
- 1Stable Diffusion 安装教程_stable diffusion·中 python安装在哪里
- 2Stable Diffusion 模型分享:Inkpunk Diffusion(动漫、墨水朋克)
- 3【git】TortoiseGit图标不显示 及 文件夹中.git文件夹不显示_tortoisegit文件夹没有图标
- 4Github 上传、下载过慢的解决方案_githubdesktop上传慢
- 5探秘DataV:可视化神器,数据洞察新体验
- 6# 我实践:搭建轻量git服务器的两个方案
- 7Python 使用轻量级 Flask 框架搭建 Web 服务器详细教程(基础篇)_flask搭建web服务器
- 8ELK日志采集系统搭建
- 9科研难点:三线表的制作与调整
- 10信息系统项目管理师证书有什么用?_信息系统管理工程中级有什么用
AIGC音视频工具分析和未来创新机会思考_aigc 音视频行业的竞争分析
赞
踩
-01- 发生了什么
首先,2023年发生了什么事?
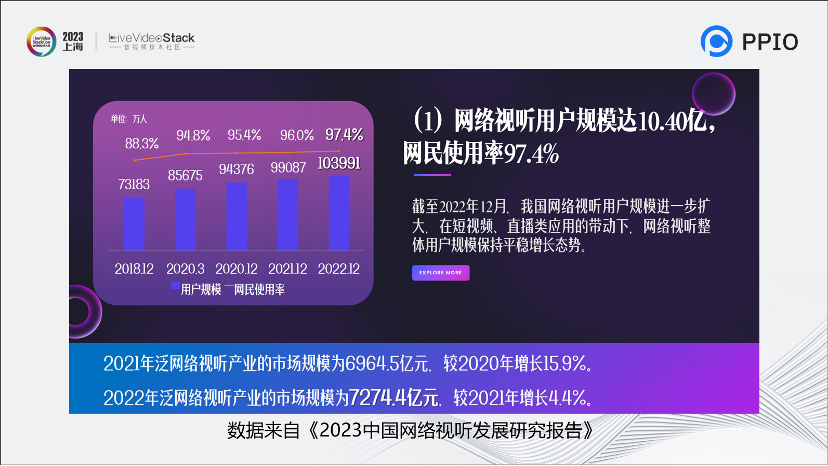
这张图摘自《2023中国网络视听发展研究报告》。可以明显看到,整个音视频行业的使用量已经达到了增长缓慢的极限。比起22年底,21年底用户人数只增加了一个百分点。22年产业的市场规模的增长速度也只有4.4个百分点。整个音视频行业遇到了瓶颈,开始进入一个很缓慢的时代。
这是我们音视频行业的从业者面临着“卷”的根源,大家都在相互竞争。我们怎么样创新才能从这种“卷”中出来?
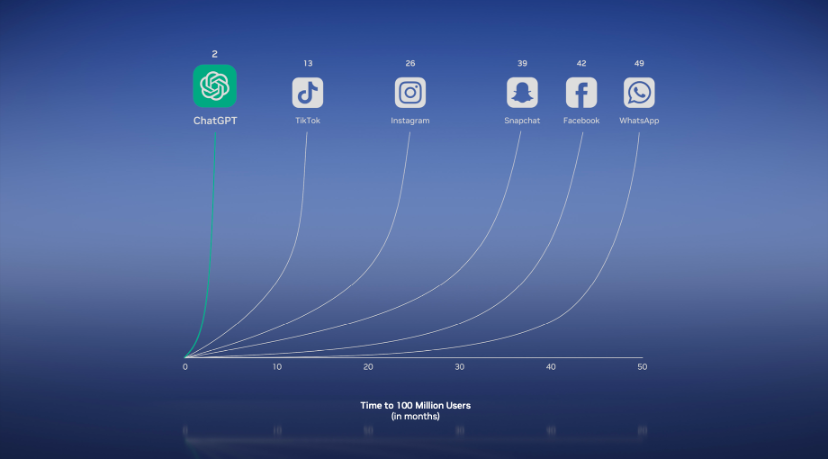
过去一年,世界发生了什么?请看下图,这是ChatGPT,它达到一个亿的用户只用了两天的时间,超过了历史上所有的APP,甚至包括Tiktok,Instagram,Snapchat,Facebook等。
再看下图,Stable Diffusion成为历史上增速最快的项目。和它对标的项目是比特币、以太坊、kafka、spark等知名项目。而且,Stable Diffusion基本上是垂直的线,一天时间就达到了几万关注。
这就是这次的十倍变化要素,AI的魅力。
这里回溯一下AI的发展过程:①在20世纪50年代,就有了基于规则的少量数据处理;后来80年代,基于统计学发展出了机器学习;②21世纪后,伴随显卡的性能提升,神经网络,深度学习逐步得到应用;③特别是2014-2017年,神经网络得到一系列的发展,包括CNN卷积神经网络RNN、循环神经网络、VAE、GAN生成对抗网络等,AI在很多领域有了落地的应用。④直到2017年,Transfarmer的伟大发明,带领我们进入了今天大语言模型的时代。⑤后来在2020年,Diffusion的发明,非常惊艳的生成图片效果,点燃了AIGC绘画的的浪潮。
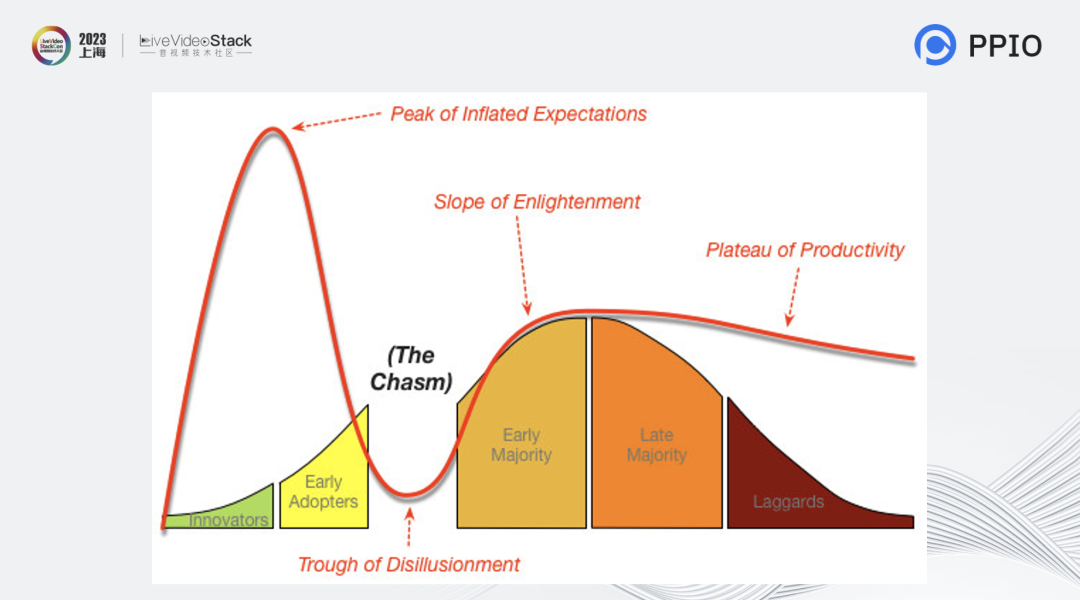
那么视频在什么时代呢?我的看法是视频可能离走过这个鸿沟还有一定距离,这是在我分析过国外的APP后得出的想法。
接下来我给大家分享4款AIGC的应用。
-02- 音视频应用AIGC在萌芽
第一款应用是D-ID,它的核心是实现面部的动画。

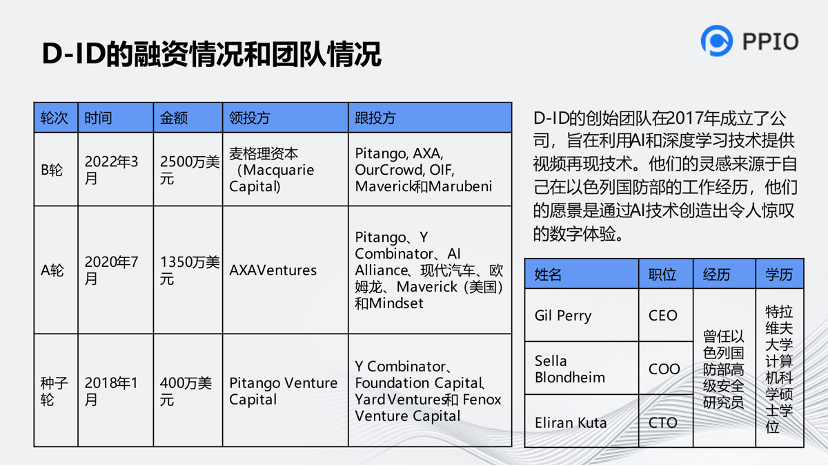
这是对他们公司做的分析,包括融资和创始人的经历。国外音视频的创业者并不都是名校毕业生。中国人只要再努力一下,是很容易超越国外的产品的。
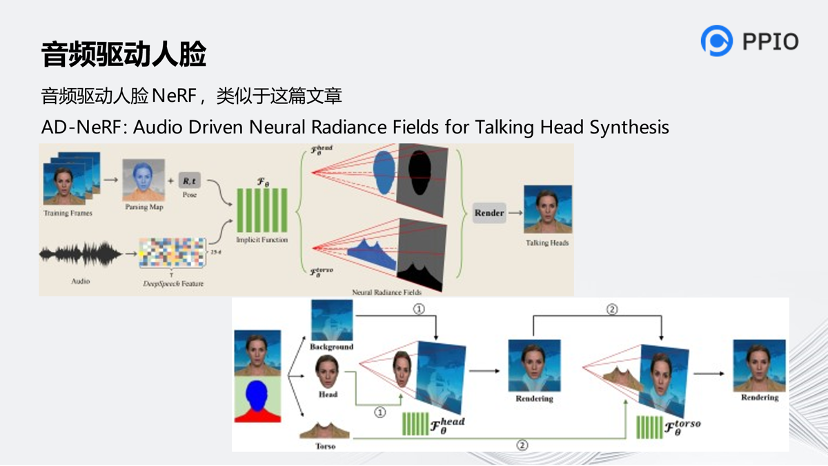
关于技术的实现,在他们CEO的一篇演讲中有提到如何将声音和嘴型进行对齐的内容,还提到了一种音频驱动人脸的全神经辐射的技术。
它的本质是把一个图像从2D生成3D的建模过程,但是文章中没有提到具体是怎么做的,我们根据AD-NeRF进行相关的假设。
AD-NeRF这篇资料讲述了音频驱动人脸的技术原理。AD-NeRF是一种由语音信号直接生成说话人视频的算法,仅需要目标人物几分钟的说话视频,该方法即可实现对该人物超级逼真的形象复刻和语音驱动。首先利用人脸解析方法将整个训练画面分为三部分,分别是背景、头部和躯干。其次,通过头部的前景和背景的后景去训练头部部分模型。然后,通过头部部分隐函数生产的图像和背景作为后景,再把躯干作为前景,去训练躯干部分的模型。
同时,声音部分也作为AD-NeRF模型的一个新的特征输入,通过DeepSpeech的方法,将声音转化成29维的特征数据,输入到AD-NeRF模型当中。
在生成图像的时候,通过对头部模型和躯干模型输入相同的特征,其中包括音频特征和姿态特征,来完成AD-NeRF模型的推理。在最终立体渲染图像的过程当中,首先采用头部模型积累像素的采样密度和RGB值,把渲染好的头部图像贴到静态背景上,然后躯干模型通过预测躯干区域的前景像素来填充缺失的躯干部分。通过以上的方法,AD-NeRF实现了音频驱动人脸当中头部与上身运动一致,并让产生动作与表情非常自然。
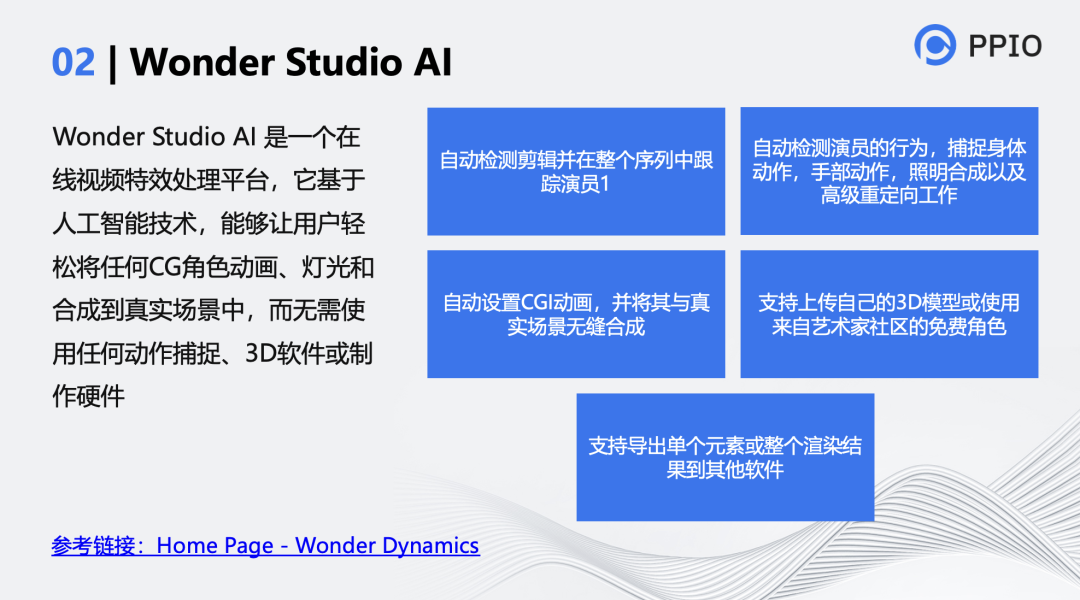
第二个分享的是Wonder Studio AI。它的两位创始人不是计算机工程师,一个是艺术家,一个是《头号玩家》的演员。它是在电影中或视频中,把一个真实的人换成另一个真实的人或数字人。

这个项目的融资不多,但做的东西非常惊艳。两位创始人都是电影制片人,还有一些顾问共同实现这个体系。有两篇文章提到他们项目的实现方法,一篇是他们的官方文章,另一篇是国内一位博主对他们进行的分析。
要做到视频内CG角色的实时替换,首先利用Opnepose等人体姿态估计算法对人物的3D姿态进行捕捉,并将其与建模好的CG模型进行绑定。其次,由于选定人物与CG模型在视频中所占的空间环境不同,因此需要对选定人物的轮廓进行精准识别,并经过一定的处理让选定人物仿佛在原视频中没有出现过一般,这里需要采用人物擦除算法。

目前,由清华团队提出的Inpaint Anything能够轻松实现这一需求。该算法基于Meta开源语义分割算法Segment Anything Model(SAM)对目标人物轮廓进行精准识别,生成Mask,再利用图像生成算法LaMa或stable Diffusion能够实现对Mask的图像内容进行自定义填充。

但Wonder Studio官方没有提到他们的方案具体是怎么实现的,以上是我就这个技术本身做的想法。

第三个工具是AIGC的官方应用,叫做Runway,它的定位是新一代的艺术,也是一个2c的产品。它提供了一个平台,可以对视频进行风格编辑,还有一系列的工具。它分为两代:Gen1和Gen2。Gen1只能视频转化成视频,视频加上文字最后转化为视频。

这家公司的融资背景非常深厚,在过去几年紧跟AIGC的浪潮及爆发性场景的应用。值得注意的是,它的三位创始人员都是艺术家。而我们国内创业或公司创新的人都是工程师或者学术方面的人员。这家公司都是艺术家创业,可见他们更注重做出来的东西的感受。这也体现了东西方文化上的差异。
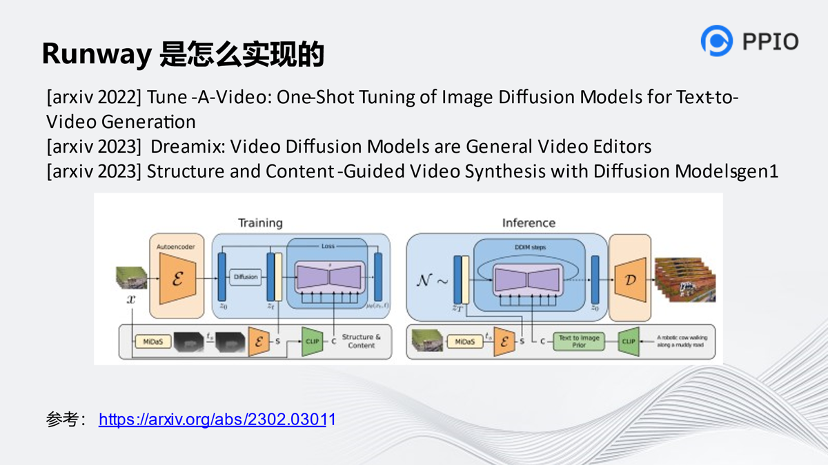
已有的研究中表明CLIP的图像embedding对图像内容在图像中的位置和形态不敏感,而更关注内容本身,因此它是与深度这一结构信息较为“正交”的,使得Gen-1可以将图像解耦为彼此干扰较小的结构信息和内容信息。
Gen-1和Stable Diffusion路径很像,把中间的竖线去掉,基本上就是Stable Diffusion的架构。它把一个原始的视频形成画面,图像的深度图作为结构信息、CLIP编码器的图像embedding作为内容信息,在隐空间进行扩散模型的训练。生成的时候也是把输入的文本通过CLIP方式转化回去,最后再进行干预,就能呈现视频的结果。不同的是,它还运用了图片的模式转化,即MiDaS,把图片生成一个框架,再干预这个环节。大概的技术原理是用文本干预视频的过程,从而得出最后的效果。
https://arxiv.org/abs/2302.03011这篇论文是他们的官方论文。这个应用思路其实比较简单,如果大家要做也不会很困难。
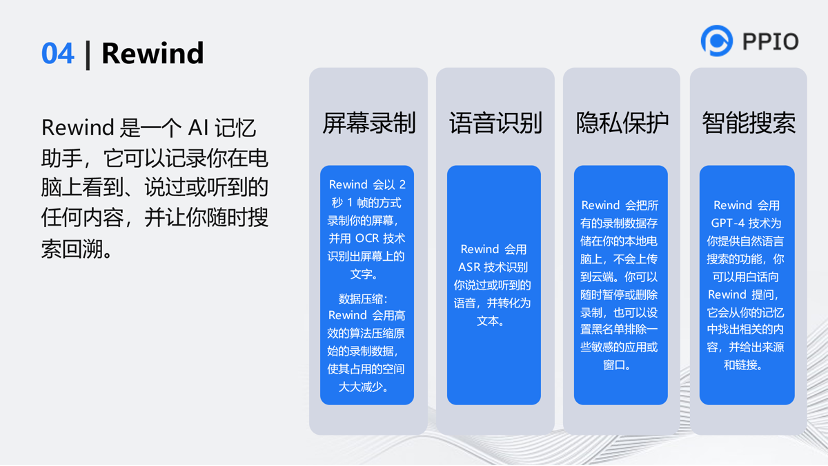
第四个工具是Rewind。这个工具特别厉害,很遗憾的是它只能在苹果电脑上使用。它把大家日常工作的内容全部录下来,整理后再通过GTP进行对接。这个工具严格来说不是完整的视频应用,但它是个类视频应用,我是它的重度用户。可以通过回拉里面的进度条得知自己今天做的任何事,里面的文本也是可以摘出来的。
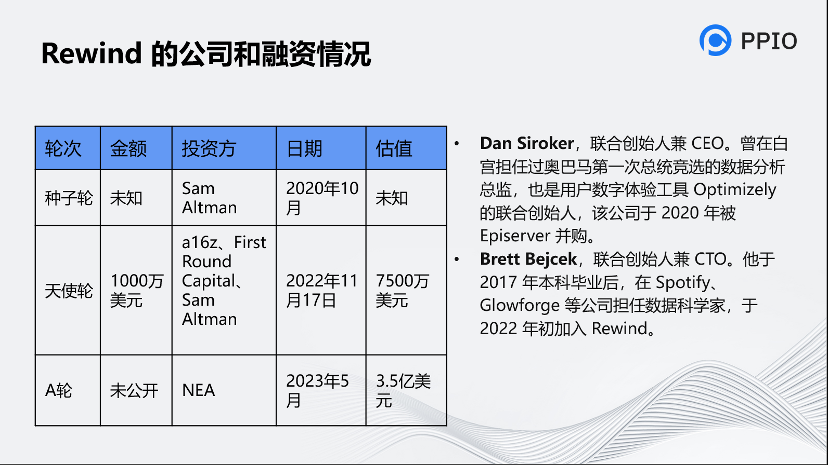
这个公司很有意思,Altman投了2轮,种子轮和天使轮,另外还拿到了很多知名的投资。
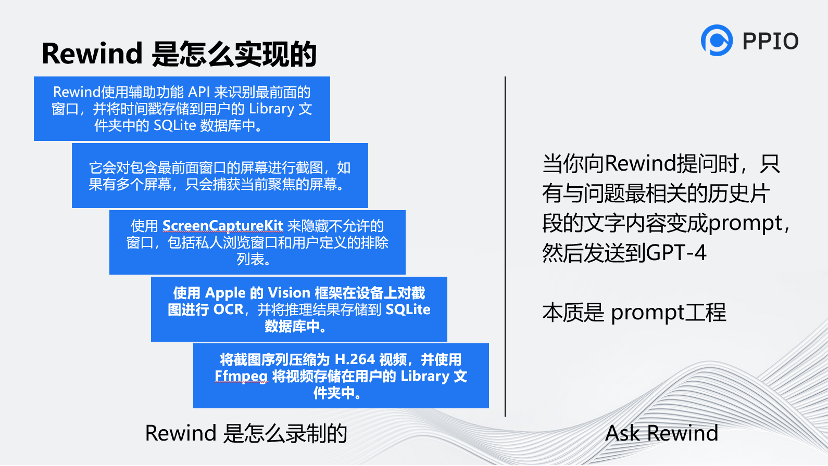
这个工具很有创意,它和音视频技术关系不大。核心点是调用了苹果的M1和M2芯片的接口,对显示的内容做OCR,再把OCR后的内容用文本方式存起来,
另外,官方宣称它用了H.264技术进行压缩,来同时把视频录制了下来。(但是这里我是持怀疑的,能把视频大小压缩到70倍,但我觉得H.264的技术还有些挑战)
最后,再把OCR的文本通过向量工程的方式和Chatgpt对接,从而具备了智能能力。当你问它(Rewind)你做了什么,它通过向量工程向Chatgpt调API来完成这一过程,所以它基本可以帮你总结出你每天都做了什么,你之前遇到了什么问题。它能够对你的日常工作进行归类,这是我用这个工具的原因。
其实AIGC视频工具还有很多,我这里讲的4个是比较典型的使用场景。
-03- 视频生成研究最新趋势
另外谈谈我对视频生成技术的学习和研究。
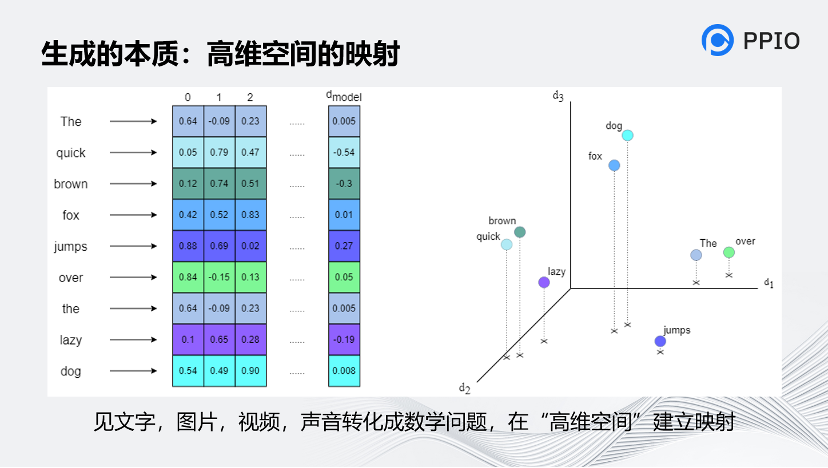
生成的本质是什么?我认为生成的本质是高维空间建立映射,不论是文字、图片,还是视频、音频,最终都会转化为数学问题,并在高维空间中建立起映射。而人脑正是因为能够建立起这种高维的映射,才能形成一定的智能。
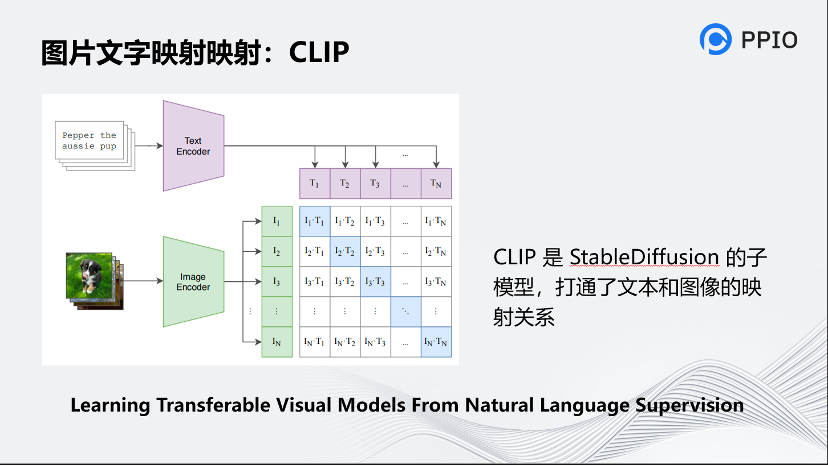
前面也提到的,CLIP是非常关键的技术,是StableDiffusion的子模型,打通了文本和图像的映射关系。CLIP的原理是对文本和图片分别通过Text Encoder和Image Encoder输出对应的特征,然后在这些输出的文字特征和图片特征上进行对比学习,再将它进行映射。
为了训练CLIP,OpenAI从互联网收集了共4个亿的文本-图像对,论文称之为WIT(Web Image Text)。WIT质量很高,而且清理得非常好,其规模相当于JFT-300M,这也是CLIP如此强大的原因之一。

这是谷歌的一篇论文,讲的是视频的Diffusion Model,它可以理解为是StabDiffusion的变种,它在StableDiffusion的每个过程中都引入了一个时间维度t,以实现时间注意力机制,使得它生成的画面之间有一定的联系。
为了使扩散模型适用于视频生成任务,这篇论文提出了3D UNet,该架构使用到了space-only 3D卷积和时空分离注意力。具体来说,该架构将原UNet中的2D卷积替换成了space-only 3D卷积(space-only 3D convolution)。随后的空间注意块仍然保留,但只针对空间维度进行注意力操作,也就是把时间维度flatten为batch维度。在每个空间注意块之后,新插入一个时间注意块(temporal attention block),该时间注意块在第一个维度即时间维度上执行注意力,并将空间维度flatten为batch维度。论文在每个时间注意力块中使用相对位置嵌入(relative position embeddings),以便让网络能够不依赖具体的视频帧时间也能够区分视频帧的顺序。这种先进行空间注意力,再进行时间注意力的方式,就是时空分离注意力。
这种时空分离注意力的UNet可以应用在可变序列长度上,这种时空分离注意力的方式有一个好处是可以对视频和图片生成进行联合建模训练。就是说可以在每个视频的最后一帧后面添加随机的多张图片,然后通过掩码的方式来将视频以及各图片进行隔离,从而让视频和图片生成能够联合训练起来。

但是这个机制其实比较弱,只能生成一些非常简单的画面。
近期有两篇论文值得一提,一个是Diffusion over Diffusion,这篇论文的定位是关于生成长视频的思考。Diffusion over Diffusion主要解决的问题是长视频之间前后关联的问题。之前的视频基本都是自回归的架构,生成得比较慢,因为它是串行的。
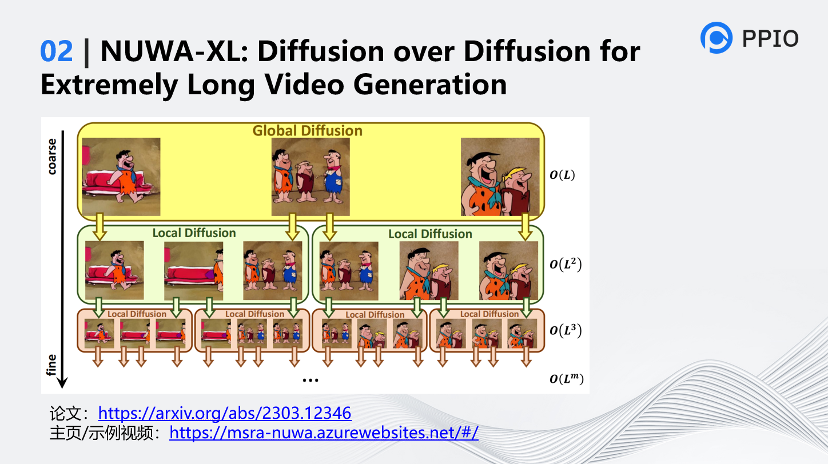
它的特点是什么?它为什么要Diffusion over Diffusion?因为它是一种分层结构的扩散模型,通过一层层扩散生成视频。
Diffusion over Diffusion的视频生成过程是一个“从粗到细”的视频生成过程,先通过在全局扩散模型(Global Diffusion)中输入文字来生成整个时间范围内的关键帧,然后在局部扩散模型(Local Diffusion)中输入文字和上一层Diffusion生成的两张图片,递归地生成填充附近帧之间的内容,最终生成长视频。
这种分层结构的设计使模型能够直接在长视频上进行训练,不仅消除了视频生成领域中训练短视频与推理长视频之间差距,也确保了视频情节的连续性,同时也能极大的提升了生成效率。
,时长11:15
通过官网的演示资料可以看到,它下面写的是一个prompt演讲,根据prompt生成一个稍微长一点的视频内容。在prompt换了之后,它又能生成一个稍微更长点的、更多样化的(内容)。这就是它的演示结果。
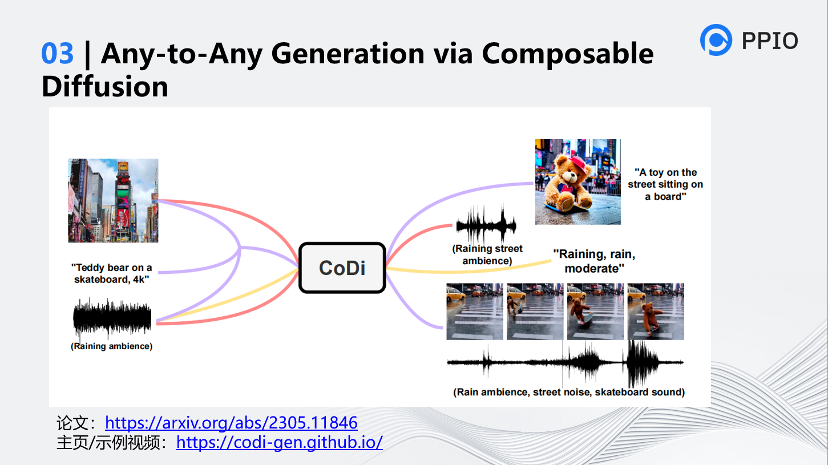
下面这篇论文的名字叫Any-to-Any,这是一篇综合图像、语音、视频和文本的多模态论文。其中Any to any的含义是,你能将上述模态数据进行任意组合的输入,得到任意组合的输出。例如输入的时候可以根据图片、文本、声音,最后生成一个带语音的视频。
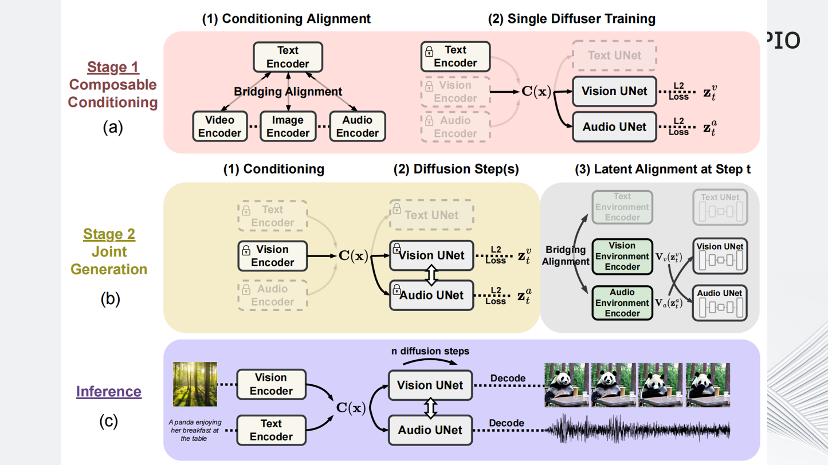
这篇论文提出了模型可组合扩散(Composable Diffusion,CoDi),这是第一个能够同时处理和生成任意组合模态的模型。它具体是怎么做的?
首先这篇论文为了对齐不同模态之间的特征,设计了Bridging Alignment(特征桥接对齐)方式,采用CLIP为基准,冻结CLIP文本编码器权重,再使用对比学习在文本-音频、文本-视频数据集上进行训练,使得音频、视频编码器提取的特征能对齐CLIP预训练模型中文本编码器提取的文本特征。
第二步,为每种模态(例如文本、图像、视频和音频)训练一个潜变扩散模型(Latent Diffusion Model,LDM)。这些模型可以独立并行训练,利用广泛可用的特定模态训练数据(即具有一个或多个模态作为输入和一个模态作为输出的数据)确保出色的单模态生成质量。
最后,通过为每个扩散器添加交叉注意力模块和一个环境编码器V来实现的,将不同LDM的潜变量投影到共享的潜空间。之后再固定LDM的参数,只训练交叉注意力参数和V。由于不同模态的环境编码器是对齐的,LDM可以通过插值表示的V与任何组合的共同生成模态进行交叉注意力。这使得CoDi能够无缝地生成任何模态组合,而无需对所有可能的生成组合进行训练。

官网的演示很震撼。例如这三个是带有声音的视频。

这三个分别是文本、图片、下雨的声音。这三个结合起来,就生成了一个泰迪熊在雨中过街的画面。网上有一些评论,说这篇论文真正运用的时候差距很大,因为多模态需要大量的数据支持才可能做好。它还是学术级,离跨越鸿沟还有很远的距离。
-04- 未来音视频创新机会在哪
我接下来的思考是,未来音视频AIGC成熟且能大规模应用在什么时候?

这个图摘自红杉的报告。红色部分属于很不成熟的,黄色部分属于正在发展的,绿色部分就是成熟的。在这个预测里可以看到,文本和code在2023年能够做到很成熟,但是图片可能要到25年才能做到非常可控、可产品化,3D和视频预测要到2030年才能成熟。
不管是应用还是论文,基本上都是基于Diffusion的改良,甚至很多模型都是基于Diffusion模型的一种扩散,今天的很多更高级的视频、3D的生成框架,也离不开扩散。如果某天视频真的要参与化的时候,是不是需要有一种更原生的底层逻辑的突破、比扩散还高一个维度的突破才能做到?但是今天我们基于已有的技术,加上一些工程化的努力,我相信应该可以做很多东西了。
关于音视频的应用,如果和行业数据相关,我认为用好开源,加上一些工程上的产品级创新,再结合大模型,把向量工程、提示工程做好,基本就能解决大量的需求了。
-05- 关于PPIO边缘云
最后介绍一下我们的PPIO边缘云。PPIO 于 2018年由 PPTV 创始人姚欣和王闻宇联合创立,作为中国领先的独立边缘云服务提供商,PPIO在全国30多个省,超过1000多个县市及区域,为客户提供符合低时延、高带宽、海量数据分布处理需求的边缘云计算服务和解决方案。
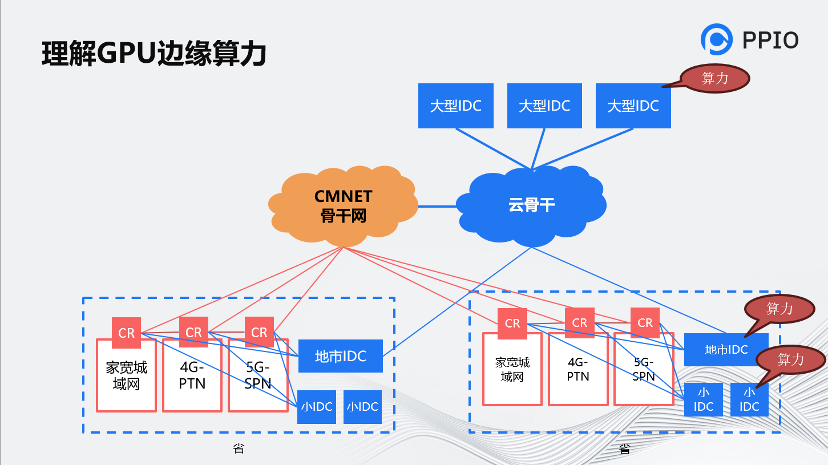
PPIO的核心是以算力为本。这个图是运营商的骨干图,能够帮助理解边缘带宽。图中拿移动来举例,我们覆盖的范围并不是很大很多,而是相对分散的一些节点,但是这种节点的SOA也是可保证的。
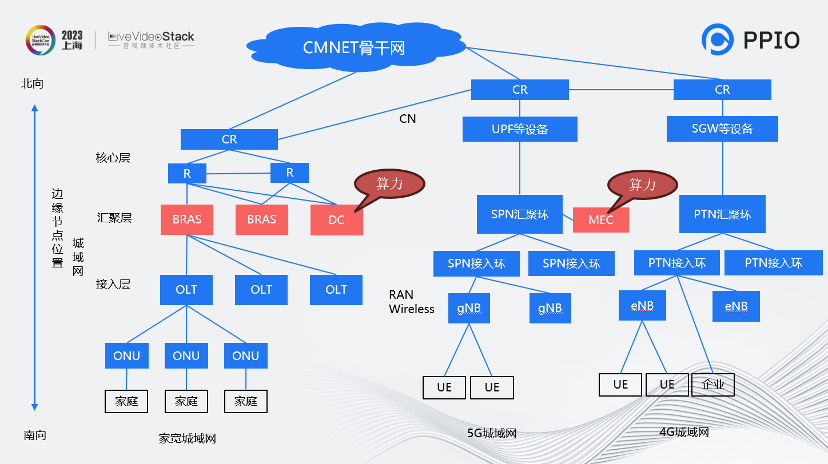
从城域网的角度看,备用节点覆盖在BRAS这一层,甚至会放置在MEC。
把算力资源放下后,就能做一些边缘的推理服务。我们可以提供基于裸金属和GPU容器的的服务,同时也能提供上面调度的逻辑。另外我们还可以支持推理加速的框架,例如Oneflow、AITemplate、TensorRT等。
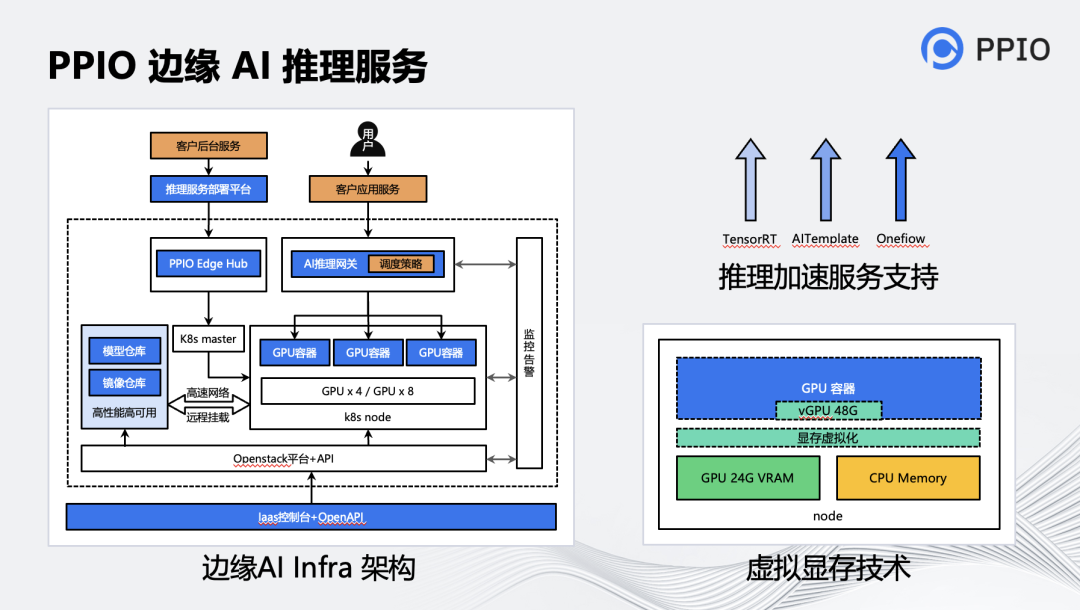
基于 PPIO 在边缘算力上的优势,我们构建了专门适用于 AI 推理场景的架构。它主要包含三个层面的服务:裸金属,容器,推理网关。
• 裸金属服务,主要适用于大模型的场景,例如:一个大语言模型的推理服务需要占用 4~10 张显卡,甚至要多机联合推理的情形。客户可以直接通过 IaaS 控制台或 OpenAPI 来申请、启动、停止和释放裸金属机。
• 容器服务,主要适用于可以灵活调度的场景,一般这类模型相对较小,一个推理服务实例只需要 1 张左右显卡,例如 StableDiffusion 的推理。容器服务实例由 PPIO k8s@Edge 系统管理,该系统保持与原生 k8s 兼容,可以满足客户按需弹性调度的需求。
• 推理网关服务,是上层用户请求层的智能调度服务,它可以根据后端推理实例的负载情况,动态地将用户的请求调度到最合适的实例上,并且它支持客户设置个性化的调度策略。另外当部分节点或实例故障时,该网关也可以智能地将其剔除,避免用户请求打到该实例上,对于已经调度到这些实例上的请求,网关将自动将这些请求重新转发到其他健康实例上去处理,整个过程对于请求方完全无感。
此外,在服务客户的过程中,我们发现有些时候显卡在接受较大的用户请求时,偶尔会出现显存不足的情况。比如 在 3090 24G 上,刚好有一个模型要跑 30G 多一些怎么办?这时候很容易想到,将一部分内存来“充当”那显存使用,临时性地将显存的内容搬运到内存里,当这些显存的内容需要被访问时再搬回去,这样可以让上层的应用勉强能跑起来。为此我们基于 Nvidia 的 Unifed Memory 和 Cuda 劫持技术,构建了用户态的虚拟 GPU,实现了这一功能。该项技术使得推理服务在处理用户的较大请求过程中,显存的问题得到了极大的缓解。但是该技术也会使得显存和内存之间的 swap 操作变多,从而影响性能,因此在对性能有较高要求的场景,不建议设置太大的虚拟显存。

我们也有基于 Stable Diffusion WebUI 的一些应用,采用界面和算力分离的架构,不用 GPU,不用安装 WebUI,入门门槛低,也容易整合到用户自有的工作流中。用户也不用下载和维护模型,一方面我们已经集成了很多模型了,另一方面用户还可以添加自己的模型。

我们还提供了基于 Stable Diffusion 的 AI 图片生成和图片编辑的 API 平台,基本上从工程阶段已经做到了快、便宜,同样也能够支持各种模型,也能实现 文生图,图生图,ControlNet,Upscaling,Inpainting,Outpainting,抠图,和擦除等系列功能,可以满足游戏素材生成,电商图片的修改等场景。

另外,我们也针对一些场景实现了主体固定的解决方案,就是能生成一系列图片,但保持主体不变、背景变换,特别适合当前流行的儿童插画,小说配图生成等场景。
最后,我最近经常也在思考,我们人类为什么有智能。再看看 AI 的高速发展,距离我们人类越来越近了,现在AI的原理越来越和我们的大脑近似,也是类似的矩阵、向量的计算,所以我顿时感觉人类的智慧没有想象中那么伟大。
或者再过十年,计算机超越人类是完全有可能的。而我们作为音视频行业从业者,需要积极拥抱新的技术创造更大的价值。

