
- 1JAVA微信小程序购物商城系统毕业设计 开题报告_基于java网上商城系统的写作提纲
- 2[Python] 函数详解_python 生日歌(参数传递)
- 3Meta 开移动端 AI 生成神器 PyTorch Live,打造人工智能驱动的移动体验_meta公司基于torch开发了基于python的pytorch框架,并于2017年1月将其开源。
- 4python duplicated函数_Python Pandas Dataframe.duplicated()用法及代码示例
- 5太阳能电池片制造工艺_太阳能电池制作流程
- 6Git使用个人访问令牌提交代码到仓库_git令牌
- 7TCP的三次握手与四次挥手理解_为什么是fin的序号代表最后一个字节
- 8第十一章:GCN——图卷积神经网络:全面回顾
- 9将数据从 SQL Server 数据库复制到 Azure Blob 存储_sql备份到azure storage
- 10解决Ubantu扩展磁盘空间和使用命令sudo apt-get install gparted安装gparted工具时出现E: Unable to locate package gperted问题_unable to locate package gparted
MongoDB 学习笔记_mongodb uri
赞
踩
概述
MongoDB 是一个介于关系型数据库和非关系型数据库之间的产品,是非关系型数据库中功能最丰富,最像关系型数据库的。
MongoDB 支持的数据结构非常松散,类似 json 的 bson 格式,因此可以存储比较复杂的数据类型。MongoDB 最大的特点是支持的查询语言非常强大,语法类似于面向对象的查询语言,几乎可以实现类似关系型数据库单表查询的绝大部分功能,还支持对数据建立索引
MongoDB 的特点:
- 面向集合存储,易存储对象类型的数据
- 支持查询,以及动态查询
- 支持多种语言
- 文件存储格式为 BSON
- 支持主从复制、故障恢复和分片
MongoDB 的应用场景:
- 游戏应用:使用 MongoDB 作为游戏服务器的数据库存储用户信息,用户的游戏装备、积分等直接以内嵌文档的形式存储,方便查询和更新
- 物流应用:使用 MongoDB 存储订单信息,订单状态在运送过程中会不断更新,以内嵌数组的形式存储,一次查询就能将订单所有的变更读取出来
- 社交应用:使用 MongoDB 存储用户信息以及用户发表的朋友圈信息,通过地理位置索引实现附近的人、地点等功能,存储聊天记录
- 大数据应用:使用 MongoDB 作为大数据的云存储系统,随时进行数据提取分析,掌握行业动态
MongoDB 安装
1. 传统方式安装
在官网下载对应版本的安装包并解压:https://www.mongodb.com/try/download/communiy
这里选择 ubuntu 环境下的 5.0.8 版本
进入 bin 目录,启动 MongoDB 服务
./mongod --port=27017 --dbpath ../data --logpath ../logs/mongo.log &
- 1
- port:指定服务监听端口,默认 27017
- dbpath:指定 mongo 的数据存放目录
- logpath:指定 mongo 的日志存放目录
- &:表示程序在后台运行
使用客户端连接 MongoDB 服务
# ./mongo [mongodb://[主机名:端口号]]
./mongo mongodb://127.0.0.1:27017
- 1
- 2
2. Docker 方式安装
拉取 MongoDB 镜像
docker pull mongo:5.0.8
- 1
运行 MongoDB 镜像
docker run -d --name mongo --p 27017:27017 mongo:5.0.5
- 1
进入 MongoDB 容器
docker exec -it [容器id] bash
- 1
MongoDB 核心概念
1. 库
MongoDB 中的库类似传统关系型数据库中库的概念,用来通过不同的库隔离不同的数据
MongoDB 中可以建立多个数据库,每一个库都有自己的集合和权限,不同的数据库也放置在不同的文件中
2. 集合
集合就是 MongoDB 文档组,类似于关系型数据库中表的概念
集合存储在库中,一个库可以有多个集合,每个集合没有固定的结构,这意味着可以对集合插入不同格式和类型的数据,但通常我们插入集合数据都会有一定的关联性
3. 文档
文档集合中的记录,是一组键值对(BSON)
MongoDB 的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别,也是 MongoDB 的特点
一个简单的文档例子:
{"site":"www.google.com", "name":"xiaowang"}
- 1
MongoDB 基本操作
1. 库操作
# 查看所有库,默认不显示没有集合的库
show databases | show dbs
# 选中一个库,如果库不存在,则自动创建
use [库名]
# 帮助指令
db.help()
# 查看当前库
db
# 删除当前库
db.dropDatabase()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
MongoDB 有三个保留库:
- admin:从权限的角度来看,这是 root 数据库。如果一个用户被添加到这个数据库,这个用户将自动继承对所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器
- local:该库的数据永远不会被复制(例如创建副本),可以用来存储仅限于本地单台服务器的任意集合
- config:当 Mongo 用于分片设置时,config 数据库在内部使用,用于保存分片的相关信息
2. 集合操作
# 查看当前库的集合
show collections | show tables
# 显示创建集合
# db.createCollection("[集合名]", [Options])
db.createCollection("products", {capped:true,size:5000})
# 向集合插入数据/隐式创建集合,向不存在的集合插入数据也可以创建集合
# db.[集合名称].insert({"[属性名]":"[属性值]",...})
db.emp.insert({name:"xiaowang"})
# 删除集合
# db.[集合名称].drop()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Options 可以是如下参数:
- capped:(可选)如果为true,则创建固定集合。固定集合是指有着固定大小的集合,当达到最大值时,它会自动覆盖最早的文档。当该值为 true 时,必须指定 size 参数
- size:(可选)为固定集合指定一个最大值,即字节数。如果 capped 为 true,也需要指定该字段
- max:(可选)指定固定集合中包含文档的最大数量
3. 文档操作
# 插入单条文档 db.[集合名称].insert({"[属性名]":"[属性值]",...}) # 插入多条文档 db.[集合名称].insertMany( [<document1>,<document2>,...], { writeConcern: 1 # 写入策略,默认为1,表示要求确认写操作,为0不要求 ordered: true # 指定是否按顺序写入,默认为true,按顺序写入 } ) db.[集合名称].insert( [<document1>,<document2>,...] ) # 脚本方式插入多条文档,MongoDB默认会为每一条文档设置一个_id的key for(var i = 0; i < 10; i++) { db.[集合名称].insert({"_id":i, ....}) } # 查询文档 # query 可选,指定查询条件 # projection 可选,指定返回的键值,不写默认返回全部键值 # pretty 对返回结果格式化 db.[集合名称].find(query,project).pretty() # 使用运算符查询 # > : ($gt) # < : ($lt) # >= : ($gte) # <= : ($lte) # = : ($eq) # != : ($ne) # 查询年龄大于29的用户记录 db.users.find({age:{$gt:29}}) # AND 查询 db.[集合名称].find($and:[{key1:value1,key2:value2,...},...]).pretty() # OR 查询 db.[集合名称].find($or:[{key1:value1,key2:value2,...},...]).pretty() # and or 联合 db.[集合名称].find($and:[...],$or:[...]).pretty() # not or 查询,既不是也不是 db.[集合名称].find($nor:[...]).pretty() # 模糊查询 db.[集合名称].find({查询字段:正则表达式}) # 数组中查询,找出likes数组字段中有看电视值的记录 db.users.find({likes:"看电视"}) # 数组中查询,找出likes数组字段长度为3的记录 db.users.find({likes:{$size:3}}) # 对查询排序,1升序,2降序 db.[集合名称].find({查询条件}).sort({排序字段:升序/降序,...}) # 对查询分页 db.[集合名称].find({查询条件}).skip(起始条数).limit(每页显示的记录数) # 查询总条数 db.[集合名称].count() # 去重 db.[集合名称].distinct("字段") # 文档删除 db.[集合名称].remove( <query>, # 可选,删除文档的条件 { justOne: <boolean> # 可选,设为true则只删除一个文档,否则删除所有匹配的文档 writeConcern: <document> # 可选,抛出异常的级别 } ) # 删除_id为1的文档 db.users.remove({"_id":1}) # 更新文档 db.[集合名称].update( <query>, # 查询条件 <update>, # 更新操作符,类似sql update的set { upsert: <boolean>, # 可选,如果不存在记录,则插入,默认为true multi: <boolean>, # 可选,默认false表示只更新第一条记录,true表示更新符合条件的全部记录 writeConcern: <document> # 可选,抛出异常的级别 } ) # 这种更新相当于先删除再插入 db.[集合名称].update({"name":"zhangsan" },{name:"11",bir:new date()}) # 保存原有数据的更新 db.[集合名称].update({"name":"xiaohei"},{$set:{name:"mingming"}})

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
MongoDB 索引
1. 简介
索引能极大的提高查询效率。索引是特殊的数据结构,它存储在一个易于遍历读取的数据集合中,是对数据库表中一列或多列的值进行排序的一种数据结构
MongoDB 索引原理如图所示:
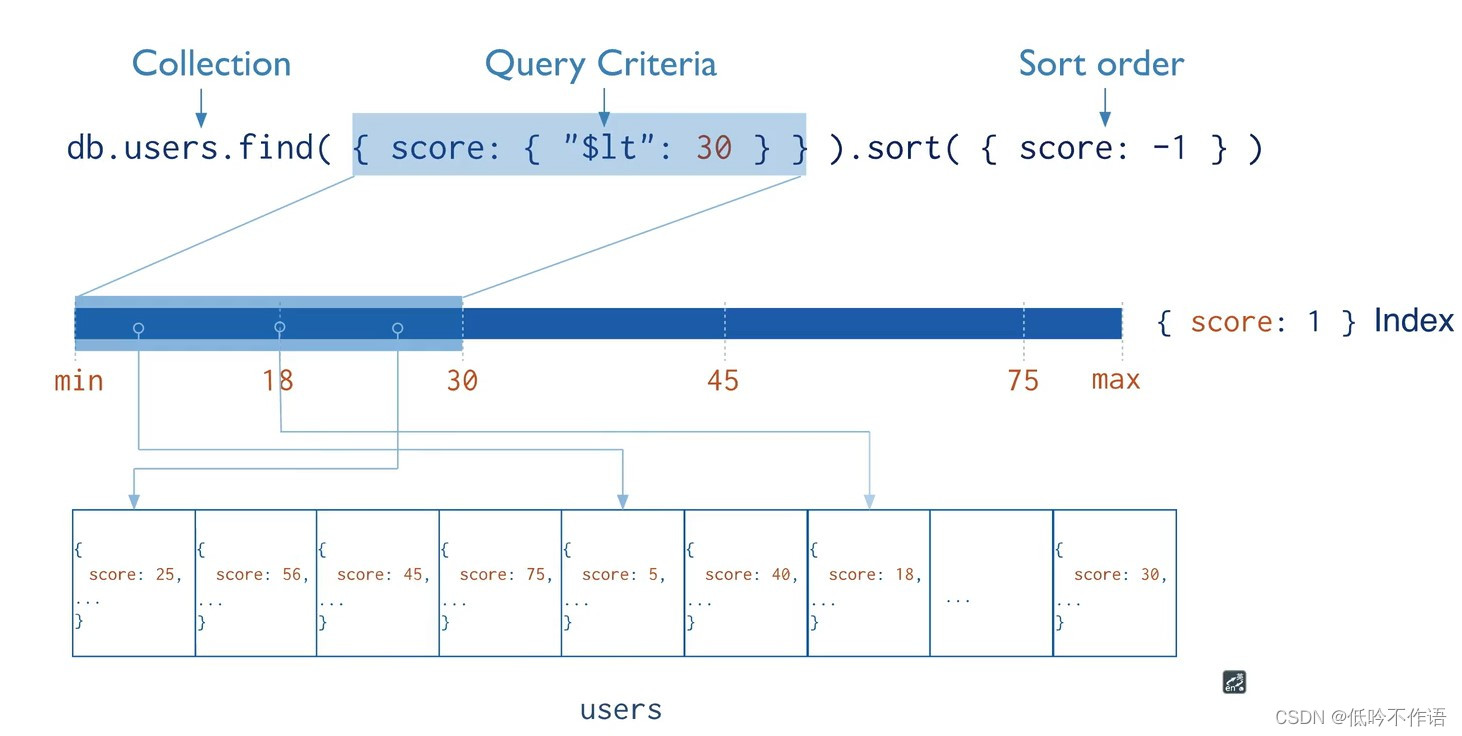
MongoDB 的索引和其他关系型数据库中的索引类似,MongoDB 在集合层面上定义了索引,并支持对 MongoDB 集合中的任何字段或文档的子字段进行索引
2. 索引操作
# 创建索引,1为指定按升序创建索引,-1为降序
db.[集合名称].createIndex(keys,options)
db.topics.createIndex({"title":1})
# 创建复合索引,只有使用索引前部的查询才能使用该索引
db.[集合名称].createIndex({"[要创建索引的字段]":1,....})
# 查看索引
db.[集合名称].getIndexes()
# 查看集合索引大小
db.[集合名称].totalIndexSize()
# 删除集合所有索引
db.[集合名称].dropIndexs()
# 删除集合指定索引
db.[集合名称].dropIndex("索引字段")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
createIndex 可接受以下可选参数:
| Parameter | Type | Description |
|---|---|---|
| background | Boolean | 建索引过程会阻塞其它数据库操作,background 可指定以后台方式创建索引,即增加 background 可选参数。 “background” 默认值为 false |
| unique | Boolean | 建立的索引是否唯一。指定为 true 创建唯一索引。默认值为 false |
| name | string | 索引的名称。如果未指定,MongoDB 的通过连接索引的字段名和排序顺序生成一个索引名称 |
| dropDups | Boolean | 3.0+ 版本已废弃。在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 false |
| sparse | Boolean | 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为 true 的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false |
| expireAfterSeconds | integer | 指定一个以秒为单位的数值,完成 TTL 设定,设定集合的生存时间 |
| v | index version | 索引的版本号。默认的索引版本取决于 mongod 创建索引时运行的版本 |
| weights | document | 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。 |
| default_language | string | 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语 |
| language_override | string | 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的 language,默认值为 language |
SpringBoot 整合 MongoDB
引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
- 1
- 2
- 3
- 4
编写配置
# mongodb(协议)://主机:端口/库名
spring.data.mongodb.uri=mongodb://127.0.0.1:27017/test
# 如果开启用户名密码校验
spring.data.mongodb.host=127.0.0.1
spring.data.mongodb.port=27017
spring.data.mongodb.database=test
spring.data.mongodb.username=root
spring.data.mongodb.password=123
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
创建和删除集合
@Test
public void testCollection() {
// 创建集合
mongoTemplate.createCollection("products");
// 删除集合
mongoTemplate.dropCollection("products");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
操作文档
@Document("users") // 代表是users集合的文档
public class User {
@Id // 映射文档的_id
private Integer id;
@Field // 映射文档的键值对
private String name;
@Field
private Integer salary;
@Field
private Date birthday;
....
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
@Test public void testDocument() { User user = new User(1, "hhh", 3000, new Date()) // _id存在时更新数据 mongoTemplate.save(user) // _id存在时发生主键冲突 mongoTemplate.insert(user) // 批量插入 List<User> users = Arrays.asList( new User(2, "aaa", 3000, new Date()), new User(3, "bbb", 3000, new Date()) ); mongoTemplate.insert(users, User.class) // 基于id查询 mongoTemplate.findById("1", User.class); // 查询所有 mongoTemplate.findAll(User.class); mongoTemplate.find(new Query(), User.class); // 等值查询 mongoTemplate.find(new Query(Criteria.where("name").is("aaa")), User.class); // > gt < lt >= gte <= lte mongoTemplate.find(new Query(Criteria.where("age").lt(25)), User.class); mongoTemplate.find(new Query(Criteria.where("age").gt(25)), User.class); mongoTemplate.find(new Query(Criteria.where("age").gte(25)), User.class); mongoTemplate.find(new Query(Criteria.where("age").lte(25)), User.class); // and 查询 mongoTemplate.find(new Query(Criteria.where("name").is("aaa").and("salary").is(3000)), User.class); // or 查询 mongoTemplate.find( new Query( Criteria.orOperator( Criteria.where("name").is("aaa"), Criteria.where("name").is("bbb") )), User.class); // and or 查询 mongoTemplate.find( new Query( Criteria.where("salary").is("3000") .orOperator( Criteria.where("name").is("aaa") )), User.class); // 排序查询 mongoTemplate.find( new Query().with(Sort.by(Sort.Order.desc("salary"))), User.class); // 分页查询 mongoTemplate.find( new Query().with(Sort.by(Sort.Order.desc("salary"))) .skip(0) .limit(2), User.class); // 总条数 mongoTemplate.count(new Query(), User.class); // 去重 mongoTemplate.findDistinct(new Query(), User.class); // 使用json字符串查询 Query query = new BasicQuery("{name:'aaa'}"); mongoTemplate.find(query, User.class); // 更新条件 Query query = Query().query(Criteria.where("age").is(23)); // 更新内容 Update update = new Update(); update.set("name", "ccc"); // 单条更新 mongoTemplate.updateFirst(query, update, User); // 多条更新 mongoTemplate.updateMulti(query, update, User); // 更新插入 mongoTemplate.upsert(query, update, User); // 删除所有 mongoTemplate.remove(new Query, User.class); // 条件删除 mongoTemplate.remove( Query.query(Criteria.where("name").is("aaa")) , User.class); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
MongoDB 副本集
1. 简介
MongoDB 副本集是有自动故障恢复功能的主从集群,由一个 Primary 节点和一个或多个 Secondary 节点组成。副本集群没有固定的主节点。当出现故障时,整个集群会选举出一个主节点,保证系统的高可用性
2. 搭建副本集
创建数据目录
sudo mkdir repl1 repl2 repl3
- 1
启动三个节点
# --replSet 副本集选项 myreplace 副本集名称/集群中其他节点的主机和端口号
sudo ./mongod --port 27017 --dbpath ../repl1 --bind_ip 0.0.0.0 --replSet myreplace/[localhost:27018,localhost:27019]
sudo ./mongod --port 27018 --dbpath ../repl2 --bind_ip 0.0.0.0 --replSet myreplace/[localhost:27017,localhost:27019]
sudo ./mongod --port 27019 --dbpath ../repl3 --bind_ip 0.0.0.0 --replSet myreplace/[localhost:27017,localhost:27018]
- 1
- 2
- 3
- 4
配置副本集,通过 client 登录到任意一个节点,必须在 mongo 中默认的 admin 库中做集群的配置
use admin
# 定义配置信息
> var config = {
"_id":"myreplace",
members:[
{_id:0,host:"aaa:27017"},
{_id:1,host:"aaa:27018"},
{_id:2,host:"aaa:27019"}]
}
# 初始化副本集
rs.initiate(config)
# 开启从节点查询权限
rs.slaveOk()
# 查看副本集状态
rs.status()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
MongoDB 分片集群
1. 简介
分片是指将数据拆分,将其分散存在不同的机器上,不需要功能强大的大型计算机就可以存储更多的数据,处理更大的负载
MongoDB 支持自动分片,可以摆脱手动分片的管理困扰。MongoDB 分片的基本思想就是将集合切分成小块,这些块分散到若干片里面,每个片只负责总数据的一部分,应用程序不必知道分片细节

- Shard:用于实际存储的数据块,实际生产中一个 Shard Server 角色可以组成一个副本集,防止主机单点故障
- Config Server:配置服务器存储集群的元数据和相关设置,配置服务器必须部署为副本集
- Query Remote:分片之前要运行一个路由进程,该进程名为 mongos,这个路由器知道所有数据的存放位置,应用可以连接它来正常发送请求。路由器知道数据和片的对应关系,能够转发请求正确的片上,如果请求有了回应,路由器将收集起来回送给应用
- Shard Key:设置分片时需要在集合中选一个键,用该键的值作为拆分数据的依据,这个片键称为 shard key
2. 搭建分片集群
# 1.集群规划 Shard Server 1:27017 Shard Repl 1:27018 Shard Server 2:27019 Shard Repl 2:27020 Shard Server 3:27021 Shard Repl 3:27022 Config Server :27023 Conifg Server :27024 Conifg Server :27025 Route Process :27026 # 2.进入安装的 bin 目录创建数据目录 mkdir -p ../cluster/shard/s1 mkdir -p ../cluster/shard/s1-repl ... mkdir -p ../cluster/shard/config3 # 3.启动4个shard服务并分别初始化 sudo ./mongod --port 27017 --dbpath ../cluster/shard/s1 --bind_ip 0.0.0.0 --shardsvr --replSet r0/127.0.0.1:27018 sudo ./mongod --port 27018 --dbpath ../cluster/shard/s1 --bind_ip 0.0.0.0 --shardsvr --replSet r0/127.0.0.1:27017 ... # 4.启动3个config服务并初始化 sudo ./mongod --port 27023 --dbpath ../cluster/shard/config1 --bind_ip 0.0.0.0 --configsvr --replSet r0/[127.0.0.1:27024,127.0.0.1:27025] ... > var config = { "_id":"config", configsvr:true, members:[ {_id:0,host:"127.0.0.1:27023"}, {_id:1,host:"127.0.0.1:27024"}, {_id:2,host:"127.0.0.1:27025"} ] } > rs.initiate(config) # 5.启动路由服务 ./mongos --port 27026 --configdb config/127.0.0.1:27023,127.0.0.1:27024,127.0.0.1:27025 --bind_ip 0.0.0.0 # 6.登录mongos服务 # 6.1 登录 mongo --port 27026 # 6.2 使用 admin 库 use admin # 6.3 添加分片信息 db.runCommand({addshard:"127.0.0.1:27017","allowLocal":true}) db.runCommand({addshard:"127.0.0.1:27019","allowLocal":true}) db.runCommand({addshard:"127.0.0.1:27021","allowLocal":true}) # 6.4 指定分片的数据库 db.runCommand({enablesharding:"[库名]"}) # 6.5 设置库的片键信息 db.runCommand({shardcollection:"[库名].[集合名]",key:{[字段名]:1}}) db.runCommand({shardcollection:"[库名].[集合名]",key:{[字段名]:"hashed"}}) # 通过对片键哈希将数据散开
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57

