
- 1【亲测有效!一站式解决】Git上传出现报错及解决方法整理,git上传github,gitlab报错,git上传报错_git上传代码失败
- 2国开网c语言性考答案,电大国开C语言程序设计形考任务2答案
- 3机器学习领域五大发展趋势,谷歌 AI 掌门人万字回顾 2021
- 42.一步一步教你使用pycharm运行起第一个Django项目_pycharm运行django项目
- 5AST:Audio Spectrogram Transformer_ast: audio spectrogram transformer
- 6windows中使用selenium控制edge无界面模式_webdriver.edge()无界面启动
- 7使用 Scapy 库编写 TCP 劫持攻击脚本
- 8Vivado生成、固化烧录文件_vivado prm文件有啥用
- 9人工智能辅导程序 Mr. Ranedeer AI Tutor_mr. ranedeer ai tutor 怎么使用
- 10知识图谱的应用---新零售
Hadoop实验4:MapReduce编程_mapreduce实验
赞
踩
目录
一. 【实验准备】
参考《Hadoop安装部署》实验,安装部署配置了三个数据节点的Hadoop集群
1.工作目录
本实验的工作目录为~/course/hadoop/mr_pro,使用以下命令创建和初始化工作目录:
- $ mkdir -p ~/course/hadoop/mr_pro
- $ cd ~/course/hadoop/mr_pro
2.打开eclipse并配置工作空间
在桌面右键打开终端输入如下命令打开eclipse:
eclipse &
打开eclipse后选择/headless/course/hadoop/mr_pro做为工作空间
二、准备工作
1. 新建项目
1.在eclipse中依次点击:File->New->Project->Map/Reduce Project->Next。
2.在项目名称(Project Name)处填入WordCount,将工程位置设置为文件夹/headless/course/hadoop/mr_pro/WordCount,点击Finish。
2. 准备测试数据
新建终端,使用如下命令新建一个文本文件:
- # cd ~/course/hadoop/mr_pro/WordCount/
- # mkdir target
- # mkdir data
- # cd data
- # echo "Hello World" >> file1.txt
- # echo "Hello MapReduce" >> file2.txt
使用如下命令进入master节点:
# docker exec -it --privileged master /bin/bash
主机的~/course目录挂载到了master节点的/course目录。
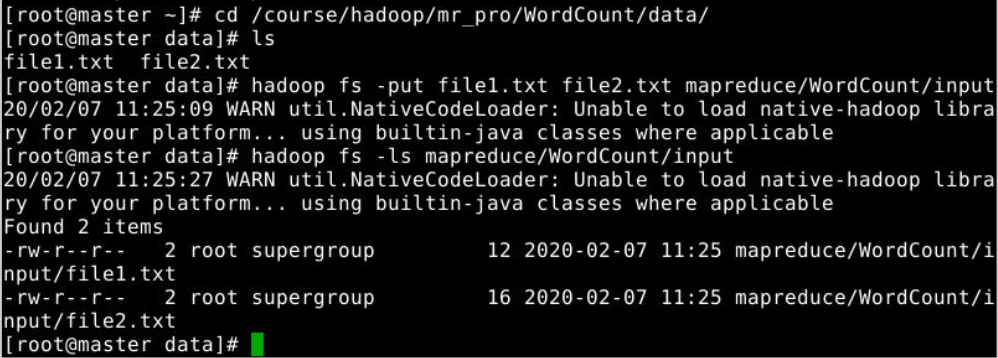
在master节点中使用如下命令新建目录,并将文本文件上传到目录:
- # hadoop fs -mkdir -p mapreduce/WordCount/input
- # cd /course/hadoop/mr_pro/WordCount/data
- # hadoop fs -put file1.txt file2.txt mapreduce/WordCount/input
- # hadoop fs -ls mapreduce/WordCount/input
- Found 2 items
- -rw-r--r-- 3 bd1_cg bd1 12 2018-12-20 17:59 mapreduce/WordCount/input/file1.txt
- -rw-r--r-- 3 bd1_cg bd1 16 2018-12-20 17:59 mapreduce/WordCount/input/file2.txt
3. 添加 MapReduce 编程框架
MapReduce 编程框架分为三个部分,请在 Eclipse 中的 WordCount 下分别创建如下三个类,内容分别如下:
(1).WcMapper
- public class WcMap extends Mapper<LongWritable, Text, Text, LongWritable>{
- //重写map这个方法
- //mapreduce框架每读一行数据就调用一次该方法
- protected void map(LongWritable key, Text value, Context context)
- throws IOException, InterruptedException {
- //具体业务逻辑就写在这个方法体中,而且我们业务要处理的数据已经被框架传递进来,在方法的参数中key-value
- //key是这一行数据的起始偏移量,value是这一行的文本内容
- }
- }
(2).WcReducer
- public class WcReduce extends Reducer<Text, LongWritable, Text, LongWritable>{
-
- //继承Reducer之后重写reduce方法
- //第一个参数是key,第二个参数是集合。
- //框架在map处理完成之后,将所有key-value对缓存起来,进行分组,然后传递一个组<key,valus{}>,调用一次reduce方法
- protected void reduce(Text key, Iterable<LongWritable> values,Context context)
- throws IOException, InterruptedException {
-
- }
- }
(3).WcRunner
- public class WcRunner {
-
- public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
- //创建配置文件
- Configuration conf = new Configuration();
- //获取一个作业
- Job job = Job.getInstance(conf);
-
- //设置整个job所用的那些类在哪个jar包
- job.setJarByClass(WcRunner.class);
-
- //本job使用的mapper和reducer的类
- job.setMapperClass(WcMap.class);
- job.setReducerClass(WcReduce.class);
-
- //指定reduce的输出数据key-value类型
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(LongWritable.class);
-
-
- //指定mapper的输出数据key-value类型
- job.setMapOutputKeyClass(Text.class);
- job.setMapOutputValueClass(LongWritable.class);
-
- //指定要处理的输入数据存放路径
- FileInputFormat.setInputPaths(job, new Path("hdfs://192.168.51.149:9000/user/cg/input"));
-
- //指定处理结果的输出数据存放路径
- FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.51.149:9000/user/cg/output"));
-
- //将job提交给集群运行
- job.waitForCompletion(true);
- }
- }

三、Map过程
Map过程需要继承org.apache.hadoop.mapreduce包中Mapper类,并重写其map方法。通过在map方法中添加两句把key值和value值输出到控制台的代码,可以发现map方法中value值存储的是文本文件中的一行(以回车符为行结束标记),而key值为该行的首字母相对于文本文件的首地址的偏移量。然后StringTokenizer类将每一行拆分成为一个个的单词,并将<word,1>作为map方法的结果输出,其余的工作都交有MapReduce框架处理。
完整代码与解析如下:
- import java.io.IOException;
- import org.apache.commons.lang.StringUtils;
- import org.apache.hadoop.io.LongWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Mapper;
- /***
- *
- * @author Administrator
- * 1:4个泛型中,前两个是指定mapper输入数据的类型,KEYIN是输入的key的类型,VALUEIN是输入的value的值
- * KEYOUT是输入的key的类型,VALUEOUT是输入的value的值
- * 2:map和reduce的数据输入和输出都是以key-value的形式封装的。
- * 3:默认情况下,框架传递给我们的mapper的输入数据中,key是要处理的文本中一行的起始偏移量,这一行的内容作为value
- * 4:key-value数据是在网络中进行传递,节点和节点之间互相传递,在网络之间传输就需要序列化,但是jdk自己的序列化很冗余
- * 所以使用hadoop自己封装的数据类型,而不要使用jdk自己封装的数据类型;
- * Long--->LongWritable
- * String--->Text
- */
- public class WcMap extends Mapper<LongWritable, Text, Text, LongWritable>{
- //重写map这个方法
- //mapreduce框架每读一行数据就调用一次该方法
- @Override
- protected void map(LongWritable key, Text value, Context context)
- throws IOException, InterruptedException {
- //具体业务逻辑就写在这个方法体中,而且我们业务要处理的数据已经被框架传递进来,在方法的参数中key-value
- //key是这一行数据的起始偏移量,value是这一行的文本内容
-
- //1:
- String str = value.toString();
- //2:切分单词,空格隔开,返回切分开的单词
- String[] words = StringUtils.split(str," ");
- //3:遍历这个单词数组,输出为key-value的格式,将单词发送给reduce
- for(String word : words){
- //输出的key是Text类型的,value是LongWritable类型的
- context.write(new Text(word), new LongWritable(1));
- }
- }
- }
四、Reduce过程
Reduce过程需要继承org.apache.hadoop.mapreduce包中Reducer类,并重写其reduce方法。Map过程输出<key,values>中key为单个单词,而values是对应单词的计数值所组成的列表,Map的输出就是Reduce的输入,所以reduce方法只要遍历values并求和,即可得

