手眼标定,眼在手中,眼在手外_gen_cam_par_area_scan_telecentric_division
- 7渲染管线_渲染管线 cs
- 8文本分类(LSTM+PyTorch)_lstm文本分类
- 9Unity导出exe报错,PC端_unity报错build completed with a result of 'failed' i
- 10后台管理UI的选择_后台管理系统ui选择
当前位置: article > 正文
给大语言模型“开天眼”,看图说话性能超CLIP!斯坦福等新方法无需多模态预训练丨开源...
作者:知新_RL | 2024-02-17 23:22:20
赞
踩
大语言模型辅助图像检测模块有哪些内容
卧剿,6万字!30个方向130篇!CVPR 2023 最全 AIGC 论文!一口气读完。
文源 西风 发自 凹非寺 量子位 QbitAI
不靠多模态数据,大语言模型也能看得懂图?!
话不多说,直接看效果。
就拿曾测试过BLIP-2的长城照片来说,它不仅可以识别出是长城,还能讲两句历史:

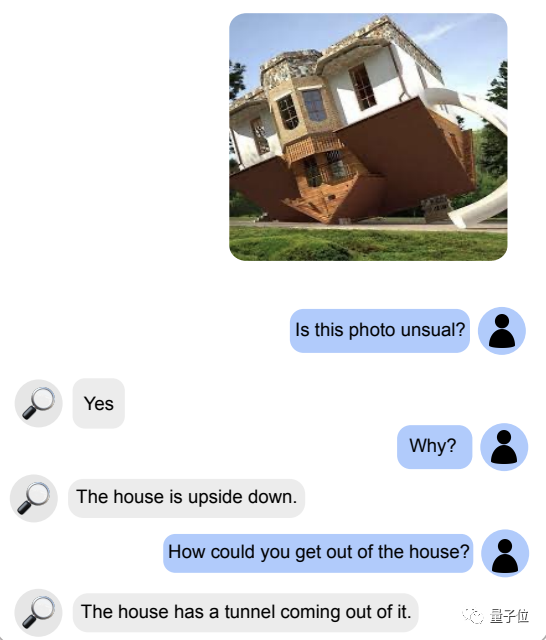
再来一个奇形怪状的房子,它也能准确识别出不正常,并且知道该如何进出:
故意把“Red”弄成紫色,“Green”涂成红色也干扰不了它:

这就是最近研究人员提出的一种新模块化框架——LENS声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/知新_RL/article/detail/102300?site
推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

