
- 1python threading模块进阶之join_python threading join
- 2动手学CV-目标检测入门教程2:VOC数据集_voc格式数据集中的绝对路径信息
- 3为什么要用傅里叶变换?FFT你不知道的细节_fft算法的基本原理
- 4一、NLP中的文本分类_nlp文本分类
- 5苹果笔记本能玩网页游戏吗 苹果电脑玩steam游戏怎么样 苹果手机可以玩游戏吗 mac电脑安装windows
- 6深度学习-第J9周:Inception v3算法实战与解析
- 7利用AI Agent革新Text2SQL应用_chain of thought微调text2sql方法
- 8Elasticsearch:不用高深的数学知识来理解 LLMs 是如何工作的
- 9SFT 监督微调_sft微调任务
- 10YOLO目标检测综述(2024.6月最新!)_目标检测 综述
LLM大模型技术实战3:大白话带你掌握Transformer架构_自注意力机制:transformer的核心是自注意力机制(self-attention),它能够在输
赞
踩
Transformer架构及其变体(如GPT、BERT等)已经成为许多NLP任务的基石。它们不仅在学术界取得了巨大成功,也被广泛应用于工业界,改善了搜索引擎、语音识别、推荐系统等技术的性能。理解Transformer架构对于从事深度学习和NLP研究的人来说至关重要。它的提出标志着NLP领域的一个重要转折点,开启了处理语言数据的新篇章。随着技术的不断发展和优化,Transformer及其衍生模型将继续推动人工智能领域的进步。
一、Transformer的核心概念
1. 自注意力机制(Self-Attention)
自注意力机制是Transformer的核心,它使模型能够处理输入序列中的每个元素,并计算元素之间的关系。简而言之,自注意力机制允许模型在处理一个元素(如一个单词)时,考虑到序列中的所有其他元素,从而捕获它们之间的上下文关系。这种机制特别适用于处理序列数据,如文本或时间序列数据。
- 1
2. 编码器-解码器结构
Transformer原始架构包含两部分:编码器和解码器。编码器负责处理输入数据,解码器负责生成输出数据。在NLP任务中,例如机器翻译,编码器处理源语言文本,解码器生成目标语言文本。每个编码器或解码器由多个相同的层堆叠而成,每层都包含自注意力机制和前馈神经网络。
- 1
3. 位置编码
由于Transformer完全基于注意力机制,不使用循环(RNN)或卷积(CNN)结构,因此无法直接处理序列中的位置信息。为了解决这个问题,Transformer引入了位置编码,将位置信息添加到输入序列的每个元素中。这使模型能够利用元素的顺序信息。
- 1
4. Transformer的优点
-
并行计算能力:相比于RNN需要按顺序处理序列的元素,Transformer可以同时处理整个序列,显著提高了计算效率。
-
长距离依赖处理:自注意力机制使得模型能够直接计算序列中任意两个元素之间的关系,有效地捕获长距离依赖信息。
-
灵活性和通用性:Transformer架构可以应用于多种NLP任务,如文本分类、机器翻译、问答系统等,只需少量修改即可适应不同的应用场景。
二、Transformer整体架构
1、背景知识铺垫
1.1、生成式模型
相信大家在使用手机聊天的输入法时,都会注意到,当你输入文字后,会有很多的选项,那么这些选项是如何而来的呢?
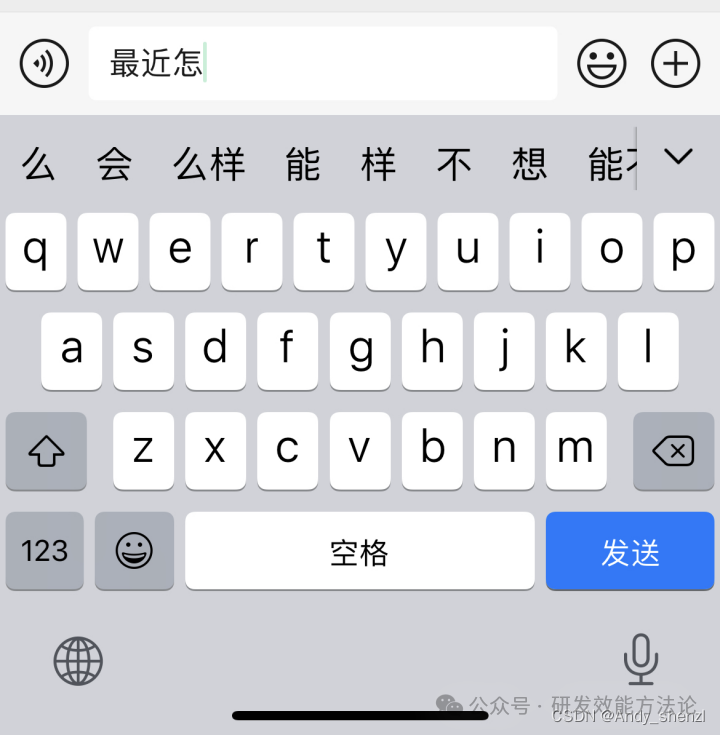
首先要了解一下N_gram

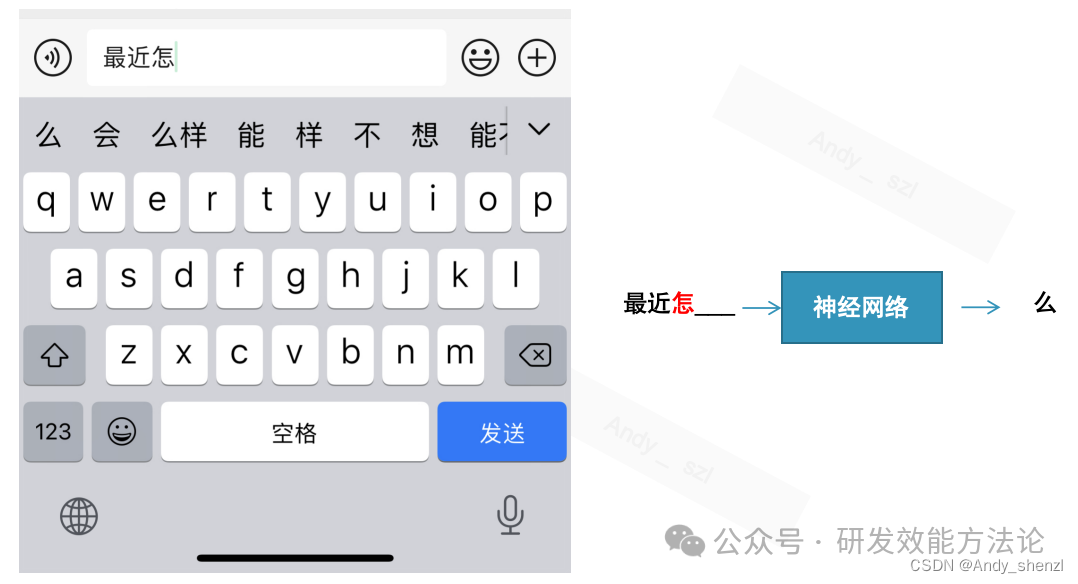
当我们输入最近怎______时,手机一般会给出很多的提示,这些提示我们可以发现都是和怎相关的词组,这些可以选择的词组是如何来的呢?
比如我们使用一个数据集来训练一个模型,那么模型就会将数据集里面涉及到的怎后面所有的情况列举在这里,并按照出现的频率进行排序,让我们进行好选择,这种方法被称为1-Gram,就是根据前面一个词来选择后面生成的词。
再来看看3-Gram,就是根据前面的三个词来预测下一个词,这时就在在数据集中找到最近怎三个子同时出现的词组后面出现的说有的字出现的情况,我们可以看到,出现的字的数量少了很多

如果根据前面所选的字的数量越多,那么参考的信息就越多,其实我们预测准确性聚会越高,但是,也有可能无法给出预测,这就是N-gram方法。
当然这种方法因为是靠统计方法,很容易出现过拟合;其次,对于一些低频词汇无法进行预测,所以在真正的大型语言处理中不会使用N-gram。
1.2、神经网络
在transformer中,其实是使用神经网络来进行预测的,这里做一个简单的介绍:
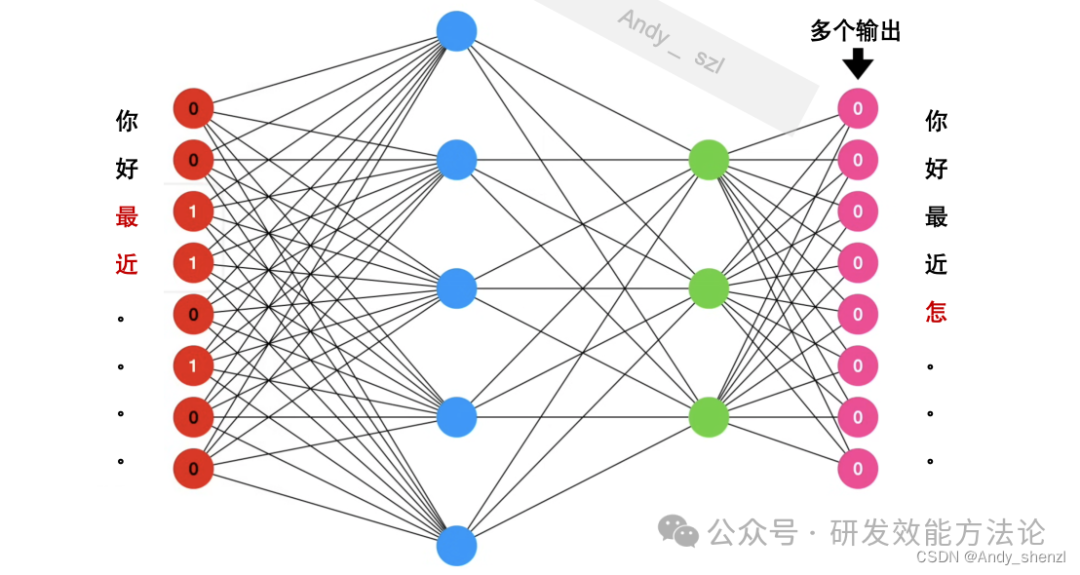
神经网络会根据大脑神经元的传递方式进行模拟,我们看上图。输入时我们所有的词,编码后向后传递,经过神经元后进行传播和更新权重;而输出呢,当输出的选择时两个标签时就是二分类问题,比如情感分类、垃圾邮件识别等;如果是多个值就是多分类;当然如果输出的选择时全部的词组时那么就是文本生成模型。
我想这一点对于学习transformer的人来说应该比较容易理解。
2、整体框架
我们按照transformer原文的整体架构来简单的进行梳理

2.1 tokenization
在自然语言处理(NLP)中,tokenization是将文本分解为更小的单元的过程,这些单元通常被称为tokens。我们更加容易理解的表示就是分词。
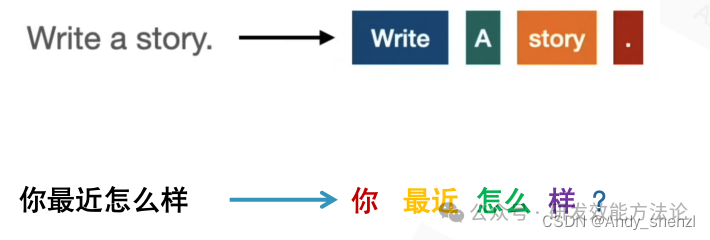
英文一般按照空格进行切分,是比较容易的;而中文就比较麻烦了,需要建立分词辞典根据词典中出现的特有名词等进行切分,当然对于python来说有现成的开源分词工具,如Jieba、spacy等等;还有就是停用词,有些词语没有实际的意义我们可以直接过滤掉来减轻我们模型的压力以及减少不必要的混淆。
2.2 embedding
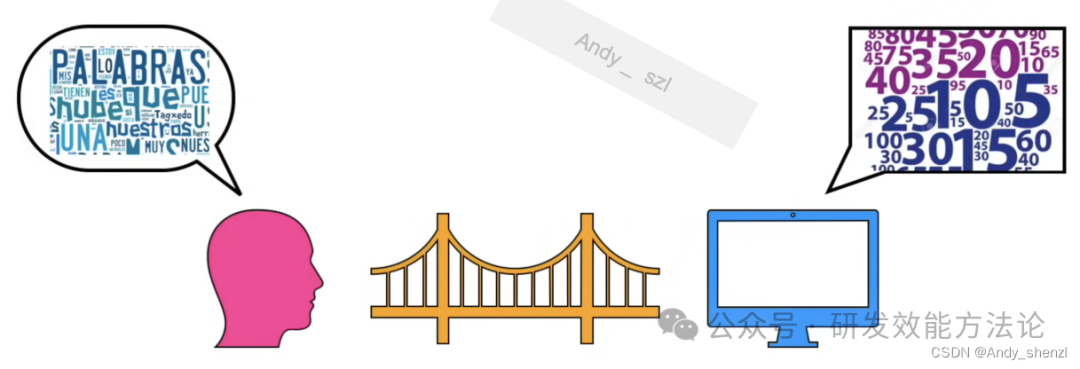
embedding就是建立自然语言和计算机识别语言的桥梁,主要目的就是相似性高的词会给予更加相近的向量。
这里要多说一句的就是,embedding是如何创建的?

我们的大脑在看见不同的事物的时候,会根据事物的各种特征进行分类,比如我们看见苹果和草莓时,认为他们都是水果,在大脑里面就会有一个位置给他们进行编码,会将他们放在一起,距离比较近的位置,而当出现一个其他的类别,比如建筑物,那么大脑会根据他的类别,将其放在另外一个地方,当然我们这里指的是相对位置。

其实是经网络的构建是一致的,也会给他创建一个位置,让相似的在一起
2.3 位置编码
我们知道RNN和LSTM是一种循环的序列模型,本身训练的过程中就会有位置的训练;但是我们看到transformer中,到现在为止我们没有讲到与序列或者排序相关的内容。
我们知道在自然语言中,字词的顺序是会影响语义的,比如:
-
我爱你
-
你爱我
同样的三个字,顺序不一样,表达的不是一个概念,所以我们必须要考虑这一点。
首先我们看一下论文中进行位置编码的位置,他是在做完embedding后,创建位置编码与原始的embedding进行相加,然后再去进行attention。

也就是说我们给予所有的词一个初始的位置编码,让位置编码直接加到原始的embedding上去,让模型不断的去学习和修改每个字词的方向
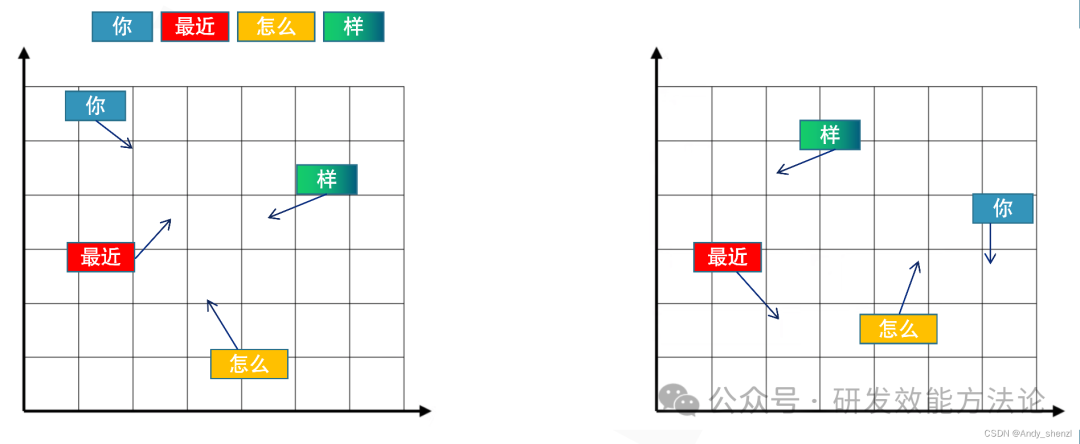
在不断的调整中,让模型学习到顺序,让后理解他们相互之间的关联(相互作用力)进行修改其embedding。
2.4 注意力机制
注意力机制其实最大的作用就是对词嵌入也就是embedding的优化,下面我们来看下是怎么做到的。
一个例子
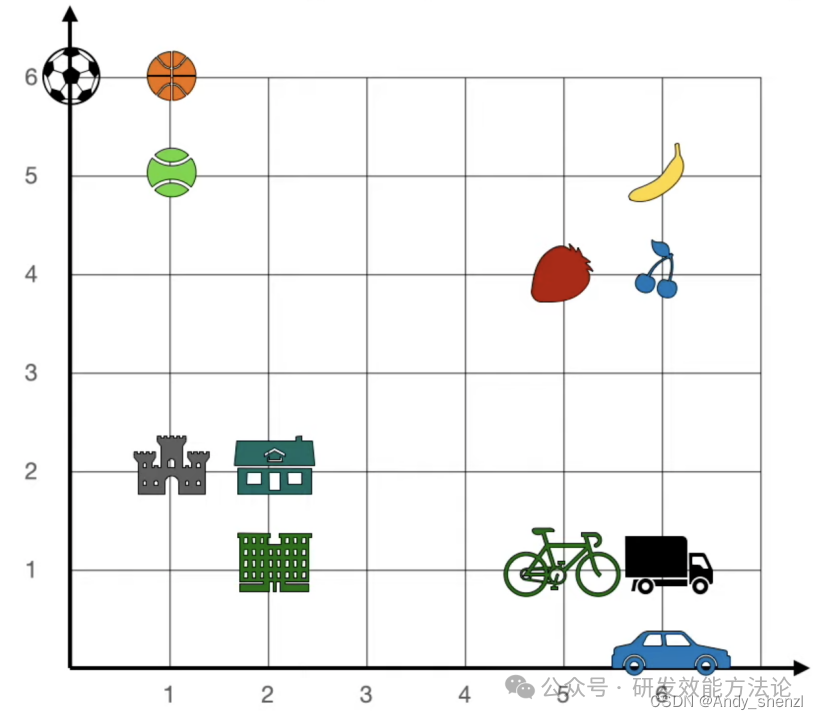
我们这里有一堆文本单词,在一个二维的坐标系中,每个单词都有一个水平和垂直的坐标,比如香蕉是6,5,那么现在出现了一个新的单词,apple(
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

