
热门标签
热门文章
- 1Qt 鼠标滚轮示例_qt鼠标连续滚轮
- 2安装bootcamp时遇到的几个坑_bootcamp安装win10大于4g
- 3springboot集成对象存储aws java v2_software.amazon.awssdk
- 4【开源分享】深度学习网络模型大全(基于TensorFlow和PyTorch的开源复现)_基于pytorch的开源模型
- 5Js对比常用JSON数据差异_js 对比 两个json的差异
- 6多尺度卷积网络(Muti-CNN-FNN Network)寿命预测研究_多尺度cnn模型
- 7MIPS 架构及其汇编语言【英】
- 8微信小程序多图列表页面性能问题为什么会出现?如何解决?
- 9算法训练day14||二叉树的递归遍历|二叉树的迭代遍历|二叉树的统一迭代法
- 10Mineflayer简介——Minecraft机器人
当前位置: article > 正文
SE-ResNet34对结构性数据进行多分类_resnet34 多标签分类
作者:笔触狂放9 | 2024-03-22 21:05:01
赞
踩
resnet34 多标签分类
1、摘要
本文主要讲解:SE-ResNet34对结构性数据进行多分类
主要思路:
- 构建SEBasicBlock
- 构建resnet34
- 去除数据中的nan值,并对数据使用SMOTE算法进行平衡
- 选取BCELoss对损失进行评估
2、数据介绍
需要数据请私聊
以下是简单数据截图,最右边那列为标签
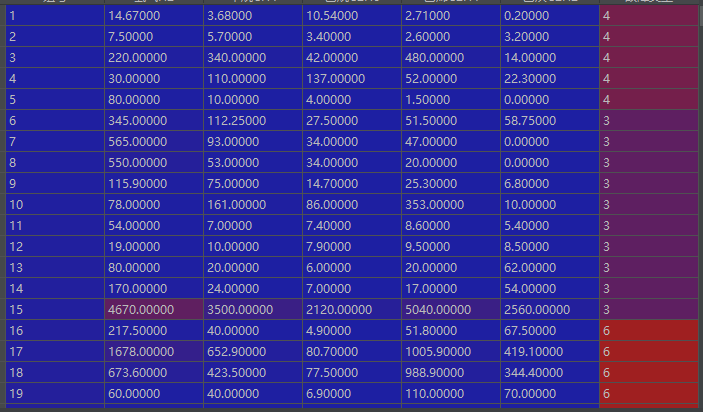
3、相关技术
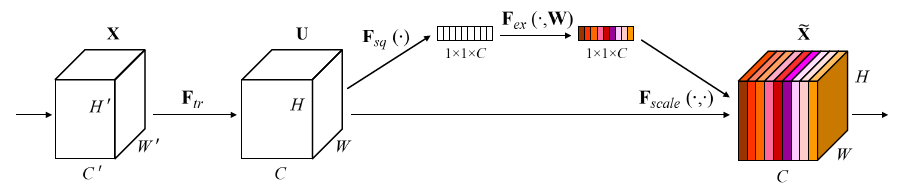
SE:Squeeze-and-Excitation的缩写,特征压缩与激发的意思。
可以把SENet看成是channel-wise的attention,可以嵌入到含有skip-connections的模块中,ResNet,VGG,Inception等等。
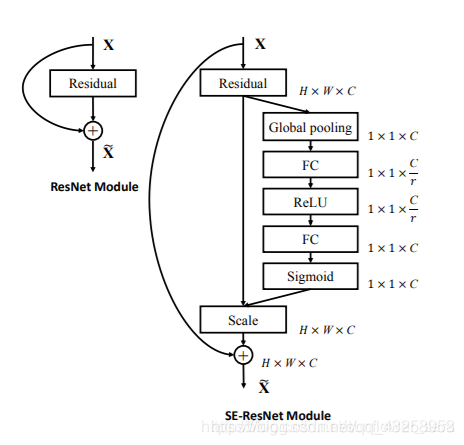
在resnet中加入SE:
下图是SE-ResNet, 可以看到SE module被apply到了residual branch上。我们首先将特征维度降低到输入的1/r,然后经过ReLu激活后再通过一个Fully Connected 层升回到原来的维度。
这样做比直接用一个Fully Connected层的好处在于:
1)具有更多的非线性,可以更好地拟合通道间复杂的相关性;
2)极大地减少了参数量和计算量。然后通过一个Sigmoid的门获得01之间归一化的权重,最后通过一个Scale的操作来将归一化后的权重加权到每个通道的特征上。在Addition前对分支上Residual的特征进行了特征重标定。如果对Addition后主支上的特征进行重标定,由于在主干上存在01的scale操作,在网络较深BP优化时就会在靠近输入层容易出现梯度消散的情况,导致模型难以优化。
————————————————
版权声明:本文为CSDN博主「AI剑客」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:原文链接
4、完整代码和步骤
代码输出如下:
主运行程序入口
import matplotlib.pyplot as plt
from PIL import ImageFile
from imblearn.over_sampling import SMOTE
from sklearn import preprocessing
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from tensorflow.python.keras.utils.np_utils import to_categorical
from torchvision.models import ResNet
ImageFile.LOAD_TRUNCATED_IMAGES = True
from torch import nn
import os
import time
import csv
os.environ['CUDA_LAUNCH_BLOCKING'] = "0"
import torch.optim
import torch.utils.data
import warnings
warnings.filterwarnings("ignore")
import pandas as pd
from tqdm import tqdm
import numpy as np
torch.backends.cudnn.enabled = True
torch.backends.cudnn.benchmark = True
def checkpoint(model, best_loss, best_epoch, LR):
"""
Saves checkpoint of torchvision model during training.
Args:
model: torchvision model to be saved
best_loss: best val loss achieved so far in training
epoch: current epoch of training
LR: current learning rate in training
Returns:
None
"""
state = {
'model': model,
'state_dict': model.state_dict(),
'best_loss': best_loss,
'best_epoch': best_epoch,
'LR': LR
}
torch.save(state, 'results/checkpoint')
def make_pred_multilabel(model, test_df, device):
"""
Gives predictions for test fold and calculates mse using previously trained model
Args:
model: seresnet from torchvision previously fine tuned to training data
test_df : dataframe csv file
Returns:
pred_df: dataframe containing individual predictions and ground truth for each test data
"""
size = len(test_df)
print("Test _df size :", size)
model = model.to(device)
inputs = test_df[:, :6]
labels = test_df[:, 6]
y_test = [int(i) for i in labels.tolist()]
scaler_x = preprocessing.MinMaxScaler(feature_range=(0, 1))
inputs = scaler_x.fit_transform(inputs)
inputs = inputs.astype(float)
labels = to_categorical(labels)
# X_train = torch.FloatTensor(X_train.reshape((X_train.shape[0], 3, 2, 1)))
inputs = torch.FloatTensor(inputs.reshape((inputs.shape[0], 3, 1, 2)))
labels = torch.FloatTensor(labels)
# inputs = Variable(torch.unsqueeze(inputs, dim=3).float(), requires_grad=False)
inputs = inputs.to(device)
labels = labels.to(device)
criterion = nn.MSELoss()
batch_size = 64
length = len(inputs)
model.eval()
with torch.no_grad():
for j in range(0, length, batch_size):
X_train_batch = inputs[j:j + batch_size]
y_train_batch = labels[j:j + batch_size]
X_train_batch = X_train_batch.to(device)
y_train_batch = y_train_batch.to(device)
outputs = model(X_train_batch)
outputs = torch.sigmoid(outputs)
loss = criterion(outputs, y_train_batch)
print("loss:{:.3f}".format(loss))
y_pred = outputs.cpu().data.numpy()
y_pred = np.argmax(y_pred, axis=1)
acc = accuracy_score(y_test, y_pred)
print('acc', acc)
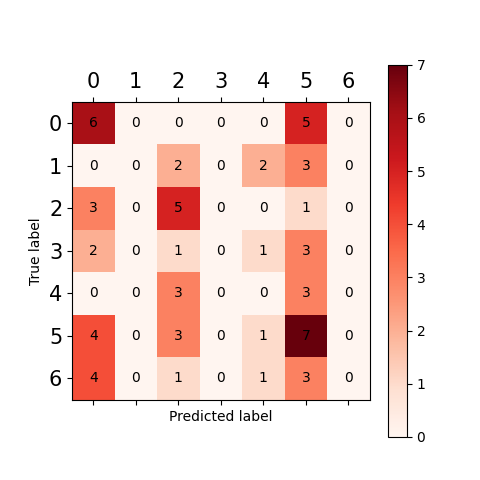
C = confusion_matrix(y_test, y_pred)
plt.matshow(C, cmap=plt.cm.Reds) # 根据最下面的图按自己需求更改颜色 , labels=labels
plt.colorbar()
for i in range(len(C)):
for j in range(len(C)):
plt.annotate(C[j, i], xy=(i, j), horizontalalignment='center', verticalalignment='center')
plt.tick_params(labelsize=15)
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
def conv3x3(in_planes, out_planes, stride=1):
return nn.Conv2d(in_planes, out_planes, kernel_size=2, stride=stride, padding=1, bias=False)
class SEBasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None,
*, reduction=16):
super(SEBasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes, 1)
self.bn2 = nn.BatchNorm2d(planes)
self.se = SELayer(planes, reduction)
self.downsample = downsample
self.stride = stride
def forward(self, x):
# residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.se(out)
# if self.downsample is not None:
# residual = self.downsample(x)
# out += residual
out = self.relu(out)
return out
def se_resnet34(num_classes):
"""Constructs a ResNet-34 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(SEBasicBlock, [3, 4, 6, 3], num_classes=num_classes)
model.avgpool = nn.AdaptiveAvgPool2d(1)
return model
class Se_ResNet34(nn.Module):
def __init__(self, N_LABELS):
super(Se_ResNet34, self).__init__()
self.se_resnet34 = se_resnet34(N_LABELS)
num_ftrs = self.se_resnet34.fc.in_features
self.se_resnet34.fc = nn.Sequential(nn.Linear(num_ftrs, N_LABELS), nn.Sigmoid())
# print(self.se_resnet34)
def forward(self, x):
x = self.se_resnet34(x)
return x
# 剪辑反向传播期间计算的梯度,以避免梯度爆炸。
def clip_gradient(optimizer, grad_clip):
for group in optimizer.param_groups:
for param in group['params']:
if param.grad is not None:
param.grad.data.clamp_(-grad_clip, grad_clip)
def BatchIterator(model, phase, Data_loader, criterion, optimizer, device):
# -------------------- Initial paprameterd
global loss, outputs, y_train_batch
grad_clip = 0.5 # clip gradients at an absolute value of
running_loss = 0.0
X_train = Data_loader[:, :6]
scaler_x = preprocessing.MinMaxScaler(feature_range=(0, 1))
X_train = scaler_x.fit_transform(X_train)
y_train = Data_loader[:, 6]
y_train = to_categorical(y_train)
X_train = X_train.astype(float)
X_train = torch.FloatTensor(X_train.reshape((X_train.shape[0], 3, 1, 2)))
y_train = torch.FloatTensor(y_train)
# X_train = Variable(torch.unsqueeze(X_train, dim=3).float(), requires_grad=False)
batch_size = 64
length = len(X_train)
X_train = X_train.to(device)
y_train = y_train.to(device)
if phase == "train":
optimizer.zero_grad()
model.train()
for j in range(0, length, batch_size):
X_train_batch = X_train[j:j + batch_size]
y_train_batch = y_train[j:j + batch_size]
X_train_batch = X_train_batch.to(device)
y_train_batch = y_train_batch.to(device)
outputs = model(X_train_batch)
outputs = torch.sigmoid(outputs)
# backward
loss = criterion(outputs, y_train_batch)
loss.backward()
clip_gradient(optimizer, grad_clip)
# update weights
optimizer.step()
running_loss += loss * batch_size
# print("loss:{:.3f}".format(loss))
return running_loss
def ModelTrain(train_df, val_df,
device, LR):
# Training parameters
start_epoch = 0
num_epochs = 88 # number of epochs to train for (if early stopping is not triggered)
random_seed = 33 # random.randint(0,100)
np.random.seed(random_seed)
torch.manual_seed(random_seed)
model = Se_ResNet34(7).cuda()
# print(model)
model = model.to(device)
criterion = nn.BCELoss().to(device)
epoch_losses_train = []
epoch_losses_val = []
since = time.time()
best_loss = 999999
best_epoch = -1
# --------------------------Start of epoch loop
for epoch in tqdm(range(start_epoch, num_epochs)):
# print('Epoch {}/{}'.format(epoch, num_epochs))
print('-' * 10)
phase = 'train'
optimizer = torch.optim.Adam(params=filter(lambda p: p.requires_grad, model.parameters()), lr=LR) # 固定部分参数
running_loss = BatchIterator(model=model, phase=phase, Data_loader=train_df,
criterion=criterion, optimizer=optimizer, device=device)
epoch_loss_train = running_loss / len(train_df)
epoch_losses_train.append(epoch_loss_train.item())
# print("Train_losses:", epoch_losses_train)
phase = 'val'
optimizer = torch.optim.Adam(params=filter(lambda p: p.requires_grad, model.parameters()), lr=LR)
running_loss = BatchIterator(model=model, phase=phase, Data_loader=val_df,
criterion=criterion, optimizer=optimizer, device=device)
epoch_loss_val = running_loss / len(val_df)
epoch_losses_val.append(epoch_loss_val.item())
# print("Validation_losses:", epoch_losses_val)
timestampTime = time.strftime("%H%M%S")
timestampDate = time.strftime("%d%m%Y")
timestampEND = timestampDate + '-' + timestampTime
# checkpoint model if has best val loss yet
if epoch_loss_val < best_loss:
best_loss = epoch_loss_val
best_epoch = epoch
checkpoint(model, best_loss, best_epoch, LR)
print('Epoch [' + str(epoch + 1) + '] [save] [' + timestampEND + '] loss= ' + str(epoch_loss_val))
else:
print('Epoch [' + str(epoch + 1) + '] [----] [' + timestampEND + '] loss= ' + str(epoch_loss_val))
# log training and validation loss over each epoch
with open("results/log_train", 'a') as logfile:
logwriter = csv.writer(logfile, delimiter=',')
if (epoch == 1):
logwriter.writerow(["epoch", "train_loss", "val_loss", "Seed", "LR"])
logwriter.writerow([epoch, epoch_loss_train, epoch_loss_val, random_seed, LR])
# -------------------------- End of phase
# break if no val loss improvement in 3 epochs
if ((epoch - best_epoch) >= 3):
if epoch_loss_val > best_loss:
print("decay loss from " + str(LR) + " to " + str(LR / 2) + " as not seeing improvement in val loss")
LR = LR / 2
print("created new optimizer with LR " + str(LR))
if ((epoch - best_epoch) >= 10):
print("no improvement in 10 epochs, break")
break
# old_epoch = epoch
# ------------------------- End of epoch loop
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
# 画损失下降图
plt.plot(epoch_loss_train.cpu().data.numpy())
plt.plot(epoch_losses_val)
plt.ylim([0.0, 0.9])
plt.xlabel("epochs")
plt.ylabel("loss")
plt.legend(['epoch_loss_train', 'epoch_losses_val'], loc='best')
plt.show()
checkpoint_best = torch.load('results/checkpoint')
model = checkpoint_best['model']
best_epoch = checkpoint_best['best_epoch']
print(best_epoch)
return model, best_epoch
def change_c2h6(x):
try:
x = float(x)
return x
except:
if x == '-':
return 0
else:
print(x)
def main():
# train_df_path = "data/DGA数据.xlsx"
train_df_path = "data/数据1(1).xlsx"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
data = pd.read_excel(train_df_path)
# data = pd.read_excel(train_df_path)
data.fillna(0, inplace=True)
data = data[~data.isin([np.nan, np.inf, -np.inf]).any(1)]
data.replace(np.inf, 0, inplace=True)
data.replace(-np.inf, 0, inplace=True)
le = LabelEncoder()
data['故障类型'] = le.fit_transform(data['故障类型'])
X_train = data.iloc[:, :6]
y_train = data.iloc[:, 6]
oversample = SMOTE()
X_train, y_train = oversample.fit_resample(X_train, y_train)
data = pd.concat([X_train, y_train], axis=1)
data = data.values
test_size = 64 / len(data)
train_df, test_df = train_test_split(data, test_size=test_size, random_state=0, shuffle=True)
val_df = test_df
train_df_size = len(train_df)
print("Train_df size", train_df_size)
test_df_size = len(test_df)
print("test_df size", test_df_size)
val_df_size = len(val_df)
print("val_df size", val_df_size)
LR = 0.5e-4
# acc 0.484375 acc 0.5625 LR = 0.1e-4 epochs =100
model, best_epoch = ModelTrain(train_df, val_df, device, LR)
make_pred_multilabel(model, test_df, device)
if __name__ == "__main__":
main()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
- 383
- 384
- 385
5、学习链接
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/290870
推荐阅读
相关标签

