
- 1Stable diffusion报Torch is not able to use GPU; add --skip-torch-cuda-test to COMMANDLINE_ARGS variab_runtimeerror: torch is not able to use gpu; add --
- 2【C语言】八道经典指针笔试题(详解)_c语言指针例题及解析
- 3硬件越跑越快,软件越陷越慢
- 4can 常见面试题_can总线面试问题
- 5【Java前端技术栈】ES6-ECMAScript6.0
- 6LLM之RAG理论(四)| RAG高级数据索引技术
- 7解决pip超时的问题_pip-23.2.1-py3-none-any.whl
- 8python:threading.Thread类的使用详解_python-threading
- 9远程连接ECS服务器提示了Connection refused,怎么办?_远程桌面connection refused
- 10debian10安装x ui失败_debian 10x-ui安装命令
12 Python正则表达式_python searchall
赞
踩
1、介绍
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),主要功能是通过匹配规则来获取或验证字符串中的数据。
这我们就知道了,要想成功进行字符串的匹配,需要正则表达式模块,正则表达的匹配规则,以及需要被匹配的字符串。
在这三个条件中,模块和字符串都是准备好的,只需要匹配规则异常的灵活。
2、特殊字符
首先我们来学习正则表达式里的特殊字符,通过这些特殊字符就可以针对我们想要的数据进行匹配。
首先来看一下正则表达式里都有哪些常用的特殊字符。
| 特殊字符 | 描述 |
|---|---|
| /d | 匹配任何十进制数字,与【0-9】一致 |
| /D | 匹配任意数字 |
| /w | 匹配任何字母数字下划线以及unicode字符集 |
| /W | 匹配任何非字母数字以及下划线 |
| /s | 匹配任何空格字符,与【\n\t\r\v\f】相同 |
| /S | 匹配任意字符 |
| \A | 匹配字符串的起始 |
| \Z | 匹配字符串的结束 |
| . | 匹配任何字符串 |
代码演示:
import re
# 准备需要被匹配的字符串
data = 'hello jie you are 22 age old'
# 匹配任何十进制数字,与【0-9】一致
print(re.findall('\d', data))
# 匹配任何空格字符
print(re.findall('\s', data))
# 匹配任何字母数字下划线以及unicode字符集
print(re.findall('\w', data))
# 匹配字符串的起始
print(re.findall('\Ahello', data))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
执行结果:

3、量词符号与组
细心的大家一定发现上面的代码的执行效果,我们获获取的每一个匹配信息都是一个单纯的字符存到我们的结果中的。
那我们如何才能根据我们的词组进行匹配呢?
接下来我们就来认识量词符号与组的概念。
3.1 量词符号
| 符号 | 描述 |
|---|---|
| re1|re2 | 匹配正则表达式re1 或者 re2 |
| ^ | 匹配字符串起始部分 |
| $ | 匹配字符串终止部分 |
| * | 匹配0次或者多次前面出现的正则表达式 |
| + | 匹配一次或者多次前面出现的正则表达式 |
| {N} | 匹配N次前面出现的正则表达式 |
| {M,N} | 给出匹配到的数据范围 |
| […] | 匹配来自字符集的任意单一字符 |
| […x-y…] | 匹配x~y范围中的任意单一字符 |
| [^…] | 不匹配此字符集中出现的任何一个字符, 包括某一范围的字符(如果在此字符集中出现) |
| \ | 将特殊字符无效化 |
代码演示:
import re
# 准备需要被匹配的字符串
data = 'hello jie you are 22 age old'
# 匹配正则表达式 re1 或者 re2 注意 : 匹配的数据只按字符串数据返回,而不是按照匹配规则返回
print(re.findall('hello|jie|21', data))
# 匹配字符串起始部分
print(re.findall('^hello', data))
# 匹配字符串终止部分
print(re.findall('old$', data))
# W* 匹配0次或多次数字或字母
print(re.findall('\w*', data))
# W+ 匹配一次或者多次数字或字母 空属于0次范围不会配匹配出来
print(re.findall('\w+', data))
# 对于匹配到的数据只获取3个
print(re.findall('\w{3}', data))
# 匹配a~z范围中的任意单一字符 [a-zA-Z0-9]等同于\w
print(re.findall('[a-z]{3}', data))
# 匹配1或者5次 {N,M}中间的逗号左右不要出现空格
print(re.findall('\w{1,5}', data))
# 不匹配此字符集中出现的任何一个字符 字符集中的^号不代表开始的意思而是过滤掉
print(re.findall('[^jie]', data))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
执行效果:

3.2 组
| 符号 | 描述 |
|---|---|
| () | 在匹配规则中获取指定的数据 |
看这描述可能会有点懵,我们直接看代码演示:
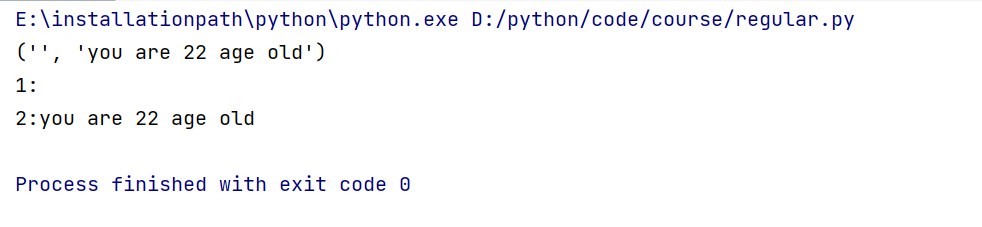
import re
# 准备需要被匹配的字符串
data = 'hello jie you are 22 age old'
# search 获取组
result = re.search('hello (.*)jie (.*)', data)
print(result.groups())
print("1:" + result.group(1))
print("2:" + result.group(2))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
执行结果:
4、正则表达式模块
4.1 findall()的使用
findall 函数 我们之前已经接触过了。
findall(pattern ,String,[flags])
它需要我们传三个参数:
- 匹配规则
- 需要被匹配的字符串
- re的额外匹配要求
findall 会查找字符串中所有(非重复)出现的正则表达式模式,并返回一个匹配列表。
4.2 search()的使用
search(pattern ,String,flags=0)
search函数与我们findall函数所需传入的参数相同。
- 匹配规则
- 需要被匹配的字符串
- re的额外匹配要求
search 函数 使用可选的标记搜索字符串中第一次出现的字符串中第一次出现的正则表达式模式。如果匹配成功,则返回匹配对象;如果失败,则返回None。
4.3 group()与groups()的使用
group(num): group + 一个数字返回整个匹配对象或者编号为numb的特定子组。
groups():返回一个包含所有匹配子组的元组(如果没有匹配成功,则返回一个空元组)。
4.4 split()正则替换
split(pattern,String,max=0)
- 匹配规则
- 需要被匹配的字符串
- 默认0。如果默认=0的情况下式代表匹配所有能匹配到的信息
根据正则表达式的模式分隔符,split 函数将字符串分隔为列表,然后返回成功匹配的列表,分隔最多操作max 次 (默认分隔所有匹配成功的位置)。
代码演示:
import re
# 准备需要被匹配的字符串
data = 'hello jie you are 22 age old'
print(re.split('\W', data))
- 1
- 2
- 3
- 4
- 5
- 6
执行效果:

4.5 compile 的使用
compile (pattern,flags=0)
- 匹配规则
- re的额外匹配要求
定义一个匹配规则的对象。
我们之前定义的pattern 都是一个字符串被传进去的,但是我们的compile函数会把我们匹配的这个字符串变成一个匹配规则的对象。
接下里我们只需要调用这个对象去传入被匹配的字符串,就可以匹配出我们相应的信息了。
代码演示:
import re
# 准备需要被匹配的字符串
data = 'hello jie you are 22 age old'
# ? 可将贪婪模式转为非贪婪模式 就是匹配多次转为匹配一次
re_obj = re.compile('hello (.*?) you')
result = re_obj.findall(data)
print(result)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
执行效果:

4.6 match的使用
match(pattern,String,flags=0)
- 匹配规则
- 需要被匹配的字符串
- re的额外匹配要求
match只会匹配字符串从头开始的信息,如果匹配成功则会返回匹配对象,匹配失败就会返回null。
并且match返回的正则对象也可以通过group函数来调用。
代码演示:
import re
# 准备需要被匹配的字符串
data = 'hello jie you are 22 age old'
result = re.match('hello', data)
print(result.group())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
执行效果:

4.7 re的额外匹配要求
re模块的额外匹配要求,其实这些匹配要求都是一些属性,一般情况下使用率不高,了解即可。
| 属性 | 描述 |
|---|---|
| re.I 、re.IGNORECASE | 不区分大小写的匹配 |
| re.L、re.LOCALE | 根据所使用的本地语言环境通过\w、\W、\s、\S实现匹配 |
| re.M、re.MULTILINE | ^和$分别匹配目标字符串中行的起始和结尾,而不是严格匹配整个字符串本身的起始和结尾。 |
| re.S、rer.DOTALL | “.”(点号)通常匹配除了\n(换行符)之外的所有单个字符;该标记表示"."(点号)能够匹配全部字符 |
| re.X、re.VERBOSE | 忽略规则表达式中的空白和注释 |

