
- 1金融质检新纪元:AI技术如何重塑服务体验
- 2求0~10000的水仙花数_0-10000水仙花
- 3基于SSM的“小型企业人事管理系统”的设计与实现(源码+数据库+文档+PPT)_ssm人力资源管理系统代码
- 4树莓派puttyl连接_putty连接树莓派
- 5包含libusb库文件报错:libusb-1.0/libusb.h: No such file or directory_libusb-1.0-0-dev
- 6深入解析SOME/IP协议在汽车行业的应用案例_汽车ip协议
- 7【粉丝投稿】上海某大厂的面试题,岗位是测开(25K*16)_大厂测开
- 8Kafka(三)生产者发送JSON消息+使用统一序列化器+提升吞吐量_kafka json序列化
- 9AI大模型探索之路-实战篇:智能化IT领域搜索引擎的构建与初步实践
- 10ireport中文手册3.7版(无图)_ireport中文版
CPU、GPU、FPGA、ASIC等AI芯片特性及对比
赞
踩
点击蓝字关注我们
- 关注、星标公众号,精彩内容每日送达
- 来源:网络素材
1、前言
目前,智能驾驶领域在处理深度学习AI算法方面,主要采用GPU、FPGA 等适合并行计算的通用芯片来实现加速。同时有部分芯片企业开始设计专门用于AI算法的ASIC专用芯片,比如谷歌TPU、地平线BPU等。在智能驾驶产业应用没有大规模兴起和批量投放之前,使用GPU、FPGA等已有的通用芯片可以避免专门研发定制芯片(ASIC)的高投入和高风险,但是,由于这类通用芯片设计初衷并非专门针对深度学习,因而存在性能不足、功耗过高等方面的问题。这些问题随着自动驾驶行业应用规模的扩大将会日益突出。
本文从芯片种类、性能、应用和供应商等多角度介绍AI芯片,用于给行业内入门新人扫盲。
2、什么是人工智能(AI)芯片?
从广义上讲,能运行AI算法的芯片都叫AI芯片。
目前通用的CPU、GPU、FPGA等都能执行AI算法,只是执行效率差异较大。
但狭义上讲一般将AI芯片定义为“专门针对AI算法做了特殊加速设计的芯片”。

目前AI芯片的主要用于语音识别、自然语言处理、图像处理等大量使用AI算法的领域,通过芯片加速提高算法效率。AI芯片的主要任务是矩阵或向量的乘法、加法,然后配合一些除法、指数等算法。AI算法在图像识别等领域,常用的是CNN卷积网络,一个成熟的AI算法,就是大量的卷积、残差网络、全连接等类型的计算,本质是乘法和加法。
对汽车行业而言,AI芯片的主要用于就是处理智能驾驶中环境感知、传感器融合和路径规划等算法带来的大量并行计算需求。
AI芯片可以理解为一个快速计算乘法和加法的计算器,而CPU要处理和运行非常复杂的指令集,难度比AI芯片大很多。GPU虽然为图形处理而设计,但是CPU与GPU并不是专用AI芯片,其内部有大量其他逻辑来实现其他功能,这些逻辑对于目前的AI算法来说完全无用。目前经过专门针对AI算法做过开发的GPU应用较多,也有部分企业用FPGA做开发,但是行业内对于AI算法必然出现专用AI芯片。
3、为什么要用AI芯片?
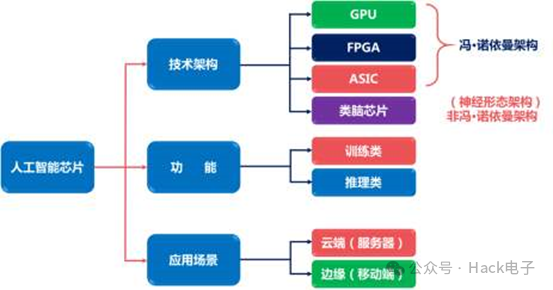
人工智能从功能上来看包括推理和训练两个环节,智能驾驶行业亦然。在训练环节,通过大数据训练出一个复杂的神经网络模型,目前大部分企业在训练环节主要使用英伟达的GPU集群完成。推理环节是指利用训练好的模型,使用大量数据推理出各种结论。因此,训练环节对芯片的算力性能要求比较高,推理环节对简单指定的重复计算和低延迟的要求很高。
从应用场景来看,人工智能芯片应用于云端和设备端,在智能驾驶领域同样具备云服务器和车载的各种计算平台或域控制器,在智能驾驶深度学习的训练阶段需要极大的数据量和大量运算,单一处理器无法独立完成,因此训练环节只能在云服务器实现。相对的在设备端即车上,各种ECU、DCU等终端数量庞大,而且需求差异较大。因此,推理环节无法在云端完成,这就要求车上的各种电子单元、硬件计算平台或域控制器有独立的推理计算能力,因此必须要有专用的AI芯片来应对这些推理计算需求。
传统的CPU、GPU都可以拿来执行AI算法,但是速度慢,性能低,尤其是CPU,在智能驾驶领域无法实际投入商用。
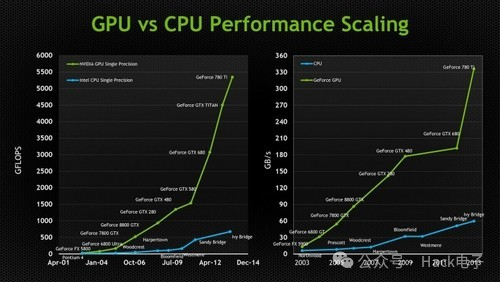
比如,自动驾驶需要识别道路、行人、红绿灯等路况和交通状况,这在自动驾驶算法里面都是属于并行计算,如果是CPU去执行计算,那么估计车撞到人了也没算出来个结果,CPU并行计算速度慢属于先天不足。如果用GPU速度要快得多,毕竟GPU专为图像处理并行计算设计,但是GPU功耗过大,汽车的电池无法长时间支撑正常使用,而且GPU价格相对较高,用于自动驾驶量产的话普通消费者也用不起。另外,GPU因为不是专门针对AI算法开发的ASIC,执行AI计算的速度优势还没到极限,还有提升空间。
在智能驾驶这样的领域,环境感知、物体识别等深度学习应用要求计算响应方面必须快!时间就是生命,慢一步就有可能造成无法挽回的情况,但是保证性能快效率高的同时,功耗不能过高,不能对智能汽车的续航里程造成较大影响,也就是AI芯片必须功耗低,所以GPU不是适合智能驾驶的最佳AI芯片选择。因此开发ASIC就成了必然。
4、AI芯片的种类
当前主流的AI芯片主要分为三类,GPU、FPGA、ASIC。GPU、FPGA均是前期较为成熟的芯片架构,属于通用型芯片。ASIC属于为AI特定场景定制的芯片。行业内已经确认CPU不适用于AI计算,但是在AI应用领域也是必不可少,另外一种说法是还有一种类脑芯片,算是ASIC的一种。
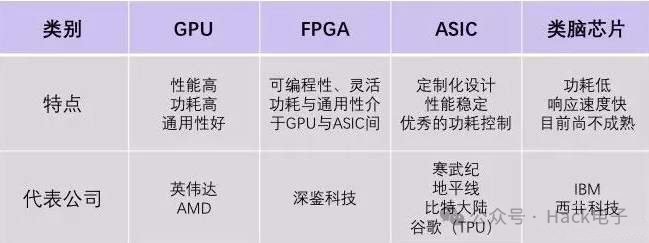
FPGA(Field Programmable Gate Array,现场可编程门阵列)具有足够的计算能力和足够的灵活性。FPGA的计算速度快是源于它本质上是无指令、无需共享内存的体系结构。对于保存状态的需求,FPGA中的寄存器和片上内存(BRAM)是属于各自的控制逻辑的,无需不必要的仲裁和缓存,因此FPGA在运算速度足够快,优于GPU。同时FPGA也是一种半定制的硬件,通过编程可定义其中的单元配置和链接架构进行计算,因此具有较强的灵活性。相对于GPU,FPGA能管理能运算,但是相对开发周期长,复杂算法开发难度大。
ASIC(Application Specific Integrated Circuit特定用途集成电路)根据产品的需求进行特定设计和制造的集成电路,能够在特定功能上进行强化,具有更高的处理速度和更低的能耗。缺点是研发成本高,前期研发投入周期长,且由于是定制化,可复制性一般,因此只有用量足够大时才能够分摊前期投入,降低成本。
4.1 CPU (CentralProcessing Unit)
中央处理器作为计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元,CPU 是对计算机的所有硬件资源(如存储器、输入输出单元) 进行控制调配、执行通用运算的核心硬件单元。
优点:CPU有大量的缓存和复杂的逻辑控制单元,非常擅长逻辑控制、串行的运算
缺点:不擅长复杂算法运算和处理并行重复的操作。
对于AI芯片来说,算力最弱的是cpu。虽然cpu主频最高,但是单颗也就8核,16核的样子,一个核3.5g,16核也就56g,再考虑指令周期,每秒最多也就30g次乘法。还是定点的。
生产厂商:intel、AMD
4.2 GPU (GraphicsProcessing Unit)
图形处理器,又称显示核心、视觉处理器、显示芯片,是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上做图像和图形相关运算工作的微处理器。
优点:提供了多核并行计算的基础结构,且核心数非常多,可以支撑大量数据的并行计算,拥有更高的浮点运算能力。
缺点:管理控制能力(最弱),功耗(最高)。
生产厂商:AMD、NVIDIA

4.3 FPGA(Field Programmable Gate Array)
FPGA是在PAL、GAL等可编程器件的基础上进一步发展的产物。它是作为专用集成电路(ASIC)领域中的一种半定制电路而出现的,既解决了定制电路的不足,又克服了原有可编程器件门电路数有限的缺点。
优点:可以无限次编程,延时性比较低,同时拥有流水线并行和数据并行(GPU只有数据并行)、实时性最强、灵活性最高
缺点:开发难度大、只适合定点运算、价格比较昂贵
生产厂商:Altera(Intel收购)、Xilinx
4.4 ASIC(Application Specific IntegratedCircuit)
ASIC,即专用集成电路,指应特定用户要求和特定电子系统的需要而设计、制造的集成电路。目前用CPLD(复杂可编程逻辑器件)和 FPGA(现场可编程逻辑阵列)来进行ASIC设计是最为流行的方式之一。
优点:它作为集成电路技术与特定用户的整机或系统技术紧密结合的产物,与通用集成电路相比具有体积更小、重量更轻、 功耗更低、可靠性提高、性能提高、保密性增强、成本降低等优点。
缺点:灵活性不够,成本比FPGA贵
主要性能指标:功耗、速度、成本
生产厂商:谷歌、地平线、寒武纪等

4.5 四种芯片的特性总结
CPU是一个有多种功能的优秀领导者。它的优点在于调度、管理、协调能力强,计算能力则位于其次。而GPU相当于一个接受CPU调度的“拥有大量计算能力”的员工。
GPU 作为图像处理器,设计初衷是为了应对图像处理中需要大规模并行计算。因此,其在应用于深度学习算法时,有三个方面的局限性:
第一,应用过程中无法充分发挥并行计算优势。深度学习包含训练和应用两个计算环节,GPU 在深度学习算法训练上非常高效,但在应用时一次性只能对于一张输入图像进行处理,并行度的优势不能完全发挥。
第二,硬件结构固定不具备可编程性。深度学习算法还未完全稳定,若深度学习算法发生大的变化,GPU 无法像FPGA 一样可以灵活的配置硬件结构。
第三,运行深度学习算法能效远低于FPGA。学术界和产业界研究已经证明,运行深度学习算法中实现同样的性能,GPU 所需功耗远大于FPGA,例如国内初创企业深鉴科技基于FPGA 平台的人工智能芯片在同样开发周期内相对GPU 能效有一个数量级的提升。
FPGA,其设计初衷是为了实现半定制芯片的功能,即硬件结构可根据需要实时配置灵活改变。
研究报告显示,目前的FPGA市场由Xilinx 和Altera 主导,两者共同占有85%的市场份额,其中Altera 在2015 年被intel以167 亿美元收购, Xilinx则选择与IBM进行深度合作,背后都体现了 FPGA 在人工智能时代的重要地位。
尽管 FPGA 倍受看好,甚至百度大脑、地平线AI芯片也是基于FPGA 平台研发,但其毕竟不是专门为了适用深度学习算法而研发,实际仍然存在不少局限:
第一,基本单元的计算能力有限。为了实现可重构特性,FPGA 内部有大量极细粒度的基本单元,但是每个单元的计算能力(主要依靠LUT 查找表)都远远低于CPU 和GPU中的ALU模块。
第二,速度和功耗相对专用定制芯片(ASIC)仍然存在不小差距。
第三,FPGA 价格较为昂贵,在规模放量的情况下单块FPGA 的成本要远高于专用定制芯片。
人工智能定制芯片是大趋势,从发展趋势上看,人工智能定制芯片将是计算芯片发展的大方向。
5、AI芯片算力对比
5.1 通用芯片—GPU
GPU(Graphics Processing Unit)即为图形处理器。NVIDIA公司在1999年发布GeForce256图形处理芯片时首先提出GPU的概念。从此NVIDIA显卡的芯就用这个新名字GPU来称呼。GPU使显卡削减了对CPU的依赖,部分替代原本CPU的工作,特别是在3D图形处理方面。由于在浮点运算、并行计算等方面,GPU可以提供数十倍乃至于上百倍于CPU的性能。
GPU相比CPU更适合人工智能计算。GPU和CPU分别针对的是两种不同的应用场景,他们的设计目标不同,CPU需要很强的通用性来处理各种不同的数据类型,同时逻辑判断又会引入大量的分支跳转和中断的处理。这些都使得CPU的内部结构异常复杂。而GPU擅长的则是在不需要被打断的纯净的计算环境中进行类型高度统一的、相互无依赖的大规模数据处理,人工智能的计算恰巧主要是后者,这使得原本为图像处理而生的GPU在人工智能时代焕发第二春。
CPU的逻辑运算单元(ALU)较少,控制器(control)占比较大;GPU的逻辑运算单元(ALU)小而多,控制器功能简单,缓存(cache)也较少。架构的不同使得CPU擅长进行逻辑控制、串行计算,而GPU擅长高强度的并行计算。GPU单个运算单元处理能力弱于CPU的ALU,但是数量众多的运算单元可以同时工作,当面对高强度并行计算时,其性能要优于CPU。现如今GPU除了图像处理外,也越来越多的运用到别的计算中。
CPU根据功能划分,将需要大量并行计算的任务分配给GPU。GPU从CPU获得指令后,把大规模、无结构化的数据分解成许多独立部分,分配给各个流处理集群(SMM)。每个流处理集群再次把数据分解,分配给调度器,调度器将任务放入自身所控制的计算核心core中完成最终的数据处理任务。
GPU性能较强但功耗较高。以NVIDIA开发的GPU为例,Xavier最高算力为30Tops,功耗为30W,NVIDIA最新发布的GPUA100相比Volta架构的640个Tensor Core,A100核心的TensorCore减少到了432个,但是性能大幅增强,支持全新的TF32运算,浮点性能156TFLOPS,同时INT8浮点性能624TOPS,FP16性能312TFLOPS,同时功耗也达到了400W。
5.2 半定制化芯片—FPGA
FPGA(Field-ProgrammableGate Array),即现场可编程门阵列。它是在PAL、GAL、CPLD等可编程器件的基础上进一步发展的产物。它是作为专用集成电路(ASIC)领域中的一种半定制电路而出现的,既解决了定制电路的不足,又克服了原有可编程器件门电路数有限的缺点。
FPGA内部有很多可配置逻辑模块(CLB),这些模块是现实逻辑功能的基本单元,FPGA可通过灵活地配置CLB来令其实现工程师想要实现的逻辑功能。FPGA的并行处理能力也很强大,其可编程性也适用于不断优化的深度学习算法的运算。目前很多公司基于FPGA开发人工智能处理器。于2016年成立的深鉴科技,就在研发深度学习通用解决方案。2016年初,深鉴科技就设计了基于FPGA、针对深度学习的DPU硬件架构。该产品实现了高性能功耗比,并且成本也比GPU产品低很多。今年8月加州的Hot Chips大会上,百度也发布了其基于FPGA芯片的A.I加速芯片—XPU。该芯片有256核,旨在寻求性能和效率的平衡,处理多样化计算任务。
基于FPGA开发的人工智能处理器具有高性能、低能耗、可硬件编程的特点。
1)高性能
除了GPU,FPGA也擅长并行计算,基于FPGA开发的处理器可以实现更高的并行计算。而且FPGA带有丰富的片上存储资源,可以大大减少访问片外存储的延迟,提高计算性能,访问DRAM储存大约是访问寄存器存储延迟的几百倍以上。
2)低能耗
相比于CPU和GPU,FPGA的能耗优势主要有两个原因:1)相比于CPU、GPU,FPGA架构有一定的优化,CPU、GPU需要频繁的访问DRAM,而这个能量消耗较大,FPGA可以减少这方面的能耗。2)FPGA的主频低,CPU和GPU的主频一般在1-3GHz之间,而FPGA的主频一般在500MHz一下。因此,FPGA的能耗要低于CPU、GPU。
3)可硬件编程
FPGA可硬件编程,并且可以进行静态重复编程和动态系统重配置。用户可像编程修改软件一样修改系统的硬件功能,大大增强了系统设计的灵活性和通用性。使得FPGA可以灵活地部署在需要修改硬件设置场景中。
FPGA+CPU异构架构被越来越多地研究和认可。相比于CPU+GPU,因为FPGA的高性能低功耗等优势使FPGA+CPU可以提供更好的单位功耗性能,且更易于修改和编程。因此FPGA适合做可并行计算的任务,如矩阵运算。如果是一些判断类的问题,FPGA算得并没有CPU快。所以已经有研究人员探讨FPGA+CPU的架构模式。
5.3 全定制芯片—ASIC
ASIC(Application Specific IntegratedCircuit)在集成电路界被认为是一种为专门目的而设计的集成电路。是指应特定用户要求和特定电子系统的需要而设计、制造的集成电路。ASIC的特点是面向特定用户的需求,ASIC在批量生产时与通用集成电路相比具有体积更小、功耗更低、可靠性提高、性能提高、保密性增强、成本降低等优点。简单地讲,ASIC芯片就是通过台积电等代工厂流片的芯片。目前,基于ASIC的人工智能芯片有地平线BPU、谷歌的TPU。
基于ASIC开发人工智能芯片开发周期较长。基于ASIC开发人工智能芯片更像是电路设计,需要反复优化,需要经历较长的流片周期,故开发周期较长。
量产后ASIC人工智能芯片成本及价格较低。虽然相较于FPGA, ASIC人工智能芯片需要经历较长的开发周期,并且需要价格昂贵的流片投入,但是这些前期开发投入在量产后会被摊薄,所以量产后,ASIC人工智能芯片的成本和价格会低于FPGA人工智能芯片。
ASIC芯片性能功耗比较高。从性能功耗比来看,ASIC作为定制芯片,其性能要比基于通用芯片FPGA开发出的各种半定制人工智能芯片更具有优势。而且ASIC也并不是完全不具备可配置能力,只是没有FPGA那么灵活,只要在设计的时候把电路做成某些参数可调即可。
ASIC人工智能芯片主要面向消费电子市场。ASIC更高的性能,更低的量产成本以及有限可配置特性,使其主要面向消费电子市场,如寒武纪等公司。
5.4 类脑芯片
类人脑芯片架构是一款基于神经形态的工程,旨在打破“冯·诺依曼”架构的束缚,模拟人脑处理过程,感知世界、处理问题。这种芯片的功能类似于大脑的神经突触,处理器类似于神经元,而其通讯系统类似于神经纤维,可以允许开发者为类人脑芯片设计应用程序。通过这种神经元网络系统,计算机可以感知、记忆和处理大量不同的信息。类脑芯片的两大突破:1、有望形成自主认知的新形式;2、突破传统计算机体系结构的限制,实现数据并行传送、分布式处理,能以极低功耗实时处理大量数据。
6、总结
CPU 有强大的调度、管理、协调能力。应用范围广。开发方便且灵活。但其在大量数据处理上没有 GPU 专业,相对运算量低,但功耗不低。
GPU:是单指令、多数据处理,采用数量众多的计算单元和超长的流水线,如名字一样,图形处理器,GPU善于处理图像领域的运算加速。但GPU无法单独工作,必须由CPU进行控制调用才能工作。CPU可单独作用,处理复杂的逻辑运算和不同的数据类型,但当需要大量的处理类型统一的数据时,则可调用GPU进行并行计算。
FPGA:和GPU相反,FPGA适用于多指令,单数据流的分析,因此常用于预测阶段,如云端。FPGA是用硬件实现软件算法,因此在实现复杂算法方面有一定的难度,缺点是价格比较高。将FPGA和GPU对比发现,一是缺少内存和控制所带来的存储和读取部分,速度更快。二是因为缺少读取的作用,所以功耗低,劣势是运算量并不是很大。结合CPU和GPU各自的优势,有一种解决方案就是异构。
ASIC芯片:是专用定制芯片,为实现特定要求而定制的芯片。除了不能扩展以外,在功耗、可靠性、体积方面都有优势,尤其在高性能、低功耗的移动端。谷歌的TPU、寒武纪的MLU,地平线的BPU都属于ASIC芯片。谷歌的TPU比CPU和GPU的方案快30-80倍,与CPU和GPU相比,TPU把控制缩小了,因此减少了芯片的面积,降低了功耗。
四种架构将走向哪里?
众所周知,通用处理器(CPU)的摩尔定律已入暮年,而机器学习和Web 服务的规模却在指数级增长。
人们使用定制硬件来加速常见的计算任务,然而日新月异的行业又要求这些定制的硬件可被重新编程来执行新类型的计算任务。
将以上四种架构对比,GPU未来的主攻方向是高级复杂算法和通用性人工智能平台,其发展路线分两条走:一是主攻高端算法的实现,对于指令的逻辑性控制要更复杂一些,在面向需求通用的AI计算方面具有优势;二是主攻通用性人工智能平台,GPU的通用性强,所以应用于大型人工智能平台可高效完成不同的需求。FPGA更适用于各种细分的行业,人工智能会应用到各个细分领域。
ASIC芯片是全定制芯片,长远看适用于人工智能。现在很多做AI算法的企业也是从这个点切入。因为算法复杂度越强,越需要一套专用的芯片架构与其进行对应,ASIC基于人工智能算法进行定制,其发展前景看好。类脑芯片是人工智能最终的发展模式,但是离产业化还很遥远。
几个品牌的SOC及域控制器做的还是不错的,尤其是基于NVIDIA Xavier以及前期PX2等芯片的开发。国内大部分企业的应用比较集中在Xavier平台和Linux系统,尤其是新势力造车企业,而传统车企更青睐TI、瑞萨等半导体公司的智能AI芯片以及QNX系统。国内基于Xavier做开发的企业很多,天津优控智行目前的域控制器产品在行业内属于中等偏上水平,但是其软件工具和服务做得相对有些优势,后期有时间也扒一扒地平线、智行者等企业的域控制器学习学习。

想要了解FPGA吗?这里有实例分享,ZYNQ设计,关注我们的公众号,探索

