
- 11. 查询全部学生的学号、姓名、课程名称、成绩。_查询所有学生的学号,姓名,课程名和成绩
- 2学习opencv:PS滤镜—扩散_ps滤镜扩散有什么用
- 3基于Springboot框架家教老师预约系统设计与实现 开题报告
- 43D目标检测之数据集_3d目标检测数据集
- 5发现新词 | NLP之无监督方式构建词库(一)
- 6虚拟机下Redis的安装和部署_虚拟机上部署redis
- 7跨境电商竞品分析报告_跨境电商平台 竞品分析 苹果手机华为手机
- 8java基础教程01讲:使用idea写第一个java程序_idea怎么写代码
- 9Python模块学习 - fabric
- 10Linux进程管理学习心得_linux父子进程学习心得体会
【深度学习】——神经网络DNN/CNN/RNN/LSTM内部结构区别_rnn,cnn,dnn,lstm区别
赞
踩
一、DNN深度神经网络
先说DNN,从结构上来说他和传统意义上的NN(神经网络)没什么区别,但是神经网络发展时遇到了一些瓶颈问题。一开始的神经元不能表示异或运算,科学家通过增加网络层数,增加隐藏层可以表达。并发现神经网络的层数直接决定了它对现实的表达能力。但是随着层数的增加会出现局部函数越来越容易出现局部最优解的现象,用数据训练深层网络有时候还不如浅层网络,并会出现梯度消失的问题。我们经常使用sigmoid函数作为神经元的输入输出函数,在BP反向传播梯度时,信号量为1的传到下一层就变成0.25了,到最后面几层基本无法达到调节参数的作用。值得一提的是,最近提出的高速公路网络和深度残差学习避免梯度消失的问题。DNN与NN主要的区别在于把sigmoid函数替换成了ReLU,maxout,克服了梯度消失的问题。
二、CNN卷积神经网络
深度学习的深度没有固定的定义,2006年Hinton解决了局部最优解问题,将隐含层发展到7层,这达到了深度学习上所说的真正深度。不同问题的解决所需要的隐含层数自然也是不相同的,一般语音识别4层就可以,而图像识别20层屡见不鲜。但随着层数的增加,又出现了参数爆炸增长的问题。假设输入的图片是1K*1K的图片,隐含层就有1M个节点,会有10^12个权重需要调节,这将容易导致过度拟合和局部最优解问题的出现。为了解决上述问题,提出了CNN。
CNN最大的利用了图像的局部信息。图像中有固有的局部模式(比如轮廓、边界,人的眼睛、鼻子、嘴等)可以利用,显然应该将图像处理中的概念和神经网络技术相结合,对于CNN来说,并不是所有上下层神经元都能直接相连,而是通过“卷积核”作为中介。同一个卷积核在所有图像内是共享的,图像通过卷积操作后仍然保留原先的位置关系。卷积神经网络隐含层,通过一个例子简单说明卷积神经网络的结构。假设m-1=1是输入层,我们需要识别一幅彩色图像,这幅图像具有四个通道ARGB(透明度和红绿蓝,对应了四幅相同大小的图像),假设卷积核大小为100*100,共使用100个卷积核w1到w100(从直觉来看,每个卷积核应该学习到不同的结构特征)。用w1在ARGB图像上进行卷积操作,可以得到隐含层的第一幅图像;这幅隐含层图像左上角第一个像素是四幅输入图像左上角100*100区域内像素的加权求和,以此类推。同理,算上其他卷积核,隐含层对应100幅“图像”。每幅图像对是对原始图像中不同特征的响应。按照这样的结构继续传递下去。CNN中还有max-pooling等操作进一步提高鲁棒性。
一个典型的卷积神经网络结构,注意到最后一层实际上是一个全连接层。在这个例子里,我们注意到输入层到隐含层的参数个数瞬间降低到了,这使得我们能够用已有的训练数据得到良好的模型。适用于图像识别,正是由于模型限制参数了个数并挖掘了局部结构的这个特点,顺着同样的思路,利用语音语谱结构中的局部信息,CNN照样能应用在语音识别中。CNN结构图如下:


三、RNN循环神经网络
全连接的DNN还存在着另一个问题——无法对时间序列上的变化进行建模。然而,样本出现的时间顺序对于自然语言处理、语音识别、手写体识别等应用非常重要。对了适应这种需求,就出现了另一种神经网络结构——循环神经网络RNN。在普通的全连接网络或CNN中,每层神经元的信号只能向上一层传播,样本的处理在各个时刻独立,因此又被成为前向神经网络(Feed-forward Neural Networks)。而在RNN中,神经元的输出可以在下一个时间戳直接作用到自身,即第i层神经元在m时刻的输入,除了(i-1)层神经元在该时刻的输出外,还包括其自身在(m-1)时刻的输出!表示成图就是这样的:
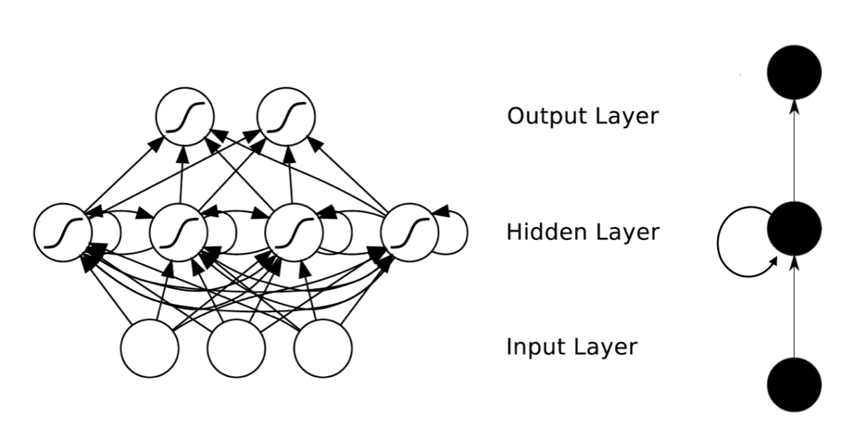
我们可以看到在隐含层节点之间增加了互连。为了分析方便,我们常将RNN在时间上进行展开,得到如图6所示的结构

RNN可以看成一个在时间上传递的神经网络,它的深度是时间的长度!正如我们上面所说,“梯度消失”现象又要出现了,只不过这次发生在时间轴上。对于t时刻来说,它产生的梯度在时间轴上向历史传播几层之后就消失了,根本就无法影响太遥远的过去。因此,之前说“所有历史”共同作用只是理想的情况,在实际中,这种影响也就只能维持若干个时间戳。为了解决时间上的梯度消失,机器学习领域发展出了长短时记忆单元。
四、LSTM(长短时记忆网络)
参见文章:https://www.cnblogs.com/pinard/p/6519110.html
视频讲解:https://www.bilibili.com/video/av30578651?from=search&seid=8975336397144365929




