
- 1RecyclerView的基本用法、横向/纵向/网格/瀑布流布局显示及点击事件_recyclerview 横向
- 2什么是SOTA,SOTA是什么意思_sota水平
- 3python湖北武汉购物店铺数据可视化大屏全屏系统设计与实现(django框架)
- 4linux+QT+FFmpeg 6.0,把多个QImage组合成一个视频_ffmpeg 6.0 + qt
- 5Linux:使用ntpdate命令同步更新系统时间_ntpd 更新时间
- 6精品微信小程序基于Uniapp+springboot基于微信小程序的摄影平台设计与实现|计算机毕业设计|Java毕业设计|课程设计|Python毕设|小程序|毕业设计推荐_基于微信小程序的摄影作品交流平台
- 7sqlalchemy更新json 字段的部分字段_sqlalchemy json字段
- 8[23000][1452] Cannot add or update a child row: a foreign key constraint fails (`test2`.`#sql-1238_5
- 9网页设计与制作(HTML+CSS)(三)_html如何在css调整视频和文字的距离
- 10LeetCode 1229. Meeting Scheduler - 亚马逊高频题32_input slots[10,50]
Pandas基础——DataFrame_pandasdataframe
赞
踩
pandas简介
Pandas是字典形式,基于NumPy创建,让以NumPy为中心的应用变得更加简单。
Pandas有两种数据结构,Series和DataFrame。Numpy的是ndarray。
本文将讲解DataFrame的知识点。
一、DataFrame简介
DataFrame类型由共用相同索引的一组Series组成
DataFrame既有行索引(index)、也有列索引(columns)
二、创建DataFrame
DataFrame主要是依靠pd.DataFrame()创建。
2.1、使用pd.DataFrame()
使用pd.DataFrame()参数可以是
- 二维数组
- 二维ndarray
- 由一维ndarray、列表、Series构成的字典
- 也可以从现成的DataFrame中截取
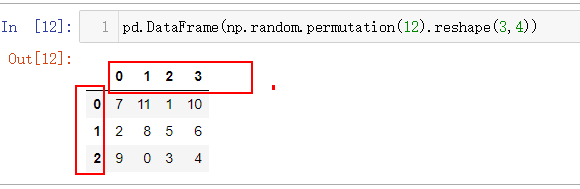


注意,是columns而不是column。

三、DataFrame取元素
3.1、取列
- df后面直接跟中括号,他就只能取列(想取行,得用loc[ ])
- df.loc[ ]
- df.iloc[ ]
方法一:df后面直接跟中括号

方法二:df.loc[ ]

方法三:df.iloc[ ] 因为和第二种差不多,所以不做演示。
3.2、取行
- df.loc[ ]
- df.iloc[ ]
因为两种方法差不多,所以只演示第一种。

3.3、行列都取
其实就是使用df.loc[ ]和df.iloc[ ]

**注意:在使用布尔实现限制的时候,对行的限制需要取某列;对列的限制需要取某行。**可以看看上例的实现。
三、增加列
主要就是三种方法
- 直接赋值
- df.apply()方法
- df.assign()方法
四、增加行
主要是三种方法
- 使用df.loc[ ]直接添加
- df.append()方法,增加一行或多行
- df.concat()方法,拼接两个df
4.1、直接添加
注意,loc可以对没有的 index 进行赋值,而 iloc 则不允许,iloc只能对已经存在的位置进行操作。

4.2、df.append()方法,增加一行或者多行
>>> df = pd.DataFrame([[1, 2], [3, 4]], columns=list('AB'))
>>> df
A B
0 1 2
1 3 4
>>> df2 = pd.DataFrame([[5, 6], [7, 8]], columns=list('AB'))
>>> df.append(df2)
A B
0 1 2
1 3 4
0 5 6
1 7 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
ignore_index参数是把拼接的两部分的index都重置,并且按照隐式索引。上面的例子,以为没有设置ignore_index,所以index比较混乱。
>>> df = pd.DataFrame(columns=['A'])
>>> for i in range(5):
df = df.append({'A': i}, ignore_index=True)
>>> df
A
0 0
1 1
2 2
3 3
4 4
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
df.append()不会修改原数组,需要接受返回值
4.3、df.concat()拼接两个df,和上面差不多。
五、删除行列
删除行或列都可以使用df.drop()
DataFrame.drop(labels=None,axis=0, inplace=False)
- labels,单个索引或者索引组成的列表
- axis,删除方向,0代表删除行,1代表删除列
- inplace,是否对原始数组进行修改,如果不,就返回修改后的值
5.1、删除列

5.2、删除行

六、索引操作。
6.1、添加新索引
1、使用上面的添加列的方式
2、直接添加
df [ new_col ]= data
data可以先使用np.nan(缺失值)填充这一列,也可以使用一个列表填充这一列,但是列表的长度是有限制的。

3、先添加索引,再添加值
df.index.insert()
df.columns.insert()
这两种方法返回的都只是新的索引,而不是DataFrame,还要进一步结合reindex()

6.2、修改索引名
1、修改索引名
这个功能很重要,因为修改不能通过先删除在增加来实现,那样的话,数据会在删除的时候直接没了。
df.rename(index=字典, columns=字典)


2、重新排列DataFrame的index和columns
df.reindex()方法
也适用于Series

另外,如果在重新排列索引时,使用了不存在于原数组索引的索引值,则其对应数据默认是NaN,我们可以使用fill_value参数来对其进行填充。

6.3、删除某个index或者columns
其实还是使用df.drop()方法

小结:
df.reindex()
df.index.insert()、df.columns.insert()
df.index.delete()、df.columns.delete()
df.rename(index=字典, columns=字典)
以上对DataFrame的修改都会返回新的值,可能是新的索引、或者新的df,而不是直接修改原本的数组,所以需要接受返回值。
七、运算法则
7.1、算术运算法则
在pandas中,两个对象首先会广播,然后进行运算,但是这里的广播不同于一般的numpy广播。
7.2、逻辑运算法则
八、排序
8.1、按照索引值排序
df.sort_index(axis=0, ascending=True)
按照索引的值排序,而不是数据。
默认按照0轴排序、默认升序。

ascending=False意味着逆序排序。
8.2、按照某一列的值进行排序
df.sort_values(by= 列名, ascending=True)
by用来指明哪一列,如果是多列,用列表表示。
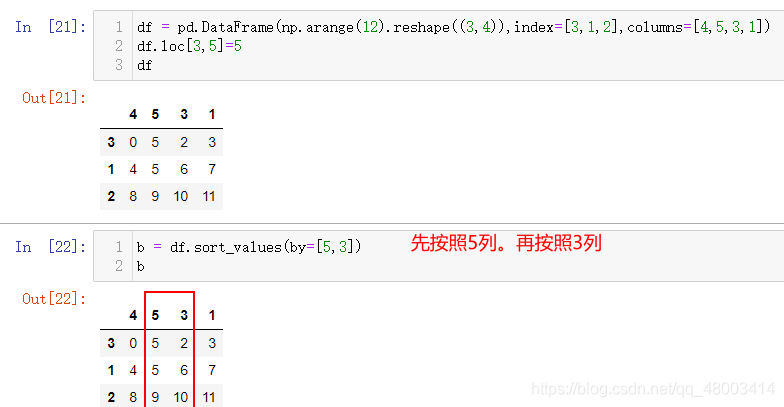
对于pandas,没有按照某一行的值来排序的方法。
元素数据类型的修改
c_itcont['收到捐款的日期'] = c_itcont['收到捐款的日期'] .astype(str)
- 1
九、统计分析函数

1、count()计算的是非NaN的数量。
2、value_counts()统计各种值的频次,这个可以使用group_by()实现,但是前者返回Series后者是DataFrame。而且前者不能实现后者的所有功能,例如group_by可以统计每个类别的项目属性值的和,而不只是个数。
3、这两个都是用于Series
两个搭配起来,series.value_counts().count()统计一共有几种值。
df.describe()会自行计算数据类型为int的列,而不是全部都计算,所以不用取子集
df.describe()也可以对非int数据类型的数组使用
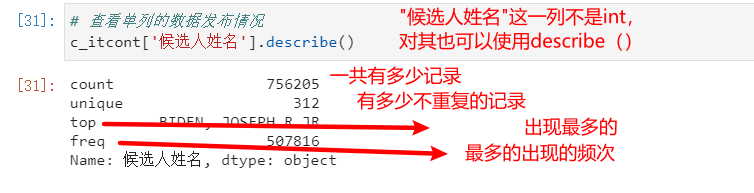


8.2、统计分析实例


十、数据文件的读取
一般就是用pd.read_excel()
pd.read_csv(filepath, header, names,index_col, usecols,encoding)
1、filepath设置文件路径,也可以是url
2、header,用来设置文件的哪一行作为列索引的那一行。如果没有设置,就按隐式索引。
header=0,表示文件的第0行作为列索引。
如果header=1,使用第二行,那么第一行的数据会被丢弃。
3、names,当文件中没有想要使用的列索引时,可以手动设置列索引名。是一个列表形式。
names=[“姓名”,“年龄”,“电话”]
如果header和names都设置了,names就会覆盖headers
4、index_col,使用哪一列来作为行的索引。
5、usecols,如果列有很多,不想都使用,就用usecols指定需要的列。
index_col和usecols都可以使用前面的header或者names中设置的列名来指定。
6、如果文件中含有中文,设置参数encoding=“utf-
8”。
7、在使用列名访问DataFrame里的数据时,对于中文列名,需要在列名前面加一个u,表示后面的字符串以unicode格式存储。
print(df[u"经度"])
1、数据缺失值的处理
缺失值不等同于空值,空值是"",缺失值就是NaN。excel中如果在表格中有的值没有填,那读取之后就是空值,因为excel几乎是无边界的,如果是在“表格”范围之外就是缺失值,一班这里也碰不到。
缺失值:
- df.isna() 判断是否为缺失值
- df.dropna() 删除缺失值
- df.fillna() 填充缺失值


空值:
- df.isnull()
十一、总结
11.1、增添新列的一个例子

11.2、对某列或某行进行字符串操作。

11.2、
凡是会对原数组作出修改并返回一个新数组的,往往都有一个 inplace可选参数。如果手动设定为True(默认为False),那么原数组直接就被替换
取出一行或者一列的时候返回的是Series,尤其是取一行时,打印结果会是
以列的形式,但结果仍然是一行。

