
热门标签
热门文章
- 1四、张量表示_张量显示
- 2FastDFS【FastDFS概述(简介、核心概念 、上传机制 、下载机制)】(一)-全面详解(学习总结---从入门到深化)
- 3使用openvpn连通多个机房内网
- 4linux中clear报错:terminals database is inaccessible的解决方法
- 5OpenWrt下mwan3定时重启_openwrt定时重启
- 6android从strings资源文件获取,并拼接字符串方法_android 从资源文件拼接string
- 7SQLite3移植到ARM Linux教程_sqlite3数据库移植到arm
- 8【Linux】list_for_each_entry用法
- 9Linux | firewall命令 对外开放端口、查看端口、防火墙开启、防火墙关闭_firewall永久开放端口
- 10GitHub上受欢迎的Android UI Library_github 上最受欢迎的android ui
当前位置: article > 正文
python统计分析——使用AIC进行模型选择
作者:笔触狂放9 | 2024-02-23 04:50:03
赞
踩
python统计分析——使用AIC进行模型选择
参考资料:用python动手学统计学
1、导入库
- # 导入库
- # 用于数值计算的库
- import numpy as np
- import pandas as pd
- import scipy as sp
- from scipy import stats
- # 用于绘图的库
- import matplotlib.pyplot as plt
- import seaborn as sns
- sns.set()
- # 用于估计统计模型的库
- import statsmodels.formula.api as smf
- import statsmodels.api as sm
2、数据准备
- data=pd.DataFrame({
- 'beer':np.array([45.3, 59.3, 40.4, 38. , 37. , 40.9, 60.2, 63.3, 51.1, 44.9, 47. ,
- 53.2, 43.5, 53.2, 37.4, 59.9, 41.5, 75.1, 55.6, 57.2, 46.5, 35.8,
- 51.9, 38.2, 66. , 55.3, 55.3, 43.3, 70.5, 38.8]),
- 'temp':np.array([20.5, 25. , 10. , 26.9, 15.8, 4.2, 13.5, 26. , 23.3, 8.5, 26.2,
- 19.1, 24.3, 23.3, 8.4, 23.5, 13.9, 35.5, 27.2, 20.5, 10.2, 20.5,
- 21.6, 7.9, 42.2, 23.9, 36.9, 8.9, 36.4, 6.4])
- })
- data.head()
4、建立线性模型
- # 利用普通最小二乘法(ordinary least squares)拟合线性模型
- lm=smf.ols(formula="beer ~ temp",data=data).fit()
- # 查看模型的AIC值
- lm.aic
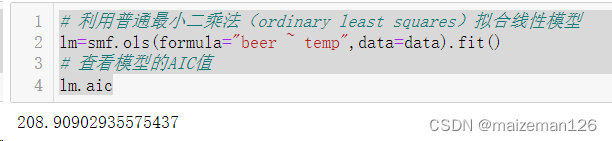
现在模型里只有temp(气温)这一个解释变量,我们不妨对比一下它和空模型的AIC。下面建立一个空模型,当没有解释变量时,定位“beer~1”。
- # 设置空模型
- null_model=smf.ols("beer ~ 1",data=data).fit()
- # 查看空模型的AIC值
- null_model.aic

由两个拟合结果可以看出,含有解释变量的模型的AIC值更小,所以认为“包含结实变量(气温)的模型预测精度更高”,即用来预测啤酒销售额的模型应该考虑气温因素。
5、分步计算AIC值,已加深印象。
AIC的计算式为:
AIC=-2×(最大对数似然-参与估计的参数个数)

接下来只需要知道参与估计的参数个数即可。这个值没有包含在模型里,但我们可以先找到解释变量的个数:

事实上,截距(β0)也参与了估计,所以上面的结果加上1就是参与估计的参数个数。最终AIC计算如下:

注:在确定参与估计的参数个数方面也有很多做法。有时也会算上多余参数(这种情况下AIC就是210.909)。R语言等工具有时也会各处多余参数的个数。
AIC的核心是各个AIC之间的对比,其绝对值并不重要。通过相同做法计算出来的AIC的大小关系是不变的,只要不更换做法,就不会影响模型选择,就意味着我们要避免跨工具计算AIC。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/133796
推荐阅读
相关标签

