
热门标签
热门文章
- 1探索AI人才培养新范式,合合信息与同济大学软件学院签署产教融合人才培养协议
- 2数据结构——链表(C语言实现)_严蔚敏 数据结构 c语言代码 线性链表
- 3动态规划课堂5-----子序列问题(动态规划 + 哈希表)_子序列:是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺
- 4基于springboot实现秒杀系统项目【项目源码+论文说明】计算机毕业设计_基于springbiit的房产销售系统论文
- 5【已拿offer】最新AI产品经理大厂面经(含百度&腾讯&科大讯飞&商汤&蚂蚁金服)_商汤pk科大讯飞
- 6数字抽取滤波(一)
- 7基于小程序和SSM实现智能推荐的电影推荐_ssm框架 + 推荐算法 具体实现
- 8unity3D 插件plugins_managed plugins
- 9Linux安装Mysql详细教程(两种安装方法)_linux 安装mysql
- 10swift 3d v6.0汉化中文版_swift 3d软件
当前位置: article > 正文
机器学习-深度学习_先用adam再用sgd可以吗
作者:码创造者 | 2024-07-15 13:14:47
赞
踩
先用adam再用sgd可以吗
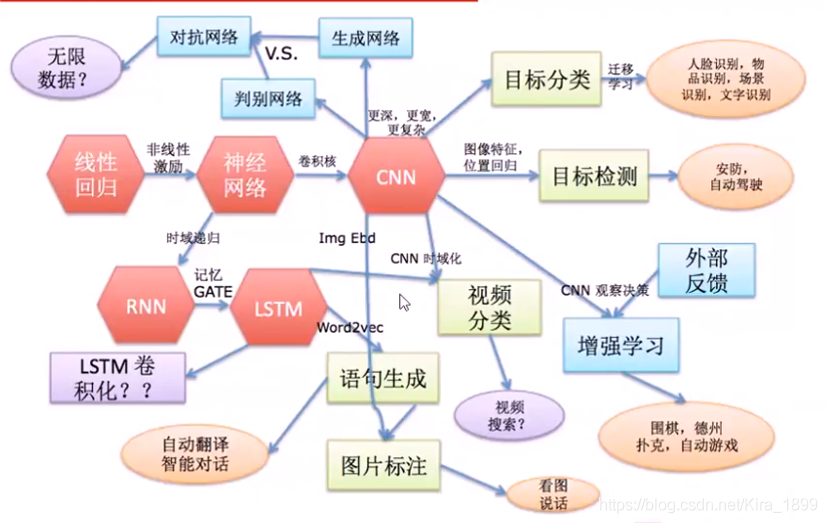
1、深度学习知识架构
2、线性回归
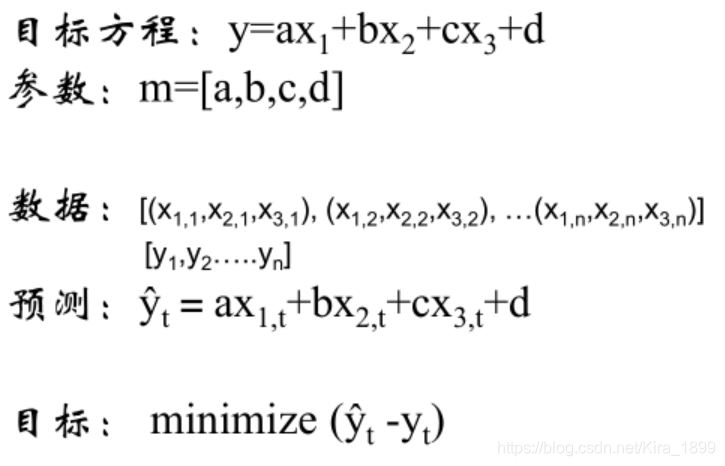
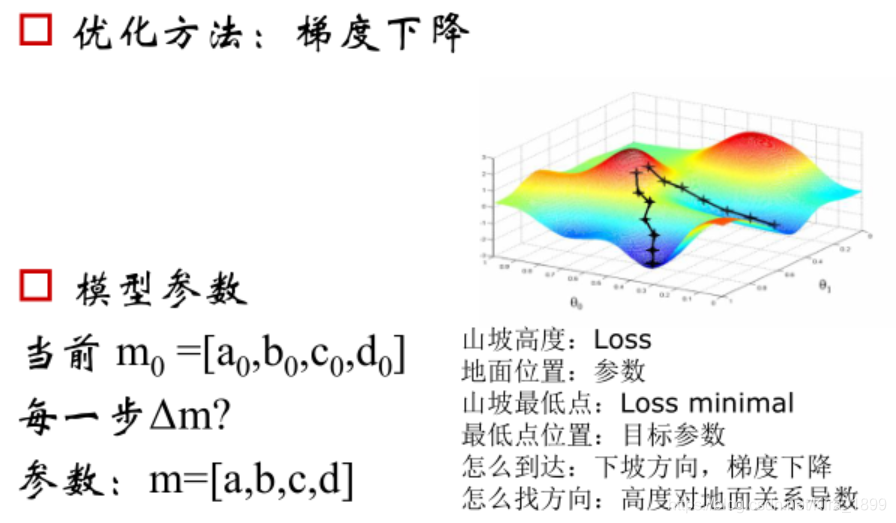
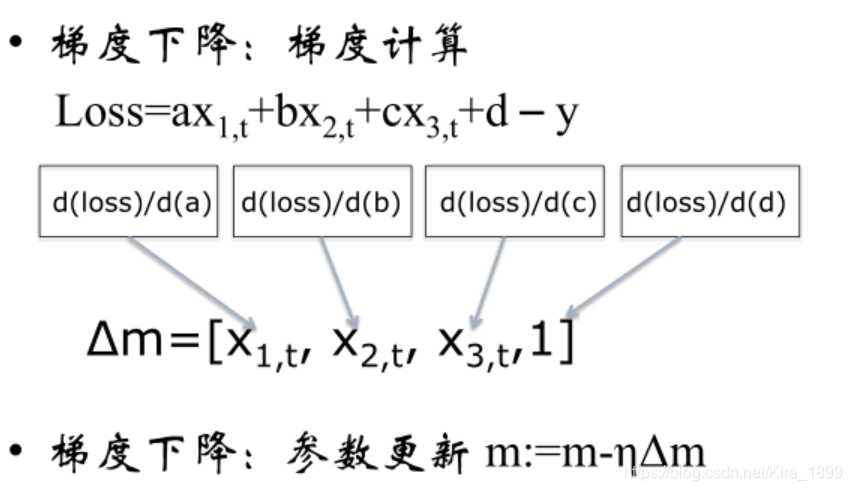

能够同时预测多个目标,进行多目标学习,通过合并多个任务loss,一般能够产生比单个模型更好的效果。线性回归能够清楚的描述分割线性分布的数据,对非线性分布的数据描述较弱。
3、从线性到非线性-非线性激励
常用的非线性激励函数:
(1)Sigmoid
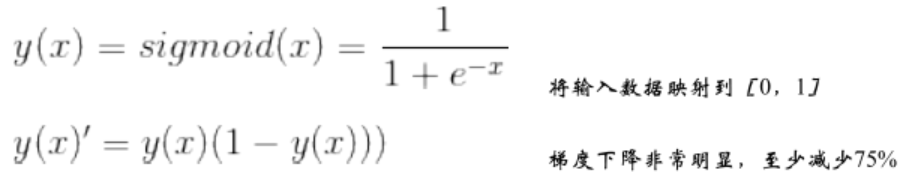
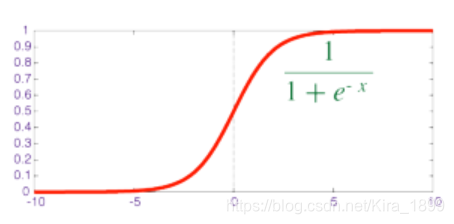
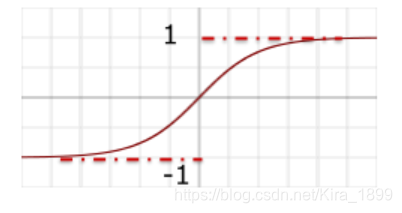
(2)tahn
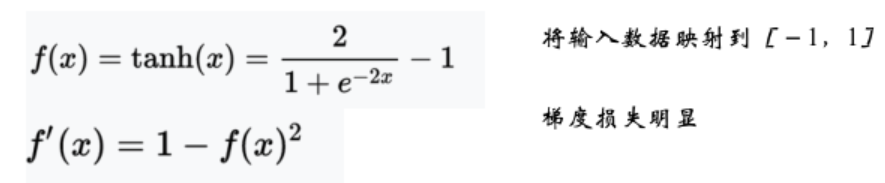
(3)ReLU(Rectified Linear Units)线性整流函数,又称修正线性单元, 是一种人工神经网络中常用的激活函数(activation function),通常指代以斜坡函数及其变种为代表的非线性函数。

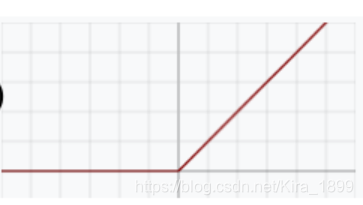

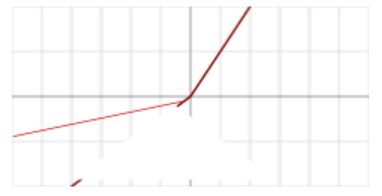
(4)Leaky ReLU 带泄露整流函数
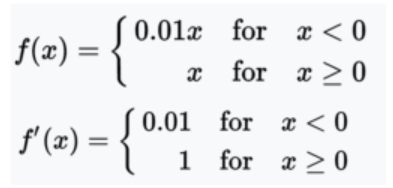
4、神经元-神经网络
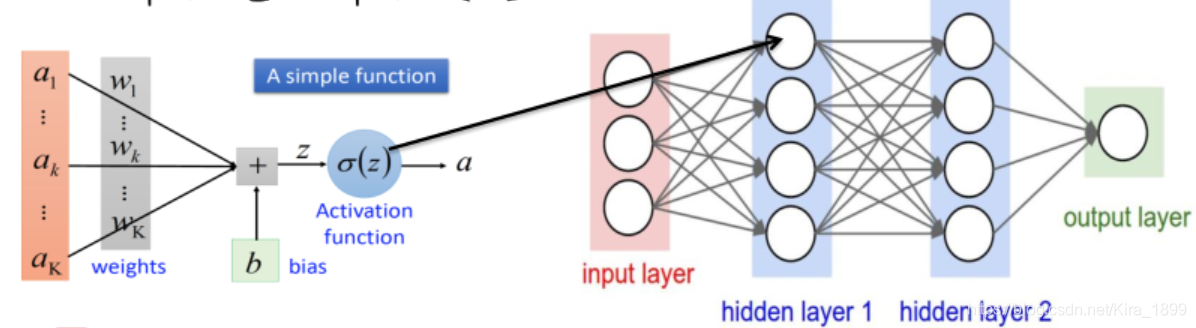
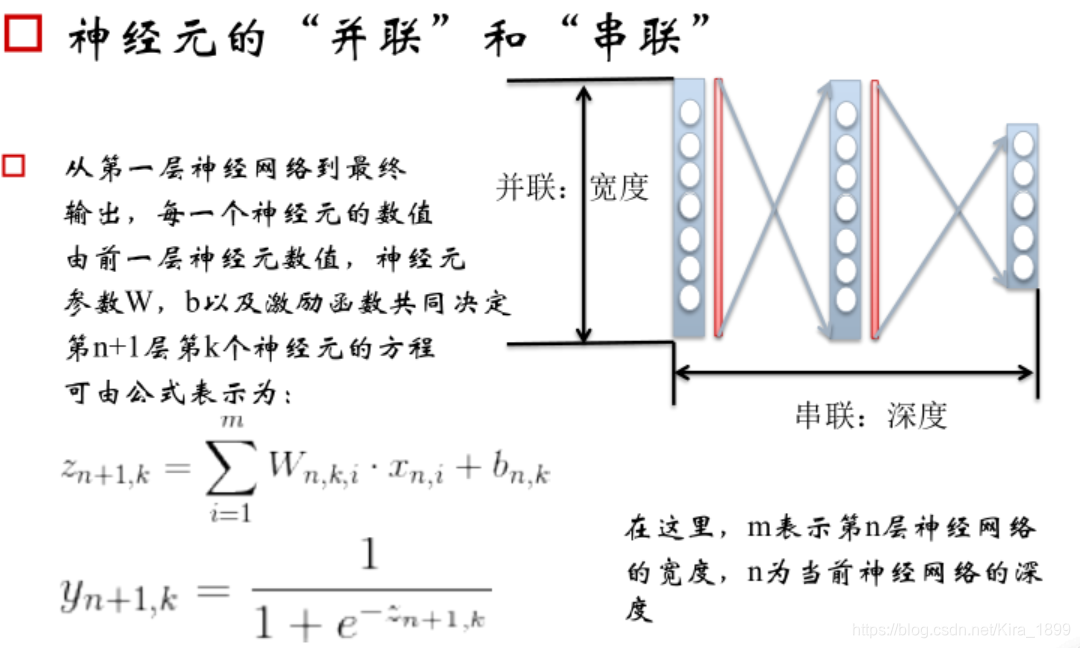
5、神经网络的”配件“
(1)损失函数(Softmax:使分类问题的预测结果更明显;Cross entropy:处理目标为[0,1]区间的回归问题,以及生成)
(2)学习率(数值大:收敛速度快,数值小:精度高)
如何选用合适的学习率步骤:1.Fixed 2.Step 3.Adagrad 4.RMSprop
(3)动量
正常:x += -learning_rate * dx
另一种:v = mu * v - learning_rate * dx
(4)过拟合
预测的结果好与不好,要看两个因素:bias和variance,如果bias大,variance小,欠拟合;如果bias小,variance大,过拟合;最好结果是bias和variance都小。
过拟合-应对:
①Regularization
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/码创造者/article/detail/829540
推荐阅读


相关标签

