- 1如何接收用户发送的短信验证码,判断是否合法-短信验证码开发10_如何保证接收验证码手机号的合法性呢
- 2windows安装hadoop教程,带截图
- 3声学多普勒流速剖面仪_带上这款声速仪,来一场说走就走的超便捷水深测量
- 4从0开始入门智能知识库和星火大模型,打造AI客服。_使用 星火 训练智能客服
- 5WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platfo
- 6关于 GPT必须知道的10 个认知!_gpt的本质
- 7问题解决:idea 中无法连接 sql server 数据库,报错 [08S01] 驱动程序无法通过使用安全套接字层(SSL)加密与 SQL Server 建立安全连接_interbase database support is not licensed
- 8苹果审核团队_苹果审核力度加强,不止警告直接下架!
- 9Flutter 中获取地理位置[Flutter专题61]_flutter location
- 10【设计模式】Springboot 项目实战中使用策列+工厂模式优化代码中的if...else.._springboot if 优化
Filebeat将csv导入es尝试_filebeat导入csv文件
赞
踩
一、安装
二、主要配置
|
|
三、关于elastic的pipline
https://hacpai.com/article/1512990272091
我简单介绍主流程,详情见上链接
1.开启数据预处理,node.ingest: true
2.向es提交pipline,并命名为my-pipeline-id
PUT _ingest/pipeline/my-pipeline-id
{
"description" : "describe pipeline",
"processors" : [
{
"set" : {
"field": "foo",
"value": "bar"
}
}
]
}
3.以上pipline的作用
若产生新的数据,会新增一个字段为foo:bar
4.curl的pipline即时测试
POST _ingest/pipeline/_simulate
是一个测试接口,提供pipline的规则和测试数据,返回结果数据
四、关于grok
是pipline中的正则匹配模式,以上规则的复杂版
|
|
五、使用pipline导入csv
|
|
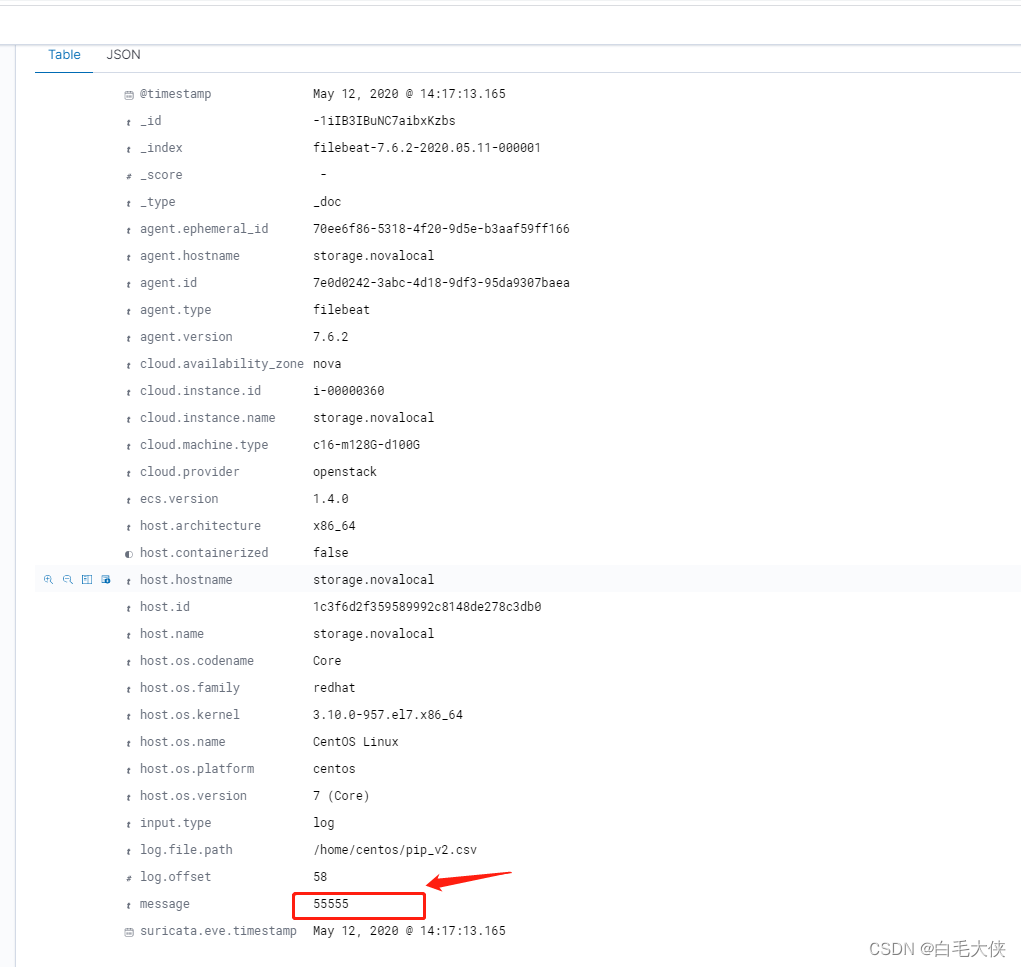
测试结果pipline配置后,并没生效。
六、结论
1.filebeat 导入csv的资料很少,主要为pipline方式,测试几个失败。
2.J和数据组并没有filebaeat 导入csv的成功案例。J不太建议使用
结论:filebeat导csv并不方便,建议采用logstash。
一般日志收集可使用logstash,每行的信息会存到message中