
- 1Linux环境中的git
- 2Android 9.0 系统systemui状态栏下拉左滑显示通知栏右滑显示控制中心模块的流程分析_android 通知栏 左右
- 3double和float的精度和取值范围_double范围
- 4CNN卷积神经网络学习笔记(特征提取)_cnn提取三维数据特征
- 5VGG16网络模型_vgg16模型图
- 6机器学习系列(13)_PCA对图像数据集的降维_02_图片 pca降维
- 7unity3d功能脚本大全_gui.drawtexture(new rect(0, 0, screen.width, scree
- 85个ai工具导航网站,最新最全的ai网址_ai产品行业看哪些网站
- 9Exit 0、exit 1、exit -1 的区别_exit(0)和exit(-1)
- 10Oracle listener lsnrctl_lsnrctl 启动特定实例
SM3杂凑算法的verilog实现(附免费可用代码)_sm3 verilog实现
赞
踩
SM3算法作为我国自主要发设计的密码杂凑算法,输出消息摘要值长度为 256bit,消息分组长度512bit,迭代压缩次数64次。在算法的硬件实现中,信息需要经过消息填充、扩展生成消息字和轮函数迭代压缩。因此硬件结构模块划分为:消息填充模块、消息扩展模块和迭代压缩模块。
消息填充模块将输入的明文数据按照规则填充,并分成512bit一组的模块,是 SM3 杂凑算法的基础组成部分。消息填充模块每次输入32 bit,当输入不是最后一个字时,将输入字直接输出,否则判断输入字节寄存器中值,并进行相应的填充。
消息扩展模块用来产生消息字 Wj和 Wj’,并将轮函数需要的消息字送入到指定位置,该部分是SM3算法硬件结构中的重要模块。由于在后续迭代计算中需要使用消息字参与计算,为降低迭代压缩的操作时间,需要提前生成消息字,在设定节拍送入迭代压缩模块。为减少寄存器的使用数目,本设计采取复用的方式减少寄存器的使用数量。在该设计中,每次生成两个新的消息字保证下一个周期消息字的产生。
迭代函数作为杂凑算法的核心处理部分在硬件设计中非常重要。SM3算法的迭代函数共有64轮,根据对算法的分析可以看出,对每一个消息分组的运算而言,将迭代展开直接计算无疑是最节省时间的。因为运算路径中没有其它多余元件(例如寄存器)的插入,所以路径是最短的。但是这种将循环迭代展开的方式对大大减少了硬件资源的使用,占用面积很大。E203 RISC-V处理器主要用于低功耗、低面积的嵌入式应用,所以本设计采用了循环结构的设计方式,这种方式的占用面积小,但需要64个时钟周期才能完成一个消息分组的迭代。
由于最后一个字节的消息经过消息填充模块后可能扩展出两个消息分组,而迭代压缩模块只能处理一个消息分组,所以需要增加一个fifo对最后一个消息分组进行存储。

下面是各模块的verilog代码。
消息填充模块:
- module msg_padding (
- input clk,rst_n,
- input msg_padding_en,
- input [31:0] msg_in,
- input msg_in_vld,
- input msg_is_last_word,
- input [1:0] msg_bytes_num, //00:x000 01:xx00 10:xxx0 11:xxxx
- output reg [31:0] pad_result,
- output reg res_vld,
- output reg pad_done
- );
- localparam DIRECT = 3'd0;
- localparam CASE_80 = 3'd1;
- localparam CASE_00 = 3'd2;
- localparam CASE_LH = 3'd3;
- localparam CASE_LL = 3'd4;
- reg [2:0] state_r;
- reg [3:0] gene_counter;
- reg [63:0] bit_counter;
- wire [3:0] gcnt_add1 = gene_counter+1'b1;
- wire [2:0] bcnt_add_num = {~msg_is_last_word|(msg_bytes_num==2'b11),
- msg_is_last_word&((msg_bytes_num==2'b01)|(msg_bytes_num==2'b10)),
- msg_is_last_word&~msg_bytes_num[0]};
- wire [63:0] bcnt_adder = bit_counter+{bcnt_add_num,3'd0};
- wire msg_bn_00 = (msg_bytes_num==2'b00);
- wire msg_bn_01 = (msg_bytes_num==2'b01);
- wire msg_bn_10 = (msg_bytes_num==2'b10);
- wire msg_bn_11 = (msg_bytes_num==2'b11);
-
- always @(posedge clk,negedge rst_n) begin
- if(~rst_n)begin
- state_r<=DIRECT;
- res_vld<=1'b0;
- gene_counter<=4'd0;
- bit_counter<=64'd0;
- pad_result<=32'd0;
- pad_done<=1'b0;
- end
- else if(msg_padding_en)begin
- case (state_r)
- DIRECT:begin
- if(msg_in_vld)begin
- res_vld<=1'b1;
- bit_counter<=bcnt_adder;
- gene_counter<=gcnt_add1;
- if(msg_is_last_word)begin
- if(msg_bn_00)begin
- pad_result<={msg_in[31:24],24'h800000};
- state_r<=CASE_00;
- end
- if(msg_bn_01)begin
- pad_result<={msg_in[31:16],16'h8000};
- state_r<=CASE_00;
- end
- if(msg_bn_10)begin
- pad_result<={msg_in[31:8],8'h80};
- state_r<=CASE_00;
- end
- if(msg_bn_11)begin
- pad_result<=msg_in;
- state_r <= CASE_80;
- end
- end
- else pad_result<=msg_in;
- if(gene_counter==4'd15)
- pad_done<=1'b1;
- else pad_done<=1'b0;
- end
- else begin
- res_vld<=1'b0;
- pad_done<=1'b0;
- end
- end
- CASE_80:begin
- pad_result<=32'h8000_0000;
- gene_counter<=gcnt_add1;
- if(gene_counter==4'd13)
- state_r<=CASE_LH;
- else state_r<=CASE_00;
- end
- CASE_00:begin
- gene_counter<=gcnt_add1;
- pad_result<=32'd0;
- if(gene_counter==4'd13)
- state_r<=CASE_LH;
- end
- CASE_LH:begin
- pad_result<=bit_counter[63:32];
- state_r<=CASE_LL;
- end
- CASE_LL:begin
- pad_result<=bit_counter[31:0];
- gene_counter<=4'd0;
- bit_counter<=64'd0;
- pad_done<=1'b1;
- state_r<=DIRECT;
- end
- default:state_r<=DIRECT;
- endcase
- end
- end
- endmodule

消息扩展模块:
- module msg_expansion (
- input clk,rst_n,
- input msg_expansion_en,
- input [31:0] msg_expansion_in,
- input msg_in_vld,
- output msg_in_ready,
- output [31:0] wj0,wj1,
- output res_vld
- );
- wire state_is_padreg;
- wire state_is_genw16;
- reg [6:0] counter;
-
- reg [31:0] w0,w1,w2,w3,w4,w5,w6,w7,w8,w9,w10,w11,w12,w13,w14,w15;
- wire [31:0] tmp0 = w0^w7^{w13[16:0],w13[31:17]};
- wire [31:0] tmp1 = tmp0^{tmp0[16:0],tmp0[31:17]}^{tmp0[8:0],tmp0[31:9]};
- wire [31:0] w16 = tmp1^{w3[24:0],w3[31:25]}^w10;
-
- assign state_is_padreg = counter<=7'd15;
- assign state_is_genw16 = ~state_is_padreg;
- assign wj0 = w11;
- assign wj1 = wj0^w15;
- assign res_vld = (counter>=7'd5);
- assign msg_in_ready=state_is_padreg;
-
- always @(posedge clk,negedge rst_n)begin
- if(~rst_n){w0,w1,w2,w3,w4,w5,w6,w7,w8,w9,w10,w11,w12,w13,w14,w15}<=512'd0;
- else if(msg_expansion_en)begin
- if(state_is_padreg&msg_in_vld)
- {w0,w1,w2,w3,w4,w5,w6,w7,w8,w9,w10,w11,w12,w13,w14,w15}<={w1,w2,w3,w4,w5,w6,w7,w8,w9,w10,w11,w12,w13,w14,w15,msg_expansion_in};
- else if(state_is_genw16)
- {w0,w1,w2,w3,w4,w5,w6,w7,w8,w9,w10,w11,w12,w13,w14,w15}<={w1,w2,w3,w4,w5,w6,w7,w8,w9,w10,w11,w12,w13,w14,w15,w16};
- else {w0,w1,w2,w3,w4,w5,w6,w7,w8,w9,w10,w11,w12,w13,w14,w15}<={w0,w1,w2,w3,w4,w5,w6,w7,w8,w9,w10,w11,w12,w13,w14,w15};
- end
- end
- always @(posedge clk,negedge rst_n)begin
- if(~rst_n)counter<=7'd0;
- else if(msg_expansion_en)begin
- if((state_is_padreg&msg_in_vld)|state_is_genw16)
- counter <= (counter==7'd68)?7'd0:(counter+1'b1);
- else counter<=counter;
- end
- end
- endmodule
迭代压缩模块:
- module msg_compression (
- input clk,rst_n,
- input msg_compression_en,
- input [31:0] wj0,wj1,
- input msg_in_vld,
- input last_block,
- output [31:0] hash,
- output reg res_vld,
- output reg one_block_done
- );
- localparam A0=32'h7380166f;
- localparam B0=32'h4914b2b9;
- localparam C0=32'h172442d7;
- localparam D0=32'hda8a0600;
- localparam E0=32'ha96f30bc;
- localparam F0=32'h163138aa;
- localparam G0=32'he38dee4d;
- localparam H0=32'hb0fb0e4e;
- localparam TJ0=32'h79cc4519;
- localparam TJ1=32'h7a879d8a;
-
- reg [31:0] IV0,IV1,IV2,IV3,IV4,IV5,IV6,IV7;
- reg [31:0] A,B,C,D,E,F,G,H;
- reg [5:0] index_j;
- wire [255:0] IV_AH;
- reg [31:0] Tj0,Tj1;
- wire j_less16 = (index_j<=6'd15);
- wire j_equal7 = (index_j==6'd7);
- wire j_equal63= (index_j==6'd63);
- wire [31:0] Tj_shift=j_less16?Tj0:Tj1;
- wire [31:0] ss0,cc0;
- wire [31:0] tmp_for_ss1=ss0+cc0;
- wire [31:0] SS1={tmp_for_ss1[24:0],tmp_for_ss1[31:25]};
- wire [31:0] SS2=SS1^{A[19:0],A[31:20]};
- wire [31:0] FFj=j_less16?(A^B^C):((A&B)|(A&C)|(B&C));
- wire [31:0] GGj=j_less16?(E^F^G):((E&F)|(~E&G));
- wire [31:0] s0,c0,s1,c1,s2,c2,s3,c3;
- wire [31:0] TT1=s1+c1;
- wire [31:0] TT2=s3+c3;
- assign s0=FFj^D^SS2;
- assign c0=((FFj&D)|(FFj&SS2)|(D&SS2))<<1;
- assign s1=s0^c0^wj1;
- assign c1=((s0&c0)|(s0&wj1)|(c0&wj1))<<1;
- assign s2=GGj^H^SS1;
- assign c2=((GGj&H)|(GGj&SS1)|(H&SS1))<<1;
- assign s3=s2^c2^wj0;
- assign c3=((s2&c2)|(s2&wj0)|(c2&wj0))<<1;
- assign ss0={A[19:0],A[31:20]}^E^Tj_shift;
- assign cc0=(({A[19:0],A[31:20]}&E)|({A[19:0],A[31:20]}&Tj_shift)|(E&Tj_shift))<<1;
- assign IV_AH={IV0,IV1,IV2,IV3,IV4,IV5,IV6,IV7}^{A,B,C,D,E,F,G,H};
- assign hash=IV0;
- always @(posedge clk,negedge rst_n) begin
- if(~rst_n){A,B,C,D,E,F,G,H}<={A0,B0,C0,D0,E0,F0,G0,H0};
- else begin
- if(msg_compression_en&msg_in_vld)
- {A,B,C,D,E,F,G,H}<={
- TT1,A,{B[22:0],B[31:23]},C,
- TT2^{TT2[22:0],TT2[31:23]}^{TT2[14:0],TT2[31:15]},
- E,{F[12:0],F[31:13]},G
- };
- if(one_block_done) {A,B,C,D,E,F,G,H}<=IV_AH;
- if(res_vld&j_equal7)
- {A,B,C,D,E,F,G,H}<={A0,B0,C0,D0,E0,F0,G0,H0};
- end
- end
- always @(posedge clk,negedge rst_n) begin
- if(~rst_n){IV0,IV1,IV2,IV3,IV4,IV5,IV6,IV7}<={A0,B0,C0,D0,E0,F0,G0,H0};
- else begin
- if(one_block_done)
- {IV0,IV1,IV2,IV3,IV4,IV5,IV6,IV7}<=IV_AH;
- if(res_vld&~j_equal7)
- {IV0,IV1,IV2,IV3,IV4,IV5,IV6,IV7}<={IV1,IV2,IV3,IV4,IV5,IV6,IV7,32'd0};
- if(res_vld&j_equal7)
- {IV0,IV1,IV2,IV3,IV4,IV5,IV6,IV7}<={A0,B0,C0,D0,E0,F0,G0,H0};
- end
- end
-
- always @(posedge clk,negedge rst_n) begin
- if(~rst_n)index_j<=6'd0;
- else begin
- if((msg_compression_en&msg_in_vld)|(res_vld&~j_equal7))
- index_j<=index_j+1'b1;
- if(res_vld&j_equal7)
- index_j<=6'd0;
- end
- end
- always @(posedge clk,negedge rst_n) begin
- if(~rst_n)Tj0<=TJ0;
- else if(msg_compression_en&msg_in_vld)
- Tj0<={Tj0[30:0],Tj0[31]};
- end
- always @(posedge clk,negedge rst_n) begin
- if(~rst_n)Tj1<=TJ1;
- else if(msg_compression_en&msg_in_vld)
- Tj1<={Tj1[30:0],Tj1[31]};
- end
- always @(posedge clk,negedge rst_n) begin
- if(~rst_n)res_vld<=1'b0;
- else if(msg_compression_en)begin
- if(res_vld)res_vld<=~j_equal7;
- else res_vld<=last_block&one_block_done;
- end
- end
-
- always @(posedge clk,negedge rst_n) begin
- if(~rst_n)one_block_done<=1'b0;
- else one_block_done<=msg_compression_en&msg_in_vld&j_equal63;
- end
- endmodule
FIFO模块:
- module sm3_fifo # (
- parameter DP = 8,
- parameter DW = 32
- ) (
-
- input i_vld,
- output i_rdy,
- input [DW-1:0] i_dat,
- output o_vld,
- input o_rdy,
- output [DW-1:0] o_dat,
-
- input clk,
- input rst_n
- );
-
- genvar i;
- generate
-
- reg [DW-1:0] fifo_rf_r [DP-1:0];
- wire [DP-1:0] fifo_rf_en;
-
- wire wen = i_vld & i_rdy;
- wire ren = o_vld & o_rdy;
-
- wire [DP-1:0] rptr_vec_nxt;
- reg [DP-1:0] rptr_vec_r;
- wire [DP-1:0] wptr_vec_nxt;
- reg [DP-1:0] wptr_vec_r;
-
- assign rptr_vec_nxt = rptr_vec_r[DP-1]?{{DP-1{1'b0}},1'b1}:(rptr_vec_r<<1);
- assign wptr_vec_nxt = wptr_vec_r[DP-1]?{{DP-1{1'b0}},1'b1}:(wptr_vec_r<< 1);
-
- always @(posedge clk,negedge rst_n) begin
- if(~rst_n)rptr_vec_r<=1'b1;
- else if(ren)
- rptr_vec_r<=rptr_vec_nxt;
- end
- always @(posedge clk,negedge rst_n) begin
- if(~rst_n)wptr_vec_r<=1'b1;
- else if(wen)
- wptr_vec_r<=wptr_vec_nxt;
- end
-
- wire [DP:0] i_vec;
- wire [DP:0] o_vec;
- wire [DP:0] vec_nxt;
- reg [DP:0] vec_r;
-
- wire vec_en = (ren ^ wen );
- assign vec_nxt = wen ? {vec_r[DP-1:0], 1'b1} : (vec_r >> 1);
- always @(posedge clk,negedge rst_n) begin
- if(~rst_n)vec_r<=1'b1;
- else if(vec_en)
- vec_r<=vec_nxt;
- end
-
- assign i_vec = {1'b0,vec_r[DP:1]};
- assign o_vec = {1'b0,vec_r[DP:1]};
- assign i_rdy = (~i_vec[DP-1]);
-
- for (i=0; i<DP; i=i+1) begin:fifo_rf
- assign fifo_rf_en[i] = wen & wptr_vec_r[i];
- always @(posedge clk) begin
- if(fifo_rf_en[i])fifo_rf_r[i]<=i_dat;
- end
- end
-
- integer j;
- reg [DW-1:0] mux_rdat;
- always @*
- begin : rd_port_PROC
- mux_rdat = {DW{1'b0}};
- for(j=0; j<DP; j=j+1) begin
- mux_rdat = mux_rdat | ({DW{rptr_vec_r[j]}} & fifo_rf_r[j]);
- end
- end
-
- assign o_dat = mux_rdat;
- assign o_vld = (o_vec[0]);
- endgenerate
- endmodule
顶层模块:
- module sm3_top (
- input clk,rst_n,
- input sm3_en,
- input [31:0] msg_in,
- input msg_in_vld,
- input msg_is_last_word,
- input [1:0] msg_bytes_num,
- output one_block_done,
- output [31:0] msg_hash,
- output msg_hash_vld
- );
-
- wire [31:0] pad_result;
- wire [31:0] msg_expansion_in;
- wire pad_res_vld,pad_done;
- wire expansion_in_vld;
- wire expansion_in_rdy;
- wire exp_res_vld;
- wire [31:0] wj0,wj1;
- reg last_word_in,last_block;
-
- always @(posedge clk,negedge rst_n) begin
- if(~rst_n)last_word_in<=1'b0;
- else if(sm3_en)
- last_word_in<=last_word_in?~msg_hash_vld:msg_is_last_word;
- end
- always @(posedge clk,negedge rst_n) begin
- if(~rst_n)last_block<=1'b0;
- else if(sm3_en)
- last_block<=last_block?~msg_hash_vld:(last_word_in&~expansion_in_rdy&~expansion_in_vld);
- end
-
- msg_padding u_msg_padding(
- .clk(clk),
- .rst_n(rst_n),
- .msg_padding_en(sm3_en),
- .msg_in(msg_in),
- .msg_in_vld(msg_in_vld),
- .msg_is_last_word(msg_is_last_word),
- .msg_bytes_num(msg_bytes_num),
- .pad_result(pad_result),
- .res_vld(pad_res_vld),
- .pad_done(pad_done)
- );
-
- msg_expansion u_msg_expansion(
- .clk(clk),
- .rst_n(rst_n),
- .msg_expansion_en(sm3_en),
- .msg_expansion_in(msg_expansion_in),
- .msg_in_vld(expansion_in_vld),
- .msg_in_ready(expansion_in_rdy),
- .wj0(wj0),
- .wj1(wj1),
- .res_vld(exp_res_vld)
- );
-
- msg_compression u_msg_compression(
- .clk(clk),
- .rst_n(rst_n),
- .msg_compression_en(sm3_en),
- .wj0(wj0),
- .wj1(wj1),
- .msg_in_vld(exp_res_vld),
- .last_block(last_block),
- .hash(msg_hash),
- .res_vld(msg_hash_vld),
- .one_block_done(one_block_done)
- );
-
- sm3_fifo #(.DP(32)) fifo_paddout(
- .i_vld(pad_res_vld),
- .i_rdy(),
- .i_dat(pad_result),
- .o_vld(expansion_in_vld),
- .o_rdy(expansion_in_rdy),
- .o_dat(msg_expansion_in),
- .clk(clk),
- .rst_n(rst_n)
- );
-
- endmodule
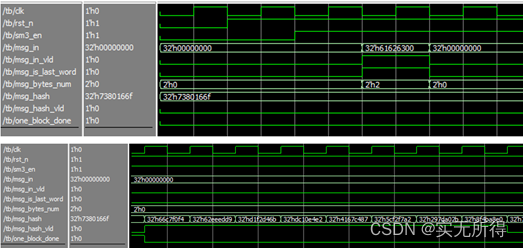
使用两个标准测试向量进行仿真,其结果如下:

在Cyclone III ,型号为EP3C16F484I7的资源占用及最高频率如下:



