
- 1Flink SQL 1.11新功能详解:Hive 数仓实时化 & Flink SQL + CDC 实践_hive cdc
- 2论文阅读--Search to Distill
- 3C语言学习——数据在内存中的存储_c语言数据在内存中的存储形式
- 4《自然语言处理实战入门》 第二章:NLP 前置技术 ---- python开发环境搭建(IDE 与编码规范简介)_自然语言处理nlp实战
- 5离线数仓和实时数仓的区别_实时数仓和离线数仓的区别
- 6HBase数据库设计之RowKey_hbase 数据库设计之 rowkey 第1关:金融类 rowkey 设计
- 7Gazebo无法加载机器人模型(urdf),打开是空白界面_urdf导入vrep后不显示机器人模型
- 8关于DBSCAN聚类算法
- 9Python + logging输出到屏幕,将log日志写入到文件_python logging 写入文件
- 10leetcode--接雨水(双指针法,动态规划,单调栈)_接雨水leetcode
2022最新ES面试题整理(Elasticsearch面试指南系列)
赞
踩
文章目录
引言
看到网上各式各样关于Elasticsearch面试题的文章,但是貌似都不是很全面,所以特意整理了一篇关于常见的ES面试题,已收录至面试专栏,计划更新 10/50 个常见面试题,此次先发出来 10个,后续更新,请关注我的博客,第一时间查看更新。
另外,本文目前对面试问题的描述存在以下几个问题,将在后续更新中不断改善,是的这篇文章还会改进!
- 答案过于书面,需要自己组织语言
- 只适合
Question1:Elasticsearch是什么
Elasticsearch是什么
Elasticsearch是由 Java语言开发基于Lucene的一款开源的搜索、聚合分析和存储引擎。同时它也可以称作是一种非关系型文档数据库。
-
天生分布式、高性能、高可用、易扩展、易维护。
-
跨语言、跨平台:几乎支持所有主流编程语言,并且支持在“Linux、Windows、MacOS”多平台部署
-
支持结构化、非结构化、地理位置搜索等
-
海量数据的全文检索,搜索引擎、垂直搜索、站内搜索:
- 百度、知乎、微博、CSDN
- 导航、外卖、团购等软件
- 以京东、淘宝为代表的垂直搜索
- B站、抖音、爱奇艺、QQ音乐等音视频软件
- GIthub
-
数据分析和聚合查询
-
日志系统:ELK
Question 2:ES中mapping是什么,你知道es哪些数据类型?
mapping是什么,你知道ES的哪些数据类型
2.1 mapping解释
ES中的mapping有点类似与RDB中“表结构”的概念,在MySQL中,表结构里包含了字段名称,字段的类型还有索引信息等。在Mapping里也包含了一些属性,比如字段名称、类型、字段使用的分词器、是否评分、是否创建索引等属性,并且在ES中一个字段可以有对个类型。分词器、评分等概念在后面的课程讲解。
2.2 ES数据类型
2.2.1 常见类型
- **数字类型:**long integer short byte double float half_float scaled_float unsigned_long
- Keywords:
- dates(时间类型):包括
date和date_nanos. - alias:为现有字段定义别名。
- text:当一个字段是要被全文搜索的,比如Email内容、产品描述,这些字段应该使用text类型。设置text类型以后,字段内容会被分析,在生成倒排索 引以前,字符串会被分析器分成一个一个词项。text类型的字段不用于排序,很少用于聚合。(解释一下为啥不会为text创建正排索引:大量堆空间,尤其是 在加载高基数text字段时。字段数据一旦加载到堆中,就在该段的生命周期内保持在那里。同样,加载字段数据是一个昂贵的过程,可能导致用户遇到延迟问 题。这就是默认情况下禁用字段数据的原因)
2.2.2 对象关系类型
- object:用于单个JSON对象
- nested:用于JSON对象数组
- join:为同一索引中的文档定义父/子关系。
2.2.3 结构化类型
- geo-point:纬度/经度积分
- geo-shape:用于多边形等复杂形状
- point:笛卡尔坐标点
- shape:笛卡尔任意几何图形
2.3 自动映射和手工映射
2.3.1 Dynamic field mapping:
-
整数 => long
-
浮点数 => float
-
true || false => boolean
-
日期 => date
-
数组 => 取决于数组中的第一个有效值
-
对象 => object
-
字符串 => 如果不是数字和日期类型,那会被映射为text和keyword两个类型
除了上述字段类型之外,其他类型都必须显示映射,也就是必须手工指定,因为其他类型ES无法自动识别。
2.3.2 Expllcit field mapping:手动映射
PUT /product
{
"mappings": {
"properties": {
"field": {
"mapping_parameter": "parameter_value"
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2.4 映射参数
- index:是否对创建对当前字段创建倒排索引,默认true,如果不创建索引,该字段不会通过索引被搜索到,但是仍然会在source元数据中展示
- analyzer:指定分析器(character filter、tokenizer、Token filters)。
- boost:对当前字段相关度的评分权重,默认1
- coerce:是否允许强制类型转换 true “1”=> 1 false “1”=< 1
- copy_to:该参数允许将多个字段的值复制到组字段中,然后可以将其作为单个字段进行查询
- doc_values:为了提升排序和聚合效率,默认true,如果确定不需要对字段进行排序或聚合,也不需要通过脚本访问字段值,则可以禁用doc值以节省磁盘 空间(不支持text和annotated_text)
- dynamic:控制是否可以动态添加新字段
- true 新检测到的字段将添加到映射中。(默认)
- false 新检测到的字段将被忽略。这些字段将不会被索引,因此将无法搜索,但仍会出现在_source返回的匹配项中。这些字段不会添加到映射中,必须显式 添加新字段。
- strict 如果检测到新字段,则会引发异常并拒绝文档。必须将新字段显式添加到映射中
- eager_global_ordinals:用于聚合的字段上,优化聚合性能。
- Frozen indices(冻结索引):有些索引使用率很高,会被保存在内存中,有些使用率特别低,宁愿在使用的时候重新创建,在使用完毕后丢弃数据,Frozen indices的数据命中频率小,不适用于高搜索负载,数据不会被保存在内存中,堆空间占用比普通索引少得多,Frozen indices是只读的,请求可能是秒级或者分钟级。*eager_global_ordinals不适用于Frozen indices
- enable:是否创建倒排索引,可以对字段操作,也可以对索引操作,如果不创建索引,让然可以检索并在_source元数据中展示,谨慎使用,该状态无法修改。fielddata:查询时内存数据结构,在首次用当前字段聚合、排序或者在脚本中使用时,需要字段为fielddata数据结构,并且创建倒排索引保存到堆中
PUT my_index { "mappings": { "enabled": false } }- 1
- 2
- 3
- 4
- 5
- 6
- **fields:给field创建多字段,用于不同目的(全文检索或者聚合分析排序)
- format:格式化
"date": { "type": "date", "format": "yyyy-MM-dd" }- 1
- 2
- 3
- 4
- ignore_above:超过长度将被忽略
- ignore_malformed:忽略类型错误
- index_options:控制将哪些信息添加到反向索引中以进行搜索和突出显示。仅用于text字段
- Index_phrases:提升exact_value查询速度,但是要消耗更多磁盘空间
- Index_prefixes:前缀搜索
- min_chars:前缀最小长度,>0,默认2(包含)
- max_chars:前缀最大长度,<20,默认5(包含)
- meta:附加元数据
- normalizer:
- norms:是否禁用评分(在filter和聚合字段上应该禁用)。
- null_value:为null值设置默认值**
- position_increment_gap:
- proterties:除了mapping还可用于object的属性设置
- search_analyzer:设置单独的查询时分析器:
- similarity:为字段设置相关度算法,支持BM25、claassic(TF-IDF)、boolean
- store:设置字段是否仅查询
- term_vector:**运维参数
Question 3:什么是全文检索(面试简化版)
什么是全文检索
3.1 相关度
- 搜索:有明确的查询边界,比如:where name = xxx、where age > 30
- 检索:讲究相关度,无明确的查询条件边界
3.2 图解全文检索
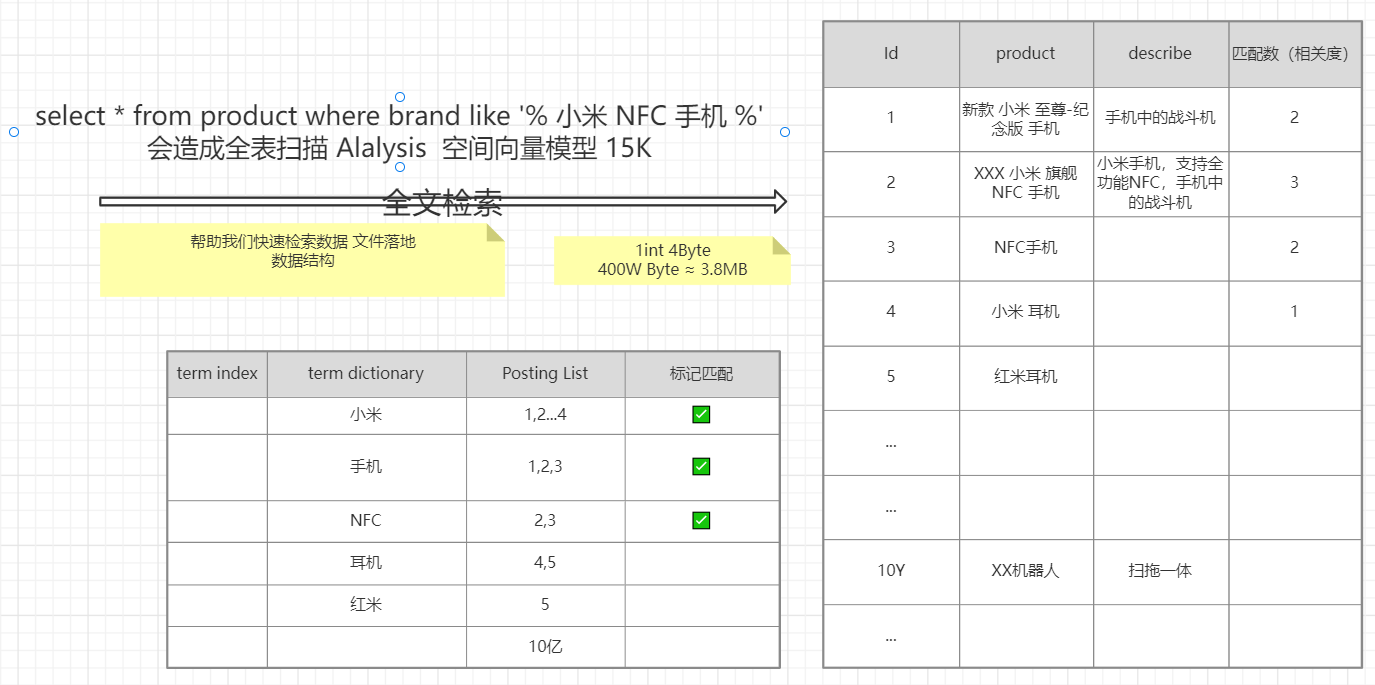
GET index/_search
{
"query": {
***
}
}
- 1
- 2
- 3
- 4
- 5
- 6
Question 4:ES支持哪些类型的查询
ES支持哪些类型的查询
此题目答案不唯一,按照不同的分类方式,答案也不一样
4.1 按语言划分
-
Query DSL:Domain Specific Language
-
Script:脚本查询
-
Aggregations:聚合查询
-
SQL查询
-
EQL查询
4.2 按场景划分
4.2.1 Query String
-
查询所有:
GET /product/_search- 1
-
带参数:
GET /product/_search?q=name:xiaomi- 1
-
分页:
GET /product/_search?from=0&size=2&sort=price:asc- 1
-
精准匹配 exact value
GET /product/_search?q=date:2021-06-01- 1
-
_all搜索 相当于在所有有索引的字段中检索
GET /product/_search?q=2021-06-01- 1
验证_all搜索
PUT product { "mappings": { "properties": { "desc": { "type": "text", "index": false } } } } # 先初始化数据 POST /product/_update/5 { "doc": { "desc": "erji zhong de kendeji 2021-06-01" } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
4.2.2 全文检索-Fulltext query
```
GET index/_search
{
"query": {
***
}
}
```
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4.2.3 精准查询-Term query
-
term:匹配和搜索词项完全相等的结果
- term和match_phrase区别:
match_phrase 会将检索关键词分词, match_phrase的分词结果必须在被检索字段的分词中都包含,而且顺序必须相同,而且默认必须都是连续的
term搜索不会将搜索词分词 - term和keyword区别
term是对于搜索词不分词,
keyword是字段类型,是对于source data中的字段值不分词
- term和match_phrase区别:
-
terms:匹配和搜索词项列表中任意项匹配的结果
-
range:范围查找
4.2.4 过滤器-Filter
GET _search
{
"query": {
"constant_score": {
"filter": {
"term": {
"status": "active"
}
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
filter:query和filter的主要区别在: filter是结果导向的而query是过程导向。query倾向于“当前文档和查询的语句的相关度”而filter倾向于“当前文档和查询的条件是不是相符”。即在查询过程中,query是要对查询的每个结果计算相关性得分的,而filter不会。另外filter有相应的缓存机制,可以提高查询效率。
4.2.5 组合查询-Bool query
bool:可以组合多个查询条件,bool查询也是采用more_matches_is_better的机制,因此满足must和should子句的文档将会合并起来计算分值
- must:必须满足子句(查询)必须出现在匹配的文档中,并将有助于得分。
- filter:过滤器 不计算相关度分数,cache☆子句(查询)必须出现在匹配的文档中。但是不像 must查询的分数将被忽略。Filter子句在filter上下文中执行,这意味着计分被忽略,并且子句被考虑用于缓存。
- should:可能满足 or子句(查询)应出现在匹配的文档中。
- must_not:必须不满足 不计算相关度分数 not子句(查询)不得出现在匹配的文档中。子句在过滤器上下文中执行,这意味着计分被忽略,并且子句被视为用于缓存。由于忽略计分,0因此将返回所有文档的分数。
minimum_should_match:参数指定should返回的文档必须匹配的子句的数量或百分比。如果bool查询包含至少一个should子句,而没有must或 filter子句,则默认值为1。否则,默认值为0
4.2.6 地理位置搜索
4.2.7 复杂类型查询
-
Object
-
Nested
-
Join
4.3 按数据类型(准确度)划分
-
全文检索:match
-
精确查找:term
-
模糊查询:suggester、模糊查询、通配符、正则查找
Question 5:term、match、keyword的有何区别,你还知道哪些检索类型
term和match的区别
5.1 term和match
term:对搜索词不分词,不影响源数据
match:对搜索词分词,不影响源数据
5.2 term和keyword
term:检索类型
keyword:字段类型
Question 6:为什么MySQL(B+Trees)不适合做全文检索?
MySQL(B+Trees)为什么不适合做全文检索
6.1 什么是索引
6.2 数据库的组成
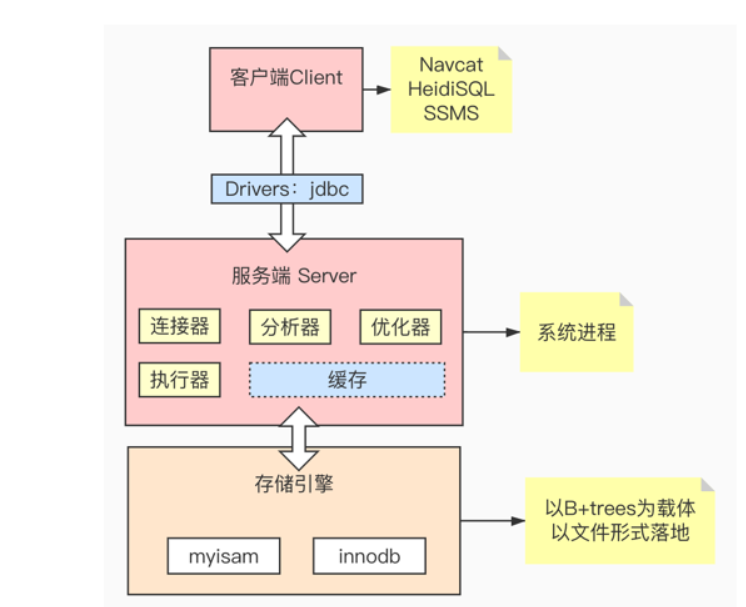
6.3 B-Trees的数据结构
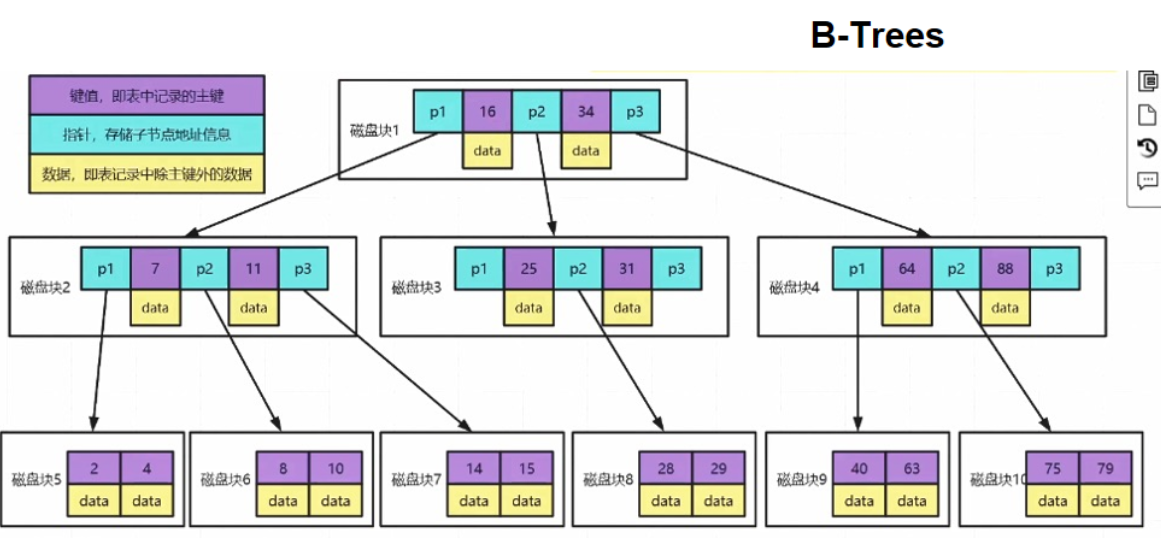
6.4 B+Trees的数据结构
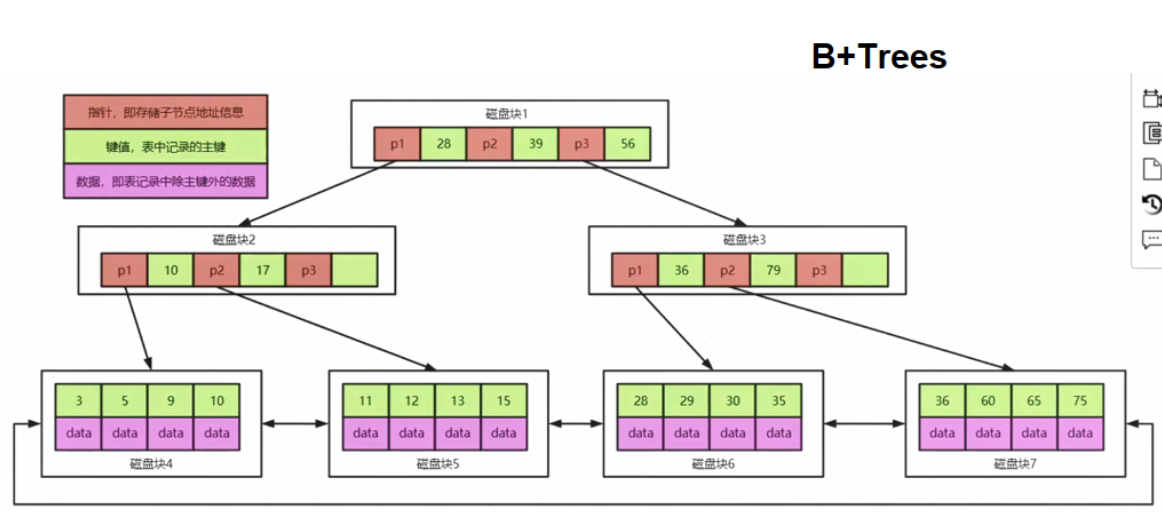
6.5 B+Trees做全文检索的弊端
- 索引往往字段很长,如果使用B+trees,树可能很深,IO很可怕
- 性能无法保证并且索引会失效
- 精准度差(相关度低),并且无法和其他属性产生相关性
Question 7:倒排索引的基本原理(面试简化版)
倒排索引基本原理
7.1 概念
倒排索引:“关键词”=> “文档ID”,即关键词到文档id的映射。
7.2 倒排索引的基本数据结构
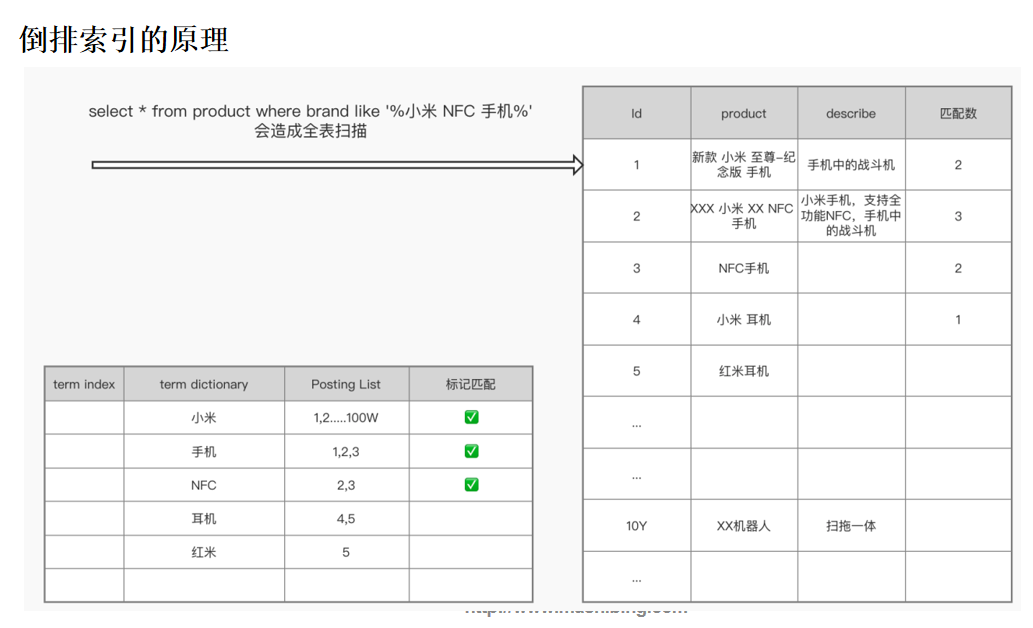
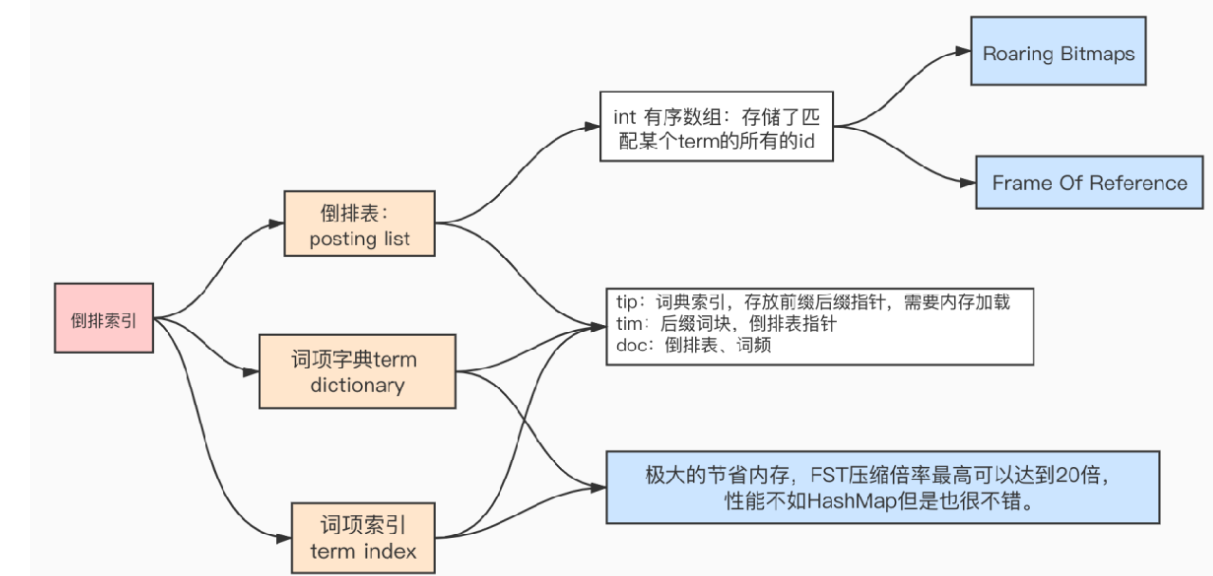
Question 8:倒排表的压缩算法-1:FOR
倒排表的压缩算法:FOR
搜索引擎级别的数据量级通常通常在亿级甚至十亿级上,那么也就说如果我们对其建立倒排索引,每个字段被拆分成了若干Term,结果就有可能导致倒排索引的数据量甚至超过了source data,即便我们对倒排索引的检索不必全表扫描,但是太多的数据不管是存储成本还是查询性能可能都不是我们想要的,解决办法就是采用高效的压缩算法和快速的编码和解码算法。
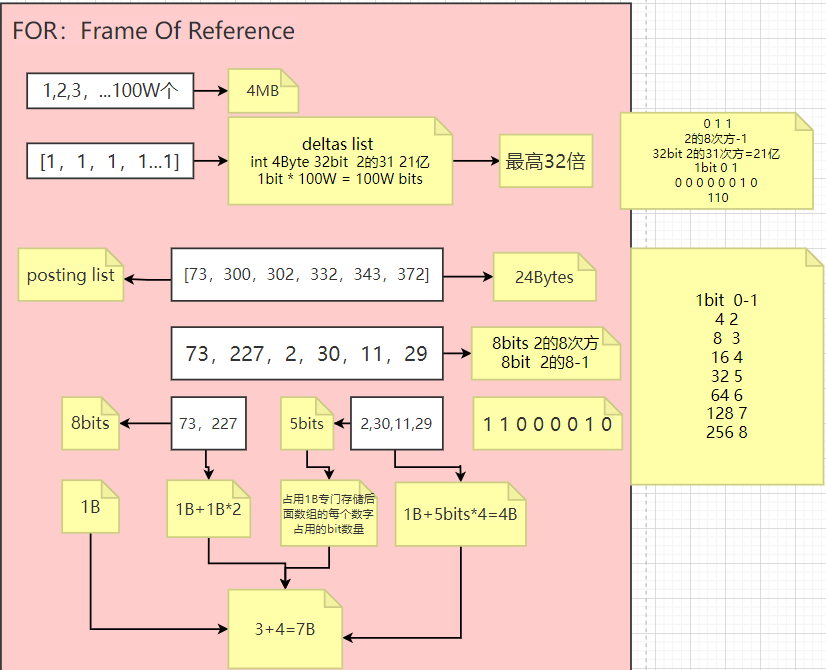
Question 9:倒排表的压缩算法-2:RBM
倒排表的压缩算法:RBM
其实上述例子中的数组仍然具有一定的特殊性。因为它是一个稠密数组,可以理解为是一个取值区间波动不大的数组。如果倒排表中出现这样的情况:[1000W, 2001W, 3003W, 5248W, 9548W, 10212W, … , 21Y],情况将会特别糟糕,因为我们如果还按照FOR的压缩算法对这个数组进行压缩,我们对其计算dealta list,可以发现其每个项与前一个数字的差值仍然是一个很大的数值,也就意味着dealta list的每个元素仍然是需要很多bit来存储的。于是Lucene对于这种稀疏数组采用了另一种压缩算法:RBM(Roaring Bitmaps)
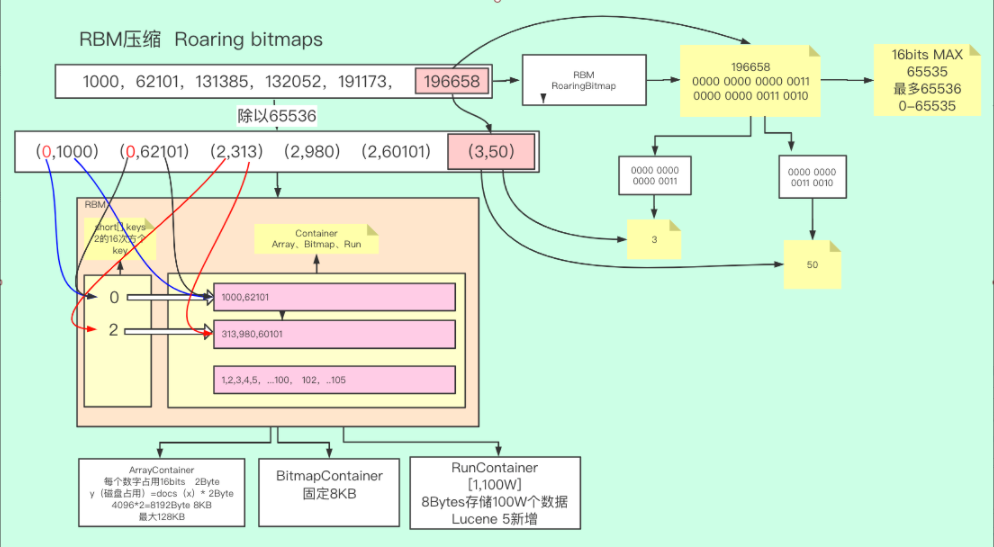
这是一个典型的稀疏型数组。在进行数据压缩的时候,其实不管何种方法,我们的最终目的都是把原来的数字转换成足够小的数字以便于我们存储,同时又必须保证压缩后的数据是可以快速解码的。“减法”不好用,这次我们尝试使用“除法”。由于无符号int类型的最大值不超过2 32 ,因此RBM的策略就是把一个int型拆成两个short型的乘机,具体做法是把数组中的每个元素对216取模,因为被除数是232除数是2 16 ,因此商和余数均小于2 16 。其实这种想法是国内开发者强行转化的逻辑,RBM算法本身的设计思路是将原数字的的32个bit分为了高16位和低16位。以原数组中的196658这个id为例,将其转化为二进制结果为 110000000000110010,我们看到其实结果是不足32bits的,但因为每个int型都是有32个bit组成的,不足32bit会在其前面补0,实际其占用的空间大小仍然为32bits,如果这一点不理解,打个比方,公交车有32个座位,无论是否坐满,都是使用了32个座位。最终196658转换成二进制就是0000 0000 0000 0011 0000 0000 0011 0010,前16位就是高16位,转换成十进制就是3,后16位也就是低16位,转换成十进制就是50,3和50分别正好是196658除以63326(2 16 )的得数和余数,换句话说,int类型的高16位和低16位分别就是其本身对216的商和模。
对数组中每个数字进行相同的操作,会得到以下结果:(0,1000)(0,62101)(2,313)(2,980)(2,60101)(3,50),其含义就是每个数字都由一个很大的数字变为了两个很小的数字,并且这两个数字都不超过65536,更重要的是,当前结果是非常适合压缩的,因为不难看出,出现了很多重复的数字,比如前两个数字的得数都是0,以及第2、3、4个数字的得数都是2。RBM使用了非常适合存储当前结果的数据结构。这种数据结构是一种类似于哈希的结构,只不过Key值是一个short有序不重复数组,用于保存每个商值,value是一个容器,保存了当前Key值对应的所有模,这些模式不重复的,因为同一个商值的余数是不会重复的。这里的容器官方称之为Container,RBM中包含三种Container,分别是ArrayContainer、BitmapContainer和RunContainer。
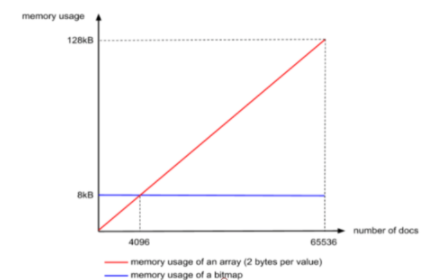
首先ArrayContainer,顾名思义,Container中实际就是一个short类型的数组,其空间占用的曲线如下图中的红色线段,注意这里是线段,因为docs的数量最大不会超过65536,其函数为 y(空间占用)=x(docs 长度) x 2Bytes,当长度达到65536极限值的时候,其占用的大小就是16bit * 65536 / 8 /1024 = 128KB,乘以65536是总bit数,除以8是换算成Byte,除以1024是换算成KB。
第二种是BitmapContainer,理解BitmapContainer之前首先要了解什么是bitmap。以往最常见的数据存储方式都是二进制进位存储,比如我们使用8个bit存储数字,如果存十进制0,那二进制就是 0 0 0 0 0 0 0 0,如果存十进制1,那就是 0 0 0 0 0 0 0 1,如果存十进制2,那就是 0 0 0 0 0 0 1 1,用到了第二个bit。这种做法在当前场景下存储效率显然不高,如果我们现在不用bit来存储数据,而是用来作为“标记”,即标记当前bit位置商是否存储了数字,出的数字值就是bit的下标,如图所示,就表示存储了2、3、5、7四个数字,第一行数字的bit仅代表当前index位置上是否存储了数字,如果存储了就记作1,否则记为0,存储的数字值就是其index,并且存储这四个数字只使用了一个字节。

不过这种存储方式的问题就是,存储的数字不能包含重复数字,并且Bitmap的大小是固定的,不管是否存储了数值,不管存储了几个值,占用的空间都是恒定的,只和bit的长度有关系。但是我们刚才已经说过,同一个Container中的数字是不会重复的,因此这种数据类型正好适合用这种数据结构作为载体,而因为我们Container的最大容量是65536,因此Bitmap的长度固定为65536,也就是65536个bit,换算成千字节就是8KB,如上面图中的蓝色线段所示,即Lucene的RBM中BitmapContainer固定占用8KB大小的空间,通过对比可以发现,当doc的数量小于4096的时候,使用ArrayContainer更加节省空间,当doc数量大于4096的时候,使用BitmapContainer更加节省空间。
第三种Container叫RunContainer,这种类型是Lucene 5之后新增的类型,主要应用在连续数字的存储商,比如倒排表中存储的数组为 [1,2,3…100W] 这样的连续数组,如果使用RunContainer,只需存储开头和结尾两个数字:1和100W,即占用8个字节。这种存储方式的优缺点都很明显,它严重收到数字连续性的影响,连续的数字越多,它存储的效率就越高。
Question 10:什么是字典树
字典树的存储和遍历过程
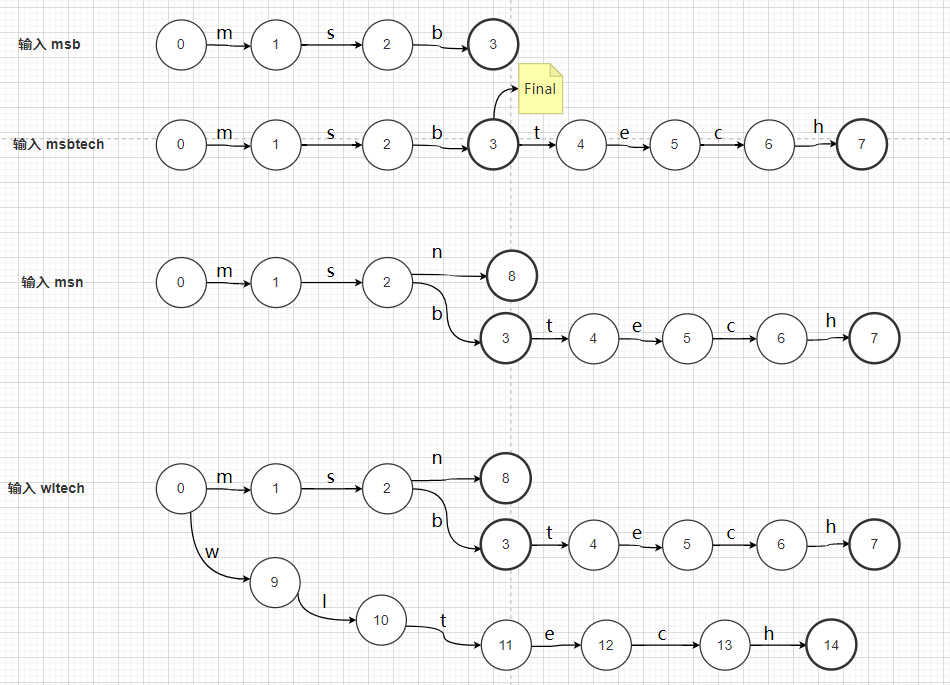
Term Dictionary是字典序非重复的K-V结构的,而通常搜索引擎级别的倒排索引,Term Dictionary动辄以“亿”起步,这势必要求我们在做数据存储时对其数据结构有极其高的要求。假设下图中英汉词典片段就是我们要存储的词项字典,遵循“通用最小化算法”对其进行数据压缩,我们就必须要考虑如何以最小的代价换区最高的效率。通过观察不难发现,无论任何一个Term,无外乎由26个英文字母组成,这也就意味越多的词项就会造成的越多的数据“重复”。这里所说的重复指的是词项之间会有很多个公共部分,如“abandon”和“abandonment”就共享了公共前缀“abandont”。我们是否可以像Java开发过程中对代码的封装那样,重复利用这一部分公共内容呢?答案是肯定的!Lucene在存储这种有重复字符的数据的时候,只会存储一次,也就是哪怕有一亿个以abandon为前缀的词项,“abandom”这个前缀也只会存储一次。这里就用到了一种我们经常用到的一种数据结构:Trie即字典树,也叫前缀树(Prefix Tree)。

下面我们以Term Dictionary:(msb、msbtech、msn、wltech)为例,演示一下Trie是如何存储Term Dictionary的。
更多精彩讲解,后续更新
关注博主,获得第一手更新!

