
- 1计算机毕设 大数据二手房数据爬取与分析可视化 -python 数据分析 可视化_大数据分析毕设数据量多少合适
- 2ti-idf算法,实现对英文文档的检索,把多篇文档中的词(英文单词),按照权值从小到大进行排列_ti-idf
- 3史上最全的数字转型必读书单,私藏TOP经典数字化转型书单
- 4NLP自然语言处理之句法分析_nlp句子处理
- 5作为NLP算法,最近被ChatGPT刷屏后的心路历程
- 6概率论与数理统计B 重点/笔记梳理 第二章_概率论与数理统计考点归纳两点分布
- 7如何根据自有数据拟合绘制3D曲面图-Python matplotlib_已知数据拟合曲面
- 8知识抽取-实体及关系抽取(一)_实体识别和关系抽取
- 9Ubuntu 20.04安装CUDA失败导致系统黑屏消息nvidia 0000:01:00.0: can‘t change power state from D3cold to D0 的解决方法_can't change power state from d3cold to d0
- 10Java在线健康测评评测系统设计与实现(Idea+Springboot+mysql)
[好文翻译]用于遥感图像检索聚集的深度局部特征_[1]y. yang, and s. newsam. geographic image retrie
赞
踩
Raffaele Imbriaco , Clint Sebastian, Egor Bondarev,Peter H.N
埃因霍温工业大学电气工程系视频编码和架构小组
摘要:由于遥感影像的特殊性,遥感影像检索仍然是一个具有挑战性的话题。遥感图像包含各种不同的语义对象,这显然使检索任务复杂化。在本文中,我们提出了一种图像检索流程,该流程使用了细心的局部卷积特征,并使用局部聚集描述符向量(VLAD)对其进行了聚集,以生成全局描述符。我们研究各种系统参数,例如乘法和加法注意力机制和描述符维数。我们提出了一种不需要外部输入的查询扩展方法。实验表明,即使不进行训练,局部卷积特征和全局表示也优于其他系统。经过系统调整之后,我们可以获得最先进的或具有竞争力的结果。此外,我们观察到,我们的查询扩展方法仅使用前三个检索到的图像即可将整体系统性能提高约3%。最后,我们展示降维如何产生紧凑的描述符,并提高检索性能和加快检索计算时间,例如比当前系统快50%。
关键字:图像检索; 卷积描述符; 查询扩展; 描述符聚合;卷积神经网络
1.简介
基于内容的图像检索(CBIR)是图像检索的一个分支,它使用视觉查询信息(例如颜色,纹理)在数据库中找出相似或匹配的图像。从使用人工设计的描述符(例如SIFT [1])到从卷积神经网络(CNN)[2] [3] [4]中提取的学习型卷积描述符,该技术一直在稳步发展。此外,已经提出了几种用于大规模图像检索的描述符聚合方法,例如词袋模型(BoW)[5]、局部聚合描述符向量(VLAD)[6]、费舍尔核(Fisher Kernels,FK)[7]和记忆向量(Memory Vectors)[8]。在遥感(RS)领域,也已采用了相关技术,并取得了积极进展。空间分辨率和图像数据库大小的增加已引起人们对能够基于其可视内容有效检索遥感图像的系统和技术的兴趣。遥感图像检索方法(RSIR)结合了标准图像检索的一些先进技术,以及使用BoW表示[9],局部不变描述符[10]或学习的卷积特征[11] [12]的方法。
CBIR系统可以用两个基本过程来概述。首先是特征提取,处理图像视觉内容的紧凑,描述性表示形式。此过程将图像映射到高维特征空间。第二个是图像匹配,产生一个表示查询和数据库图像的可视内容相似度的数值。该值用于对图像进行排序并选择最佳候选匹配项,然后将其呈现给用户。图1描绘了这种通用的CBIR系统。
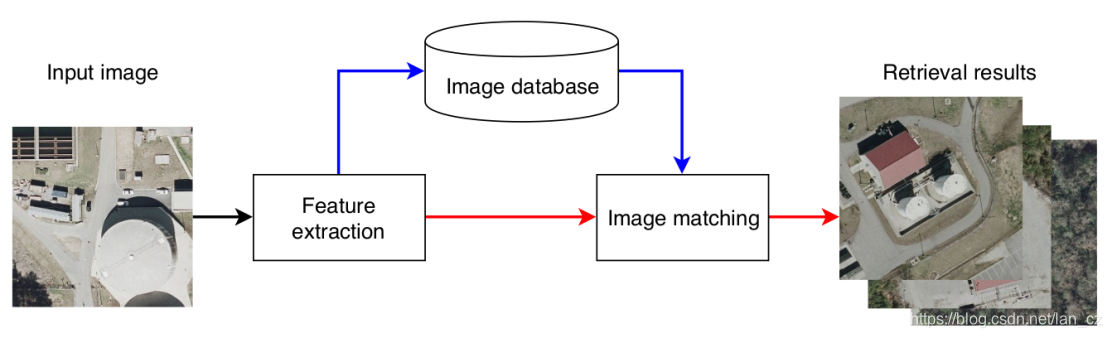
图1. CBIR系统流程图,显示查询(红色)和数据库(蓝色)数据流。
RSIR的挑战在于遥感图像描绘了较大的地理区域,其中可能包含各种各样的语义对象。此外,属于相同语义类别的图像可能具有明显的外观变化。因此,准确检索具有相似视觉内容的图像需要提取足够描述性和鲁棒性的特征。此外,系统应在合理的时间内检索出结果。因此,生成的描述符应具备高度区分性,同时实现高效的数据库搜索。现有的文献将描述符分为三类。
第一类由低级描述符组成,这些描述符对颜色,光谱特征和纹理等信息进行编码[13-15]。第二类由中级特征表示,这些特征通常是通过使用BoW汇总为全局表示的局部不变特征来获得的,如[10]中所述。第三类包括语义特征,这些语义特征对诸如“树”或“建筑物”之类的语义概念进行编码,并从CNN中提取。最近,后者在图像检索领域变得很流行,并已成功地用于地标检索[2] [16] [17]、视觉位置识别[3] [18]和RSIR [9] [12]。在RSIR中,我们找不到任何系统可以直接为图像的最显著或最具代表性的区域生成局部卷积描述符。
在我们的工作中,我们提出了一种新颖的RSIR系统,据我们所知,它是第一个使用显著的多尺度卷积特征(attentive, multi-scale convolutional features)的系统。与先前的工作不同,使用描述符机制学习局部描述符,该机制不需要将图像划分为小块。注意力机制将在后面讨论。这使我们能够提取图像中最相关的对象的描述符,同时保留以各种比例捕获特征的能力。此外,我们使用局部聚合描述符向量(VLAD)执行描述符聚合,而不是使用通常在其他RSIR方法中应用的BoW框架。使用VLAD聚合局部描述符会带来更好的检索性能[6]。我们的系统还利用查询扩展来提高检索准确性。本文贡献如下:
- 提出了一种新颖的RSIR流程,可提取显著的多尺度卷积描述符,从而在各种RSIR数据集上产生最新的或更好的结果。这些描述符自动捕获各种尺度上的显著语义特征。
- 我们展示了系统的泛化能力,并展示了如何将为地标检索而学习的特征成功地重新用于RSIR,并获得具有竞争力的性能。
- 我们尝试使用不同的注意力机制进行特征提取,并评估局部卷积特征的上下文是否对RSIR任务有用。
- 我们引入了不需要用户输入的查询扩展方法。这种方法可将平均性能提高约3%,且复杂度较低。
- 评估具有较低维描述符的RSIR。减少描述符的大小会产生更好的检索性能,并显著减少匹配时间。
本文的结构如下。第2节介绍并分析了标准图像检索和RSIR中的相关工作。第3节描述了所提出的RSIR系统的体系结构流程。这包括CNN体系结构及其训练,描述符提取,描述符聚合和图像检索。第4节介绍了数据集,评估指标和实验结果。最后,第5节总结了论文。
2.相关工作
本节总结了标准图像检索和RSIR中的各种工作。首先,概述了传统图像检索的趋势,特别强调了用于大规模CBIR的描述符聚合技术和卷积描述符的提取。之后,提出了各种RSIR方法,从传统技术(即手工设计的特征)到当前的最新技术。
2.1图像检索
2.1.1 描述符聚合
直到最近几年,图像检索一直基于手工制作的特征(例如SIFT [1]),这些方法通常与聚合方法结合使用,例如:词袋模型(BoW)[5]。而局部描述符则表现出一些理想的特性,例如尺度和方向不变形和启用几何验证。但是,它们缺乏全局描述符提供的紧凑性和存储效率。聚合对于有效的数据库搜索是必需的,因为单个图像可以包含大量的局部描述符。像BoW这样的描述符聚合技术会为每个图像生成单个全局表示。该表示可以是例如图像中的视觉单词的频率直方图或高维向量。查询和数据库图像之间的相似性是由矢量运算确定的,例如欧几里得距离或余弦相似性。给定图像中的大量描述符,聚合方法的目标是生成紧凑但描述性的全局表示形式。在文献中已经提出了其他描述符聚合方法。其中,我们认为VLAD [6]和Fisher Kernels(FKs)[7]是主要技术。这些描述符聚合方法的共同因素是,它们首先计算量化器或码本。对于FK码本,这是通过高斯混合模型实现的,而对于VLAD和BoW,则使用k-均值算法。在VLAD和FK的情况下,将局部描述符的统计信息编码为单个向量,从而产生比BoW模型更好的性能[6]。
传统的图像检索利用后处理技术来提高检索性能。几何验证[5] [19–21]和查询扩展[22–25]是文献中用于此类增强的两种流行方法。第一种技术称为几何验证,用于识别同时出现在查询图像和候选图像中的特征。通常部署RANSAC [26]或Hamming Embedding [19] [27]算法,其中候选者的质量由匹配特征的数量决定。这使得检索系统可以拒绝具有相似视觉内容但指示不同对象的候选对象。第二种技术称为查询扩展,它使用正确匹配的特征来扩展查询的特征以支持成功匹配。以这种方式,可以通过连续查询来检索更相关的图像。通常使用几何验证来评估候选图像的正确性。查询扩展技术与几何验证结合使用特别有用,而后者可以独立使用。
在上面讨论的工作中,每个图像生成几个局部描述符,需要进行聚合才能有效检索。另一种解决方案是直接从图像中提取全局表示,例如GIST描述符[28]。但是,图像检索文献中出现了一个明显的趋势,其中手工描述符被从CNN中提取的高级学习描述符代替。这些高级描述符提供了可辨别的,整体表现,胜过手工制作的描述符[29]。
2.1.2 卷积描述符
在[2]中,Babenko等人证明了CNN系统用于分类的高级特征也可以用于图像检索。通过使用与检索任务相关的图像对CNN进行再训练,可以提高这种系统的检索性能。他们还表明,从中层提取的特征比从深层提取的特征更适合图像检索。但是,卷积层会产生高维张量,这些高维张量需要聚合成更紧凑的表示形式才能有效检索图像。最常见的方法是使用求和池化[16]或最大池化[30]等池化操作对特征张量进行矢量化。Tolias等在文献[31]中提出了一种改进的池化操作,它使用积分图像进行有效的描述符计算。它们的描述符对图像中的区域进行编码,并用于图像检索和对象定位。文献[4]中,提出了一种新的CNN架构,该架构可以学习和提取图像显著区域中的多尺度局部描述符。这些描述符被称为深度局部特征(DELF),其性能优于其他全局表示和用于图像检索的手工描述符[29]。与传统的手工描述符相比,DELF描述符提供的一个优势在于,图像中特定特征的相关性也得到了量化。这是通过一种注意力机制来完成的,该机制了解特定语义类的哪些特征更具区分性。 RSIR可被视为图像检索的专门分支。目的仍然是基于相似图像的视觉内容来识别它们。
但是,遥感图像提出了独特的挑战,阻碍了图像检索中常见的某些技术(例如几何验证,查询扩展)的直接部署。遥感图像覆盖较大的地理区域,其中可能包含以各种分辨率捕获的大量不同的语义对象。此外,常见的遥感数据集包括属于同一语义类别的图像,但是它们显示出较大的外观变化,或者是在不同的地理区域中获取的。这导致了针对RSIR问题的专用解决方案的开发,如下所示。
2.2 遥感图像检索
最早的RSIR工作[13] [32]提出了用于图像匹配和分类的手工纹理特征。接着,文献[33]和[34]的工作提出了一个更复杂的系统。作者部署了使用Gibbs-Markov随机字段作为空间信息描述符的贝叶斯框架。 文献[35]研究了各种距离度量(例如欧几里得距离、余弦相似度)对于基于直方图的图像表示的有效性。文献[15]介绍了用于遥感影像的完整CBIR系统GeoIRIS。该系统提取、处理和索引各种图像特征。它使用基于分快的特征(光谱、纹理和人为特征)和基于对象的特征(形状、空间关系)来提供信息丰富的遥感图像表示。 [36]中提出通过使用相关性反馈来训练用户支持向量机的方法。 [37]中提出了一种使用相关反馈的改进的主动学习方法,其中尝试将所需的用户注释数量减至最少。在[10]和[38]中,出现了传统的图像检索特征和框架,用于CBIR和目标检测。这些方法使用SIFT [1]、Harris [39]或高斯差分[40]特征以及BoW框架来提供图像的紧凑全局表示。在[14]中引入了替代的聚合描述符,其中将SIFT(局部)和纹理(全局)特征融合到单个描述符中,并馈入分类器。最近的工作[41]产生了极小的二进制全局表示,用于快速检索。
上面讨论的工作使用RSIR的低级特征(颜色,纹理)或中级特征(BoW直方图)。但是,这些类型的特征不对语义信息进行编码。在[42]中提出了一种减少这种语义鸿沟的方法。这项工作使用低级视觉特征使用概念邻域模型[43]创建对象的更复杂的语义解释。它在场景对象之间构造关系图,以基于语义信息检索图像。最近的方法已经从手工设计的特征转换为卷积描述符[44]。 Penatti等在文献[11]证明,即使在其他数据集上训练了卷积描述符,航空图像分类也能很好地概括。文献[9]中提出的一种RSIR系统,可以学习从图像到文本表达的映射。将卷积特征用于RSIR的另一项工作是[12]。通过将图像划分为小块并为每个小块提取卷积描述符,可以实现最新的结果。这些描述符使用BoW框架进行汇总。 [12]中的RSIR系统与使用卷积描述符的其他方法之间的主要区别在于,它们的训练不受监督。它部署了一种深层的自动编码器体系结构,该体系结构可重构输入图像切片并学习相关特征。最近的工作集中在生成紧凑和有区别的描述符。这可以通过[45]中显式学习非二进制短代码来实现,也可以通过[46-48]中联合学习特征和二进制表示来完成。但是,这些方法会产生低维的全局描述符,这意味着无关的背景信息可能仍会编码在最终描述符中。我们基于注意力的特征提取模块可以了解哪些图像区域与特定类别更相关,而无需考虑无关区域。
此外,我们的方法允许使用众所周知的技术(例如主成分分析(PCA)[49])生成低维向量。在[50]中,适度的降维对图像检索性能有积极影响。我们的工作中提出的方法的固有优势是,可以根据特定于应用程序的要求选择描述符的最终维数,而无需更改CNN架构。可以注意到,RSIR的进步源于传统图像检索的发展。但是,许多技术都需要适应遥感影像的特征。这解释了为什么在这项工作中,我们提出了一个结合了最新的局部描述符和图像检索技术的RSIR系统。这些局部卷积描述符是基于特征显著性以端到端的方式提取的。这些与VLAD聚合相结合,以实现紧凑和描述性的图像表示,从而可以快速进行数据库搜索。这种方法使我们的系统能够捕获各种规模的高级语义信息。
3.遥感图像检索流程
本节介绍组成我们的RSIR系统的过程,包括特征提取,描述符聚合和图像匹配。首先,它介绍了深度局部描述符(DELF)[4]体系结构,本文工作中使用的不同注意模块以及训练过程。其次,总结了VLAD表示形式。第三部分介绍了图像匹配和检索过程。此外,引入了仅使用全局表示并且不需要用户输入的查询扩展策略。简化的系统架构如图2所示。
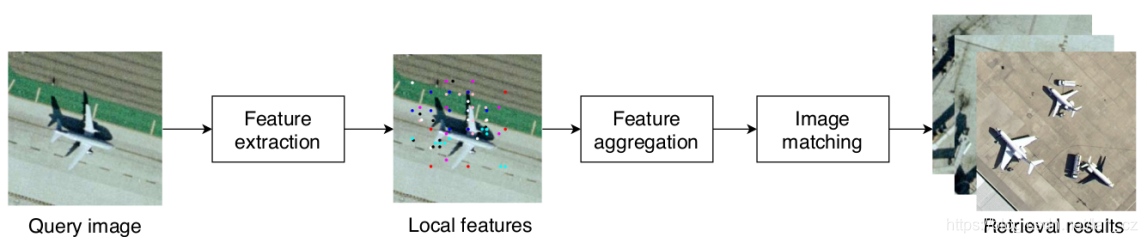
图2 本文提出的遥感图像检索流程
3.1 特征提取
任何CBIR系统的第一步都是找到图像视觉内容的有意义的描述性表示形式。我们的系统利用DELF,它基于局部的、显著的卷积特征,可以在困难的地标识别任务中实现最新的结果[4] [29]。特征提取过程可以分为两个步骤。首先,在特征生成过程中,通过训练用于分类的全卷积网络从图像中提取密集特征。我们使用ResNet50模型[51],并从第三个卷积块中提取特征。第二步涉及选择基于注意力的关键点。密集特征不会直接使用,而是会利用注意力机制来选择图像中最相关的特征。给定遥感图像的性质,无关的对象通常会出现在属于不同类别的图像中。例如,描述中等密度的城市化区域的图像还可以包括其他语义对象,例如车辆,道路和植被。注意力机制将学习与每个类别相关的特征,并对它们进行相应的排序。注意力机制的输出是网络提取的卷积特征的加权和。在对特征进行微调之后,将在一个单独的步骤中学习此特征的权重。 文献[4]制定注意力训练程序如下。应当为每个特征向量学习一个得分函数,其中代表函数的参数,= 1,…,第个特征向量为,并且,其中表示特征向量的大小。使用交叉熵作为损失函数,网络的输出为:
(1)
为个类别最终预测层的权重。作者使用简单的CNN作为注意力机制,这个较小的网络使用了softplus [52]激活特征,以避免学习特征的负权重。我们将这种注意力机制表示为乘法注意力,因为最终输出是通过图像特征及其注意力得分相乘获得的。如果网络认为这些特征没有足够的相关性,则公式(1)会抑制图像中的许多有用的特征。作为替代方案,我们还研究了一种称为加性注意的不同注意力机制。网络的输出公式为
(2)
尽管希望删除不相关的对象,但对于遥感图像,乘性注意力机制也可能会删除一些有关不同语义对象上下文的有用信息。增强相关特征的注意力机制,同时保留有关其周围环境的信息,可能在RSIR任务中很有用。我们建议使用加法注意力,这与乘法注意力不同,它可以在不抵消所有其他图像特征的情况下增强显著特征。
图3描述了用于特征提取的乘法注意力和加性注意力模块的网络体系结构。我们使用与[4]中类似的方法来训练这个网络。使用交叉熵作为损失函数,将特征提取网络训练为分类器。用于训练的图像被调整为224×224像素。在此阶段,我们不采用随机裁剪,因为目标是为遥感图像学习更好的特征,而不是特征定位和显著性考虑。注意力模块以半监督的方式进行训练。在这种情况下,将随机裁剪输入图像,并将裁剪大小调整为224×224像素。交叉熵仍然是训练注意力的损失函数,这样,网络应学会识别哪些区域和特征与特定类别更相关。此过程不需要其他标注,因为仅原始图像标注用于训练。该体系结构的另一个优点是可以在一次流程中提取多尺度特征。通过调整输入图像的大小,可以生成不同尺度的特征。此外,不需要手动将图像分解为小快的切片。 [4]的作者在特征提取网络和注意力模块分别训练时得到更好的检索性能。如[4]中所述,首先训练特征提取网络。然后,该网络的权重被重新用于训练注意力网络。
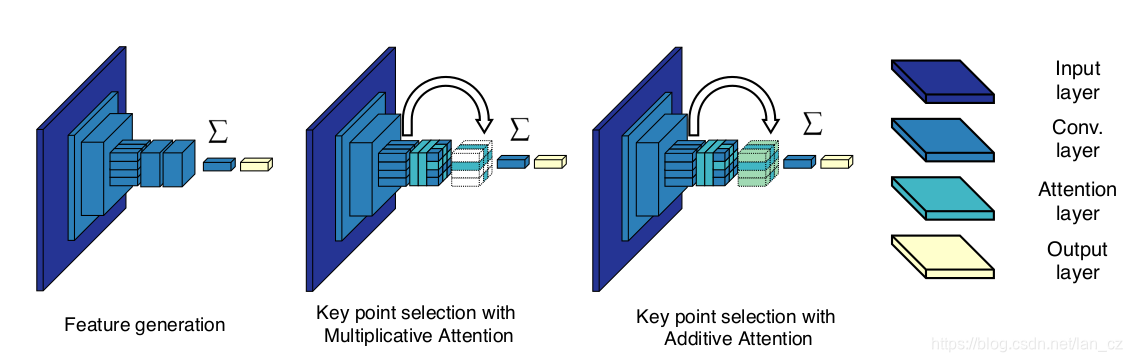
图3.特征提取和关注模块的体系结构。改编自[4]
训练后,通过删除最后两个卷积层为每个图像生成特征。通过调整输入图像的大小并将其通过网络来提取多尺度特征。与原始论文一样,我们使用从0.25开始到2.0结束的7个不同尺度,间隔因子为。网络产生的特征是大小为1024的向量。除了卷积结果之外,每个DELF描述符还包括它在图像中的位置,注意力得分和发现该特征的比例。对于描述符聚合,我们仅利用最显著的特征。我们每个图像存储300个特征,按它们的注意力得分和所有7个等级进行排序。这对应于所有提取的具有非零注意力得分的描述符中的21%。请注意,要素在尺度上分布不均。例如,在UCMerced数据集上,53%的要素属于第三和第四等级(1.0和1.4142)。其余特征未被利用。
3.2描述符聚合
DELF特征是局部的,这意味着直接特征匹配的计算量很大。每个查询图像可能包含大量局部特征,应将其与每个数据库图像中相同数量的特征相匹配。在图像检索文献中对此问题的常见解决方案是描述符聚合。这将生成图像内容的紧凑,全局表示。 RSIR文献中最常见的聚合方法是BoW。但是,现代图像检索系统应用了其他聚合方法,例如FK [7],VLAD [6]或聚合的选择性匹配核[53]。在这项工作中,我们使用VLAD生成一个单独的矢量,该矢量编码图像的视觉信息,因为它优于BoW和FK [6]。与BoW相似,使用k-means算法构造具有个视觉单词的视觉词典或码本。码本用于划分特征空间并累积与聚类中心有关的局部特征的统计量。
考虑属于图像的维局部特征的集合。对于每个视觉单词,将计算和累积与和视觉单词相关联的特征之间的差异。特征空间被划分为个不同的Voronoi单元,产生特征,其中表示最接近视觉单词的特征。 VLAD描述符构造为个分量的串联,每个分量由
(3)
其中是对应于第个视觉单词的矢量,从而得出 d维矢量。最终描述符是归一化的。VLAD聚合过程如图4所示。
图4. =4的VLAD描述符聚合示例。视觉词和最接近的图像特征之间的差异被累加到个向量中。每个向量被连接起来并产生一个全局描述符。
BoW和VLAD表示形式之间的重要区别是后者部署的视觉词典使用的视觉单词相对较少。在[6]中,FK和VLAD描述符的视觉词典包含16或64个视觉单词。同时,基于BoW的系统需要明显更大的值。在[9]和[12]中,分别将50,000和1,500个视觉词汇用于聚合描述符。最终的VLAD描述符大小取决于视觉单词的数量和原始描述符维。在我们的系统中,提取的局部描述符的大小为1,024。为了避免使用非常大的描述符,我们将的值限制为16个视觉单词,从而得到大小为16的VLAD向量。
关于我们的码本的训练,我们仅使用提取的DELF特征的子集。如上一节所述,每个图像仅保留300个特征。然而,即使对于低值,训练具有大量高维描述符的码本的计算量也是巨大的。为了解决这个问题,我们选择所有可用描述符的一部分。选择每个图像的N个最显著的DELF描述符来训练视觉词典。这样每个训练数据集大约可生成200K到300K的描述符。在下一部分中,我们将提供N个最显著的描述符的特定值。尽管可以在其他数据集上训练特征提取模块,但每个数据集都分别对码本和特征提取模块进行了训练。因此,我们获得了最具描述性的表示形式。
一旦完成码本训练,每个图像都会生成一个VLAD描述符。这些描述符在匹配模块中用于识别视觉上相似的图像。特征提取和描述符聚合过程是针对所有图像离线执行的。
3.3图像匹配和查询扩展
每个数据库图像都有VLAD表示形式后,就可以执行CBIR。给定查询图像,我们在其描述符和每个数据库图像的描述符之间采用相似性测度。根据测度对数据库图像进行排名,并将与查询图像最相似的数据库图像返回给用户。相似性由查询和数据库向量的欧几里得距离确定。如前所述,常规图像检索使用专门技术来提高候选集的质量,其中两种流行的技术是几何验证和查询扩展。
几何验证通常是在局部特征的位置可用时执行的,包括将查询图像中找到的特征与检索到的特征进行匹配。但是,由于土地利用/土地覆盖数据集中存在明显的外观变化,因此在RS影像中很难进行几何验证。可替代地,由于可以在查询的局部特征和候选图像的局部特征之间找到变换,因此在传统的图像检索中可以进行几何验证。例如,考虑来自不同视图或具有部分遮挡的同一对象或场景的图像。在这些情况下,查询和检索到的图像之间将成功匹配许多局部描述符。在本文使用的数据集中,在不同地理位置获取了属于同一语义类别的图像。因此,由于特征不属于同一对象,所以几何验证变得不可能。此外,几何验证在计算量大,并且以此方式只能评估少数候选者。
另一种技术是查询扩展,它使用正确的候选项来增强查询的特征。在图像检索中,通常是通过使用正确匹配的视觉词扩展查询的视觉词,然后重复查询来完成的。但是,通常使用几何验证来识别良好的匹配项。如前所述,很难在遥感影像中执行几何验证。但是,在我们的系统中,我们建议采用一种查询扩展方法,该方法的计算复杂度也较低。检索后,我们选择前三张候选图像,并结合其描述符以改进图像匹配过程。我们假设前三张图片将始终为查询扩展提供视觉上最接近的匹配和最相关的特征。此过程通常将需要访问要聚合的图像的局部描述符。但是,这意味着必须进行其他磁盘访问操作,因为在检索过程中不会将局部特征加载到内存中。为了避免这种情况,我们利用VLAD描述符的属性,并使用Memory Vector(MV)构造来生成扩展的查询描述符。 MV是一种全局描述符聚合方法,它产生一个组描述符。与视觉单词不同,这些表示没有语义含义。 VLAD和MV之间的区别在于后者不需要学习视觉词典。现在让我们考虑将各种VLAD全局描述符组合到MV表示中。目的是说明MV表示如何防止访问扩展查询的图像的局部描述符。 Iscen等在[8]提出了两种不同的方法来创建MV表示。第一个由p-sum表示,并定义为
(4)
是要聚合的全局表示的m×n矩阵,其中是全局表示的数量,是其维数。尽管很简单,但与VLAD描述符一起使用时,此构造很有用。应当记住,每个VLAD描述符被构造为使用等式(3)生成的个向量的串联。假设和是两个不同图像的VLAD表示,以及描述符矩阵的行元素。p-sum向量由下式给出:
(5)
与、分别为和的各个VLAD矢量分量。从等式(5)我们观察到,p-sum表示是两个图像中包含的特征的VLAD向量的近似值。代替从属于查询及其前三项匹配的特征的并集生成VLAD向量,我们可以通过利用MV构造来生成近似表示。直接VLAD聚集和p-sum聚集的结果并不相同,因为后者中使用的值已进行L 2归一化。但是,这种近似允许我们仅使用图像的整体表示。表示为p-inv的第二种构造方法为
(6)
其中()是描述符矩阵的Moore-Penrose伪逆[54]。此结构降低了向量中重复分量的贡献。在这项工作中,我们使用两种MV构造方法执行查询扩展,并比较它们的性能。
4.实验与讨论
本节详细介绍了应用的数据集,执行的实验和使用的硬件。首先,为数据集提供训练参数和评估标准。其次,使用为地标识别而学习的特征来评估我们提出的系统的性能。预训练的DELF网络用于特征提取。第三,在遥感影像上训练特征提取网络后,重复进行检索实验。这些实验还包括两种不同注意力机制的比较。对于先前的实验,我们提供带或不带查询扩展的检索结果。最后,研究了描述符维数对检索性能和图像匹配时间的影响。实验是在装有GTX Titan X GPU,Xeon E5-2650 CPU和32 GB RAM的计算机上进行的。
4.1 实验参数
4.1.1 数据集和训练
应用了四个不同的数据集来评估所提出系统在不同条件下的检索性能。数据集是:
(1)UCMerced土地利用[55],
(2)卫星遥感图像数据库[56],
(3)SIRI-WHU的Google图像数据集[57-59]和
(4)NWPU-RESISC45 [60]。
表1 每个数据集的详细信息
表1中列出了每个数据集的详细信息(图像大小,图像数量等)。为避免特征提取网络过度拟合,需要拆分数据集。仅80%的数据集图像用于训练。将属于SIRI数据集的图像调整为256×256像素,以生成与其他数据集相同大小(高度和宽度)的激活图。关于视觉词典的生成,仅使用了全部特征的一小部分。对于UCM,SATREM和SIRI,每个图像使用前100个特征。这产生了用于码本生成的足够大的特征集,同时降低了计算量。 NWPU视觉词典受训练的特征少得多。在此,鉴于此数据集中包含的图像数量更多,我们仅使用每个图像的前10个特征。如上一节所述,我们为每个图像选择最显著的特征。对于每个数据集,特征提取和视觉词典都需要重新训练。
4.1.2 评估标准
我们使用图像检索任务中的常用指标——检索精度进行评估。如果图像与查询图像属于同一语义类,则认为该图像与查询图像非常匹配。此外,我们仅考虑每个查询图像的20个最佳候选者,以减少输出数量。检索精度定义为来自同一类别的匹配项数除以检索到的候选项总数。
4.1.3 与其他RSIR系统的比较
Tang等人的工作 [12]提供了各种RSIR系统的全面比较。这些系统的详细信息在表2中找到。我们将其获得的结果用作我们工作的实验参考。此外,我们使用从两个最新的遥感分类网络中提取的特征来执行RSIR。这些是词袋式卷积特征(BoCF)[61]和判别式CNN(D-CNN)[62]。对于BoCF,我们直接使用从预训练的VGG16网络提取的直方图图像表示形式。此方法的密码本大小为5,000个视觉单词。同时,从VGG16中提取D-CNN特征,并使用与训练DELF相同的分割在相应的数据集上进行微调。对于D-CNN,参数τ,λ1和λ2分别设置为0.44、0.05和0.0005。骨干网和参数是根据其性能来选择的。我们将没有查询扩展(QE)的系统结果表示为V-DELF。如上所述,可以使用两种不同方法之一来生成扩展查询向量。我们将针对每种方法使用QE的我们提出的系统的结果表示为QE-S或QE-I,分别表示p-sum或p-inv构造。
4.2使用预训练的DELF网络进行特征提取
在最初的实验中,我们使用预先训练好的DELF网络进行特征提取。该网络接受了具有里地标的图像训练,这与遥感图像本质上是不同的。使用在不同类型的图像上训练的特征进行的RSIR实验可作为整个系统的初步测试。从不同任务中学到的特征已成功用于图像检索和分类任务。此外,该实验可以分析VLAD向量中的局部描述符的描述能力。在这里,仅评估原始的乘法注意力机制,并且我们使用16个单词的视觉词典,其特征向量大小为1,024。
该实验的结果在表3中给出。从表中可以看出,该方法能够获得较好的检索结果,除DBOW以外,其性能均优于其他大多数RSIR系统。回想一下,网络学习到的特征来自不同领域的图像(街道级地标图像)。系统中唯一可以调整到数据统计信息的部分是用于构造VLAD表示形式的可视词典。这些初步结果已经揭示了通过将局部DELF特征与VLAD描述符相结合而提供的强大表示能力,因为它的精度比除DBOW之外的所有其他方法都要好。
此外,我们注意到,查询扩展(QE)的添加不断提高了检索性能。尽管复杂度较低,但我们的QE方法可将平均性能提高大约3%。但是,查询扩展带来的这点提升和类别相关。例如,对于UCM数据集,“港口”类的检索精度仅提高0.3%,而“网球场”类的检索精度提高7%。具有良好检索结果的类别比困难的类别在精度上获得的提升较小。这表明QE可能会对检索性能较差的类别产生显著影响。此外,我们发现基于p-sum或p-inv构造的聚合之间没有较大差异。
表3.各种RSIR方法和DELF特征(在非遥感图像上预训练)之间的平均精度比较。
在采用手工特征的系统与采用卷积特征的系统之间,检索精度存在明显差距。后者在每个数据集中的表现都更好。因此,我们将仅将以下实验的结果与基于卷积特征的系统进行比较。在下一个实验中,我们在遥感影像上重新训练DELF网络,然后重复该实验。
4.3 遥感影像训练的特征的RSIR实验
我们使用上一部分中描述的方法对DELF网络进行了再训练。我们在遥感图像上训练了特征提取和注意力网络(乘法和加性)。每个图像提取新的局部描述符,并通过VLAD进行聚合,从而生成两个单独的描述符,每个注意力机制各一个。然后,重复进行检索实验,并分别统计每种注意力机制的检索精度。还对从微调的ResNet50提取的密集特征的检索性能进行了比较。每个图像由196×1024个描述符表示。
考虑到密集特征没有关联的相关性评分,我们为描述符聚合部署了略有不同的过程。首先,为了生成字典,从特征图中随机选择100个描述符。其次,从密集激活图的所有特征向量计算VLAD向量。重复此过程五次,并统计最高精度值。实验以单一尺度和不同尺度提取的特征完成。使用多尺度特征时,观察到性能下降约3%至4%。因此,我们使用单尺度密集特征统计结果。在不同类别上进行几次实验后,我们计算了每个实验的平均值,并将这些平均值记录到统计表中。该总体实验的结果在表4中找到,该表给出了上述类别实验的平均值。表8-7中提供了每个单独类别的详细精度结果。
注意力机制可显著提高检索性能。除SIRI数据集外,这两种注意力机制均优于从ResNet50提取的密集特征。注意力机制的训练中找到了跨数据集性能差异的最可能原因。例如,SIRI数据集中性能最差的类别是“河”和“池塘”。对这些类别的检索结果进行更仔细的检查后发现,“河流”图像的最常见(错误)检索结果是“池塘”,“港口”和“水”。同时,系统会将“ Pond”类中的图像与来自“ River”,“ Meadows”和“ Overpass”类中的图像混淆。这表明注意力机制无法正确学习哪些特征与这些类别相关,或者分类网络学习的特征对其中某些特征的描述不足。在这种差异方面,尽早终止培训程序可能会提高性能。图5描绘了每个比例尺上最吸引人的特征,以及它们对于不同图像的接受场。我们观察到,对于UCM和NWPU数据集,提出的系统比DBOW系统的性能高出8.59%和3.5%,而对于SATREM和SIRI数据集,DBOW系统的检索精度分别高出3.82%和8.83%。总而言之,我们的建议在两个数据集上表现良好,而对于其他两个数据集则较低。一个有趣的结果是BoCF的整体检索性能很差。对此行为的合理解释是缺乏特征提取网络的训练。从经过预训练的VGG16网络中提取的特征不像在RS数据上经过训练的网络那样具有区别性。同时,从D-CNN提取的特征提供了良好的检索性能,优于UCM数据集上的DBOW。通过D-CNN所采用的度量标准损失可以提高性能。度量学习产生的特征具有较低的班内差异和较高的班际差异,有助于识别正确的候选人。将度量学习与更深层或专心的网络相结合可以进一步提高检索性能。
表4.使用卷积特征的各种RSIR方法之间的平均精度比较。使用乘性注意力(MA)和加性注意力(AA)提取DELF特征。
表5.训练DELF网络后,UCM数据集的检索精度。粗体值表示性能最佳的系统。 DELF描述符的大小为16K。
表6.训练DELF网络后,SATREM数据集的检索精度。粗体值表示性能最佳的系统。 DELF描述符的大小为16K。
表7.训练DELF网络后,SIRI数据集的检索精度。粗体值表示性能最佳的系统。 DELF描述符的大小为16K。
表8. 训练DELF网络后NWPU数据集的检索精度。粗体值表示性能最佳的系统。DELF描述符的大小为16K。
图5.针对UCM的不同语义类别,描述了每个尺度的10个最显著的特征。从左到右分别是“稀疏住宅”,“飞机”,“棒球钻石”,“港口”。每种颜色代表不同的尺度。
我们现在讨论两种注意力机制在性能上的差异。从结果中可以直接注意到,乘法注意力比加性注意力机制提供了更好的性能。对于所有数据集,乘法注意力提供更高的平均精度。这种性能差异表明上下文信息对许多语义类都有干扰。因此,它减少了从网络中提取的特征的描述性,从而阻碍了检索过程。关于MV构造方法,乘积注意力在两种MV构造方法之间仅存在很小的差异,而加法注意会导致较大的变化。在UCM和NWPU数据集的结果中可以找到这方面的清晰示例。使用加法注意和p-inv构造时,平均检索精度比p-sum构造高5%。这可以通过p-inv构造的规范化效果和加法注意力机制中包含的上下文信息来解释。由于p-inv构造使用Moore-Penrose伪逆,因此将重复或突发特征的贡献归一化。在p-sum构造中不会发生这种情况,这会降低性能。
评估的另一个方面是查询扩展稳定性,方法是使用所有数据集和乘法注意力进行实验,尝试使用不同大小的检索集,因为它提供了最佳性能。在图6中,描绘了各种大小的检索集的平均精度。可以观察到,平均而言,检索多达五个图像时的检索性能很高。特别是,仅考虑前三幅图像时,所有数据集的检索精度都高于0.88。这个结果说明了为什么我们的查询扩展方法可以持续提高性能。我们的假设是在前三名中都可以找到良好的图像,这一事实确实得到了证实。在大多数情况下,这些图像的特征有助于更好地匹配。关于查询扩展的MV结构,可以看出查询扩展总是可以改善结果。此外,除了顶级精度外,它们的结果几乎相同。我们还在图7和图8中给出了定性匹配结果,其中显示了一些示例以及从UCM和NWPU数据集中获取的查询和图像。评估了两个附加参数对检索性能的影响。首先,我们研究用于构造密码本的描述符数量如何影响检索精度。在本实验中,VLAD描述符使用300个最细心的特征构造而成,并且用于代码本训练的特征数量也发生了变化。其次,我们评估构造VLAD描述符时使用的特征数量如何影响系统性能。在这种情况下,与之前的实验一样,使用100个描述符生成密码本。该研究的结果在表9中找到。
第一个实验表明,随着性能的提高,使用更多特征生成密码本是有益的。但是,如果使用过多的特征,则性能可能会下降,就像UCM和SIRI数据集一样。从第二个实验中,我们观察到用于VLAD生成的特征数量对检索到的图像集的质量影响更大。每个图像使用不足的特征会导致较差的检索质量。这表明一些特征(即使它们是最显著或最突出的)也不足以正确描述图像内容。当更多特征用于VLAD构建时,检索精度会提高。但是,性能似乎饱和了300个描述符。
表9.用于可视词典和VLAD构造的描述符数量对检索性能的影响。用于训练NWPU码本的描述符数量是表格中报告数量的十分之一。
虽然所提出的系统在RSIR任务中提供了最新的结果,但上述实验部署的描述符是原来的4倍大于先前工作中使用的最大描述符。由于图像检索系统应具有较高的计算效率,因此我们减小了表示的维数,并研究了对检索性能的影响。
图6.不同大小的检索集的平均精度。报告了包含1、3、5、10、15和20张图像的检索集的平均精度。
图7. UCM数据集的示例查询和检索到的图像。从上到下,查询图像属于“海滩”,“建筑物”,“高速公路”和“港口”类。
4.4 降维
本文提出的系统有两个不同的参数会影响最终的描述符维数:我们的密码本中的视觉单词数k和原始特征向量大小d。我们研究了这两个参数对检索精度的影响。 PCA用于将原始特征向量的尺寸减小为1,024、128、64、32或16,并应用16、8、4或2个视觉单词。使用与生成代码本相同的特征集学习主要组件。产生较低维描述符的另一种方法是直接降低VLAD向量的维数。由于VLAD表示的稀疏性和结构,在[6]中已证明这是有效的。但是,此过程不会减少用于生成码本的计算时间。我们针对每个描述符的大小和可视字典长度的每个组合,对每个数据集重复进行检索实验。结果显示在表10、11和图9中。
图8. NWPU数据集的示例查询和检索到的图像。从上到下,查询图像属于“机场”,“港口”,“桥梁”和“棒球钻石”类。
减少描述符维数时,我们观察到两个有趣的趋势。首先,通过PCA降维似乎是生成简洁而又高度描述性表示形式的有效方法。应用于特征向量或VLAD描述符的降维可提高性能。性能与全尺寸描述符相当,甚至更好。除[41]之外,这产生的全局表示比在其他工作中使用的较小。此外,与降低VLAD描述符的维数相比,直接将PCA应用于特征向量可提供更大的性能提升。此行为的可能原因是删除了原始特征向量中存在的不相关成分。这些组件的贡献在聚合后无法从VLAD描述符中完全删除。其次,最佳描述符大小d随数据集而变化。具有较大码本的中型描述符(大小为64或32)可提供最佳结果,并且胜过完整的16K维表示。
我们观察到,当增加视觉单词的数量时,性能也会提高。但是,饱和会迅速发生,因此较大的k值会导致性能增益受到限制。观察到的性能差异是由于每个提取的特征向量中PCA成分的密度。提取1,024维特征似乎包含不相关的数据。特征向量中包含的信息可以压缩到一定程度,而不会影响向量的整体描述性。由于较短的描述符可提高性能,因此我们将针对DBOW系统将这些描述符(d = 32,d = 64,k = 8)的检索精度进行比较。结果绘制在表10中。从该表可以得出结论,拥有足够大小的特征向量和视觉词汇量所带来的收益是巨大的。使用较小的描述符,我们可以获得更好的检索性能,从而使UCM和NWPU数据集的w.r.t分别提高了11.9%和5.7%。同时,SATREM和SIRI数据集中较早的性能改进减少到一半,分别为2%和4.6%。
表10. 使用低维描述符的平均检索精度。 PCA应用于DELF特征。
表11. 使用低维描述符的V-DELF的平均检索精度。
图9. 对所有数据集使用低维描述符的检索精度
应用PCA来减小VLAD描述子的大小。最后,我们研究了系统的计算复杂性。首先,测量多尺度特征提取所需的时间。平均而言,从单个图像获得DELF描述符仅需要20毫秒。码本的构造是计算上更昂贵的操作。所选要素(k = 16)的K均值聚类大约需要5分钟。但是,码本的生成是一个脱机过程,并非在每次查询时都执行。如果查询图像是新的,则无法预先计算其VLAD表示形式。因此,假设特征和码本均易于使用,我们还测量了生成VLAD描述符所需的时间。 VLAD聚合大约在10毫秒内完成。这意味着处理新查询的平均开销为30毫秒。我们还对检索执行时间进行比较。遍历整个数据库和检索图像所需的时间取决于两个数量。首先,数据库的大小,因为我们要检查数据库中的每个描述符。其次,向量大小,因为使用更长向量的度量会花费更多执行时间。我们遵循[12]的过程,并针对各种数据库大小比较原始描述符和压缩描述符的结果。这些结果报告在表12中,其中其他RSIR系统的检索执行时间取自[12]进行比较。我们观察到,描述符提供了最新的检索结果,并且根据描述符的大小,它们也是检索最快的。基于这些结果,建议减少尺寸,因为它既减少了图像匹配所需的执行时间,又减少了内存占用。关于查询扩展,检索执行时间应加倍,因为在整个数据集上有必要对聚合向量进行另一次比较。
表12.不同数据库和描述符大小的检索时间(以毫秒为单位)。 RFM,SBOW,DN7,DN8和DBOW的值可从[12]获得。
5结论
在本文中,我们提出了一个完整的RSIR算法流程,能够在检索精度和计算时间方面实现最新的结果。据我们所知,这是第一个部署以端到端方式提取的局部卷积特征的RSIR系统。我们已经展示了局部卷积特征以及VLAD聚合如何比现有建议产生显著更好的性能。对于为其他非RSIR任务学习型特征的情况,甚至更是如此。我们还评估了用于特征选择目的的两种不同的注意力机制,并得出结论,乘法注意力机制始终提供百分之几的更高性能。此外,我们引入了无需用户输入的低复杂度但高效的查询扩展方法。此方法使用p-sum或p-inv内存向量构造,以有效地将查询图像的描述符与前三个候选图像的描述符聚合在一起。用最匹配的查询扩展查询的特征可使性能提高约3%。我们还研究了通过减少码本中视觉单词的数量或特征向量大小来压缩全局表示的可能性。从这些研究中我们得出结论,即使对于相对较小的描述符大小(例如256或128),性能也不会受到负面影响,在某些情况下甚至可以提高精度。这使我们可以将较高的检索精度与较低的计算时间结合在一起。为了以后的工作,我们希望在处理包含较少类或图像内容非常相似的类(例如SIRI数据集中的“河”和“港口”类)的图像数据库时解决系统的难题。对于此类困难情况,对其他特征提取体系结构或注意力机制的更多研究可能会产生更好的检索性能。作者的贡献:R.I.和C.S.开发了代码,进行了实验并分析了结果。
参考文献:
1.Lowe, D.G. Object recognition from local scale-invariant features. Computer vision, 1999. Proc. of 7th IEEE intl. conf. on. Ieee, 1999, pp. 1150–1157.
2.Babenko, A.; Slesarev, A.; Chigorin, A.; Lempitsky, V. Neural codes for image retrieval. European conference on computer vision. Springer, 2014, pp. 584–599.
3.Sünderhauf, N.; Shirazi, S.; Jacobson, A.; Dayoub, F.; Pepperell, E.; Upcroft, B.; Milford, M. Place recognition with convnet landmarks: Viewpoint-robust, condition-robust, training-free. Proceedings of Robotics: Science and Systems XII 2015.
4.Noh, H.; Araujo, A.; Sim, J.; Weyand, T.; Han, B. Large-Scale Image Retrieval with Attentive Deep Local Features. 2017 IEEE International Conference on Computer Vision (ICCV) 2017, pp. 3476–3485.
5.Sivic, J.; Zisserman, A. Video Google: A text retrieval approach to object matching in videos. null. IEEE, 2003, p. 1470.
6.Jégou, H.; Douze, M.; Schmid, C.; Pérez, P. Aggregating local descriptors into a compact image representation. Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on. IEEE, 2010, pp. 3304–3311.
7.Perronnin, F.; Dance, C. Fisher kernels on visual vocabularies for image categorization. 2007 IEEE conference on computer vision and pattern recognition. IEEE, 2007, pp. 1–8.
8.Iscen, A.; Furon, T.; Gripon, V.; Rabbat, M.; Jégou, H. Memory vectors for similarity search in high-dimensional spaces. IEEE Tran. on Big Data 2017.
9.Bai, Y.; Yu, W.; Xiao, T.; Xu, C.; Yang, K.; Ma, W.Y.; Zhao, T. Bag-of-words based deep neural network for image retrieval. Proceedings of the 22nd ACM international conference on Multimedia. ACM, 2014, pp. 229–232.
10.Yang, Y.; Newsam, S. Geographic image retrieval using local invariant features. IEEE Transactions on Geoscience and Remote Sensing 2013, 51, 818–832.
11.Penatti, O.A.; Nogueira, K.; dos Santos, J.A. Do deep features generalize from everyday objects to remote sensing and aerial scenes domains? Proceedings of the IEEE conference on computer vision and pattern recognition workshops, 2015, pp. 44–51.
12.Tang, X.; Zhang, X.; Liu, F.; Jiao, L. Unsupervised deep feature learning for remote sensing image retrieval. Remote Sensing 2018, 10, 1243.
13.Manjunath, B.S.; Ma, W.Y. Texture features for browsing and retrieval of image data. IEEE Transactions on pattern analysis and machine intelligence 1996, 18, 837–842.
14.Risojevic, V.; Babic, Z. Fusion of global and local descriptors for remote sensing image classification. IEEE Geoscience and Remote Sensing Letters 2013, 10, 836–840.
15.Shyu, C.R.; Klaric, M.; Scott, G.J.; Barb, A.S.; Davis, C.H.; Palaniappan, K. GeoIRIS: Geospatial information retrieval and indexing system—Content mining, semantics modeling, and complex queries. IEEE Transactions on geoscience and remote sensing 2007, 45, 839–852.
16.Babenko, A.; Lempitsky, V. Aggregating local deep features for image retrieval. Proc. of the IEEE intl. conf. on computer vision, 2015, pp. 1269–1277.
17.Hou, Y.; Zhang, H.; Zhou, S. Evaluation of Object Proposals and ConvNet Features for Landmark-based Visual Place Recognition. Journal of Intelligent & Robotic Systems 2017, pp. 1–16.
18.Arandjelovic, R.; Gronat, P.; Torii, A.; Pajdla, T.; Sivic, J. NetVLAD: CNN architecture for weakly supervised place recognition. Proc. IEEE Conf. CVPR, 2016.
19.Jegou, H.; Douze, M.; Schmid, C. Hamming embedding and weak geometric consistency for large scale image search. European conference on computer vision. Springer, 2008, pp. 304–317.
20.Lowe, D.G. Distinctive image features from scale-invariant keypoints. International journal of computer vision 2004, 60, 91–110.
21.Philbin, J.; Chum, O.; Isard, M.; Sivic, J.; Zisserman, A. Object retrieval with large vocabularies and fast spatial matching. Computer Vision and Pattern Recognition, 2007. CVPR’07. IEEE Conference on. IEEE, 2007, pp. 1–8.
22.Voorhees, E.M. Query Expansion Using Lexical-semantic Relations. Proceedings of the 17th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval; Springer-Verlag New York, Inc.: New York, NY, USA, 1994; SIGIR ’94, pp. 61–69.Remote Sens. 2019, 11, 5
23.Chum, O.; Philbin, J.; Sivic, J.; Isard, M.; Zisserman, A. Total recall: Automatic query expansion with a generative feature model for object retrieval. Computer Vision, 2007. ICCV 2007. IEEE 11th International Conference on. IEEE, 2007, pp. 1–8.
24.Chum, O.; Mikulik, A.; Perdoch, M.; Matas, J. Total recall II: Query expansion revisited. Computer Vision and Pattern Recognition (CVPR), 2011 IEEE Conference on. IEEE, 2011, pp. 889–896.
25.Arandjelovic, R.; Zisserman, A. Three things everyone should know to improve object retrieval. 2012 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2012, pp. 2911–2918.
26.Fischler, M.A.; Bolles, R.C. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography. Communications of the ACM 1981, 24, 381–395.
27.Jain, M.; Jégou, H.; Gros, P. Asymmetric hamming embedding: taking the best of our bits for large scale image search. Proceedings of the 19th ACM international conference on Multimedia. ACM, 2011, pp. 1441–1444.
28.Oliva, A.; Torralba, A. Modeling the shape of the scene: A holistic representation of the spatial envelope. International journal of computer vision 2001, 42, 145–175.
29.Radenovic, F.; Iscen, A.; Tolias, G.; Avrithis, Y.; Chum, O. Revisiting oxford and paris: Large-scale image retrieval benchmarking. IEEE Computer Vision and Pattern Recognition Conference, 2018.
30.Azizpour, H.; Sharif Razavian, A.; Sullivan, J.; Maki, A.; Carlsson, S. From generic to specific deep representations for visual recognition. Proc. IEEE conf. comp. vision pattern recogn. wshops, 2015, pp. 36–45.
31.Tolias, G.; Sicre, R.; Jégou, H. Particular object retrieval with integral max-pooling of CNN activations. arXiv preprint arXiv:1511.05879 2015.
32.Haralick, R.M.; Shanmugam, K.; others. Textural features for image classification. IEEE Transactions on systems, man, and cybernetics 1973, pp. 610–621.
33.Datcu, M.; Seidel, K.; Walessa, M. Spatial information retrieval from remote-sensing images-Part I: information theoretical perspective. IEEE TRANSACTIONS ON GEOSCIENCE AND REMOTE SENSING GE 1998, 36, 1431–1445.
34.Schroder, M.; Rehrauer, H.; Seidel, K.; Datcu, M. Spatial information retrieval from remote-sensing images. II. Gibbs-Markov random fields. IEEE Transactions on geoscience and remote sensing 1998, 36, 1446–1455.
35.Bao, Q.; Guo, P. Comparative studies on similarity measures for remote sensing image retrieval. Systems, Man and Cybernetics, 2004 IEEE International Conference on. IEEE, 2004, Vol. 1, pp. 1112–1116.
36.Ferecatu, M.; Boujemaa, N. Interactive remote-sensing image retrieval using active relevance feedback. IEEE Transactions on Geoscience and Remote Sensing 2007, 45, 818–826.
37.Demir, B.; Bruzzone, L. A novel active learning method in relevance feedback for content-based remote sensing image retrieval. IEEE Transactions on Geoscience and Remote Sensing 2015, 53, 2323–2334.
38.Sun, H.; Sun, X.; Wang, H.; Li, Y.; Li, X. Automatic target detection in high-resolution remote sensing images using spatial sparse coding bag-of-words model. IEEE Geoscience and Remote Sensing Letters 2012, 9, 109–113.
39.Harris, C.; Stephens, M. A combined corner and edge detector. Alvey vision conference. Citeseer, 1988, Vol. 15, pp. 10–5244.
40.Vidal-Naquet, M.; Ullman, S. Object Recognition with Informative Features and Linear Classification. ICCV, 2003, Vol. 3, p. 281.
41.Demir, B.; Bruzzone, L. Hashing-based scalable remote sensing image search and retrieval in large archives. IEEE Transactions on Geoscience and Remote Sensing 2016, 54, 892–904.
42.Wang, M.; Song, T. Remote sensing image retrieval by scene semantic matching. IEEE Transactions on Geoscience and Remote Sensing 2013, 51, 2874–2886.
43.Bruns, T.; Egenhofer, M. Similarity of spatial scenes. Seventh international symposium on spatial data handling. Delft, The Netherlands, 1996, pp. 31–42.
44.Marmanis, D.; Datcu, M.; Esch, T.; Stilla, U. Deep learning earth observation classification using ImageNet pretrained networks. IEEE Geoscience and Remote Sensing Letters 2016, 13, 105–109.
45.Zhou, W.; Newsam, S.D.; Li, C.; Shao, Z. Learning Low Dimensional Convolutional Neural Networks for High-Resolution Remote Sensing Image Retrieval. Remote Sensing 2017, 9, 489.Remote Sens. 2019, 11, 5
46.Li, Y.; Zhang, Y.; Huang, X.; Ma, J. Learning Source-Invariant Deep Hashing Convolutional Neural Networks for Cross-Source Remote Sensing Image Retrieval. IEEE Transactions on Geoscience and Remote Sensing 2018, 56, 6521–6536.
47.Roy, S.; Sangineto, E.; Demir, B.; Sebe, N. Deep Metric and Hash-Code Learning for Content-Based Retrieval of Remote Sensing Images. IGARSS 2018 - 2018 IEEE International Geoscience and Remote Sensing Symposium 2018, pp. 4539–4542.
48.Li, Y.; Zhang, Y.; Huang, X.; Zhu, H.; Ma, J. Large-Scale Remote Sensing Image Retrieval by Deep Hashing Neural Networks. IEEE Transactions on Geoscience and Remote Sensing 2018, 56, 950–965.
49.Abdi, H.; Williams, L.J. Principal component analysis. Wiley interdisciplinary reviews: computational statistics 2010, 2, 433–459.
50.Jegou, H.; Perronnin, F.; Douze, M.; Sánchez, J.; Perez, P.; Schmid, C. Aggregating local image descriptors into compact codes. IEEE transactions on pattern analysis and machine intelligence 2012, 34, 1704–1716.
51.He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
52.Dugas, C.; Bengio, Y.; Bélisle, F.; Nadeau, C.; Garcia, R. Incorporating second-order functional knowledge for better option pricing. Advances in neural information processing systems, 2001, pp. 472–478.
53.Tolias, G.; Avrithis, Y.; Jégou, H. To aggregate or not to aggregate: Selective match kernels for image search. Proceedings of the IEEE International Conference on Computer Vision, 2013, pp. 1401–1408.
54.Rao, C.R.; Mitra, S.K.; others. Generalized inverse of a matrix and its applications. Proceedings of the Sixth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Theory of Statistics. The Regents of the University of California, 1972.
55.Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. Proceedings of the 18th SIGSPATIAL international conference on advances in geographic information systems. ACM, 2010, pp. 270–279.
56.Tang, X.; Jiao, L.; Emery, W.J.; Liu, F.; Zhang, D. Two-stage reranking for remote sensing image retrieval. IEEE Transactions on Geoscience and Remote Sensing 2017, 55, 5798–5817.
57.Zhao, B.; Zhong, Y.; Xia, G.S.; Zhang, L. Dirichlet-derived multiple topic scene classification model for high spatial resolution remote sensing imagery. IEEE Transactions on Geoscience and Remote Sensing 2016, 54, 2108–2123.
58.Zhao, B.; Zhong, Y.; Zhang, L.; Huang, B. The Fisher kernel coding framework for high spatial resolution scene classification. Remote Sensing 2016, 8, 157.
59.Zhu, Q.; Zhong, Y.; Zhao, B.; Xia, G.S.; Zhang, L. Bag-of-visual-words scene classifier with local and global features for high spatial resolution remote sensing imagery. IEEE Geoscience and Remote Sensing Letters 2016, 13, 747–751.
60.Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: benchmark and state of the art. Proceedings of the IEEE 2017, 105, 1865–1883.
61.Cheng, G.; Li, Z.; Yao, X.; Guo, L.; Wei, Z. Remote Sensing Image Scene Classification Using Bag of Convolutional Features. IEEE Geoscience and Remote Sensing Letters 2017, 14, 1735–1739.
62.Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When deep learning meets metric learning: remote sensing image scene classification via learning discriminative CNNs. IEEE transactions on geoscience and remote sensing 2018, 56, 2811–2821.
63.Tang, X.; Jiao, L.; Emery, W.J. SAR image content retrieval based on fuzzy similarity and relevance feedback. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 2017, 10, 1824–1842.

