
- 1RabbitMQ安装UI监控插件
- 2《图像处理的璀璨星空:技术演进与热点聚焦》_图像处理技术现如今的前沿技术有哪些
- 3C++ + QT (不使用QT插件模式)的heic图片显示。_qt heic
- 4欧拉操作系统_欧拉系统
- 5网络资源模板--基于 Android Studio 实现的新闻App_android studio新闻客户端制作
- 6Android数据库高手秘籍_android 数据库密集
- 7【kafka专栏】消息队列通用消息传递模型(带视频)_可以传输图片视频的消息队列
- 8Git工具常用命令详解_git命令工具
- 9深入理解哈希表
- 10【大模型应用篇6】私有化智能体平台,为了数据更安全........_dify和coze
复现 transformer_transformer复现
赞
踩
一、实现 掩码操作
首先是一些掩码操作
- def sequence_mask(X,valid_len,value=0):
- """在序列中屏蔽不相关的项"""
- maxlen = X.size(1)
- mask = torch.arange((maxlen),dtype =torch.float32,
- device = X.device)[None,:]<valid_len[:,None]
- X[~mask] = value
- return X
mask = torch.arange((maxlen),dtype =torch.float32, device = X.device)[None,:]<valid_len[:,None]
这行代码主要是在实现序列屏蔽的过程中构造一个形状为(batch_size, seq_len)大小的布尔型张量mask 其中,元素(i,j)的值为True表示对应输入序列中的第i个样本在位置j上存在有效元素,反之,该位置不存在有效元素。具体而言,valid_len 是一个长度为batch_size的一维张量,表示每个序列中有效元素的数量(seq_len可能大于有效长度)。而在上述代码行中,我们使用了广播机制将valid_len扩展为形状为(batch_size, 1)的二维张量,然后使用生成器表达式和比较运算符<,按行逐个比较从0到seq_len-1的整数(构造成形状为(1, seq_len)大小的二维张量),若某个位置小于对应位置的 valid_len,则该位置为True;反之,则为False。最终得到一个形状为(batch_size,seq_len)大小的二维张量mask,即序列的遮罩,返回后,本函数再使用~操作符将其取反,并应用到原始序列上。
- def masked_softmax(X,valid_lens):
- """通过在最后一个轴上掩蔽元素来执行softmax操作"""
- #X:3D张量,valid_lens:1D或者2D张量
- if valid_lens is None:
- return nn.functional.softmax(X,dim=-1)
- else:
- shape = X.shape
- if valid_lens.dim()==1:
- valid_lens = torch.repeat_interleave(valid_lens,shape[1])
- else:
- valid_lens = valid_lens.reshape(-1)
- #最后一轴上被掩蔽的元素使用一个非常大的负值替换,从而其softmax的输出为0
- X=sequence_mask(X.reshape(-1,shape[-1]),valid_lens,
- value =-1e6)
- return nn.functional.softmax(X.reshape(shape),dim=-1)
这段代码是一个返回 X 在 dim=-1 上进行 softmax 归一化处理的函数,其中 dim=-1 表示对最后一个维度上的数据进行 softmax 操作。对于一个三维张量 X,其三个维度通常分别代表数据的样本数量、每个样本中序列的长度和每个元素(例如词向量)的特征维度。
如果不用掩蔽元素,直接将X的最后一维度(每一行)softmax,否则,先存取x的形状,然后如果valid_lens的维度为1,valid_lens的列数代表有几个样本,值分别代表每个样本的有效长度。将valid_lens复制shape[1]次,shape[1]为第二维度代表每个样本的序列长度。复制完后所有的样本的所有时间步都有对应的有效长度。
如果为valid_lens为其他维度,则将它展平。然后通过sequence_mask将X的超出有效长度之外的特征设置为无穷大,每一行通过softmax值运算变为0。
二、实现多头注意力
首先是实现缩放点积注意力
- class DotProductAttention(nn.Module):
- """缩放点积注意力"""
- def __init__(self,dropout,**kwargs):
- super(DotProductAttention,self).__init__(**kwargs)
- self.dropout = nn.Dropout(dropout)
- # queries的形状:(batch_size,查询的个数,d)
- # keys的形状:(batch_size,“键-值”对的个数,d)
- # values的形状:(batch_size,“键-值”对的个数,值的维度)
- # valid_lens的形状:(batch_size,)或者(batch_size,查询的个数)
-
- def forward(self,queries,keys,values,valid_lens= None):
- d = queries.shape[-1]
- # 设置transpose_b=True为了交换keys的最后两个维度
- scores = torch.bmm(queries,keys.transpose(1,2))/math.sqrt(d)
- self.attention_weights = masked_softmax(scores,valid_lens)
- return torch.bmm(self.dropout(self.attention_weights),values)

transpose_b(1,2)的作用相当于给矩阵行列转置。
自注意力就是同时考虑自身全部的信息,不像rnn一样后面的信息只依赖以他之前的信息,q为查询,k为键,先计算q与k的点积来确定q与k的相似程度,计算得出注意力分数,越相似分数越高,(因为两个向量相乘,例如如果向量垂直则点积为0,则无关,如果在同一条线上则相似度高,乘积值大)除以根号d是因为防止数字过大或者过小,使得经过softmax的时候接近于1,或者0,导致训练困难。注意力分数经过一个softmax,变为一个概率,然后将值v与计算出来的概率做一个加权和。
然后是实现多头注意力,在实现过程中通常选择缩放点积注意力作为每一个注意力头。为了避免计算代价和参数代价的大幅增长我们设定q,k,v的第三维度为hidden_size/num_heads,以下是具体代码。
多头注意力可以做到并行运算,通过不同的权值得到不同的q、k、v矩阵,同时通过自注意力机制,得到一个多组的Z值(如z1,z2,z3,z4,......取决于num_heads,注意力的头数),然后Z值拼接,根据一个线性变化将拼接的Z矩阵变化为尺度与原来每个z(如z1)的尺度一样的矩阵。
- class MultiHeadAttention(nn.Module):
- """多头注意力"""
- def __init__(self,key_size,query_size,value_size,num_hiddens,
- num_heads,dropout,bias=False,**kwargs):
- super(MultiHeadAttention,self).__init__(**kwargs)
- self.num_heads = num_heads
- self.attention = DotproductAttention(dropout)
- self.W_q=nn.Linear(query_size,num_hiddens,bias=bias)
- self.W_k=nn.Linear(key_size,num_hiddens,bias=bias)
- self.W_v= nn.Linear(value_size,num_hiddens,bias=bias)
- self.W_o = nn.Linear(num_hiddens,num_hiddens,bias=bias)
-
- def forward (self,queries,keys,values,valid_lens):
- # queries,keys,values的形状:
- # (batch_size,查询或者“键-值”对的个数,num_hiddens)
- # valid_lens 的形状:
- # (batch_size,)或(batch_size,查询的个数)
- # 经过变换后,输出的queries,keys,values 的形状:
- # (batch_size*num_heads,查询或者“键-值”对的个数,
- # num_hiddens/num_heads)
- queries = transpose_qkv(self.W_q(queries),self.num_heads)
- keys = transpose_qkv(self.W_k(keys),self.num_heads)
- values = transpose_qkv(self.W_v(values),self.num_heads)
-
- if valid_lens is not None:
- # 在轴0,将第⼀项(标量或者⽮量)复制num_heads次,
- # 然后如此复制第⼆项,然后诸如此类。
- valid_lens = torch.repeat_interleave(
- valid_lens,repeats= self.num_heads,dim=0)
-
- # output的形状:(batch_size*num_heads,查询的个数,
- # num_hiddens/num_heads)
- output = self.attention(queries,keys,values,valid_lens)
-
- # output_concat的形状:(batch_size,查询的个数,num_hiddens)
- output_concat = tran_output(output,self.num_heads)
- return self.W_o(output_concat)
-
- def transpose_qkv(X,num_heads):
- """为了多注意力头的并行计算而变换形状"""
- # 输⼊X的形状:(batch_size,查询或者“键-值”对的个数,num_hiddens)
- # 输出X的形状:(batch_size,查询或者“键-值”对的个数,num_heads,
- # num_hiddens/num_heads)
- X=X.reshape(X.shape[0],X.shape[1],num_heads,-1)
-
- # 输出X的形状:(batch_size,num_heads,查询或者“键-值”对的个数,
- # num_hiddens/num_heads)
-
- X = X.permute(0, 2, 1, 3)
-
- # 最终输出的形状:(batch_size*num_heads,查询或者“键-值”对的个数,
- # num_hiddens/num_heads)
-
- return X.reshape(-1, X.shape[2], X.shape[3])
-
-
- def transpose_output(X, num_heads):
- """逆转transpose_qkv函数的操作"""
- X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])
- X = X.permute(0, 2, 1, 3)
- return X.reshape(X.shape[0], X.shape[1], -1)
三、位置编码
- class PositionalEncoding(nn.Module):
- """位置编码"""
- def __init__(self, num_hiddens, dropout, max_len=1000):
- super(PositionalEncoding, self).__init__()
- self.dropout = nn.Dropout(dropout)
- # 创建一个足够长的P
- self.P = torch.zeros((1, max_len, num_hiddens))
- X = torch.arange(max_len, dtype=torch.float32).reshape(
- -1, 1) / torch.pow(10000, torch.arange(
- 0, num_hiddens, 2, dtype=torch.float32) / num_hiddens)
- self.P[:, :, 0::2] = torch.sin(X)
- self.P[:, :, 1::2] = torch.cos(X)
-
- def forward(self, X):
- X = X + self.P[:, :X.shape[1], :].to(X.device)
- return self.dropout(X)
四、编码块
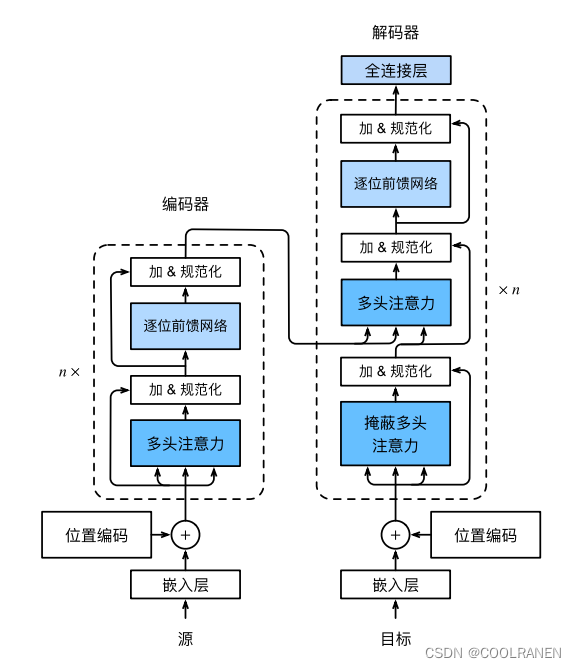
transformer的结构如下,我们先实现编码器块,它是由先通过多头注意力然后进行残差连接和一个层规范化,然后继续通过一个逐位前馈网络和残差连接和层规范化。
首先来实现逐位前馈网络和加规范化层
- #基于位置的前馈网络
- class PositionWiseFFN(nn.Module):
- """基于位置的前馈网络"""
- def __init__(self,ffn_num_input,ffn_num_hiddens,ffn_num_outputs,
- **kwargs):
- super(PositionWiseFFN, self).__init__(**kwargs)
- self.dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)
- self.relu = nn.ReLU()
- self.dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)
-
- def forward(self, X):
- return self.dense2(self.relu(self.dense1(X)))
-
- #加规范化
- class AddNorm(nn.Module):
- """残差连接后进行层规范化"""
- def __init__(self,normalized_shape,dropout,**kwargs):
- super(AddNorm,self).__init__(**kwargs)
- self.dropout = nn.Dropout(dropout)
- self.ln = nn.LayerNorm(normalized_shape)
-
- def forward(self,X,Y):
- return self.ln(self.dropout(Y) + X)
其中这个层规范化和以前的批量规范化又很不一样。批量规范化是按照特征来规范化,比如五个单词,每个单词用64个特征的向量来表示它,批量规范化是将这五个单词的每一个特征进行一次规范化,总共运行64次。而批量规范化是将每个样本进行规范化,比如第一个单词的所有特征值求均值和方差进行规范化,五个样本总共运算5次。
然后再来实现编码器块
- class EncoderBlock(nn.Module):
- """Transformer编码器块"""
- def __init__(self,key_size,query_size,value_size,num_hiddens,
- norm_shape,ffn_num_input,ffn_num_hiddens,num_heads,
- dropout,use_bias=False,**kwargs):
- super(EncoderBlock,self).__init__(**kwargs)
- self.attention = MultiHeadAttention(
- key_size,query_size,value_size,num_hiddens,num_heads,dropout,
- use_bias)
- self.addNorm1 = AddNorm(norm_shape,dropout)
- self.ffn = PositionWiseFFN(
- ffn_num_input,ffn_num_hiddens,num_hiddens)
- self.addNorm2 =AddNorm(norm_shape,dropout)
-
- def forward(self,X,valid_lens):
- Y=self.addNorm1(X,self.attention(X,X,X,valid_lens))
- return self.addNorm2(Y,self.ffn(Y))
最后实现整个transformer的编码器部分
- class TransformerEncoder(Encoder):
- """Transformer编码器"""
- def __init__(self,vocab_size,key_size,query_size,value_size,num_hiddens,
- norm_shape,ffn_num_input,ffn_num_hiddens,
- num_heads,num_layers,dropout,use_bias=False,**kwargs):
- super(TransformerEncoder,self).__init__(**kwargs)
- self.num_hiddens = num_hiddens
- self.embedding = nn.Embedding(vocab_size,num_hiddens)
- self.pos_encoding = PositionalEncoding(num_hiddens,dropout)
- self.blks = nn.Sequential()
- for i in range(num_layers):
- self.blks.add_module("block"+str(i),
- EncoderBlock(key_size,query_size,value_size,num_hiddens,
- norm_shape,ffn_num_input,ffn_num_hiddens,
- num_heads,dropout,use_bias))
-
-
- def forward(self,X,valid_lens,*args):
- # 因为位置编码值在-1和1之间,
- # 因此嵌⼊值乘以嵌⼊维度的平⽅根进⾏缩放,
- # 然后再与位置编码相加。
- X=self.pos_encoding(self.embedding(X)*math.sqrt(self.num_hiddens))
- self.attention_weights = [None]*len(self.blks)
- for i,blk in enumerate(self.blks):
- X=blk(X,valid_lens)
- self.attention_weights[i]=blk.attention.attention.attention_weights
- return X
将每一块的注意力权重保存到attention_weight的中
五、解码器
- class DecoderBlock(nn.Module):
- """解码器中第i个块"""
- def __init__(self,key_size,query_size,value_size,num_hiddens,
- norm_shape,ffn_num_input,ffn_num_hidddens,num_heads,
- dropout,i,**kwargs):
- super(DecoderBlock,self).__init__(**kwargs)
- self.i = i
- self.attention1 = MultiHeadAttention(
- key_size,query_size,value_size,num_hiddens,num_heads,dropout)
-
- self.addnorm1 = AddNorm(norm_shape,dropout)
- self.attention2 = MultiHeadAttention(
- key_size,query_size,value_size,num_hiddens,num_heads,dropout)
-
- self.addnorm2 = AddNorm(norm_shape,dropout)
- self.ffn = PositionWiseFFN(ffn_num_input,ffn_num_hidddens,
- num_hiddens)
- self.addnorm3 = AddNorm(norm_shape,dropout)
-
- def forward(self,X,state):
- enc_outputs,enc_valid_lens = state[0],state[1]
- # 训练阶段,输出序列的所有词元都在同⼀时间处理,
- # 因此state[2][self.i]初始化为None。
- # 预测阶段,输出序列是通过词元⼀个接着⼀个解码的,
- # 因此state[2][self.i]包含着直到当前时间步第i个块解码的输出表⽰
- if state[2][self.i] is None:
- #表示直接使用当前输入的 X 作为 Q 和 K 值计算注意力分布以产生加权和
- key_values = X
- else:
- key_values = torch.cat((state[2][self.i],X),axis=1)
- #将之前的输入与X拼接起来作为key_values
-
- state[2][self.i] = key_values
- #更新state[2][self.i]
- if self.training:
- batch_size,num_steps,_ = X.shape
- # dec_valid_lens的开头:(batch_size,num_steps),
- # 其中每⼀⾏是[1,2,...,num_steps]
- #将1到num_steps,复制batch_size次
- dec_valid_lens = torch.arange(1,num_steps+1,
- device = X.device).repeat(batch_size,1)
-
- else:
- dec_valid_lens=None
-
- #自注意力
- X2=self.attention1(X,key_values,key_values,dec_valid_lens)
- #首先进入的是掩蔽的多头注意力,确保后面的输出只依赖以之前的信息
- Y=self.addnorm1(X,X2)
- #编码器--解码器注意力
- #enc_outputs的开头:(batch_size,num_steps,num_hiddens)
- #enc_outputs为编码器输出的信息作为这里注意力的Q、V
- Y2=self.attention2(Y,enc_outputs,enc_outputs,enc_valid_lens)
- Z = self.addnorm2(Y,Y2)
- return self.addnorm3(Z,self.ffn(Z)),state
- class Decoder(nn.Module):
- """编码器-解码器架构的基本解码器接口"""
- def __init__(self,**kwargs):
- super(Decoder,self).__init__(**kwargs)
-
- def init_state(self,enc_outputs,*args):
- raise NotImplementedError
-
- def forward(self,X,state):
- raise NotImplementedError
-
- class AttentionDecoder(Decoder):
- """带有注意力机制解码器的基本接口"""
- def __init__(self,**kwargs):
- super(AttentionDecoder,self).__init__(**kwargs)
- @property
- def attention_weight(self):
- raise NotImplementedError
-
- class TransformerDecoder(AttentionDecoder):
- def __init__(self, vocab_size, key_size, query_size, value_size,
- num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
- num_heads, num_layers, dropout, **kwargs):
- super(TransformerDecoder,self).__init__(**kwargs)
- self.num_hiddens = num_hiddens
- self.num_layers = num_layers
- self.embedding = nn.Embedding(vocab_size,num_hiddens)
- self.pos_encoding = PositionalEncoding(num_hiddens,dropout)
- self.blks = nn.Sequential()
- for i in range(num_layers):
- self.blks.add_module("block"+str(i),
- DecoderBlock(key_size,query_size,value_size,num_hiddens,
- norm_shape,ffn_num_input,ffn_num_hiddens,
- num_heads,dropout,i))
-
- self.dense = nn.Linear(num_hiddens,vocab_size)
-
- def init_state(self,enc_outputs,enc_valid_lens,*args):
- return [enc_outputs,enc_valid_lens,[None]*self.num_layers]
-
- def forward(self,X,state):
- X= self.pos_encoding(self.embedding(X)*math.sqrt(self.num_hiddens))
- self._attention_weights = [[None] * len(self.blks) for _ in range (2)]
- #生成一个(2,[none]*len(self.blks))的矩阵来保存解码器的自注意力权重,
- #以及编码器-解码器的自注意力权重
- for i,blk in enumerate(self.blks):
- X,state = blk(X,state)
- #解码器自注意力权重
- self._attention_weights[0][i]=blk.attention1.attention.attention_weights
- #编码器-解码器 自注意力权重
- self._attention_weights[1][i]=blk.attention2.attention.attention_weights
- return self.dense(X),state
-
- def attention_weights(self):
- return self._attention_weights
解码器与编码器的不同主要在于解码器多了掩蔽多头注意力部分以及编码器解码器注意力部分。掩蔽多头注意力确保后面的信息不会被输入,后面的输出只依赖于前面的全部信息的输入。具体实现是将后面的信息变为负无穷大,通过softmax就会计算得为0,从而屏蔽后面的信息。比如像机器翻译也就是一个字一个字往外蹦出来 。编码器解码器注意力部分是将编码器的输出作为解码器的k,v,而解码器自己的输入为q,进行注意力计算。

