
- 1苍穹外卖项目学习----跳过使用微信支付
- 2基于Uniapp+SSM+Vue奶茶点餐订餐小程序的设计与实现_uniapp点餐小程序
- 3将十进制转换成短浮点数格式(IEEE745)并用十六进制表示(组成原理)_十进制转化为浮点数
- 4K-huggingface官网以及diffusers基本使用方法 https://huggingface.co_huggingface官网怎么连接
- 5Java程序员职业规划如何做?_java后端开发职业规划
- 6PyTorch 笔记(02)— 常用创建 Tensor 方法(torch.Tensor、ones、zeros、eye、arange、linspace、rand、randn、new)_torch.tensor.eye
- 725个常用Matplotlib图的Python代码(四):棒棒糖图、包点图、坡度图、哑铃图、连续变量的直方图_python哑铃图
- 8gradle下载网址以及使用方法_gradle下载官网
- 9MagicAnimate:一张照片,让TikTok小姐姐跳舞
- 10AVD Manager(安卓模拟器)启动报错
【数学建模】灰色关联度分析
赞
踩
前言
灰色关联度分析(Grey Relation Analysis,GRA),是一种多因素统计分析的方法。简单来讲,就是在一个灰色系统中,我们想要了解其中某个我们所关注的某个项目受其他的因素影响的相对强弱,再直白一点,就是说:我们假设以及知道某一个指标可能是与其他的某几个因素**相关**的,那么我们想知道这个指标与其他哪个因素相对来说更有关系,而哪个因素相对关系弱一点,依次类推,把这些因素排个序,得到一个分析结果,我们就可以知道我们关注的这个指标,与因素中的哪些更相关。
( note : 灰色系统这个概念的提出是相对于白色系统和黑色系统而言的。这个概念最初是由控制科学与工程(hhh熟悉的一级学科)的教授邓聚龙提出的。按照控制论的惯例,颜色一般代表的是对于一个系统我们已知的信息的多少,白色就代表信息充足,比如一个力学系统,元素之间的关系都是能够确定的,这就是一个白色系统;而黑色系统代表我们对于其中的结构并不清楚的系统,通常叫做黑箱或黑盒的就是这类系统。灰色介于两者之间,表示我们只对该系统有部分了解。)
一、灰色关联度分析是什么
灰色关联度分析和AHP层次分析法、TOPSIS、熵权法等一样,可以用来进行系统分析的方法。但与其他三个不同之处在于灰色关联度分析对样本数量要求不高,计算量较小,数据收集难度较小,且几乎不会出现如量化结果同定性分析结果不符的情况。
二、使用步骤
1.代码准备
代码如下:
1.1 导入库
- import pandas as pd
- import numpy as np
- from numpy import *
- import matplotlib.pyplot as plt
- import warnings
- import seaborn as sns
- import matplotlib as mpl
1.2 读入数据
代码如下(示例):
- data = pd.read_excel('1234565.xlsx',usecols=[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25])
- data.head()
2. 使用步骤
2.1 数据统计分析
在这一部分将会对数据整体分布情况以及整体的趋势进行一个分析,

- 从上图可以看出data3即综合平均违约概率,data1和data2、data4为不同类型企业的违约概率都在呈现上涨趋势。
- 其中data2企业上涨幅度最大。
2.2 确定分析序列
在这一步需要确定分析序列,即确定一个母序列和n个子序列。
母序列(参考序列)是能反映系统行为特征的序列。类似于因变量及被解释变量,此处记为Y
子序列(比较序列)是影响系统行为的因素组成的序列。类似于自变量及解释变量,此处记为(X1,X2,X3,... ,Xn)
在本例中,data3为母序列Y,data1、data2、data4为子序列X1,X2,X3。
2.3 对变量进行预处理
- 数据无量纲化
- 缩小变量范围来简化计算
预处理的方法:先求出每个指标的均值,再用该指标中的每个元素都除以均值,其实这样算出来的结果就避免了因为单位的影响而造成的不可比较性。
无量纲化代码如下图所示:
- # 无量纲化(由于数据之间的物理意义不同,故要对数据先进行无量纲化)
- def dimensionlessProcessing(df):
- newDataFrame = pd.DataFrame(index=df.index)
- columns = df.columns.tolist() #获取数据list
- for c in columns:
- d = df[c]
- MAX = d.max()
- MIN = d.min()
- MEAN = d.mean()
- newDataFrame[c] = ((d - MEAN) / (MAX - MIN)).tolist()
- print('newdataframe',newDataFrame)
- return newDataFrame
2.4 计算子序列中各个指标与母序列的关联系数
设子序列的个数为m,每个序列有n个样本,则我们的数据可以表示为:



设a为两极最小差,b为两极最大差

如下代码所示:
- def GRA_ONE(gray, m=0):
- # 读取为df格式
- gray = dimensionlessProcessing(gray)
- # 标准化
- std = gray.iloc[:, m] # 为标准要素
- gray.drop(str(m),axis=1,inplace=True)
- ce = gray.iloc[:, 0:] # 为比较要素
- shape_n, shape_m = ce.shape[0], ce.shape[1] # 计算行列
-
- # 与标准要素比较,相减
- a = zeros([shape_m, shape_n])
- for i in range(shape_m):
- for j in range(shape_n):
- a[i, j] = abs(ce.iloc[j, i] - std[j])
- print('a',a)
- # 取出矩阵中最大值与最小值
- c, d = amax(a), amin(a)
关联系数y(Gamma值)的公式为:

其中ρ为分辨系数,一般取0.5,
代码如下图所示:
- # 计算值
- result = zeros([shape_m, shape_n])
- for i in range(shape_m):
- for j in range(shape_n):
- result[i, j] = (d + 0.5 * c) / (a[i, j] + 0.5 * c)
2.5 计算各个子序列的灰色关联度
设灰色关联度为r,则:
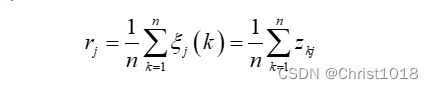
(这一部分其实就是对每一个子序列的关联系数取平均值)
总结
灰色关联度分析其实总的来说就五步骤
- 第一步先对数据进行无量纲化,去除因为变量单位不统一而导致的数值含义不一样的问题
- 第二步就是要找出因变量和自变量从而确定字母序列
- 第三步就是求出各个指标与母序列的关联系数,即用Y(K)-X(K),再选取其中的最大值和最小值
- 第四步求出关联系数
- 第五步就是求出每个子序列的均值关联系数


