
- 1前端vue后端express项目服务器部署操作_前端vue3,后端express
- 2时间戳校验和计算
- 3STM32的QSPI在dual-flash双闪存模式下读写寄存器描述,译自H743参考手册_qspi双闪存模式
- 4推荐系统!基于tensorflow搭建混合神经网络精准推荐!_tenserflow 做内容推荐
- 52-报错“a component required a bean of type ‘微服务名称‘ that could”_微服务 启动报错a component required a bean of type 'com.s
- 6unity3d中平滑跟随的功能实现!!!!_smooth follow unity
- 7git命令大全(非常齐全)_linlin@tiger versa-activity % git pull feature/sig
- 8java正则验证时间戳_时间戳和正则表达式
- 910个python入门小游戏,零基础打通关,就能掌握编程基础_python编写的入门简单小游戏_python编程小游戏简单的
- 10Postgresql排序与limit组合场景性能极限优化_posterger limit
YOLOv5模型简述_yolov5概述
赞
踩
一、模型背景
YOLOv5是一个计算机视觉模式设计的对象检测任务,它是YOLO系列的升级版,YOLO系列以其实时物体检测能力而著称。YOLOv5由Ultralytics开发,并于2020年年中发布。
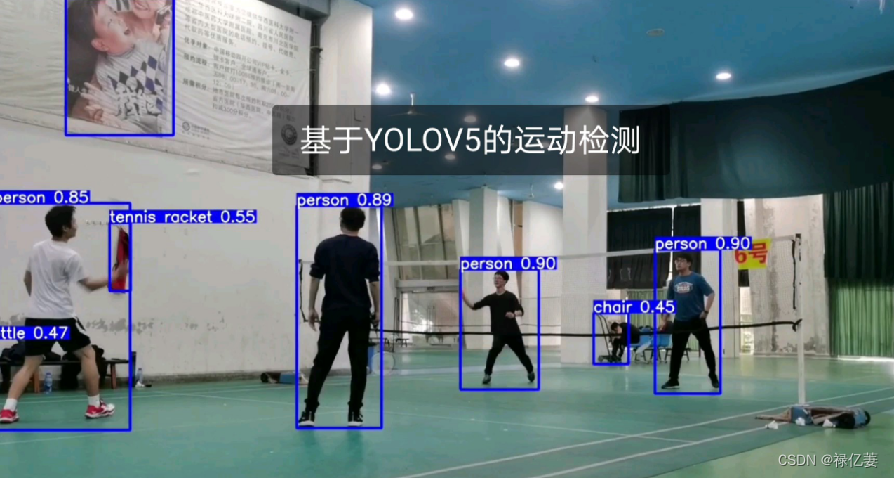
如上图所示,基于YOLOv5的运动检测,检测出了person、tennis rocket、chair等等,检测结果相对准确。
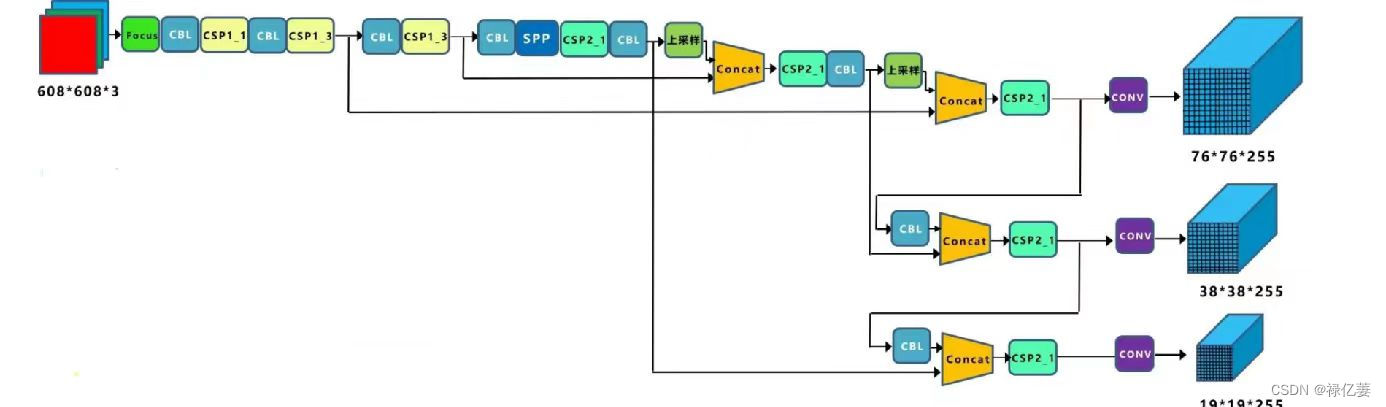
二、网络模型
模型主要结构分为:Input、Backbone、Neck、Head
整体模型结果图如下:
2.1 Input
输入端:Mosaic数据增强、自适应锚框计算、自适应图片缩放
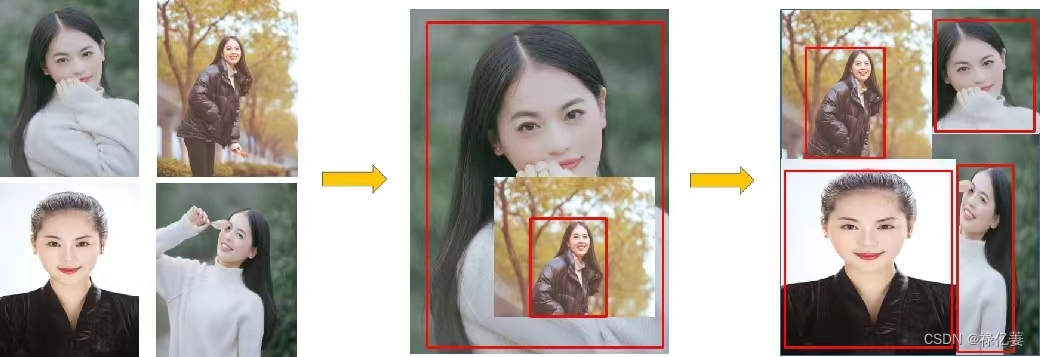
(1)Mosaic数据增强
采用4张图片,按照随机缩放、随机裁剪和随机排布的方式进行拼接,不仅可以丰富数据集,极大的提升网络训练速度,还降低了模型内存。
(2)自适应锚框计算
在Yolo算法中,针对不同的数据集,都会有初始设定长宽的锚框。在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框groundtruth进行比对,计算两者差距,再反向更新,迭代网络参数。
(3)自适应图片缩放
第一步:计算缩放比例

原始缩放尺寸是416*416,都除以原始图像的尺寸后,可以得到0.52,和0.69两个缩放系数,选择小的缩放系数。
第二步:计算缩放后的尺寸
![]()
原始图片的长、宽都乘以最小的缩放系数0.52,宽变成了416,而高变成了312。
第三步:计算填充数值
![]()
将416-312=104,得到原本需要填充的高度。再采用numpy中np.mod取余数的方式,得到8个像素,再除以2,即得到图片高度两端需要填充的数值。图像高度上两端的填充越少,在推理时,计算量也会减少,即目标检测速度会得到提升。
2.2 Backbone
Backbone主要由Focus结构和CSP结构组成,网络模型图如下:
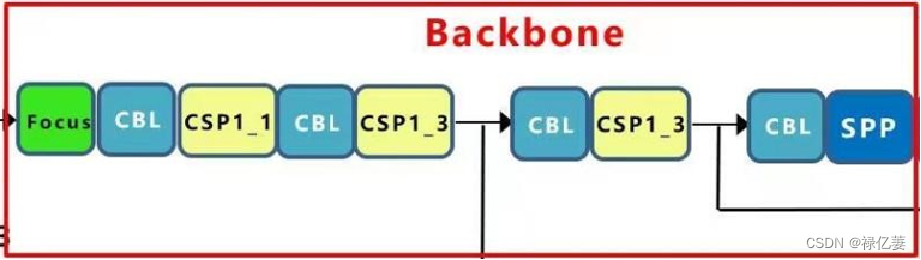
(1)Focus结构:

Focus模块是对图片进行切片操作,具体操作是在一张图片中每隔一个像素拿到一个值,类似于邻近下采样,这样就拿到了4张图片,四张图片互补,没有信息丢失,这样使得W,H信息就集中到了通道空间,输入通道扩充了4倍,即拼接起来的图片相对于原先的RGB三通道模式变成了12个通道,最后将得到的新图片再经过卷积操作,最终得到了没有信息丢失情况下的二倍下采样特征图。
(2)CSP结构
首先,介绍一些基础组件:
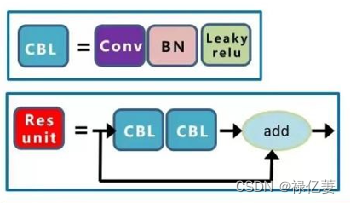
CBL:CBL模块是由Conv+BN+Leaky_relu激活函数组成,卷积层是卷积神经网络中最基础的层之一,用于提取输入特征中的局部空间信息。BN层是在卷积层之后加入的一种归一化层,用于规范化神经网络中的特征值分布。激活函数是一种非线性函数,用于给神经网络引入非线性变换能力。
Res_unit:借鉴ResNet中的残差结构,用来构建深层网络。
其次,CSP结构将feature map特征图拆成两个部分,一部分进行卷积操作,另一部分和上一部分卷积操作的结果进行concate。分类问题中,使用CSPNet可以降低计算量,但是准确率提升很小;在目标检测问题中,使用CSPNet作为Backbone带来的提升比较大,可以有效增强CNN的学习能力,同时也降低了计算量。

Yolov5中设计了两种CSP结构,以Yolov5s网络为例,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。
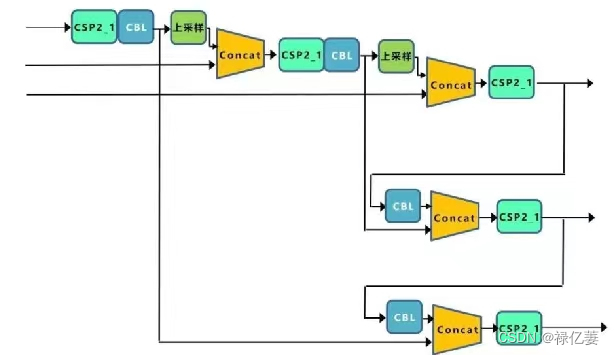
2.3 Neck
Yolov5的Neck结构中,采用借鉴CSPnet设计的CSP2结构,加强网络特征融合的能力。 Neck结构:结构包括SPP、FPN、PAN,Neck网络结构图如下:
(1)SPP
SPP结构又被称为空间金字塔池化,能将任意大小的特征图转换成固定大小的特征向量;借鉴了残差网络的思想,提高的网络面临深度的增加使网络退化的问题,缓解了梯度消失;其结构示意图如下:
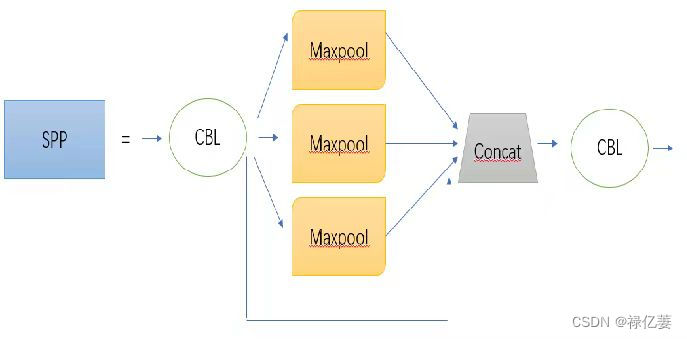

SPP处理,提高了图像的尺度不变和降低了过拟合。
(2)FPN、PAN
由于物体在图像中的大小和位置是不确定的,因此需要一种机制来处理不同尺度和大小的目标。特征金字塔是一种用于处理多尺度目标检测的技术,它可以通过在骨干网络上添加不同尺度的特征层来实现。在Yolov5中,采用的是FPN(Feature Pyramid Network)特征金字塔结构,通过上采样和下采样操作将不同层次的特征图融合在一起,生成多尺度的特征金字塔。
FPN: 结合多层级特征来解决多尺度问题的特征金字塔模型,浅层或者说前级过来的特征图利于定位,深层特征图(此级特征图)包含高级语义信息,这是利于小目标的;PAN:为了解决小目标的效果,对FPN网络进行了补充(补充点主要为对于定位信息)。
自上向下部分主要是通过上采样和与更粗粒度的特征图融合来实现不同层次特征的融合,而自下向上则是通过使用一个卷积层来融合来自不同层次的特征图。FPN属于上采样,PAN属于下采样; 结构示意图如下:

在目标检测算法中,Neck模块通常被用于将不同层级的特征图结合起来,生成具有多尺度信息的特征图,以提高目标检测的准确率。
2.4 Head
(1)nms非极大值抑制
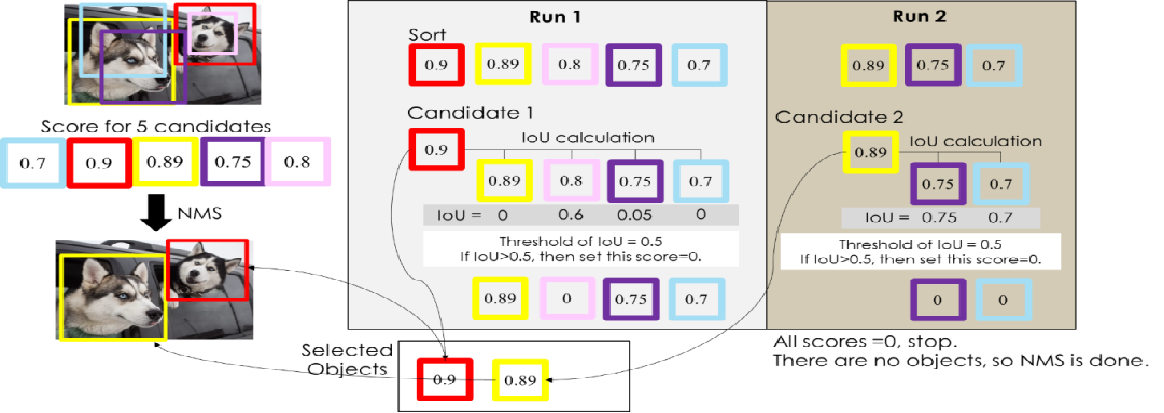
在目标检测的后处理过程中,针对很多目标框的筛选,通常需要nms操作。NMS 的本质是搜索局部极大值,抑制非极大值元素。非极大值抑制,主要就是用来抑制检测时冗余的框,只保留最具有代表性的边界框。因为在目标检测中,在同一目标的位置上会产生大量的候选框,这些候选框相互之间可能会有重叠,所以我们需要利用非极大值抑制找到最佳的目标边界框,消除冗余的边界框。
算法流程:
1.对所有预测框的置信度降序排序。
2.选出置信度最高的预测框,确认其为正确预测,并计算他与其他预测框的 IOU。
3.根据步骤2中计算的 IOU 去除重叠度高的,IOU > threshold 阈值就直接删除。
4.剩下的预测框返回第1步,直到没有剩下的为止。
(2)损失函数
Yolov5中采用CIOU_Loss做Bounding_box的损失函数:


其中,C:预测框和真实框的最小外接矩形;Distance_2:预测框的中心点和真实框的中心点的欧氏距离 ;Distance_C:C的对角线距离; v:(w为宽,h为高,l为真实框,p为预测框)长宽比影响因子; IOU是交并比,预测的物体框框和真实的物体框框的交集的面积与并集的面积之比。
CIOU_Loss考虑了重叠面积,宽高比和中心点距离多方面因素,使算法性能更加成熟。
Yolov5的损失函数主要由三个部分组成:
(1)loc_loss,边界框损失,网络预测的目标边界框与真实框GT_Box的CIOU_Loss。
(2)obj_loss,置信度损失,置信度表征所预测矩形框的可信程度,取值范围是0~1,值越大说明该矩形框中越可能存在目标。
(3)cls_loss,分类损失。
![]()
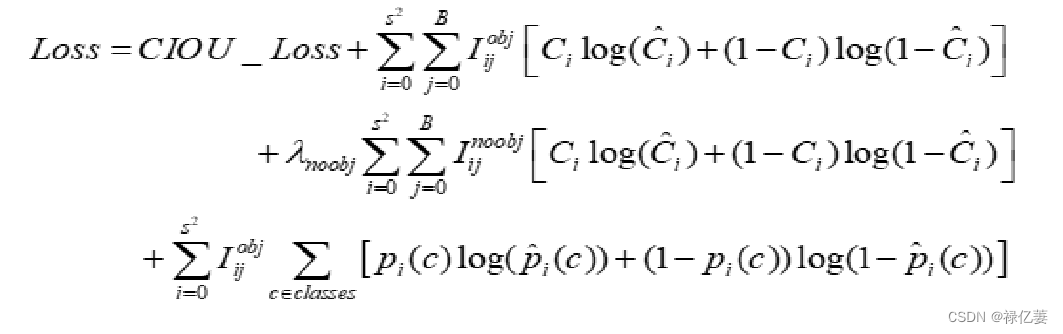
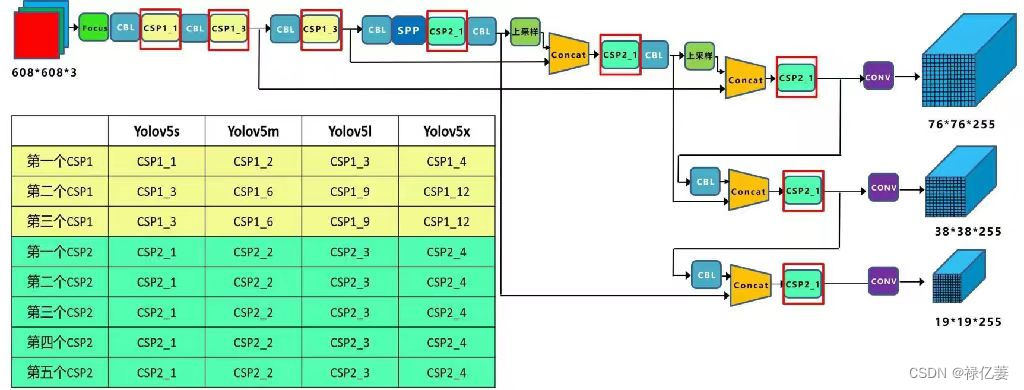
三、模型对比
Yolov5给出了四种版本的目标检测网络,分别是Yolov5s、Yolov5m、Yolov5l、Yolov5x四个模型。其中,Yolov5s是深度最浅,特征图的宽度最窄的网络,后面在此基础上不断加深、加宽。
(1)Yolov5四种网络的深度
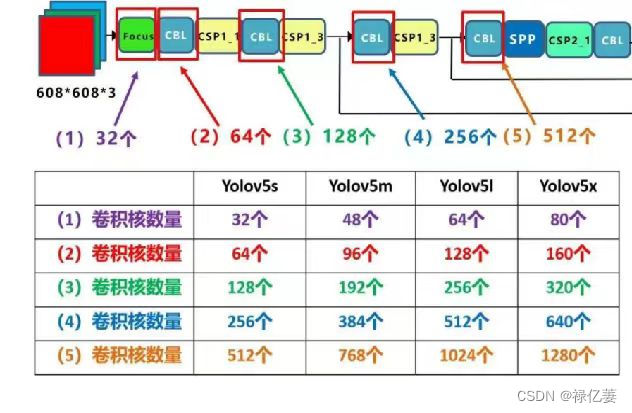
(2)Yolov5四种网络的宽度
不同版本的 YOLOv5 在 COCO 数据集上和 GPU 平台上的模型精度和速度实验结果曲线如下所示:
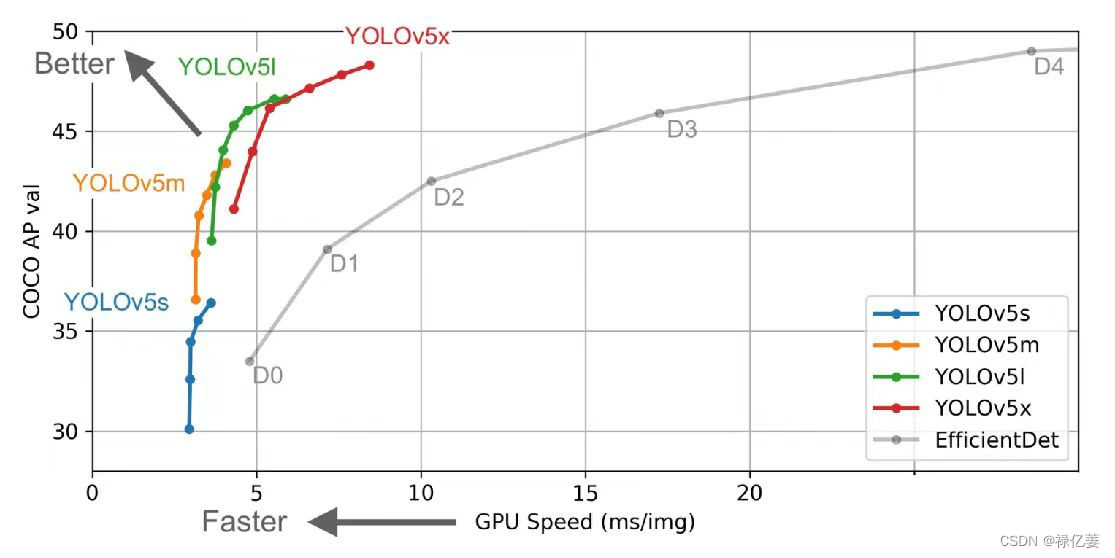
通过速度和精度的对比,可以得出:网络越小,速度越快,精度越低。
四、预测结果
第一张图片是yolov5官方预测结果图,第二张图片是电路板自定义数据集预测结果图。


总体而言,预测相对准确。
五、模型总结
Yolov5网络主要由以下几个部分组成:
输入端:Mosaic数据增强、自适应锚框计算、自适应图片缩放;
Backbone:Focus结构、CSP结构;
Neck:FPN+PAN结构;
Head:CIOU_Loss。
Yolov5是一种高效、准确的目标检测算法,它在模型结构和训练策略上进行了改进并取得了很好的性能。它已经成为目标检测领域的研究热点,并得到了广泛的应用和推广。

