
- 1机器学习笔记之分类算法(二)朴素贝叶斯_6.对于二分类问题,朴素贝叶斯输出的是什么?
- 2Linux 声音系统_audiolinux
- 3C++ SAPI5设置输出设备(声卡)_linux下使用microsoft sapi5进行输出声音
- 4网络安全 hw 蓝队实战之溯源(仅供参考学习)_hw蓝队
- 5UE使用UnLua(一)
- 6Python+GDAL 将数组写入栅格tiff文件_将数据数组保存为栅格
- 7OpenHarmony 3D显示框架详解
- 8JS学习19(Ajax与Comet)_ajax设置contenttype:'text/event-stream
- 9ChatGPT-5传闻将于2023年底推出,它会实现AGI吗?_chatgpt5
- 10GPT实战系列-Baichuan2本地化部署实战方案_baichuan2 部署
构建一个基础的大型语言模型(LLM)应用程序
赞
踩
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

几年前,人工智能还是为数不多、钱包鼓得像气球的科技公司的专利玩意儿。但转眼到了今天,找个不急着把AI塞进它们流程和产品里的科技公司都难了——哪怕他们自己对这东西长啥样还一头雾水。
这篇文章,我们就来探索这块新兴领域。如今的AI辅助应用是怎么运作的呢?它们用的是什么架构,为什么在其他方法摔跟头的地方它们却能大放异彩?
“货架上直接拿”的AI
虽然AI给人感觉挺震撼的,但它其实不是啥新鲜事。多年来,科技行业的领头羊们已经在大型应用中使用了机器学习——比如Netflix优化内容编码,Uber计算美食推荐,亚马逊规划配送。这些AI特性都非常专业,普通软件供应商的工具箱里是找不到的。
今儿个,形势有了变化,随着即用型AI技术的爆炸式增长,一些经验丰富的开发团队即使没有巨额预算和专门的机器学习知识,也能将这些功能整合到他们的应用中。
这种向即用型工具的转变主要集中在AI领域的一个相对较小且非常具体的部分:大型语言模型,即LLMs。从更广的视角来看,LLMs可能只是软件开发中可访问AI演进的第一步。未来,我们会有更多工具和更好的模式来将AI特性集成到定制软件中。现在已经很清楚,当前的LLMs并不是许多场景下的完美工具——它们有自己的怪癖、限制和意外的复杂性。但是,获取即用型AI的吸引力非常强大,大多数公司都不在乎这些。他们不愿等待,打算尽可能快地从这项技术中挖掘出每一种可能的用途。
定制化的基本要求
那么,为什么LLMs在其他类型的AI因过于复杂而难以广泛采用的地方却能取得成功呢?有几个原因,但没有基础模型的兴起,这种转变是不可能的。
本质上,基础模型是像OpenAI、谷歌和Facebook这样的公司构建的巨大的、通用目的模型。你可以直接使用一个基础模型(就像ChatGPT所做的)。但真正的诀窍在于调整基础模型以适应个别用例,而不是从头开始训练一个新模型。这是一个重要的区别,因为训练是既耗资金又需要专业知识的部分。
这听起来很有希望,但挑战在于要能够足够定制模型以满足不同行业和不同领域的需求——换句话说,就是独立软件供应商工作并盈利的那些细分市场。一个基础模型本身可能并不令人兴奋,但如果软件公司能够定制它以适用于医疗记录或技术支持票据,那就大不相同了。
但这里有个问题——基础模型并不那么容易定制。你可以尝试用新知识来微调它们,但模型已经知道的内容往往会主导你希望它们学习的新信息,因为这些模型非常庞大。虽然微调并不像从头开始训练那样复杂和昂贵,但它仍然需要时间和关键资源。
因此,目前普遍接受的方法是使用上下文学习。虽然有几种不同的技术,但总的想法是在你当前的请求上下文中给LLM提供所需的信息。这可能意味着展示一些你想要的例子(例如,“按照这种格式”)或在你的提示中包括一些额外的数据(例如,“使用这块数据回答问题”)。这些技术都不是新的,但也没有哪一种成为完全定型的最佳实践,因为LLMs还在快速变化。但核心思想是,上下文学习给开发者提供了他们需要的东西:一个只需最少量定制就能构建适当软件功能的基础模型。
大型语言模型(LLM)应用程序的经典架构
既然我们已经了解了所有背景信息,现在是时候仔细研究人们今天正在构建的LLM应用程序了。
首先,想象一种天真的方法——一个应用程序简单地坐在用户和LLM之间,转发所有请求和响应。这种情况看起来是这样的:

代理到一个LLM 改善这种情况的第一种方法是通过提示工程——换句话说,是在你发送给LLM之前对用户的请求进行正式化和改进。这里有一个例子,它采用用户数据并将其与应用程序指令结合起来,构建最终的提示:

提示工程 现在仍然只有一个提示被发送到LLM,但现在它是一个详细的指令文档,分成了清晰的几部分,用户的数据嵌入其中。
准备一个提示是一个关键步骤,但还有更多可以做的。将应用程序视为LLM上的一个独立的抽象层有助于思考。换句话说,应用程序可以为LLM交互添加新的可能性和功能。例如,你可以获取用户的请求,推断他们想要执行的任务,并使用该任务来发起多个LLM请求。有时,一个请求会使用从前一个请求返回的数据,这是一种称为提示链的技术:
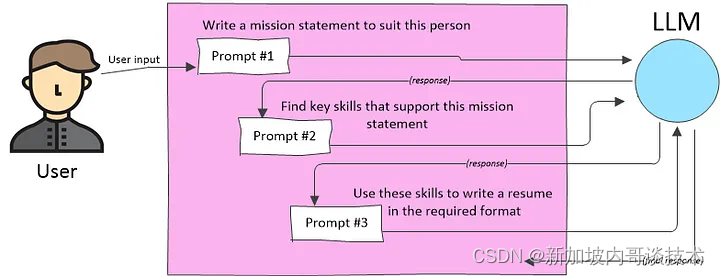
提示链 我们还没有看到今天LLM应用的主导模式,即检索增强生成(RAG)。这里的想法是从另一个来源提取一块相关的、特定领域的信息,并使用该信息在你发送给LLM的提示中。检索到的信息可以包括私有数据,给基础模型提供它以前从未见过的信息。

检索增强生成(RAG) RAG的概念看起来很直接。然而,它引入了两个重大挑战:
数据的数量
你不能把LLM可能需要的所有东西都塞进你的提示中。例如,如果你想要一个LLM使用《战争与和平》中的引用来构建论点,你不能把整本书的文本放入提示中,因为那超出了LLM的上下文窗口可用的空间。(上下文窗口是LLM一次可以考虑的所有新数据的度量。即将到来的LLM可能会有明显更大的上下文窗口,可能解决这个问题。然而,专家们仍然相信,将大量数据塞进上下文窗口在可预见的未来将是极其缓慢和昂贵的。)
数据的相关性
如果你不能使用所有东西,你给LLM的东西最好是相关的。例如,如果你在询问关于《战争与和平》的问题,你应该选择可能包含你希望LLM分析的内容的摘录。要使这项工作,你需要另一种AI驱动的能力,称为语义搜索,我们将很快讨论。 这些架构是关键的构建块。当你将这些技术结合在一起时,你将看到一些真正新的AI辅助交互的可能性。例如,想象你正在创建一个个人健康应用程序。如果你没有这些架构在心中,你可能会实现一个非常简单的模式:添加一个聊天机器人功能,告诉LLM它是一个致力于提供建议的健康专家,并让用户提问。但如果你更有野心,你可以构建这样工作的软件:
- 首先,应用程序采访用户以收集健身目标并创建个人档案(不需要AI)。
- 接下来,应用程序要求LLM根据个人档案创建总体健康目标,可能会查看一份经过审核的建议列表或使用一个可信来源。
- 然后,根据用户的兴趣和行动,应用程序要求LLM构建样本菜单,建议正念练习,并计划每周的锻炼时间表。
也许你心中有更雄心勃勃的互动想法——例如,在日历中添加锻炼提醒,将食谱成分放入购物清单,寻找当地活动,发送电子邮件,启动其他应用程序。此时,就很清楚LLM不再仅仅是一个文档生成器或智能搜索工具。
这些想法有些还不成熟和实验性。目前,我们有很多令人印象深刻的玩具项目,但在这个领域还没有突出的成功。但这种情况很可能在几个月内,而不是几年内发生变化。
基础建设
在我们迄今为止看到的例子中,“应用程序”部分是我们开发者需要构建的,我们利用自己的常规技巧和对问题领域及业务的理解来完成这一任务。应用程序外部有两个预构建的成分:
- 大型语言模型(LLM)
- 向量数据库
让我们深入了解实现这一架构的技术细节。
选择LLM
目前,开发者们用来原型设计新LLM应用的最常见的LLM是OpenAI的GPT-4。OpenAI API的优势在于它是最成熟的产品。它是最易于编程使用的LLM,其响应最为一致,需要的额外工作最少。
开发者创建了概念验证之后,会进行实验。更便宜的GPT-3.5 Turbo能否同样有效?把它迁移到像Claude或甚至是开源的Llama这样的替代服务上怎么样,这两者都可以通过亚马逊Bedrock服务轻松访问?如果你雄心勃勃,一个开源的LLM模型可以自我托管,尽管这自带其挑战,目前这还不是一个常见的方法。
选择向量数据库
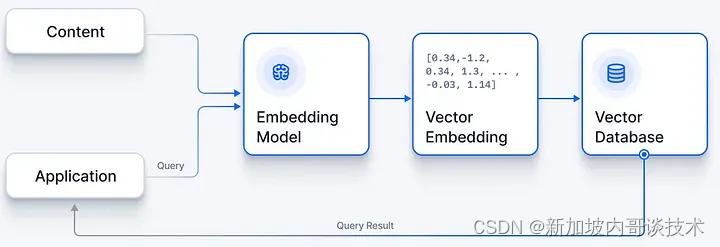
向量数据库以一种特殊的数值表示形式存储文本块,称为向量嵌入。这与LLM理解提示中的文本的过程相同。但拥有嵌入式内容的真正优势在于你可以使用自然语言处理(NLP)的特性来分析它。最有用的是,你可以使用词语的概念含义而非它们的字母来进行搜索。例如,“认证”的嵌入可能与“密码”的嵌入类似,允许搜索找到相关内容,这些内容不一定使用完全相同的词语,但覆盖相同的主题。
NLP是支撑LLMs的AI的基础领域。为了为你自己的内容创建嵌入,你需要一个嵌入模型。你可以使用一个开源库——有几个——但再次强调,最简单的服务是由OpenAI API提供的。
一旦你创建了嵌入,就需要将它们存储在数据库中。你需要使用一个向量数据库,它将索引你的文本块,以便你能高效地搜索它们。目前最常用的向量数据库是Pinecone,它是一个完全托管的云服务。然而,向量数据库领域几乎与LLMs一样快速发展,还有许多其他产品可以尝试。
未来,我将更仔细地查看使这些单独部分工作的工具,比如不同语言的LLM库。现在你已经对整体架构有了坚实的理解,这些细节将更有意义。即使你现在不急于开始构建自己的AI驱动实验,这个概览仍然是一个很好的参考点。因为到明年这个时候,这个领域肯定会再次发生翻天覆地的变化。

