
- 1MySQL - 左连接、右连接、内连接、完全外连接、交叉连接 & 一对多、多对一、多对多 & 联合连接_mysql左连接语句
- 2联盛德 HLK-W806 (十二): Makefile组织结构和编译流程说明_foreach bin
- 3Android ANR 问题和流程排查详解_android线程阻塞查看
- 4secure boot(三)secure boot的签名和验签方案_芯片boot验签
- 5【C++MiNiSTL项目开发笔记】
- 6python 安装openai的踩坑史_openai 需要python什么版本
- 7C-构造类型-共用体-枚举
- 8Python3 如何反编译EXE_python exe 反编译
- 9第二章Linux集群(1)
- 10实例讲解如何使用Jekyll搭建一个静态网站_jekyll教程
Flink(十四)【Flink SQL(中)查询】_flink查询
赞
踩
前言
接着上次写剩下的查询继续学习。
Flink SQL 查询
环境准备:
- # 1. 先启动 hadoop
- myhadoop start
- # 2. 不需要启动 flink 只启动yarn-session即可
- /opt/module/flink-1.17.0/bin/yarn-session.sh -d
- # 3. 启动 flink sql 的环境 sql-client
- ./sql-client.sh embedded -s yarn-session
记得第二步:启动 yarn-seesion !!!
注意:我们写 SQL 的时候尽量避免关键字,比如函数名(avg、sum)!
1、分组窗口聚合
分组窗口起始就是我们之前学过的 滑动窗口、会话窗口、滚动窗口,之所以叫它分组窗口,其实是把它的一个窗口看做一个分组。
从1.13版本开始,分组窗口聚合已经标记为过时,鼓励使用更强大、更有效的窗口TVF聚合,在这里简单做个介绍。
直接把窗口自身作为分组key放在GROUP BY之后的,所以也叫“分组窗口聚合”。SQL查询的分组窗口是通过 GROUP BY 子句定义的。类似于使用常规 GROUP BY 语句的查询,窗口分组语句的 GROUP BY 子句中带有一个窗口函数为每个分组计算出一个结果。
Flink SQL中只支持基于时间的窗口,不支持基于元素个数的窗口。
| 分组窗口函数 | 描述 |
| TUMBLE(time_attr, interval) | 定义一个滚动窗口。time_attr 是时间属性,也就是你选择的作为时间语义的字段,interval 是窗口长度。 |
| HOP(time_attr, interval, interval) | 定义一个跳跃的时间窗口(在 Table API 中称为滑动窗口)。滑动窗口的长度( 第二个 interval 参数 )以及一个滑动的步长(第一个 interval 参数 )。 |
| SESSION(time_attr, interval) | 定义一个会话时间窗口。interval 是会话的间隔。 |

其中,ROWTIME 代表的是事件时间语义,PROCTIME 是处理时间语义。
1)准备数据
- CREATE TABLE ws (
- id INT,
- vc INT,
- pt AS PROCTIME(), --处理时间
- et AS cast(CURRENT_TIMESTAMP as timestamp(3)), --事件时间
- WATERMARK FOR et AS et - INTERVAL '5' SECOND --watermark
- ) WITH (
- 'connector' = 'datagen',
- 'rows-per-second' = '10',
- 'fields.id.min' = '1',
- 'fields.id.max' = '3',
- 'fields.vc.min' = '1',
- 'fields.vc.max' = '100'
- );
- # 设置显示
- set sql-client.execution.result-mode=tableau;

我们可以看到,一张 flink sql 的表是允许事件时间和处理时间都存在的,只是水位线只能指定一个。

2)滑动窗口示例(时间属性,窗口长度)
- Flink SQL> select id,
- > sum(vc) as vcSum,
- > tumble_start(et,interval '5' second) as window_start,
- > tumble_end(et,interval '5' second) as window_end
- > from ws
- > group by id,tumble(et,interval '5' second);
查询结果:

可以看到每个 key 的窗口每 5s 滚动一次。
3)滑动窗口(时间属性,滑动步长,窗口长度)
- Flink SQL> select id,
- > hop_start(et,interval '3' second,interval '5' second) window_start,
- > hop_end(et,interval '3' second,interval '5' second) window_end,
- > sum(vc) sum_vc
- > from ws
- > group by id,hop(et,interval '3' second,interval '5' second);
这里我们指定滑动步长为 3 窗口大小为 5,查看运行结果:

我们可以看到,相同 key 的窗口确实间隔 3s,窗口大小为 5s。
3)会话窗口(时间属性,会话间隔)
- select
- id,
- SESSION_START(et, INTERVAL '5' SECOND) wstart,
- SESSION_END(et, INTERVAL '5' SECOND) wend,
- sum(vc) sumVc
- from ws
- group by id, SESSION(et, INTERVAL '5' SECOND);
这里因为我们的数据生成器是源源不断生成数据的,而我们指定了会话间隔为 5s,也就是说只有连续 5s 收不到数据窗口才会关闭,所以我们是看不到数据结果的。
2、窗口表值函数(TVF)聚合
前面我们学习的 Group Window 在 Flink13 版本之后已经被标记为过时了,更推荐的是 TVF Window。
对比GroupWindow,TVF窗口更有效和强大。包括:
- 提供更多的性能优化手段
- 支持GroupingSets语法
- 可以在window聚合中使用TopN
- 提供累积窗口
对于窗口表值函数(TVF),窗口本身返回的是就是一个表,所以窗口会出现在FROM后面,GROUP BY后面的则是窗口新增的字段 window_start 和 window_end。
- FROM TABLE(
- 窗口类型(TABLE 表名, DESCRIPTOR(时间字段),INTERVAL 时间间隔)
- )
- GROUP BY [window_start,][window_end,] --可选
1)滚动窗口(tumble)
- Flink SQL> select
- > id,
- > sum(vc) as vc_sum,
- > window_start,
- > window_end
- > from table( -- 这里的table是关键字 不是表名
- > tumble(table ws,descriptor(et),interval '5' second)
- > )
- > group by window_start,window_end,id; -- 这里的window_start,window_end都是关键字
运行结果:

2)滑动窗口(hop)
注意:在 TVF 中,滑动窗口的大小必须是步长的整数倍,因为 TVF 会对滑动窗口进行一个优化:把滑动窗口按照步长大小划分为 (窗口大小/步长)个滚动窗口,这样一些需要重复计算的数据所在的滚动窗口只需要计算一次即可。
如果不是整数倍,会报错:[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.table.api.TableException: HOP table function based aggregate requires size must be an integral multiple of slide, but got size xxx ms and slide xxx ms
- Flink SQL> select
- > id,
- > sum(vc) as vc_sum,
- > window_start,
- > window_end
- > from table(
- > hop(table ws,descriptor(et),interval '2' second,interval '6' second)
- > )
- > group by window_start,window_end,id;
我们上面这个滑动窗口会被 TVF 划分为 6/2 也就是 3 个,其中第一个窗口和第二个窗口之间的会有两个重复的计算结果(也就是两个子滚动窗口)。

3)累积窗口(cumulate)
注意:累积窗口的窗口大小必须是步长的整数倍!
- Flink SQL> select
- > id,
- > sum(vc) vc_sum,
- > window_start,
- > window_end
- > from table(
- > cumulate(table ws,descriptor(et),interval '2' second,interval '6' second
- > ))
- > group by window_start,window_end,id;
累积窗口也很常用,需要指定两个参数(窗口的最大长度,窗口的步长),比如统计一天内每个小时的网站访问量就可以开一个累积窗口(窗口的最大长度是 24h,窗口的步长是 1h),语法也很简单,只需要修改一个滑动窗口的一个关键字:cumulate。当窗口结束后会再开启一个窗口,属性和上一个窗口是一样的。

累积窗口的底层还是一个滚动窗口,当我们定义了一个累积窗口,就相当于开了一个最大的滚动窗口,之后会根据用户指定的步长(也就是触发计算的时间)将这个窗口划分为多个窗口,这些窗口具有相同的起点和不同的终点。
4)grouping sets 多维分析
- SELECT
- window_start,
- window_end,
- id ,
- SUM(vc) sumVC
- FROM TABLE(
- TUMBLE(TABLE ws, DESCRIPTOR(et), INTERVAL '5' SECONDS))
- GROUP BY window_start, window_end,
- rollup( (id) )
- -- cube( (id) )
- -- grouping sets( (id),() )
- ;
这个多维分析用到的时候再详细了解,这里只知道Flink有这个功能就行了。
5)会话窗口
Flink 17 的 TVF 函数窗口其实是支持会话窗口的,但是现在还是实验性的功能。
3、Over 聚合
回想我们之前 Hive 学过的开窗函数,对每个数据,我们会去计算它的开窗范围进行计算输出。比如对上一行到这一行的数据进行计算;再比如计算第一行数据到当前行。
OVER 聚合为一系列有序行的每个输入行计算一个聚合值。与 GROUP BY 聚合相比,OVER聚合不会将每个组的结果行数减少为一行。相反,OVER聚合为每个输入行生成一个聚合值。
可以在事件时间或处理时间,以及指定为时间间隔、或行计数的范围内,定义Over windows。
1)语法:
- SELECT
- -- 聚合函数
- agg_func(agg_col) OVER (
- [PARTITION BY col1[, col2, ...]]
- ORDER BY time_col
- range_definition),
- ...
- FROM ...
- ORDER BY:必须是时间戳列(事件时间、处理时间),只能升序
- PARTITION BY:标识了聚合窗口的聚合粒度
- range_definition:这个标识聚合窗口的聚合数据范围,在 Flink 中有两种指定数据范围的方式。第一种为按照行数聚合(rows 关键字),第二种为按照时间区间聚合(range 关键字)。
- 按照时间分区时,对于同一时刻的数据都会被聚合计算,但是按照行数聚合就不会。
2)案例
1. 按照时间区间聚合
统计每个传感器前 10 秒到现在收到的水位数据条数
- select
- id,
- et,
- vc,
- count(vc) over(partition by id order by et range between interval '10' second preceding and current row) cnt
- from ws;
运行结果:

也可以用 WINDOW 子句来在SELECT外部单独定义一个OVER窗口,可以多次使用:
- select
- id,
- et,
- vc,
- count(vc) over w as cnt, -- 这里的 as 可以省略
- sum(vc) over w as sum_vc
- from ws
- window w as(
- partition by id
- order by et
- range between interval '10' second preceding and current row
- );
当我们有多个聚合函数并且这几个窗口函数的开窗属性是相同的时候这样写可以简化代码。
2. 按照行数聚合
统计每个传感器前5条到现在数据的平均水位:
- select
- id,
- et,
- vc,
- avg(vc) over w as avg
- from ws
- window w as (
- partition by id
- order by et
- rows between 5 preceding and current row
- );
运行结果:

4、特殊语法 - TopN
目前在Flink SQL中没有能够直接调用的TOP-N函数,而是提供了稍微复杂些的变通实现方法,是固定写法,特殊支持的over用法。
1)语法
- SELECT [column_list]
- FROM (
- SELECT [column_list],
- ROW_NUMBER() OVER ([PARTITION BY col1[, col2...]]
- ORDER BY col1 [asc|desc][, col2 [asc|desc]...]) AS rownum
- -- 不能指定行范围!!! 只能从最早到当前
- FROM table_name)
- WHERE rownum <= N [AND conditions]
- ROW_NUMBER() :标识 TopN 排序子句
- PARTITION BY col1[, col2...] :标识分区字段,代表按照这个 col 字段作为分区粒度对数据进行排序取 topN,比如下述案例中的 partition by key ,就是根据需求中的搜索关键词(key)做为分区
- ORDER BY col1 [asc|desc][, col2 [asc|desc]...] :标识 TopN 的排序规则,是按照哪些字段、顺序或逆序进行排序,可以不是时间字段,也可以降序(TopN特殊支持)
- WHERE rownum <= N :这个子句是一定需要的,只有加上了这个子句,Flink 才能将其识别为一个TopN 的查询,其中 N 代表 TopN 的条目数
- [AND conditions] :其他的限制条件也可以加上
2)案例
取每个传感器最高的3个水位值
- select
- id,
- et,
- vc,
- rownum
- from(
- select id,
- vc,
- row_number() over (partition by id order by vc desc ) as rownum
- from ws
- )where rownum <= 3;
运行结果:

5、特殊语法 - Deduplication 去重
这种语法也是借助于 over 窗口,语法和 topN 相似,唯一不同的是它要求排序的字段必须是时间属性列,同样可以降序,不可以是其它非时间属性的列。去重的原理是按时间升序或降序然后取第一条,所以升序和降序很影响性能,我们一般建议升序,因为这样当来了一条相同的数据时,由于按照时间升序,新数据的时间小,不会取代已有的数据;但是如果是降序的话,新数据的时间比较晚会被放到第一条数据的位置,就要发生更新操作;所以我们一般使用升序。
在 row_number = 1 时,如果排序字段是普通列 planner 会翻译成 TopN 算子,如果是时间属性列 planner 会翻译成 Deduplication,这两者最终的执行算子是不一样的,Deduplication 相比 TopN 算子专门做了对应的优化,性能会有很大提升。可以从web UI 看出是翻译成哪种算子(TopN 的算子叫 Rank、Deduplication 的算子叫 Deduplication、普通聚合(比如sum、avg)的算子叫 OverAggregate)。

如果是按照时间属性字段降序,表示取最新一条,会造成不断的更新保存最新的一条。如果是升序,表示取最早的一条,不用去更新,性能更好。
1)语法
- SELECT [column_list]
- FROM (
- SELECT [column_list],
- ROW_NUMBER() OVER ([PARTITION BY col1[, col2...]]
- ORDER BY time_attr [asc|desc]) AS rownum
- FROM table_name)
- WHERE rownum = 1;
2)案例
对每个传感器的水位值去重
- select
- id,
- et,
- vc,
- rownum
- from (
- select
- id,
- et,
- vc,
- row_number() over(partition by id,vc order by et asc) as rownum
- from ws
- )where rownum = 1;
运行结果:

我们发现所有的结果的操作都是 +I 说明没有重复数据,都是新插入的数据。
6、联结查询
在标准SQL中,可以将多个表连接合并起来,从中查询出想要的信息;这种操作就是表的联结(Join)。在Flink SQL中,同样支持各种灵活的联结(Join)查询,操作的对象是动态表。
在流处理中,动态表的Join对应着两条数据流的Join操作。Flink SQL中的联结查询大体上也可以分为两类:SQL原生的联结查询方式,和流处理中特有的联结查询。
注意:什么 join 就以谁为主,left join 就是以左边的流为主,右边的流来了只能老老实实待着,待在状态里没有资格输出。right join 同理。
6.1、常规联结查询
常规联结(Regular Join)是SQL中原生定义的Join方式,是最通用的一类联结操作。它的具体语法与标准SQL的联结完全相同,通过关键字JOIN来联结两个表,后面用关键字ON来指明联结条件。
与标准SQL一致,Flink SQL的常规联结也可以分为内联结(INNER JOIN)和外联结(OUTER JOIN),区别在于结果中是否包含不符合联结条件的行。
Regular Join 包含以下几种(以 L 作为左流中的数据标识, R 作为右流中的数据标识):
- Inner Join(Inner Equal Join):流任务中,只有两条流 Join 到才输出,输出 +[L, R]
- Left Join(Outer Equal Join):流任务中,左流数据到达之后,无论有没有 Join 到右流的数据,都会输出(Join 到输出 +[L, R] ,没 Join 到输出 +[L, null] ),如果右流之后数据到达之后,发现左流之前输出过没有 Join 到的数据,则会发起回撤流,先输出 -[L, null] ,然后输出 +[L, R]
- Right Join(Outer Equal Join):有 Left Join 一样,左表和右表的执行逻辑完全相反
- Full Join(Outer Equal Join):流任务中,左流或者右流的数据到达之后,无论有没有 Join 到另外一条流的数据,都会输出(对右流来说:Join 到输出 +[L, R] ,没 Join 到输出 +[null, R] ;对左流来说:Join 到输出 +[L, R] ,没 Join 到输出 +[L, null] )。如果一条流的数据到达之后,发现之前另一条流之前输出过没有 Join 到的数据,则会发起回撤流(左流数据到达为例:回撤 -[null, R] ,输出+[L, R] ,右流数据到达为例:回撤 -[L, null] ,输出 +[L, R]
Regular Join 的注意事项:
- 实时 Regular Join 可以不是 等值 join 。等值 join 和 非等值 join 区别在于, 等值 join数据 shuffle 策略是 Hash,会按照 Join on 中的等值条件作为 id 发往对应的下游; 非等值 join 数据 shuffle 策略是 Global,所有数据发往一个并发,按照非等值条件进行关联。
- 流的上游是无限的数据,所以要做到关联的话,Flink 会将两条流的所有数据都存储在 State 中,所以 Flink 任务的 State 会无限增大,因此你需要为 State 配置合适的 TTL,以防止 State 过大。
- join 的时候,左右两条流中的数据都会先存到状态中去,先来的数据会去对方的状态中去查找有没有可以匹配上的,没有就匹配为 null。
我们再准备一张表用于join:
- CREATE TABLE ws1 (
- id INT,
- vc INT,
- pt AS PROCTIME(), --处理时间
- et AS cast(CURRENT_TIMESTAMP as timestamp(3)), --事件时间
- WATERMARK FOR et AS et - INTERVAL '0.001' SECOND --watermark
- ) WITH (
- 'connector' = 'datagen',
- 'rows-per-second' = '1',
- 'fields.id.min' = '3',
- 'fields.id.max' = '5',
- 'fields.vc.min' = '1',
- 'fields.vc.max' = '100'
- );
1)等值内联结(INNER Equi-JOIN)
内联结用INNER JOIN来定义,会返回两表中符合联接条件的所有行的组合,也就是所谓的笛卡尔积(Cartesian product)。目前仅支持等值联结条件。
select ws.id,ws1.id from ws join ws1 on ws.id=ws1.id;
我们可以看到,inner join 必须等待两条流都到齐后才会开始 join,否则就在状态里等着。
2)等值外联结(OUTER Equi-JOIN)
与内联结类似,外联结也会返回符合联结条件的所有行的笛卡尔积;另外,还可以将某一侧表中找不到任何匹配的行也单独返回。Flink SQL支持左外(LEFT JOIN)、右外(RIGHT JOIN)和全外(FULL OUTER JOIN),分别表示会将左侧表、右侧表以及双侧表中没有任何匹配的行返回。
具体用法如下:
left join:
select ws.id,ws1.id,ws.vc,ws1.vc from ws left join ws1 on ws.vc=ws1.vc;
运行结果:

right join:
select ws.id,ws.vc,ws1.id,ws1.vc from ws right join ws1 on ws.vc=ws1.vc;运行结果:
full join:

6.2、间隔联结查询
我们曾经学习过 DataStream API 中的双流 Join ,包括窗口联结(window join)和间隔联结(interval join)。两条流的Join就对应着SQL中两个表的Join,这是流处理中特有的联结方式。目前Flink SQL还不支持窗口联结,而间隔联结则已经实现。
间隔联结(Interval Join)返回的同样是符合约束条件的两条中数据的笛卡尔积。只不过这里的“约束条件”除了常规的联结条件外,还多了一个时间间隔的限制。具体语法有以下要点:
- 两表的联结
间隔联结不需要用JOIN关键字,直接在FROM后将要联结的两表列出来就可以,用逗号分隔。这与标准SQL中的语法一致,表示一个“交叉联结”(Cross Join),会返回两表中所有行的笛卡尔积。
- 联结条件
联结条件用WHERE子句来定义,用一个等值表达式描述。交叉联结之后再用WHERE进行条件筛选,效果跟内联结INNER JOIN ... ON ...非常类似。
- 时间间隔限制
我们可以在WHERE子句中,联结条件后用AND追加一个时间间隔的限制条件;做法是提取左右两侧表中的时间字段,然后用一个表达式来指明两者需要满足的间隔限制。具体定义方式有下面三种,这里分别用 ltime 和 rtime 表示左右表中的时间字段:
(1)ltime = rtime
(2)ltime >= rtime AND ltime < rtime + INTERVAL '10' MINUTE

(3)ltime BETWEEN rtime - INTERVAL '10' SECOND AND rtime + INTERVAL '5' SECOND

测试一下:
select * from ws,ws1 where ws.id=ws1.id and ws.et between ws1.et - interval '2' second and ws1.et + interval '2' second;查看 Web UI :

6.3、维表联结查询
Lookup Join 其实就是维表 Join,实时获取外部缓存的 Join,Lookup 的意思就是实时查找。
维度表(Dimension Table)是数据仓库中的一种表结构,通常包含有关业务过程的描述性属性。它可以提供多个角度来理解和分析数据。维度表的特点是宽而扁平,每一行代表一个实体,每一列代表一个属性。
比如我们只知道商品的 id ,不知道商品的名字,那么我们的Flink流就需要去 join 通过mysql 的连接器去获取mysql中的数据。
上面说的这几种 Join 都是流与流之间的 Join,而 Lookup Join 是流与 Redis,Mysql,HBase 这种外部存储介质的 Join。仅支持处理时间字段。
- 表A
- -- 固定写法 没有为什么
- JOIN 维度表名 FOR SYSTEM_TIME AS OF 表A.proc_time AS 别名
- ON xx.字段=别名.字段
比如维表在mysql,维表join的写法如下:
- CREATE TABLE Customers (
- id INT,
- name STRING,
- country STRING,
- zip STRING
- ) WITH (
- 'connector' = 'jdbc',
- 'url' = 'jdbc:mysql://hadoop102:3306/customerdb',
- 'table-name' = 'customers'
- );
-
- -- order表每来一条数据,都会去mysql的customers表查找维度数据
-
- SELECT o.order_id, o.total, c.country, c.zip
- FROM Orders AS o
- JOIN Customers FOR SYSTEM_TIME AS OF o.proc_time AS c
- ON o.customer_id = c.id; --连接条件
后面我们学习连接器的时候会深入学习。
7、Order by 和 limit
1)order by
支持 Batch\Streaming,但在实时任务中一般用的非常少。
实时任务中,Order By 子句中必须要有时间属性字段,并且必须写在最前面且为升序。
- -- 时间属性必须为升序asc
- select * from ws order by et,id desc; - 我们指定id字段降序
运行结果:

2)limit
select * form ws limit 3;运行结果:

8、SQL Hints
翻译过来叫 SQL 暗示,确实语法就像我们 Java 中的注释一样。
在执行查询时,可以在表名后面添加SQL Hints来临时修改表属性,对当前job生效。放我们定义好一张 Flink SQL 表的时候,如果要修改参数,比如数据生成器产生数据的速度,我们不可能每次都把表删了重建,那样太麻烦了。我们可以使用 SQL Hints,它主要修改的就是我们建表时 with的参数。
- -- 修改数据生成器产生数据的速度
- select * from ws1/*+ OPTIONS('rows-per-second'='10')*/;
9、集合操作
1)UNION 和 UNION ALL(合并)
将两张表上下拼接在一起,要求必须字段必须一样,至少字段数量一样,而且每个位置的字段类型是一样的。
- UNION:将集合合并并且去重
- UNION ALL:将集合合并,不做去重。
- select id from ws
- union
- select id from ws1;
运行结果:

可以看到结果是去重的,因为我们 id 的范围(ws: 1-3,ws1:3-5)。
- select id from ws
- union all
- select id from ws1;
运行结果:

可以看到,union all 不去重。
2)Intersect 和 Intersect All
- Intersect:交集并且去重
- Intersect ALL:交集不做去重
- select id from ws
- intersect
- select id from ws1;
运行结果:

可以看到,运行结果就是我们两张表的共同 id 。
- select id from ws
- intersect all
- select id from ws1;
运行结果:
可以看到,结果没有去重。
3)Except 和 Except All
- Except:差集并且去重
- Except ALL:差集不做去重
- select id from ws
- except
- select id from ws1;
运行结果:

可以看到,左边ws流中 id=3 的数据到了,但是右边ws1流中没有,于是认为是差值输出,直到ws1中出现了id=3的数据,发现这不是差值,于是撤回。
而且结果是相对于左边 ws 流的,也就是只会输出 ws 流中有而 ws1 没有的数据。
- select id from ws
- except all
- select id from ws1;
运行结果:

上述 SQL 在流式任务中,如果一条左流数据先来了,没有从右流集合数据中找到对应的数据时会直接输出,当右流对应数据后续来了之后,会下发回撤流将之前的数据給撤回。这也是一个回撤流。
4)In 子查询
- In 子查询的结果集只能有一列
select id,vc from ws where id in (select id from ws1);
运行结果:

上述 SQL 的 In 子句和之前介绍到的 Inner Join 类似。并且 In 子查询也会涉及到大状态问题,要注意设置 State 的 TTL。
10、系统函数(System Functions)
系统函数(System Functions)也叫内置函数(Built-in Functions),是在系统中预先实现好的功能模块。我们可以通过固定的函数名直接调用,实现想要的转换操作。Flink SQL提供了大量的系统函数,几乎支持所有的标准SQL中的操作,这为我们使用SQL编写流处理程序提供了极大的方便。
Flink SQL中的系统函数又主要可以分为两大类:标量函数(Scalar Functions)和聚合函数(Aggregate Functions)。
我们也可以通过下面的指令查看所有内置函数:
show functions;10.1、标量函数(Scalar Functions)
标量函数指的就是只对输入数据做转换操作、返回一个值的函数。
标量函数是最常见、也最简单的一类系统函数,数量非常庞大,很多在标准SQL中也有定义。所以我们这里只对一些常见类型列举部分函数,做一个简单概述,具体应用可以查看官网的完整函数列表。
1)比较函数(Comparison Functions)
比较函数其实就是一个比较表达式,用来判断两个值之间的关系,返回一个布尔类型的值。这个比较表达式可以是用 <、>、= 等符号连接两个值,也可以是用关键字定义的某种判断。例如:
(1)value1 = value2 判断两个值相等;
(2)value1 <> value2 判断两个值不相等
(3)value IS NOT NULL 判断value不为空
2)逻辑函数(Logical Functions)
逻辑函数就是一个逻辑表达式,也就是用与(AND)、或(OR)、非(NOT)将布尔类型的值连接起来,也可以用判断语句(IS、IS NOT)进行真值判断;返回的还是一个布尔类型的值。例如:
(1)boolean1 OR boolean2 布尔值boolean1与布尔值boolean2取逻辑或
(2)boolean IS FALSE 判断布尔值boolean是否为false
(3)NOT boolean 布尔值boolean取逻辑非
3)算术函数(Arithmetic Functions)
进行算术计算的函数,包括用算术符号连接的运算,和复杂的数学运算。例如:
(1)numeric1 + numeric2 两数相加
(2)POWER(numeric1, numeric2) 幂运算,取数numeric1的numeric2次方
(3)RAND() 返回(0.0, 1.0)区间内的一个double类型的伪随机数
4)字符串函数(String Functions)
进行字符串处理的函数。例如:
(1)string1 || string2 两个字符串的连接
(2)UPPER(string) 将字符串string转为全部大写
(3)CHAR_LENGTH(string) 计算字符串string的长度
5)时间函数(Temporal Functions)
进行与时间相关操作的函数。例如:
(1)DATE string 按格式"yyyy-MM-dd"解析字符串string,返回类型为SQL Date
(2)TIMESTAMP string 按格式"yyyy-MM-dd HH:mm:ss[.SSS]"解析,返回类型为SQL timestamp
(3)CURRENT_TIME 返回本地时区的当前时间,类型为SQL time(与LOCALTIME等价)
(4)INTERVAL string range 返回一个时间间隔。
2)聚合函数(Aggregate Functions)
聚合函数是以表中多个行作为输入,提取字段进行聚合操作的函数,会将唯一的聚合值作为结果返回。聚合函数应用非常广泛,不论分组聚合、窗口聚合还是开窗(Over)聚合,对数据的聚合操作都可以用相同的函数来定义。
标准SQL中常见的聚合函数Flink SQL都是支持的,目前也在不断扩展,为流处理应用提供更强大的功能。例如:
(1)COUNT(*) 返回所有行的数量,统计个数。
(2)SUM([ ALL | DISTINCT ] expression) 对某个字段进行求和操作。默认情况下省略了关键字ALL,表示对所有行求和;如果指定DISTINCT,则会对数据进行去重,每个值只叠加一次。
(3)RANK() 返回当前值在一组值中的排名。
(4)ROW_NUMBER() 对一组值排序后,返回当前值的行号。
其中,RANK()和ROW_NUMBER()一般用在OVER窗口中。
11、Module 操作
Module 允许 Flink 扩展函数能力。它是可插拔的,Flink 官方本身已经提供了一些 Module,用户也可以编写自己的 Module。
目前 Flink 包含了以下三种 Module:
- CoreModule:CoreModule 是 Flink 内置的 Module,其包含了目前 Flink 内置的所有 UDF,Flink 默认开启的 Module 就是 CoreModule,我们可以直接使用其中的 UDF
- HiveModule:HiveModule 可以将 Hive 内置函数作为 Flink 的系统函数提供给 SQL\Table API 用户进行使用,比如 get_json_object 这类 Hive 内置函数(Flink 默认的 CoreModule 是没有的)
- 用户自定义 Module:用户可以实现 Module 接口实现自己的 UDF 扩展 Module
使用 LOAD 子句去加载 Flink SQL 体系内置的或者用户自定义的 Module,UNLOAD 子句去卸载 Flink SQL 体系内置的或者用户自定义的 Module。
我们可以查看当前启用的 module:

或者:

1)语法
- -- 加载
- LOAD MODULE module_name [WITH ('key1' = 'val1', 'key2' = 'val2', ...)]
- -- 卸载
- UNLOAD MODULE module_name
-
- -- 查看
- SHOW MODULES;
- SHOW FULL MODULES;
在 Flink 中,Module 可以被 加载、启用 、禁用 、卸载 Module,当加载Module 之后,默认就是开启的。同时支持多个 Module 的,并且根据加载 Module 的顺序去按顺序查找和解析 UDF,先查到的先解析使用。
此外,Flink 只会解析已经启用了的 Module。那么当两个 Module 中出现两个同名的函数且都启用时, Flink 会根据加载 Module 的顺序进行解析,结果就是会使用顺序为第一个的 Module 的 UDF,可以使用下面语法更改顺序:
use module hive,core;USE是启用module,没有被use的为禁用(禁用不是卸载),除此之外还可以实现调整顺序的效果。上面的语句会将 Hive Module 设为第一个使用及解析的 Module。
2)案例
加载官方已经提供的的 Hive Module,将 Hive 已有的内置函数作为 Flink 的内置函数。需要先引入 hive 的 connector。其中包含了 flink 官方提供的一个 HiveModule。
1. 上传jar包到flink的lib中
上传hive connector
这里的 hive 版本要和我们导进去的 jar 包的hive版本一致,
- # linux
- cp flink-sql-connector-hive-3.1.3_2.12-1.17.0.jar /opt/module/flink-1.17.0/lib/
2. 重启 flink 集群和 sql-client
- Flink SQL> load module hive with('hive-version'='3.1.3');
- Flink SQL> show full modules;
- +-------------+------+
- | module name | used |
- +-------------+------+
- | core | TRUE |
- | hive | TRUE |
- +-------------+------+
- 2 rows in set
我们查看所有函数:
Flink SQL> show functions;
我们发现,内置函数多了两百多个。
select split('hello,flink');运行结果:
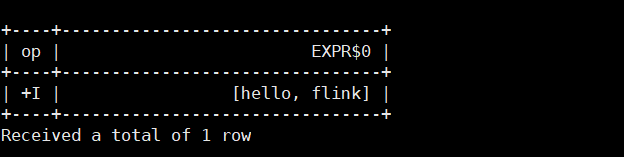
如果 hive 和 flink 有一个相同函数,一般会优先使用 flink 中的,但我们可以调整优先级。
use modules hive,core;
