
- 1基于ssm后台的宿舍管理系统小程序源码和论文
- 2Bert预训练模型
- 3nc使用详解
- 4决策树--ID3,C4.5,CART_采用决策树,给出id3、c4.5和cart算法的划分标准。通过交叉验证选择超参数用p
- 5基于 VScode 的 git 详细使用指南【保姆级!建议收藏!】_vscode使用git需要电脑安装git吗_git vscode
- 6计算机毕业设计python+spark知识图谱房价预测系统 房源推荐系统 房源数据分析 房源可视化 房源大数据大屏 大数据毕业设计 机器学习
- 7微信小程序开发:实现音乐播放与推荐_微信音乐小程序项目实现主要内容
- 8C++编程_#include
#include #include - 9VS2013 scanf_s引起 msvcr110d.dll xxxxxx处有未经处理的异常_用scnaf-s函数出现未经处理的异常
- 10GitHub Copilot——AI开发人员工具_github copilot官网
《AI学习笔记》大模型-微调/训练区别以及流程_模型微调和模型训练的区别
赞
踩
阿丹:
之前一直对于大模型的微调和训练这两个名词不是很清晰,所有找了一个时间来弄明白到底有什么区别以及到底要怎么去使用去做。并且上手实践一下。
大模型业务全流程:
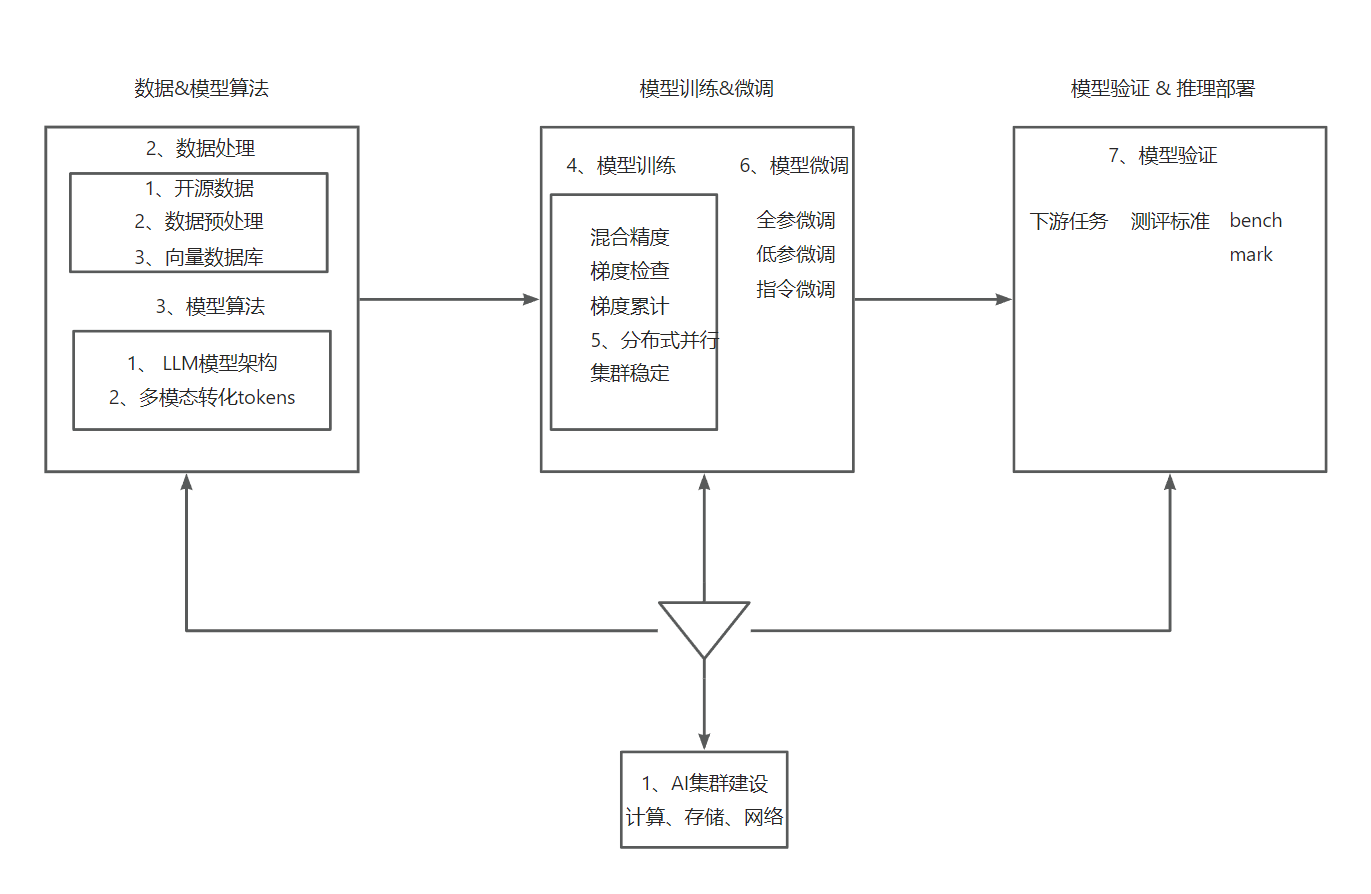
大模型为啥要微调?有哪些微调方式?
模型参数与数据集规模增长-》
模型微调:
允许少量地重新调整预训练大模型的权重参数,或者大模型的输入和输出
有助于降低训练大模型的复杂性,降低重新进行训练的成本。
微调技术
低参数微调(PEFT)
全参微调,普通微调(Full Parameter Fine-Tuning)
SFT有监督微调
Instruction Tuning,指令微调
RLHF,ReinForcement Learning Human Feedback,人类反馈强化学习。
微调的发展:
LLM and LVM 预训练大模型的训练成本非常高,需要庞大的计算机资源和大量的数据
按照微调的参数规模划分:
Full Parameter Fine-Tuing全参数微调和Parameter Efficient Fine-Tuning PEFT,参数高效微调:
FPFT:用预训练模型作为初始化权重,在特定数据集上继续训练,全部参数都更新的方法
PEFT:用更少的计算资源完成模型参数的更新,包括之更新一部分的参数,或者通过对参数进行某种结构化约束,例如稀疏化或者降低参数模型数量。
常用微调(PEFT):
微调进入:PEFT,通过最小微调网络模型中的参数数量和计算复杂度,来提高预训练模型在新任务上的性能,用来缓解大模型预训练的成本。
好处:
即使计算资源受限制,也可以利用预训练模型的知识来迅速适应新的任务,实现高效的迁徙,学习Transfer Learning。因此,Peft技术可以在提高模型效果的同时,缩短模型训练时间和计算成本。
按照训练的流程划分
按照大模型训练阶段进行微调,或者根据大模型微调的目标来区分:
提示微调、监督微调、人类反馈强化学习的方式
In-Context Learning 上下文学习(向量数据库)
区别预普通的微调fine-tuning。不对LLMS执行任何微调,直接将模型的输入输出拼接起来作为一个prompt,引导模型根据输入的数据结构,给出任务的预测结果。
ICL(上线文学习)能够给予无监督学习的基础上取得更好的模型效果,并且不需要根据特定的任务重新微调Fine-Tuning更新模型参数,避免不同任务要进行重新真正的微调。
按照训练的方式来划分:
预训练Pre-Training:
LLMs预训练过程是无监督的,但是微调过程往往是有监督的,当进行有监督的微调时,模型权重会根据真实的标签差异进行调整。
Supervised find-tuning.SFT:
有监督微调使用有标签的数据(Label Data)来调整已经训练的LLMs,用来更加适配指定的场景任务。
指令微调Instruction Tuning
指令微调可以被看做是要监督sft的一种特殊的形式
SFT:使用标记数据对预训练模型进行微调的过程,让模型能够更好的执行特定的任务。
IT:通过<指令,输出>对数据集上进一步训练LLMsm的过程,以增强LLMs能力和可控性。
特殊之处在于其数据集的结构,用人类指令和期望的输出组成进行配对,这种数据接口让微调专注于让模型理解和遵循人类的指令。作为有监督的一种特殊方式,专注于通过理解和遵循人类指令来增强大模型的能力和可控性。
经典LLMs训练流程
基于Transformer大模型,ChatGPT以及LIama2,大体都是三个训练步骤:
预训练-》有监督微调-》对齐
1》预训练,模型会学习来自海量、无标注文本数据集知识
2》使用有监督微调方式来细化模型,在后面的推理中更好的遵循特定指令
3》使用对齐技术让LLMs可以更有用更安全的相应用户提示prompt(提问模版)
流程详情:
1、预训练pre
预训练阶段通常需要数十到百亿Token的文本语料库,但训练目标是简单的【下一个单词预测】任务。
自监督训练(无监督学习):让大模型从大规模数据中学习,不依赖人工标注完成训练,因为训练、学习的标签是文本的后续单词,已经在训练的数据集中了。
2、有监督微调 Supervised finetuning
第二阶段是在【下一个单词预测】任务,中区别在于数据集,需要人工标注的指令数据集,模型输入是一个指令或者特殊的数据结构。输出为期望大模型的回复内容。
程序会将指令文本作为大模型的输入,并逐个Token输出,训练目标和预期输出相同。
虽然1阶段和2阶段都采用【next token prediction】训练方式,但是sft的数据集通常比预训练的数据小很多,指令数据需要提供标注结果(权重等),所以没有办法规范大模型应用。
3、对齐 Alignment
第三阶段还是微调,不过主要目标是将大模型配合人类的偏好、价值观进行对齐,也是RLHF机制发挥作用的时候。
PLHF主要包括步骤
1、预训练有监督微调
收集提示词集合,并要求Label(绰号)人员写出高质量的答案,然后使用该数据集监督的方式来微调预训练模型-》产生一个SFT
有监督微调使用有标签的数据(Label Data)来调整已经训练的LLMs,用来更加适配指定的场景任务。
2、创建奖励模型
对于每个提示Prompt,要求微调后的LLMs生成多个回复,再让标注人员根据真实的偏好对所有回复进行排序。接着训练奖励模型RM来学习人类的偏好,用于后续优化。
3、PPO进行微调
使用强化学习算法PPO等,根据奖励模型RM提供的奖励分数,对SFT模型进一步优化用于后续的推理。
微调使用场景:
1、定制模型
微调大模型,根据用户自身的具体需求定制模型,从而提高准确性和性能。
2、提高资源利用率
通过减少从头开始构建新模型的方式进行预训练,从而来节省时间、算力资源和其他带来的成本。
3、性能提升
微调的过程,可以让用户的独特的数据集,来增强训练模型的性能。
4、数据优化
可以充分利用客户的数据,调整
总结:
有一些微调其实也是训练的一种,用来提高回复的效果。
还有其他的提示词和模版也是微调的一部分。

