
- 1在Unity中使用Vuforia识别自定义图片、物体_vuforia物体识别
- 2NLP - pytorch 实现 word2vec(简单版)_torch word2vec
- 3【python】python绘制相关性热力图_python相关性热力图
- 4助力工业产品质检,基于YOLOv5全系列参数模型【n/s/m/l/x】开发构建智能PCB电路板质检分析系统_yolo工业质检
- 5云中 GPU的AI训练,显卡分配_如何为模型训练显卡算力分配
- 6人脸识别——使用谷歌Firebase-ML Kit实现_mlkit 人脸对比
- 7BeeWare,一个如雷贯耳的python库
- 8虚拟机双硬盘安装ubuntu固态+机械_虚拟机如何用机械盘储存固态硬盘运行
- 9JAVA常用框架及漏洞_常见框架漏洞
- 10【LLM】快速了解Dify 0.6.10的核心功能:知识库检索、Agent创建和工作流编排(二)_dify知识检索
2021(SSL) 自监督学习最新力作:Barlow Twins: Self-Supervised Learning via Redundancy Reduction
赞
踩
原文地址
https://arxiv.org/abs/2103.03230
论文阅读方法
初识
背景:近两年自监督学习取得了很大的成功,其中主流的方法就是使网络学习到输入样本不同失真(distortions)版本下的不变性特征,但是这种方法很容易遭遇平凡解,现有方法大多是通过实现上的细节来避免出现collapse。
distortion:简单点说就是输入样本的各种增广
如下图所示,本文提出了一种新颖的想法,将样本经过不同增广送入同一网络中得到两种表示,利用损失函数迫使它们的互相关矩阵接近于恒等矩阵:这意味着同一样本不同的增广版本下提取出的特征表示非常类似,同时特征向量分量间的冗余最小化。
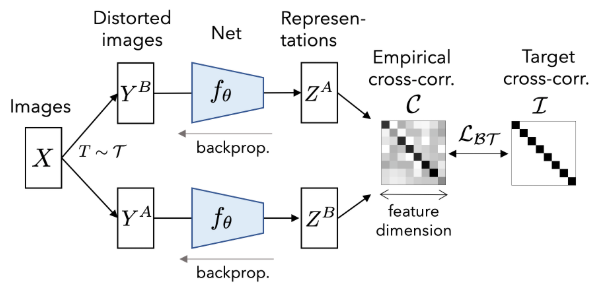
相知
2. Method
其实主要的思想就在上一节讲完了,这篇文章就是这么简单,这里主要讲一下细节
损失函数如下所示,C为互相关矩阵,其中invariance term使得对角元素接近于1,促使同一样本在不同失真版本下的特征一致性,redundancy reduction term使非对角元素接近0,解耦特征表示的不同向量分量
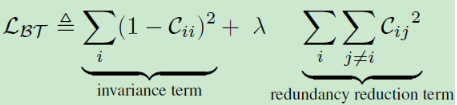
C的尺寸为网络输出的维度,λ为超参
文中还给出了互相关矩阵C的详细计算公式,如下所示:
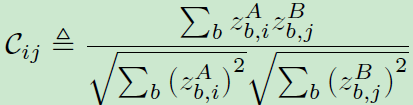
实现细节:
下图为实现Barlow Twins的伪代码:

① 图像增强:随机裁剪,resize,水平翻转,颜色抖动,转换灰度,高斯平滑,solarization。其中前两个必做,其他的以一定概率进行。
② 网络架构:ResNet-50,然后接一个小的映射网络(3个线性映射层,维度均为8192),前两个线性层后接BN+ReLU操作。
③ 优化方法:LARS优化器,1000个epoch,batchsize为2048(也可以缩小到256),忽略了一些细节,详见原文
3. Results
① 在ImageNet上训练一个线性分类器:
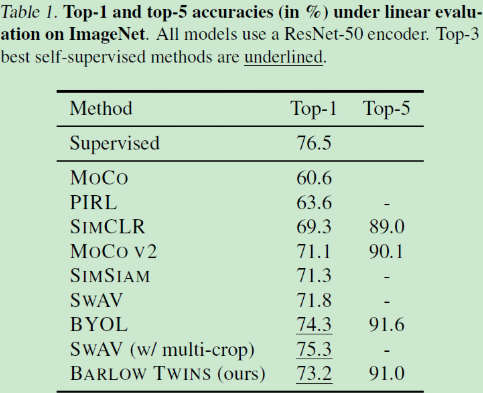

分类
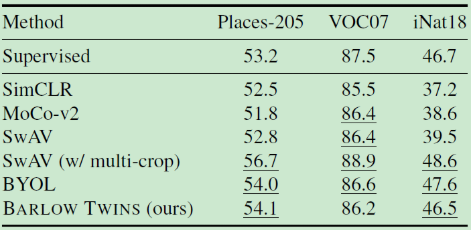
检测与分割

4. Ablations
进行了一系列的消融实验,包括损失函数、BatchSize、增强手段、映射网络的深度与宽度、网络结构对称性
这里重点提两点,其他方面见原文:① 模型对batch size较鲁棒,与BYOL一致,作者将其归功于非对比学习的方法;② 模型性能随着输出维度的增大而增大,而其他大多方法会较早饱和。
5. Discussion
重头戏,在理论上与经验上与其他方法进行对比
① infoNCE:
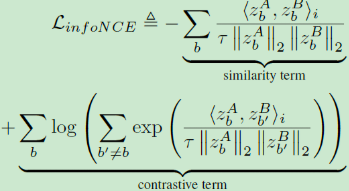

可以看到非常相似,两者都依赖于批次统计来测量变化性,InfoNCE最大化样本对之间的距离,而Barlow Twins解耦特征向量的分类。InfoNCE可以看做是表示分布熵的非参数估计,容易遭受维度诅咒,高斯参数化下表示分布的代理(proxy)熵估计。
损失函数上存在着几点不同:① InfoNCE进行维度归一化,而本文采用批次归一化;② 本文引入超参数 λ \lambda λ; ③ InfoNCE存在温度系数。
并且InfoNCE需要大的batch size,MoCo采用细节上的设计进行避免(构建memory bank),而本文对batch size鲁棒
② Asymmetric Twins:
BYOL和SIMSIAM没有采用对比项,只使用了简单的cosine相似度:
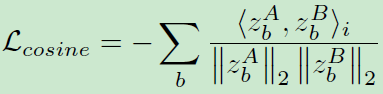
他们通过引入非对称的结构与学习策略来避免平凡解,并且与本文一样,不需要将Batch Size设置得很大。
本文直接通过目标函数的构造避免了平凡解
③ Whitening:
W-MSE在计算余弦相似度之前,对每一批表示执行可微化的白化操作(a differentiable whitening operation,通过Cholesky分解),而本文的redundancy reduction项可以视作为白化操作的一种软约束。
④ Clustering:
DeepCluster与swAV这类基于聚类的方法容易遭遇collapse。
⑤ IMAX:
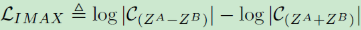
IMAX是一篇很老的文章了,作者试图将其在ImageNet上train起来,但是失败了,所以也没有可比性。
回顾
这篇文章非常新,3月4日发布于arXiv,由Facebook和Lecun出品,顶会应该是迟早的事情。相比于去年的一系列SSL工作,本文从一个全新视角出发,以一个非常简单的方法来执行自监督学习,并且结构优美,限制少。主要还达到了SOTA,这是一件很令人振奋的事情,给自监督学习注入了新鲜的血液。
关于未来的改进方向,作者最后也提到了本文只是Information Bottleneck原理在自监督上的一种应用实例而已,相信基于它们的基础上进行改进可能会达到更好的效果,例如不用孪生网络,而是直接根据单个网络的自相关矩阵计算对角项(其中作者做了初步试验,可以看原文的附录)。
代码
尚未开源
个人浅见,能力有限,如果错误,欢迎指正。

