
- 1云电脑是什么_什么是云电脑?云又是如何工作的?
- 2报错BrokenPipeError: [Errno 32] Broken pipe_brokenpipeerror: [errno 32] broken pipe 在向管道中写入参数的
- 3Could not find ‘cudart64_100.dll‘
- 4ioDraw在线图表工具 - 轻松制作专业图表,只需3步!_自动生成柱状图的ai
- 5数据结构与算法之计数排序_数据结构 计数排序
- 6微信支付-Native支付(网页二维码扫码微信支付)简单示例_网页扫码支付功能
- 7初次使用github
- 8旋转位置编码原理及代码_旋转位置代码
- 9关于AI记忆系统的研究_在ai智能如何实现记忆功能的方法
- 102024最新版JavaScript逆向爬虫教程-------基础篇之无限debugger的原理与绕过
开源Mamba-2性能狂飙8倍!多个Mamba超强进化体拿下顶会_mamba2
赞
踩
MambaOut的热度刚过去没多久,Mamba-2就带着它狂飙8倍的性能炸场了。
Mamba-2的核心层是对Mamba的选择性SSM的改进,同等性能下,模型更小,消耗更低,速度更快。与Mamba不同,新一代的Mamba-2再战顶会,这次顺利拿下ICML。

其实除了Mamba-2以外,还有很多关于Mamba的改进方案也被各大顶会收录,比如视觉Mamba中稿ICML 2024,SegMamba和Swin-UMamba均中稿MICCAI 2024。而且现在关于Mamba的各种研究一直在爆发性地增长,已经成了顶会的热门投稿方向。
这次我从Mamba众多改进方案中挑选了12个最新研究成果来分享,这些成果的代码都已开源,我也一并附上了,方便各位快速了解Mamba改进的前沿进展并复现。
论文原文以及开源代码需要的同学看文末
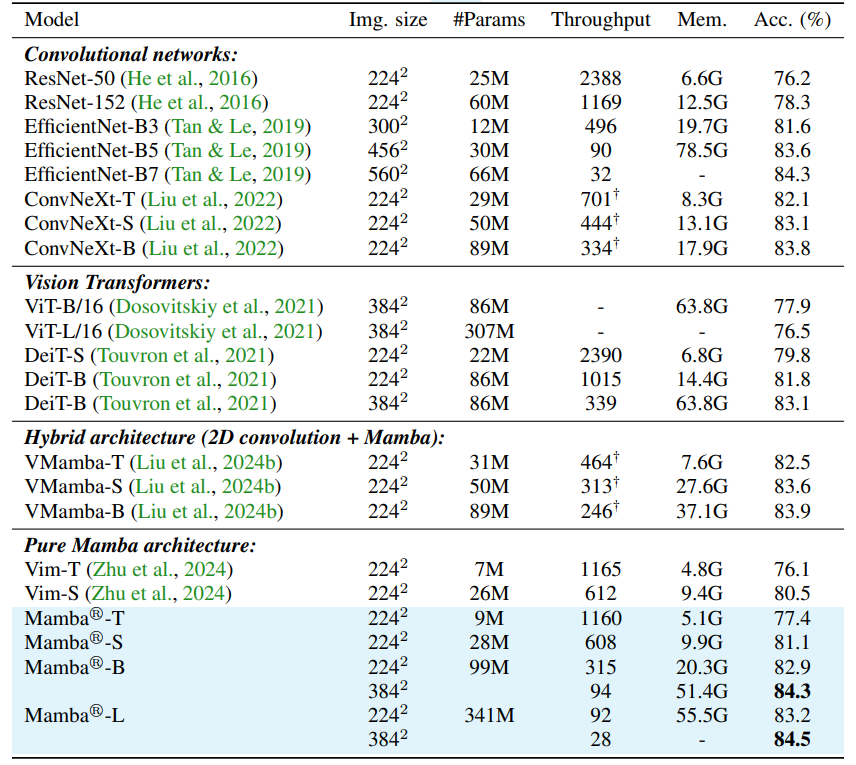
Mamba®: Vision Mamba ALSO Needs Registers
方法:本文探讨了Vision Mamba特征图中的伪影与Vision Transformers的区别,并引入了一种名为Mamba®的新型架构,通过策略性地插入寄存器来增强图像处理能力,实验证明Mamba®在准确性和可扩展性方面表现优越,为未来优化Mamba架构在视觉领域的研究提供了坚实的基础。
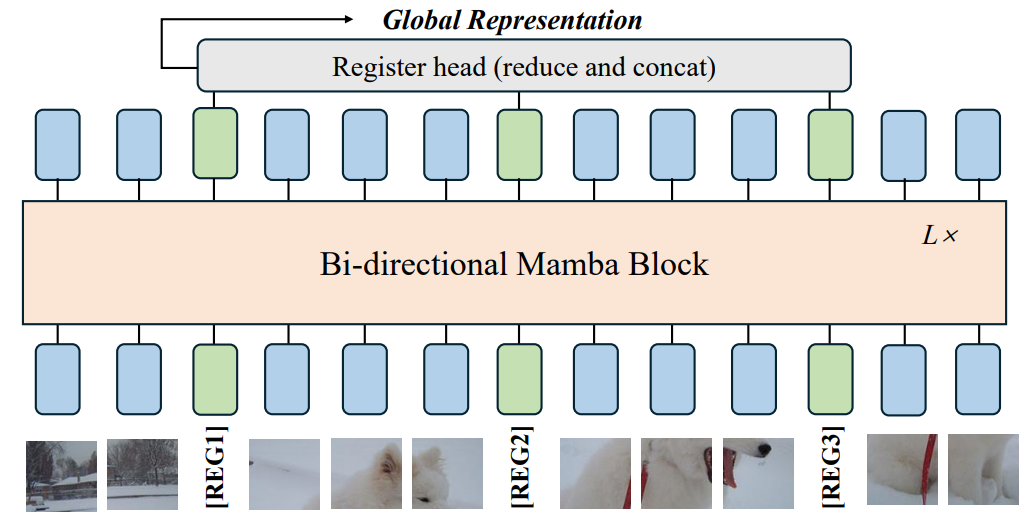
创新点:
-
引入了一种改进的Mamba ® 架构,通过在令牌序列中插入一些新的、与输入无关的寄存器令牌,对Vision Mamba进行简单而有效的架构改进。与先前的方法不同,该方法不仅在输入层的一端附加几个寄存器令牌,而且在Vision Mamba的末尾,将寄存器令牌连接起来,形成用于最终预测的综合图像表示。
-
在Vision Mamba中引入了寄存器令牌,以解决特征图中的伪影问题。通过在令牌序列中更密集地分布寄存器令牌,该方法能够更好地解决更普遍的伪影问题,从而增强图像处理能力。
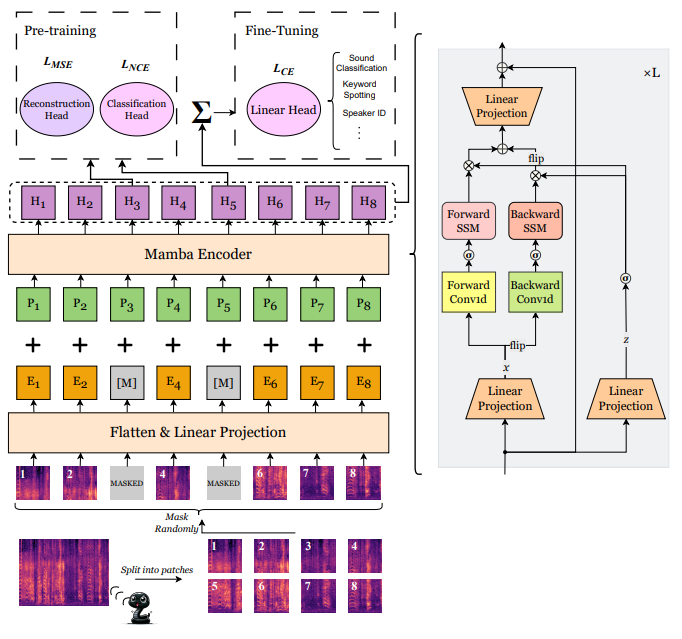
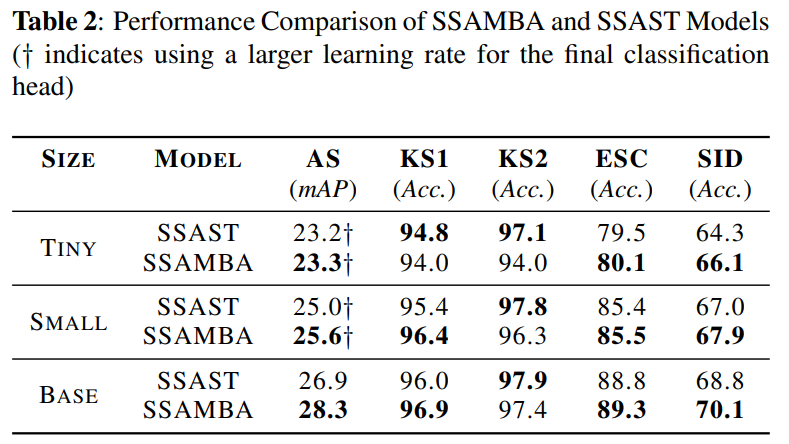
SSAMBA: Self-Supervised Audio Representation Learning with Mamba State Space Model
方法:本文介绍了一种自监督音频Mamba(SSAMBA)模型,它利用状态空间模型(SSMs)和双向架构的优势进行音频表示学习,相比传统的基于Transformer的模型,SSAMBA提供了一种更高效、可扩展的替代方案。
创新点:
-
提出了SSAMBA,这是第一个自我监督、无注意力、基于SSM(state space models)的音频表示学习模型。SSAMBA采用双向Mamba对音频进行编码和处理,并且在没有标签数据的情况下进行预训练。
-
相比于传统的基于transformer的模型,SSAMBA采用了更高效且可扩展的Mamba架构,避免了二次复杂性。SSAMBA在资源受限的设备上表现出色,具有广泛的实际应用潜力,从移动和边缘设备到大规模云系统。
PoinTramba: A Hybrid Transformer-Mamba Framework for Point Cloud Analysis
方法:本文介绍了一种名为PoinTramba的新型混合框架,将Transformer的强大建模能力与Mamba的计算效率相结合,用于增强点云分析。通过将点云分段成组,Transformer捕捉到组内复杂的依赖关系并生成组嵌入,而Mamba则同时捕捉到组间关系,确保了全面的分析。
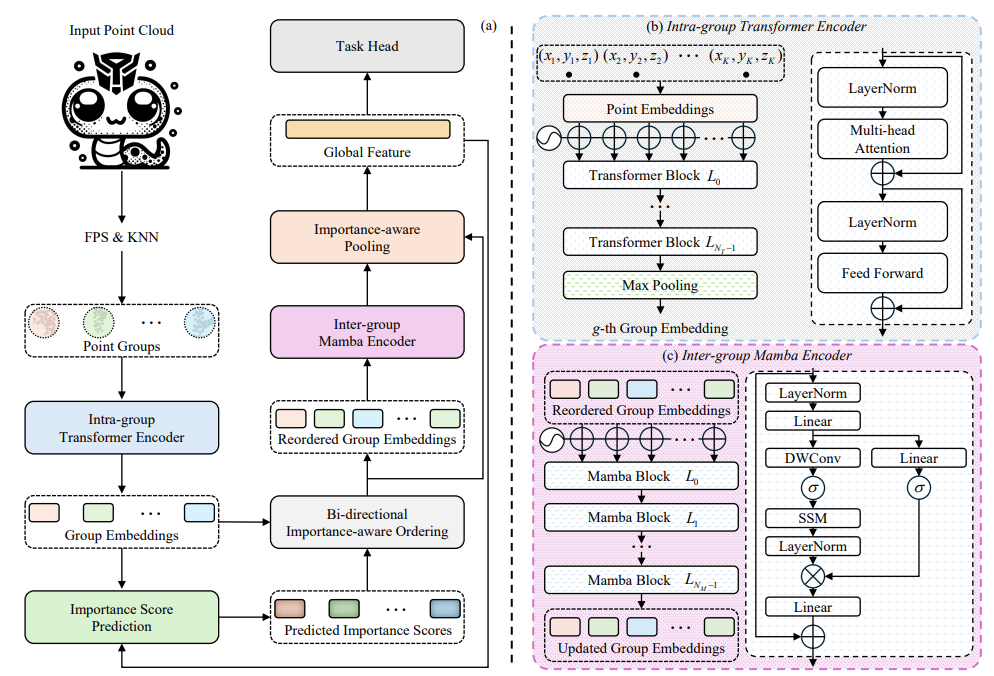
创新点:
-
PoinTramba是一种创新的混合框架,将Transformer的强大建模能力与Mamba的高效计算能力相结合,用于点云分析。通过融合这两种架构,PoinTramba在计算复杂度和分析性能之间实现了卓越的平衡,标志着领域中的一个重大进展。
-
引入了一种新的双向重要性感知排序策略(BIO),以处理随机点云排序的负面影响。该策略根据计算得到的重要性分数重新排序组嵌入,从而显著提高了Mamba的性能,并优化了整体分析过程。

Mamba as Decision Maker: Exploring Multi-scale Sequence Modeling in Offline Reinforcement Learning
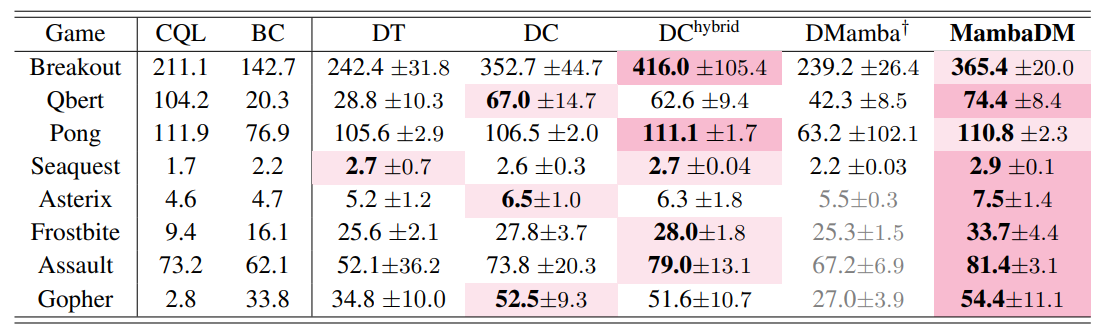
方法:MambaDM是一种用于离线强化学习的行动序列预测器,它通过一个创新的全局-局部融合Mamba(GLoMa)模块,有效地结合了全局和局部特征的多尺度序列建模,以捕捉强化学习数据集中的复杂相互关系,并在Atari和OpenAI Gym基准测试中实现了最先进的性能。
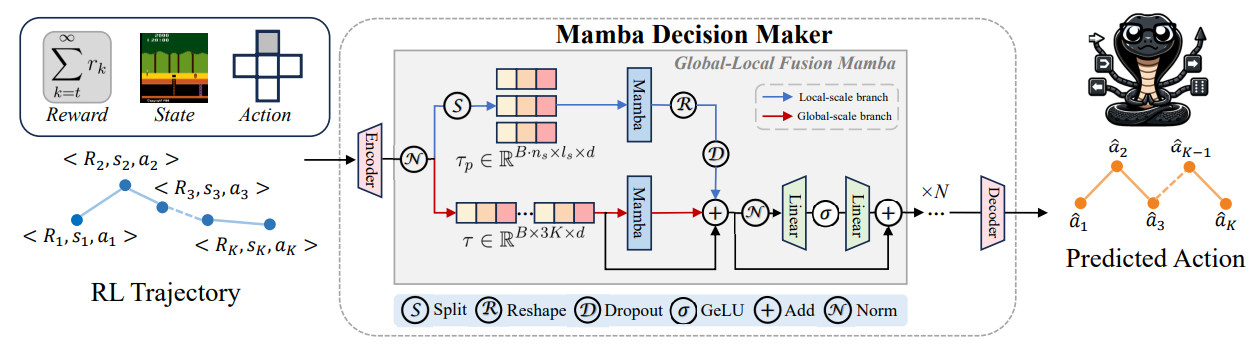
创新点:
-
全局-局部融合(GLoMa):创新性地设计了GLoMa模块,用于同时捕捉局部和全局特征,以更好地理解强化学习轨迹内的内在相关性。
-
数据集规模的缩放法则:与自然语言处理(NLP)领域不同,实验结果表明,在Atari和OpenAI Gym环境中,增加模型大小并不一定提高结果。但是,为MambaDM提供更大的数据集可以显著提高性能。
-
依赖信息的捕捉能力:通过可视化分析Mamba核心转换矩阵的特征值变化,展示了Mamba模块捕捉依赖信息的能力。
关注下方《学姐带你玩AI》
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

