
- 1python调用opencv做简单的dhash_python numpy dhash
- 2蓝桥杯备赛 | 洛谷做题打卡day4
- 3测试用例编写规范
- 4从零开始的Java RASP实现(一)_manifest配置can-redefine-classes
- 5[大模型]DeepSeek-MoE-16b-chat Transformers 部署调用_deepseek本地部署
- 6Python实现word转pdf_使用python将word文档转换为pdf
- 7Docker换源完整步骤:Docker 阿里云的镜像源最新地址为:registry.cn-hangzhou.aliyuncs.com_docker 阿里云镜像源
- 8信创基础软件之信创云介绍_信创软件
- 9防火墙介绍及使用思科模拟器模拟
- 10用于序列建模的深度学习:使用 Tensorflow 生成文本_python tensorflow生成自然文本
Mamba为什么能颠覆Transformer在计算机视觉的统治地位?
赞
踩
点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
添加小助理:dddvision,备注:方向+学校/公司+昵称,拉你入群。文末附行业细分群
扫描下方二维码,加入3D视觉知识星球,星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:近20门视频课程(星球成员免费学习)、最新顶会论文、计算机视觉书籍、优质3D视觉算法源码等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

0. 引言
深度神经网络(DNNs)已经在各种人工智能(AI)任务中展现出了显著的性能,而基本架构在确定模型能力方面起着至关重要的作用。传统神经网络通常包括多层感知器(MLP)或全连接(FC)层。卷积神经网络(CNNs)引入了卷积和池化层,特别适用于处理像图像这样的平移不变数据。循环神经网络(RNNs)利用循环单元处理顺序或时间序列数据。为了解决CNN、RNN和GNN模型仅捕获局部关系的问题,Transformer于2017年提出,在学习远距离特征表示方面表现出色。Transformer主要依赖于基于注意力的注意力机制,例如自注意力和交叉注意力,来提取内在特征并改善其表示能力。例如GPT-3这样的预训练大规模基于Transformer的模型在各种NLP数据集上表现出色,擅长自然语言理解和生成任务。Transformer基于模型在视觉应用中的广泛采用推动了其出色性能。Transformer模型的核心是其在捕获长距离依赖关系和最大化大型数据集利用方面的非凡技能。特征提取模块是视觉Transformer架构的主要组成部分。它使用一系列的自注意力块来处理数据,显著提高了其分析图像的能力。
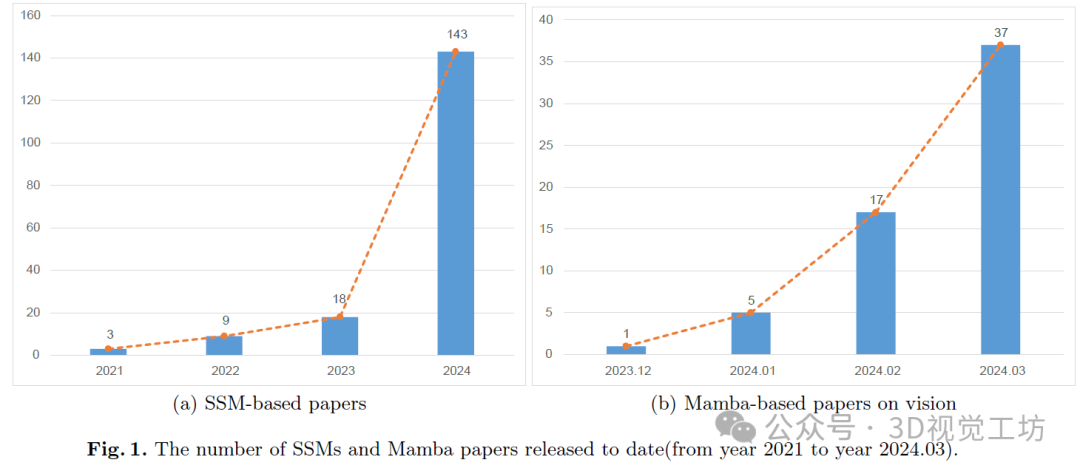
然而,Transformer的一个主要障碍是自注意力机制的巨大计算需求,随着图像分辨率的增加呈二次增加。注意力块内的Softmax运算进一步加剧了计算需求,给在边缘和低资源设备上实现这些模型带来了重大挑战。此外,利用基于Transformer的实时计算机视觉系统必须遵循严格的低延迟标准,以保持高质量的用户体验。这种情况突显了新架构的持续演变以提高性能,尽管这往往伴随着更高的计算需求的权衡。许多基于稀疏注意机制或创新的神经网络范式的新模型已被提出,以进一步降低计算成本,同时捕获长距离依赖关系并保持高性能。状态空间模型(SSMs)已经成为这些发展的中心关注点。如图1(a)所示,与SSMs相关的出版物数量呈现出爆炸性增长趋势。最初设计用于模拟诸如控制理论和计算神经科学等领域中的动态系统,使用状态变量,当为深度学习适应时,SSMs主要描述线性不变(或稳定)系统。随着SSMs的发展,一种名为Mamba的新型选择性状态空间模型已经出现。它通过两个关键改进提高了对离散数据(例如文本)的状态空间模型(SSMs)的建模。首先,它具有一个根据输入调整SSM参数的机制,动态增强信息过滤。其次,Mamba使用一种硬件感知算法,根据序列长度线性处理数据,提高了在现代系统上的计算速度。受Mamba在语言建模中的成就启发,现在有几个倡议旨在将这一成功适应到视觉领域。许多研究已经探讨了其与Mixture-of-Experts(MoE)技术的集成,如Jamba、MoE-Mamba和BlackMamba,以较少的训练步骤超越了现有技术架构Transformer-MoE。正如图1(b)所示,自从2023年12月发布Mamba以来,专注于视觉领域的Mamba的研究论文数量迅速增加,于2024年3月达到高峰。这一趋势表明,Mamba正在成为视觉中一个突出的研究领域,可能为Transformer提供了一种可行的替代方案。因此,对当前相关工作进行回顾是必要且及时的,以提供对这个不断发展的领域中这种新方法的详细概述。因此,我们提供了对Mamba模型在视觉领域中的使用方式的全面概述。本文旨在为希望深入探讨这一领域的研究人员提供指南。
我们的工作的关键贡献包括:
(1)本调查论文是首次对视觉领域中的Mamba技术进行全面回顾,明确关注分析提出的策略。
(2)在基于Naive的Mamba视觉框架的基础上进行了扩展,我们调查了如何增强Mamba的能力,并与其他架构结合以实现更高性能。
(3)我们通过根据各种应用任务组织文献进行了深入探讨。我们建立了一个分类法,确定了针对每个任务的特定进展,并就克服挑战提供了见解。
综述的结构如下:第2节探讨了Mamba策略的一般和数学概念。第3节讨论了Naive Mamba视觉模型以及它们如何与其他技术集成以增强性能,这是近年来提出的。第4节探讨了Mamba技术在解决各种计算机视觉任务中的应用。最后,第5节总结了调查。
1. 论文信息
标题:A Survey on Visual Mamba
作者:Hanwei Zhang, Ying Zhu, Dan Wang, Lijun Zhang, Tianxiang Chen, Zi Ye
机构:汽车软件创新中心、中国科学院大学、中国科学技术大学、智能软件研究所、萨尔州大学
原文链接:https://arxiv.org/abs/2404.15956
2. 摘要
具有选择机制和硬件感知体系结构的状态空间模型(SSMs),即Mamba,最近在长序列建模方面表现出显著的潜力。由于Transformer中的自注意机制随着图像大小的增加而呈二次复杂度,并且计算需求增加,研究人员现在正在探索如何调整Mamba以用于计算机视觉任务。本文是第一篇旨在对计算机视觉领域的Mamba模型进行深入分析的综述。它首先探讨了对Mamba成功起到贡献的基本概念,包括状态空间模型框架、选择机制和硬件感知设计。接下来,我们通过将这些视觉mamba模型分类为基础模型,并使用诸如卷积、循环和注意力等技术对其进行增强,来审查这些视觉mamba模型,以提高其复杂性。我们进一步深入探讨了Mamba在视觉任务中的广泛应用,其中包括将它们用作各种级别视觉处理的骨干。这包括一般视觉任务、医学视觉任务(例如2D / 3D分割、分类和图像配准等)以及遥感视觉任务。我们特别从两个层面介绍了一般视觉任务:高/中级视觉(例如对象检测、分割、视频分类等)和低级视觉(例如图像超分辨率、图像恢复、视觉生成等)。我们希望这一努力将激发社区内的额外兴趣,以解决当前的挑战,并进一步将Mamba模型应用于计算机视觉领域。
3. Mamba基本架构
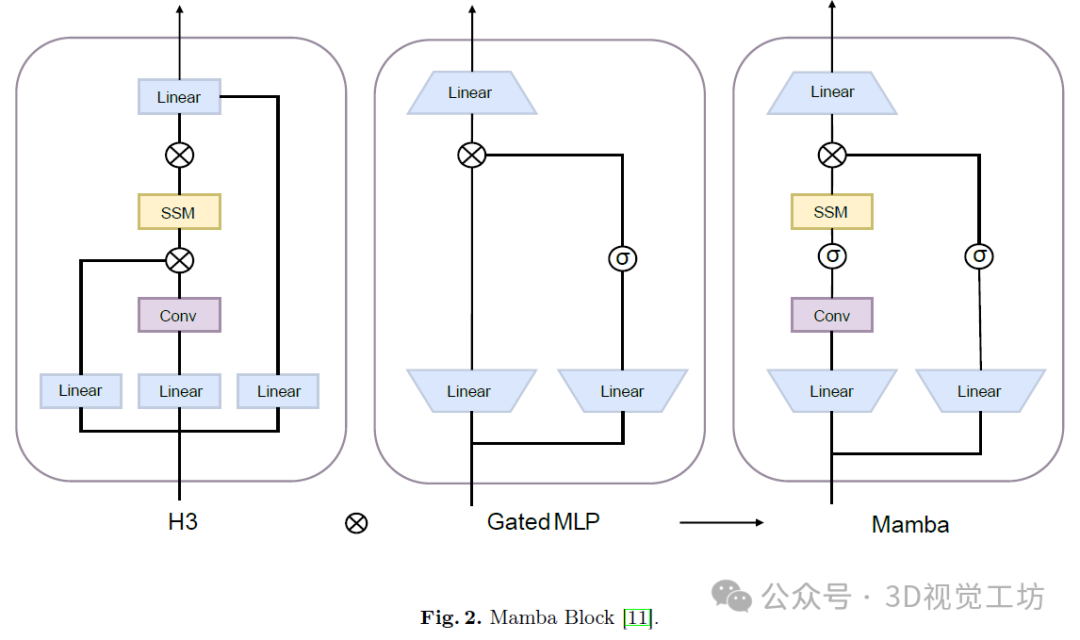
SSMs通常作为独立的序列转换,可以集成到端到端的神经网络体系结构中。这里我们介绍几种基本的体系结构。线性注意力用循环机制近似自注意力,作为线性SSM的简化形式。H3,如图2所示,在两个门控连接之间放置了一个SSM,并在其前插入了一个标准的局部卷积。在H3之后,Hyena,用MLP参数化的全局卷积替换了SSM层。RetNet引入了额外的门,并使用更简单的SSM。RetNet启用了一条替代的可并行化计算路径,并使用多头注意力(MHA)的变体,而不是卷积。受无注意力Transformer的启发,最近的RNN设计RWKV,可以解释为两个SSMs的比率,因为它的主要"WKV"机制涉及线性时间不变性(LTI)的循环。
4. 视觉Mamba
原始的Mamba块设计用于一维序列,然而与视觉相关的任务需要处理多维输入,如图像、视频和三维表示。因此,为了使Mamba适应这些任务,改进Mamba块的扫描机制和架构对于有效处理多维输入至关重要。
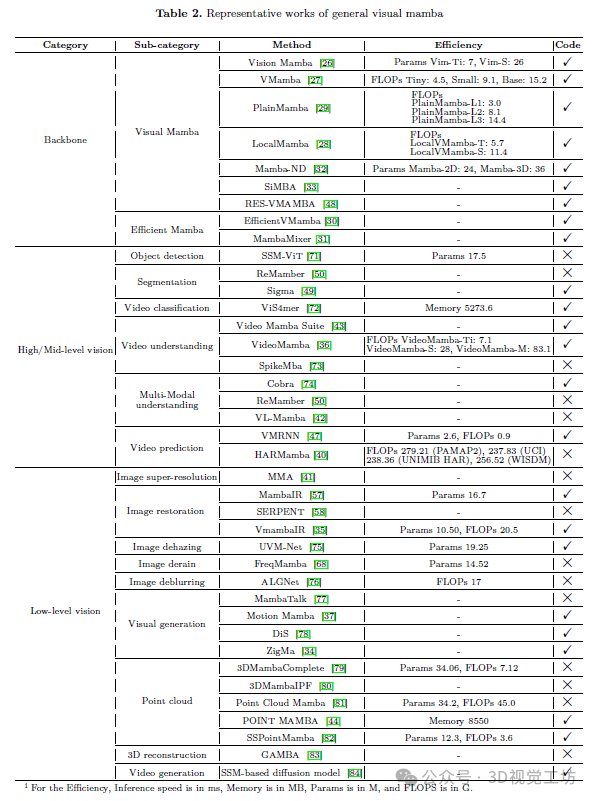
在本节中,我们提出了使Mamba能够处理与视觉相关任务并增强其效率和性能的努力。最初,我们深入探讨了两个基础性的工作:Vision Mamba和 VMamaba。这些工作分别引入了 ViM 块和 VSS 块,作为后续研究努力的基础。随后,我们探讨了重点放在改进Mamba架构上的其他工作,作为视觉相关任务的骨干。最后,我们讨论了将Mamba与其他架构(如卷积、循环和注意力)集成的工作。
4.1 视觉Mamba块
受视觉Transformer架构启发,保留Transformer模型的框架,同时用Mamba块替换注意力块,保持其余过程不变,似乎是自然而然的。问题的核心在于将Mamba块调整到与视觉相关的任务上。几乎同时,Vision Mamba 和 VMamba 提出了各自的解决方案:ViM 块和 VSS 块。
ViM 块有时也被称为双向Mamba块,使用位置嵌入标注图像序列,并使用双向状态空间模型压缩视觉表示。它同时处理前向和后向的输入,使用单向卷积处理每个方向,如图 4 的(a)所示。
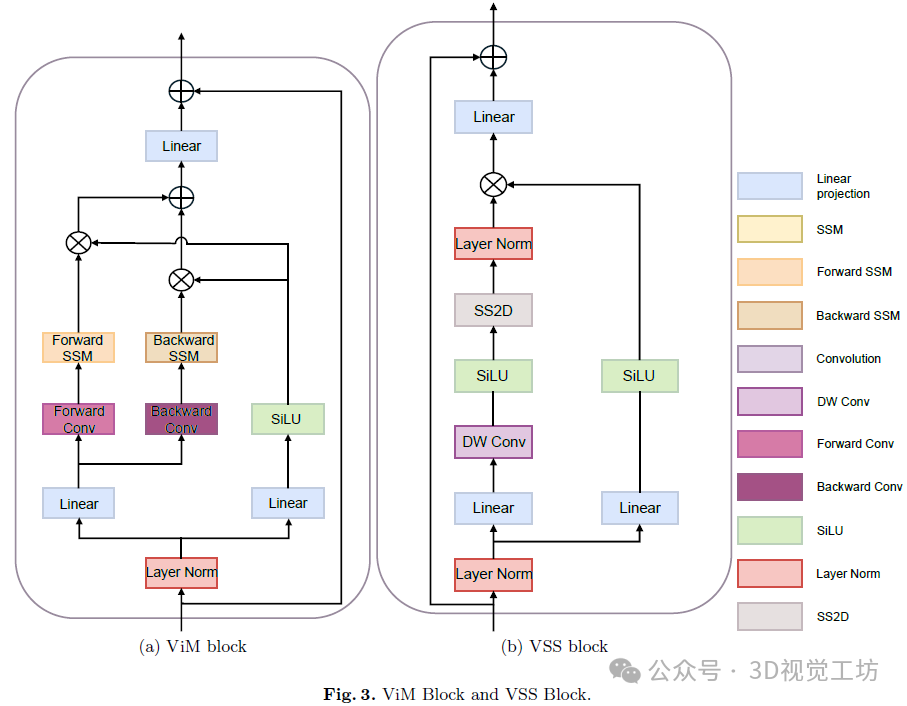

视觉状态空间(VSS)块包含关键的状态空间模型操作。它首先通过深度卷积层引导输入,然后通过 SiLU 激活函数,然后通过状态空间模型使用近似 B。之后,状态空间模型的输出经过层归一化,然后与其他信息流的输出合并,如图 3 的(b)所示。为了解决遇到的方向敏感问题,他们引入了交叉扫描模块(CSM)来遍历空间域,并将任何非因果视觉图像转换为顺序补丁序列,如图 4 的(b)所示。
4.2 纯Mamba
受视觉Transformer架构的启发,Vision Mamba将Transformer编码器替换为基于 ViM 块的视觉Mamba编码器,同时保留其余过程。这包括将二维图像转换为平坦的补丁,然后将这些补丁投影到向量中,并添加位置嵌入。一个类令牌代表整个补丁序列,随后的步骤涉及归一化层和 MLP 层以推导最终的预测。
LocalMamba是基于 ViM 块构建的,它引入了一种包含在不同窗口内进行局部扫描的新颖方法,以捕获详细的局部信息和全局上下文。此外,LocalMamba 在不同网络层之间搜索扫描方向,以识别和应用最有效的扫描组合。他们提出了两种变体,即普通结构和分层结构。他们提出了 LocalVim 块,包括四个扫描方向(参见图 4 的(d)):vim 扫描并将令牌分区到不同的窗口以及它们的翻转对应物,从尾部到头部进行扫描,状态空间模块和空间和通道注意力模块(SCAttn)。
基于 VSS 块,PlainMamba 块通过两种主要机制增强了它从二维图像中学习特征的能力:(i)采用连续的二维扫描过程来改善空间连续性,确保扫描序列中的令牌是相邻的,如图 4 的(c)所示,以及(ii)融合方向感知更新,使模型能够通过编码方向信息来识别令牌之间的空间关系。PlainMamba 通过继续使用相反方向的扫描,直到到达图像的最终视觉令牌,改善了 Vim 和 VMamba 的二维扫描机制中在新行/列移动时的空间不连续性。此外,PlainMamba 消除了特殊令牌的需要。
在轻量级模型设计中,EfficientVMamba通过基于孔径的选择性扫描方法提高了 VMamba 的能力,即 Efficient 2D Scanning(ES2D)。ES2D 采用在垂直和水平方向上前进扫描而跳过补丁并保持补丁数量不变的策略,如图 4 的(e)所示。他们的高效视觉状态空间(EVSS)块包括一个用于局部特征的卷积分支,将 ES2D 用作用于全局特征的 SSM 分支,并且所有分支都通过一个 squeeze-excitation 块结束。他们在阶段 1 和阶段 2 中都采用 EVSS 块,而在阶段 3 和阶段 4 中选择倒置残差块以增强全局表示的捕获。
多维数据作为多维数据的一部分。作为多维数据的一部分,现有的多维数据模型也适用于与视觉相关的任务,但往往缺乏促进跨维度和维内通信或数据无关性的能力。MambaMixer 块引入了跨令牌和通道的双重选择机制。然后,通过加权平均机制连接顺序选择混合器,使层能够直接访问来自各层的输入和输出。Mamba-ND通过在层间交替序列游走来扩展 SSM 的应用到更高维度。利用与 VMamba 相同的二维情景的类似扫描策略,将这种方法扩展到三维。此外,他们倡导使用多头 SSM 作为多头注意力的类比。针对传统Transformer在图像和时间序列处理中遇到的低效率和性能挑战,提出了一种名为简化Mamba基础架构的新架构,SiMBA,以将Mamba块用于序列建模,并将EinFFT用于通道建模,旨在增强模型处理图像和时间序列任务的稳定性和效率。Mamba块在处理长序列数据方面证明是有效的,而 EinFFT 则代表了一种新颖的通道建模技术。实验结果表明,SiMBA 在多个基准测试中超越了现有的状态空间模型和Transformer。
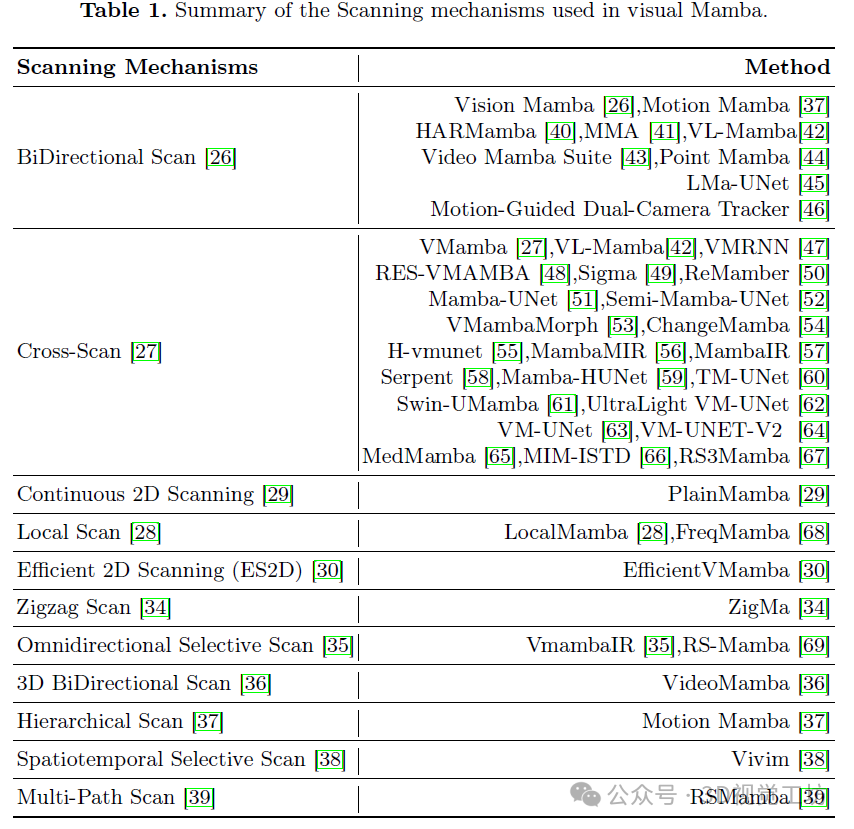
作为Mamba的重要组成部分,扫描机制不仅有助于效率,而且在与视觉相关的任务场景中提供信息。我们总结了现有作品中不同扫描机制的使用情况,如表 1 所示。Cross-Scan和 BiDirectional Scan是最广泛采用的扫描机制。然而,各种其他扫描机制都有特定的用途。例如,3D BiDirectional Scan和 Spatiotemporal Selective Scan针对视频输入进行了定制。Local Scan侧重于收集局部信息,而 ES2D优先考虑效率。
4.3 Mamba与其他架构
为了将Mamba与卷积结合起来,Mamba引入了获得局部信息的能力,这对于与医学图像或分割任务相关的任务至关重要。RES-VMAMBA在 VMamba 模型内引入了一个残差学习框架,以同时利用原始 VMamba 架构设计中固有的全局和局部状态特征。该架构以负责处理输入图像的干扰模块开头,然后是一系列按照四个不同阶段顺序组织的 VSS 块。与原始 VMamba 框架不同,Res-VMamba 架构采用 VMamba 结构作为其骨干,并将原始数据直接整合到特征图中。他们将这种整合称为全局残差机制,以区别于 VSS 块中的残差结构。这种整合旨在促进个别 VSS 块捕获的局部细节和未处理输入中的整体全局特征之间的共享信息,从而增强模型的表征能力,并提高在需要全面理解视觉数据的任务上的性能。
为了利用Mamba块的长序列建模能力和 LSTM 的时空表示能力,VMRNN Cell 消除了 ConvLSTM中的所有权重和偏差,并使用 VSS 块来学习垂直方向的空间依赖性。在 VMRNN Cell 中,通过从水平角度更新单元状态和隐藏状态的信息来捕获长期和短期时间依赖性。在 VMRNN Cell 的基础上,提出了两种变体:VMRNN-B 和 VMRNN-D。VMRNN-B 主要依赖于堆叠 VMRNN 层,而 VMRNN-D 则包含更多的 VMRNN Cells,并引入了 Patch Merging 和 Patch Expanding 层。Patch Merging 层用于下采样,有效减少数据的空间维度,有助于降低计算复杂度并捕获更抽象、全局的特征。相反,补丁扩展层用于上采样,增加空间维度以恢复细节,并在重构阶段中实现对特征的精确定位。最终,重构层接收来自 VMRNN 层的隐藏状态,并将其缩放回输入大小,生成下一个时间步的预测帧。整合下采样和上采样过程在我们的预测架构中具有重要优势。下采样简化了输入表示,使模型能够以较低的计算开销处理更高级别的特征。这对于更抽象地理解数据内部的复杂模式和关系特别有利。
SSM-ViT 块用于有效地处理基于事件的信息。它包括三个主要组件:自注意力块(Block-SA)、扩张注意力块(Grid-SA)和 SSM 块。Block-SA 专注于即时的空间关系,并提供附近特征的详细表示。Grid-SA 提供全局视角,捕获全面的空间关系和整体输入结构。SSM 块确保时间一致性和连续信息在连续时间步之间的传递。通过将 SSM 与自注意力结合,SSM-ViT 块实现了更快的训练和参数时间尺度调整,以进行时间聚合。
Meet More Areas(MMA)块采用 MetaFormer 风格的架构,包括两个层归一化层、一个令牌混合器(由通道注意力机制和一个 ViM 块并行组成)和一个用于深度特征提取的 MLP 块。选择这种结构的主要原因有两个:首先,采用 MetaFormer 风格的架构的模型已经显示出有希望的结果,表明了实现良好结果的潜力。其次,为了充分利用和利用 ViM 块提取的全局信息,将通道注意力机制并入以激活更多像素,因为全局细节在确定通道注意力权重方面起着作用。此外,合理地认为使用基于卷积的模块可以增强 ViM 块获得的视觉表示,并简化训练过程,与Transformer观察到的好处类似。对于恢复,Residual State Space Blocks(RSSBs)块在通道注意力块之前添加了 VSS 块,这使得 VSS 可以专注于学习多样的通道表示,之后通过后续通道注意力选择关键通道,从而避免通道冗余。
5. 总结
Mamba在计算机视觉领域日益受到关注,因为它能够处理长距离依赖关系,并且相对于变压器具有显著的计算效率。正如最近的调查所详述的那样,已经开发了各种方法来利用和探索Mamba的能力,这反映了该领域不断发展的进步。
我们首先讨论SSM(Structured Sparse Matrices,结构稀疏矩阵)和Mamba架构的基本概念,然后对一系列计算机视觉应用中的各种竞争方法进行全面分析。我们的调查涵盖了专门针对骨干架构、高/中级视觉、低级视觉、医学成像和遥感设计的最新Mamba模型。这篇调查是关于SSMs和基于Mamba的技术的最新发展的第一篇综述论文,明确关注计算机视觉挑战。我们的目标是在视觉社区中引起更多对利用Mamba模型可能性和找到解决当前限制的解决方案的兴趣。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
本文仅做学术分享,如有侵权,请联系删文。
3D视觉工坊交流群
目前我们已经建立了3D视觉方向多个社群,包括2D计算机视觉、大模型、工业3D视觉、SLAM、自动驾驶、三维重建、无人机等方向,细分群包括:
2D计算机视觉:图像分类/分割、目标/检测、医学影像、GAN、OCR、2D缺陷检测、遥感测绘、超分辨率、人脸检测、行为识别、模型量化剪枝、迁移学习、人体姿态估计等
大模型:NLP、CV、ASR、生成对抗大模型、强化学习大模型、对话大模型等
工业3D视觉:相机标定、立体匹配、三维点云、结构光、机械臂抓取、缺陷检测、6D位姿估计、相位偏折术、Halcon、摄影测量、阵列相机、光度立体视觉等。
SLAM:视觉SLAM、激光SLAM、语义SLAM、滤波算法、多传感器融合、多传感器标定、动态SLAM、MOT SLAM、NeRF SLAM、机器人导航等。
自动驾驶:深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器、多传感器标定、多传感器融合、自动驾驶综合群等、3D目标检测、路径规划、轨迹预测、3D点云分割、模型部署、车道线检测、Occupancy、目标跟踪等。
三维重建:3DGS、NeRF、多视图几何、OpenMVS、MVSNet、colmap、纹理贴图等
无人机:四旋翼建模、无人机飞控等
除了这些,还有求职、硬件选型、视觉产品落地、最新论文、3D视觉最新产品、3D视觉行业新闻等交流群
添加小助理: dddvision,备注:研究方向+学校/公司+昵称(如3D点云+清华+小草莓), 拉你入群。

3D视觉工坊知识星球
3D视觉从入门到精通知识星球、国内成立最早、6000+成员交流学习。包括:星球视频课程近20门(价值超6000)、项目对接、3D视觉学习路线总结、最新顶会论文&代码、3D视觉行业最新模组、3D视觉优质源码汇总、书籍推荐、编程基础&学习工具、实战项目&作业、求职招聘&面经&面试题等等。欢迎加入3D视觉从入门到精通知识星球,一起学习进步。

3DGS、NeRF、结构光、相位偏折术、机械臂抓取、点云实战、Open3D、缺陷检测、BEV感知、Occupancy、Transformer、模型部署、3D目标检测、深度估计、多传感器标定、规划与控制、无人机仿真、三维视觉C++、三维视觉python、dToF、相机标定、ROS2、机器人控制规划、LeGo-LAOM、多模态融合SLAM、LOAM-SLAM、室内室外SLAM、VINS-Fusion、ORB-SLAM3、MVSNet三维重建、colmap、线面结构光、硬件结构光扫描仪,无人机等。

3D视觉相关硬件
| 图片 | 说明 | 名称 |
|---|---|---|
 | 硬件+源码+视频教程 | 精迅V1(科研级))单目/双目3D结构光扫描仪 |
 | 硬件+源码+视频教程 | 深迅V13D线结构光三维扫描仪 |
 | 硬件+源码+视频教程 | 御风250无人机(基于PX4) |
 | 硬件+源码 | 工坊智能ROS小车 |
 | 配套标定源码 | 高精度标定板(玻璃or大理石) |
| 添加微信:cv3d007或者QYong2014 咨询更多 | ||
点这里
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

