
- 1pytorch的代码 CPU改为GPU_paddle cpu版本的代码如何置换gpu版本
- 2Python读取execl, 出现Unnamed列,导致处理报错ValueError: Unexpected input dimension XX, expected XX_python excel读取 没有内容,却读取了unnamed, nan
- 3YOLOV3翻译
- 4IDEA 官宣全新默认 UI,真香_2024idea新ui
- 5当“广撒网”遇上“精准定点”的鱼叉式网络钓鱼
- 6用matlab写一段时间序列预测
- 7爬虫使用Beautiful Soup爬取网页信息示例代码(酷dog音乐)_3、利用beautifulsoup爬取酷狗音乐top22的排名、歌名和播放时间,并保存到新建的“
- 8Pycharm创建虚拟环境
- 9如何在项目中使用uni-ui组件库_uni-ui使用
- 10SpringBoot轻量级物联网综合业务支撑平台源码_springboot 物联网项目
7.1.3、使用飞桨实现基于LSTM的情感分析模型_飞桨模型使用
赞
踩
7.1 NLP经典神经网络 RNN LSTM-CSDN博客
三、使用飞桨实现基于LSTM的情感分析模型
接下来让我们看看如何使用飞桨实现一个基于长短时记忆网络的情感分析模型。在飞桨中,不同深度学习模型的训练过程基本一致,流程如下:
- 数据处理 :选择需要使用的数据,并做好必要的预处理工作。
- 网络定义 :使用飞桨定义好网络结构,包括输入层,中间层,输出层,损失函数和优化算法。
- 模型训练 :将准备好的训练集数据送入神经网络进行学习,并观察学习的过程是否正常,如损失函数值是否在降低,也可以打印一些中间步骤的结果出来等。
- 模型评估 :使用测试集数据测试训练好的神经网络,看看训练效果如何。
- 模型预测 :取出一条文本数据,放入模型后进行预测,观察预测的情感倾向值。
在数据处理前,需要先加载飞桨平台(如果用户在本地使用,请确保已经安装飞桨)。
- import os
- import random
- import numpy as np
- import pandas as pd
- # 导入Paddle的API
- import paddle
- import paddle.nn as nn
- import paddle.nn.functional as F
- from paddle.nn import LSTM, Embedding, Dropout, Linear
-
- from paddlenlp.datasets import load_dataset
- from paddlenlp.utils.downloader import get_path_from_url
3.1 数据处理
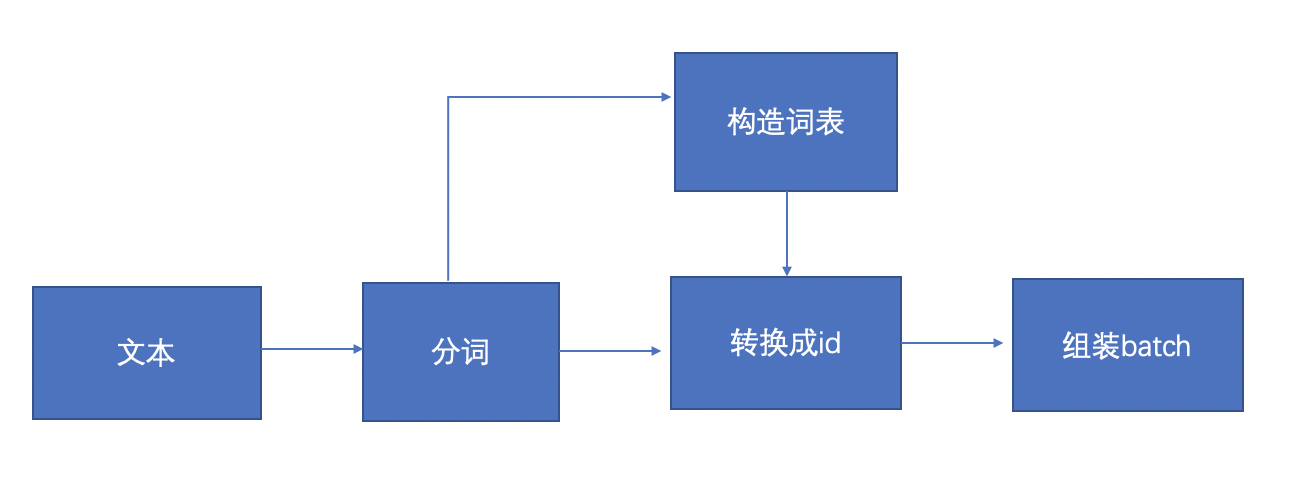
图9:数据处理流程
上图显示的是数据处理的流程,首先是输入文本,根据输入的文本数据进行分词,分词完以后构造词表,然后根据词表把分词后的文本映射成id的形式,然后再组装成batch形式的数据。
1.分词:使用结巴分词工具,把句子切分成单词的形式。
2.构造词表:将单词形式的句子,统计频率,按照频率取topK个单词,作为词表,剩下的低频单词舍弃,并给每个单词编一个号。
3.转换成id:主要是利用构造的词汇表,对分好词的数据映射成相应的id的形式。
4.组装batch:组装成一个batch数据(多条数据堆叠在一起),但是每个句子有长有短,对于较短的句子,我们需要补0对齐。
3.1.1 加载数据集
首先,需要下载语料用于模型训练和评估效果。我们使用的是ChnSentiCorp的酒店评论数据,这个数据集是一个开源的中文数据集,由训练数据,验证集和测试数据组成。训练集的数量是9601条,验证集的数量是1201条,测试集的数量是1201条。每个数据表示的是用户对酒店的真实评价,以及用户对酒店的情感倾向(是正向还是负向),数据集下载的代码如下:
- URL = "https://bj.bcebos.com/paddlenlp/datasets/ChnSentiCorp.zip"
- # 如果数据集不存在,就下载数据集并解压
- if(not os.path.exists('ChnSentiCorp.zip')):
- get_path_from_url(URL,root_dir='.')
- def read(split='train'):
- data_dict={'train':'ChnSentiCorp/ChnSentiCorp/train.tsv',
- "dev":'ChnSentiCorp/ChnSentiCorp/dev.tsv',
- 'test':'ChnSentiCorp/ChnSentiCorp/test.tsv'}
- with open(data_dict[split],'r') as f:
- head = None
- # 一行一行的读取数据
- for line in f.readlines():
- data = line.strip().split("\t")
- # 跳过第一行,因为第一行是列名
- if not head:
- head = data
- else:
- # 从第二行还是一行一行的返回数据
- if split == 'train':
- label, text = data
- yield {"text": text, "label": label, "qid": ''}
- elif split == 'dev':
- qid, label, text = data
- yield {"text": text, "label": label, "qid": qid}
- elif split == 'test':
- qid, text = data
- yield {"text": text, "label": '', "qid": qid}
-
-
- train_ds= load_dataset(read, split="train",lazy=False)
- dev_ds= load_dataset(read, split="dev",lazy=False)
- test_ds= load_dataset(read, split="test",lazy=False)
接下来,将数据集加载到程序中,并打印一小部分数据观察一下数据集的特点,代码如下:
- for data in train_ds.data[:5]:
- print(data)
{'text': '选择珠江花园的原因就是方便,有电动扶梯直接到达海边,周围餐馆、食廊、商场、超市、摊位一应俱全。酒店装修一般,但还算整洁。 泳池在大堂的屋顶,因此很小,不过女儿倒是喜欢。 包的早餐是西式的,还算丰富。 服务吗,一般', 'label': '1', 'qid': ''}
{'text': '15.4寸笔记本的键盘确实爽,基本跟台式机差不多了,蛮喜欢数字小键盘,输数字特方便,样子也很美观,做工也相当不错', 'label': '1', 'qid': ''}
{'text': '房间太小。其他的都一般。。。。。。。。。', 'label': '0', 'qid': ''}
{'text': '1.接电源没有几分钟,电源适配器热的不行. 2.摄像头用不起来. 3.机盖的钢琴漆,手不能摸,一摸一个印. 4.硬盘分区不好办.', 'label': '0', 'qid': ''}
{'text': '今天才知道这书还有第6卷,真有点郁闷:为什么同一套书有两种版本呢?当当网是不是该跟出版社商量商量,单独出个第6卷,让我们的孩子不会有所遗憾。', 'label': '1', 'qid': ''}
text表示的是评论文本,label表示的是标签,1表示文本的情感倾向是正向的,0表示文本的情感倾向是负向的。qid表示数据的编号,qid出现在测试集中,在训练集合里面数据的编号没有,所以qid为空。
3.1.2 构造词表
读取数据后,需要构造一个词典,把每个词都转化成一个ID,以便于神经网络训练。代码如下:
注意:
在代码中我们使用了一个特殊的单词"[UNK]",用于表示词表中没有覆盖到的词。之所以使用"[UNK]"这个符号,是为了处理某一些词,在测试数据中有,但训练数据没有的现象。
In [5]
- from collections import defaultdict
- import jieba
- from paddlenlp.data import Vocab
-
- def build_vocab(texts,
- stopwords=[],
- num_words=None,
- min_freq=10,
- unk_token="[UNK]",
- pad_token="[PAD]"):
- word_counts = defaultdict(int)
- for text in texts:
- if not text:
- continue
- # # 统计词频
- # 一般来说,在自然语言处理中,需要先对语料进行切词,英文可以使用空格把每个句子切成若干词的序列
- # 对于中文则需要使用结巴分词进行切分
- for word in jieba.cut(text):
- if word in stopwords:
- continue
- word_counts[word] += 1
- # 过滤掉词频小于min_freq的单词
- wcounts = []
- for word, count in word_counts.items():
- if count < min_freq:
- continue
- wcounts.append((word, count))
- # 把单词按照词频从大到小进行排序
- wcounts.sort(key=lambda x: x[1], reverse=True)
- # 把对齐的字符和unk字符加入到词表中
- if num_words is not None and len(wcounts) > (num_words - 2):
- wcounts = wcounts[:(num_words - 2)]
- # pad字符和unk字符
- sorted_voc = [pad_token, unk_token]
- sorted_voc.extend(wc[0] for wc in wcounts)
- # 给每个单词一个编号
- word_index = dict(zip(sorted_voc, list(range(len(sorted_voc)))))
- return word_index
-
- texts = []
- for data in train_ds:
- texts.append(data["text"])
- for data in dev_ds:
- texts.append(data["text"])
-
- # 以下停用词仅用作示例,具体停用词的选择需要根据具体语料库调整。
- stopwords = set(["的", "吗", "吧", "呀", "呜", "呢", "呗"])
- # 构建词汇表
- word2idx = build_vocab(
- texts, stopwords, min_freq=5, unk_token="[UNK]", pad_token="[PAD]")
- vocab = Vocab.from_dict(word2idx, unk_token="[UNK]", pad_token="[PAD]")
- # 保存词汇表
- res=vocab.to_json("./vocab.json")
Building prefix dict from the default dictionary ...
Loading model from cache /tmp/jieba.cache
Loading model cost 0.778 seconds.
Prefix dict has been built successfully.
3.1.3 分词并转换成id
在完成word2id词典假设之后,我们还需要进一步处理原始语料,把语料中的所有句子都处理成ID序列,代码如下:
在转换成id之前,我们先通过下面的示例认识一下JiebaTokenizer:
- from paddlenlp.data import JiebaTokenizer
-
- def get_idx_from_word(word, word_to_idx, unk_word):
- if word in word_to_idx:
- return word_to_idx[word]
- return word_to_idx[unk_word]
-
- # 把词汇表加载到结巴分词器中
- tokenizer = JiebaTokenizer(vocab)
- text='选择珠江花园的原因就是方便,有电动扶梯直接到达海边,周围餐馆、食廊、商场、超市、摊位一应俱全。'
- segment_text=tokenizer.cut(text)
- print("分词后的文本:{}".format(segment_text))
- input_ids = [get_idx_from_word(word,vocab.token_to_idx,vocab.unk_token) for word in segment_text]
- print("把分词后的文本转换成id:{}".format(input_ids))
-
- input_ids = tokenizer.encode(text)
- print("encode 编码后的id: {}".format(input_ids))
分词后的文本:['选择', '珠江', '花园', '的', '原因', '就是', '方便', ',', '有', '电动', '扶梯', '直接', '到达', '海边', ',', '周围', '餐馆', '、', '食廊', '、', '商', '场', '、', '超市', '、', '摊位', '一应', '俱全', '。']
把分词后的文本转换成id:[198, 1, 1595, 1, 406, 38, 105, 2, 16, 1, 1, 349, 987, 1699, 2, 663, 3103, 26, 1, 26, 1, 6212, 26, 1453, 26, 1, 1, 1, 3]
encode 编码后的id: [198, 1, 1595, 1, 406, 38, 105, 2, 16, 1, 1, 349, 987, 1699, 2, 663, 3103, 26, 1, 26, 1, 6212, 26, 1453, 26, 1, 1, 1, 3]
从上述的输出可以看到JiebaTokenizer的encode的作用就是对文本进行分词,然后根据词汇表把文本转换成id的形式。
- from functools import partial
-
- # 把语料转换为id序列
- def convert_example(example, tokenizer, is_test=False):
- # 将句子中的词逐个替换成id,如果句子中的词不在词表内,则替换成[UNK]
- input_ids = tokenizer.encode(example["text"])
- # 计算出数据转换成id后的长度,并转换成numpy的格式
- valid_length = np.array(len(input_ids), dtype='int64')
- # 把id形式的数据转换成numpy的形式
- input_ids = np.array(input_ids, dtype='int64')
- # 训练集需要label
- if not is_test:
- label = np.array(example["label"], dtype="int64")
- return input_ids, valid_length, label
- else:
- # 测试集不需要label
- return input_ids, valid_length
-
- # partial函数的意思是把tokenizer=tokenizer, is_test=False赋值给当前的convert_example函数
- trans_fn = partial(convert_example, tokenizer=tokenizer, is_test=False)
- # 训练数据转换成id的形式
- train_ds = train_ds.map(trans_fn)
- # 验证集转换成id的形式
- dev_ds = dev_ds.map(trans_fn)
3.1.4 组装成mini-batch
接下来,我们就可以开始把原始语料中的每个句子通过截断和填充,转换成一个固定长度的句子,并将所有数据整理成mini-batch,用于训练模型,代码如下:
在组装minit-batch数据之前,我们先介绍一下需要使用的API,Stack, Pad, Tuple,Stack的功能是把向量堆叠在一起,Pad的功能是把不同长度的向量填充补齐,Tuple的功能是将多个batchify函数(比如Pad,Stack)包装在一起,示例如下:
- from paddlenlp.data import Stack, Pad, Tuple
-
- # 构建a,b,c三个向量
- a = [1, 2, 3, 4]
- b = [3, 4, 5, 6]
- c = [5, 6, 7, 8]
- result = Stack()([a, b, c])
- print("堆叠(Stacked)数据后 : \n", result)
- print()
-
- # 构建a,b,c三个向量
- a = [1, 2, 3, 4]
- b = [5, 6, 7]
- c = [8, 9]
- result = Pad(pad_val=0)([a, b, c])
- print("对齐(Padded)数据后: \n", result)
- print()
-
- # 构造一个小的样本,包含输入id和label
- data = [
- [[1, 2, 3, 4], [1]],
- [[5, 6, 7], [0]],
- [[8, 9], [1]],
- ]
- batchify_fn = Tuple(Pad(pad_val=0), Stack())
- ids, labels = batchify_fn(data)
- print("id的输出: \n", ids)
- print()
- print("标签的输出: \n", labels)
- print()
堆叠(Stacked)数据后 :
[[1 2 3 4]
[3 4 5 6]
[5 6 7 8]]
对齐(Padded)数据后:
[[1 2 3 4]
[5 6 7 0]
[8 9 0 0]]
id的输出:
[[1 2 3 4]
[5 6 7 0]
[8 9 0 0]]
标签的输出:
[[1]
[0]
[1]]
- batch_size = 64
- batchify_fn = lambda samples, fn=Tuple(
- Pad(axis=0, pad_val=vocab.token_to_idx.get('[PAD]', 0)), # 表示在一个mini-batch与最长的那条数据对齐,长度不够的话用0来补齐
- Stack(dtype="int64"), # seq len
- Stack(dtype="int64") # label
- ): [data for data in fn(samples)]
-
- # 训练集的sampler,迭代式获取mini-batch的样本下标数组,数组长度与 batch_size 一致
- train_sampler = paddle.io.BatchSampler(
- dataset=train_ds, batch_size=batch_size, shuffle=True)
- # 测试集的sampler,迭代式获取mini-batch的样本下标数组,数组长度与 batch_size 一致
- test_sampler = paddle.io.BatchSampler(
- dataset=dev_ds, batch_size=batch_size, shuffle=True)
- # 使用paddle.io.DataLoader接口多线程异步加载数据
- # DataLoader根据 batch_sampler 给定的顺序迭代一次给定的 dataset
- train_loader = paddle.io.DataLoader(
- train_ds, batch_sampler=train_sampler, collate_fn=batchify_fn)
- # 使用验证集作为测试集,因为验证集包含label。而原来的测试集没有label,不方便算指标
- test_loader = paddle.io.DataLoader(
- dev_ds, batch_sampler=test_sampler, collate_fn=batchify_fn)
- # 打印输出一个mini-batch的数据
- for idx,item in enumerate(train_loader):
- if(idx==0):
- print(item)
- # break
[Tensor(shape=[64, 276], dtype=int64, place=CUDAPinnedPlace, stop_gradient=True,
[[1 , 1720, 260 , ..., 0 , 0 , 0 ],
[86 , 3144, 29 , ..., 0 , 0 , 0 ],
[55 , 567 , 1 , ..., 0 , 0 , 0 ],
...,
[327 , 1 , 494 , ..., 0 , 0 , 0 ],
[90 , 26 , 86 , ..., 0 , 0 , 0 ],
[1 , 1 , 177 , ..., 0 , 0 , 0 ]]), Tensor(shape=[64], dtype=int64, place=CUDAPinnedPlace, stop_gradient=True,
[30 , 30 , 69 , 113, 39 , 30 , 96 , 114, 54 , 118, 102, 32 , 25 , 61 ,
276, 56 , 48 , 52 , 242, 123, 35 , 39 , 107, 49 , 20 , 17 , 94 , 32 ,
85 , 116, 35 , 47 , 26 , 160, 66 , 87 , 38 , 37 , 185, 16 , 43 , 90 ,
103, 37 , 38 , 67 , 115, 39 , 46 , 121, 28 , 29 , 60 , 37 , 22 , 46 ,
61 , 80 , 22 , 14 , 35 , 59 , 58 , 124]), Tensor(shape=[64], dtype=int64, place=CUDAPinnedPlace, stop_gradient=True,
[0, 1, 0, 1, 0, 1, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0, 1, 0, 0, 1, 0, 0, 1, 1,
0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 0, 1, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 1, 1,
0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1])]
上面是迭代器的输出,可以看到输出的数据第一个Tensor中的batch size的大小是64,每条数据的长度是432;第二个Tensor存放的是每条数据实际长度,第三个Tensor表示的是每条数据的label,总共64个label。
[3] 对一个句子生成一个单一的向量表示有什么缺点,你还知道其他方式吗?

