
- 1NLP入门——基础知识_nlp学习
- 2一个基于SpringBoot+Vue前后端分离医疗用品销售网站系统详细设计实现_网站前后端分离设计
- 3报错[Vue warn]: $listeners is readonly. $attrs is readonly.怎么解决?
- 4数字化时代,如何赋能人才
- 5论文阅读:Towards a Unified View of Parameter-Efficient Transfer Learning对参数高效迁移学习的统一看法
- 6第八章:AI大模型的未来发展趋势8.1 模型结构的创新8.1.2 模型可解释性研究
- 7ChatGPT 插件(ChatGPT plugins)_chatgpt插件
- 8关于Yolov7-tiny模型瘦身(param、FLOPs)碎碎念_yolov7tiny
- 902_在VM虚拟机创建Win7系统
- 10chatGPT优化论文会导致论文重复率升高,实测段落重复率从23.2%狂飙到70.7%_chatgpt查重率多少
红黑树、b+树、b树、mysql索引详细剖析_mysql 二叉树 红黑树 b树 b+树
赞
踩
树基础知识回顾
排序二叉树:左 < 根< 右
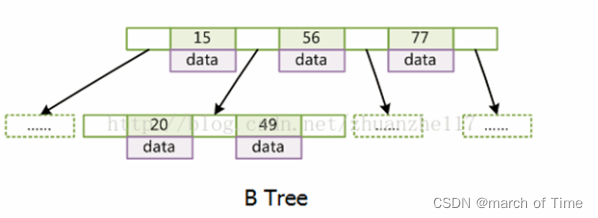
B 树:有序数组 + 多叉平衡树,节点存储关键字、数据、指针;
B+ 树:有序数组链表 + 多叉平衡树,非叶子节点存储指针、关键字,不存储数据;
红黑树:红黑树是一种不大严格的平衡树(平衡树要求太高)
红黑树
红黑树:
红黑树(一棵自平衡的排序二叉树)五大特性:
1)每个结点要么是红的,要么是黑的。
2)根结点是黑的。
3)每个叶结点,即空结点是黑的。
4)如果一个结点是红的,那么它的俩个儿子都是黑的。
5)对每个结点,从该结点到其子孙结点的所有路径上包含相同数目的黑结点。
场景
1)广泛用于C++的STL中,map和set都是用红黑树实现的.
2)著名的linux进程调度Completely Fair Scheduler,用红黑树管理进程控制块,进程的虚拟内存
区域都存储在一颗红黑树上,每个虚拟地址区域都对应红黑树的一个节点,左指针指向相邻的地址
虚拟存储区域,右指针指向相邻的高地址虚拟地址空间.
3)IO多路复用epoll的实现采用红黑树组织管理sockfd,以支持快速的增删改查.
4)ngnix中,用红黑树管理timer,因为红黑树是有序的,可以很快的得到距离当前最小的定时器.
5)java中的TreeSet,TreeMap
左旋和右旋可以参考:红黑树旋转过程
拉链法导致的链表过深问题为什么不用二叉查找树代替,而选择红黑树?为什么不一直使用红黑树?
之所以选择红黑树是为了解决二叉查找树的缺陷,二叉查找树在特殊情况下会变成一条线性结构(这就跟原来使用链表结构一样了,造成很深的问题),遍历查找会非常慢。
而红黑树在插入新数据后可能需要通过左旋,右旋、变色这些操作来保持平衡,引入红黑树就是为了查找数据快,解决链表查询深度的问题,我们知道红黑树属于平衡二叉树,但是为了保持 平衡 是需要付出代价的,但是该代价所损耗的资源要比遍历线性链表要少,所以当长度大于 8 的时候,会使用红黑树,如果链表长度很短的话,根本不需要引入红黑树,引入反而会慢。
平衡树是为了防止二叉查找树退化为链表,而红黑树在维持平衡以确保 O(log2(n)) 的同时,不需要频繁着调整树的结构;
当我们进行插入或者删除操作时所作的一切操作都是为了调整树使之符合这五条性质。
下面我们先介绍两个基本操作,旋转。
旋转的目的是将节点多的一支出让节点给另一个节点少的一支,旋转操作在插入和删除操作中经常会用到
b树、b+树
B 树即:多路平衡查找树;
B 树的巧妙之处在于:
- 将一个节点的大小设置为一页的大小;
- 一个节点可以存放多个关键字(多叉树);
- 自平衡;
这 3 点结合起来就可以做到:
- 一个节点大小为一页,被加载进内存时,这些关键字在进行对比,找出需要 leftChild 还是 rightChild 时,都是有用的(如最右侧时需要对比所有节点);
- 一个节点可以存储多个关键字,有效降低了树的高度;
B+ 树的巧妙之处在于:
- 非叶子节点不存储数据,进一步增大了一页中存储关键字的数量;
- 叶子节点中存储数据且存在指向下一页的链表指针,可以使用顺序查询(支持范围查询);
b+树比b树的优点:
1.顺序查找 范围查找 排序查找能力强
2.IO的效率更高,因为非叶结点不存储数据
3.基于索引树的全量数据扫描能力更高
为什么不能使用二叉树来存储数据库索引
先说结论:
- 平衡二叉树进行插入/删除时,大概率需要通过左旋/右旋来维持平衡;
- 旋转需要加载整个树,频繁旋转效率低;
- 二叉树的 I/O 次数近似为 O(log2(n));
- 范围查询时,二叉树的时间复杂度会退化成 O(n);
- 二叉树退化成链表时,时间复杂度也近似退化成了 O(n);
- 二叉树无法使用磁盘预读功能;
其实单论范围查询,在关系型数据库中就基本没有使用二叉树的可能了。但是为了加深对知识的了解,来看看其他的原因。
先剔除掉范围查询的情况,原因 1、2、6 可以通过红黑树来解决,那么其实就剩下 2 个原因:
- I/O 次数对比;
- 磁盘预读功能的利用;
B/B+树的索引数量
B 树的节点中存储:指针、关键字(主键)、数据
B+ 树的非叶子节点:指针、关键字
B+树的叶子节点:指针(链表)、关键字、数据
注意,这里不是绝对的,比如有的 B+ 树中叶子节点存储的不是数据,而是指向数据的指针。查询到指针之后再去对应地址取出数据,但是这样应该会增加一次 I/O 吧,应该也是在数据量和 I/O 次数之间做了取舍,具体先不讨论。
以 Sqlite3.12 之后为例,page_size = 16k,假设指针为 8 byte,假设关键字类型占 8 byte,假设数据占 1 KB;
B 树的一个节点:
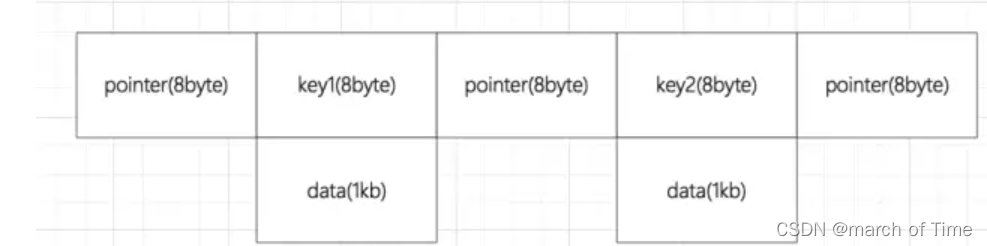
一页能存储的数据量为:16kb / (1KB+8byte+8byte) ≈ 16;
高度为 3 的 B 树能存储 16 x16 x16 = 4096 条数据
相比于二叉树的 1 个而言,确实有效降低了树的层级。而且上述是假设数据为 1KB,如果数据没那么大,高度为 3 的 B 树能存储更多的数据,但是如果用在大型数据库索引上还是不够。
B+树的核心在于非叶子节点不存储数据。
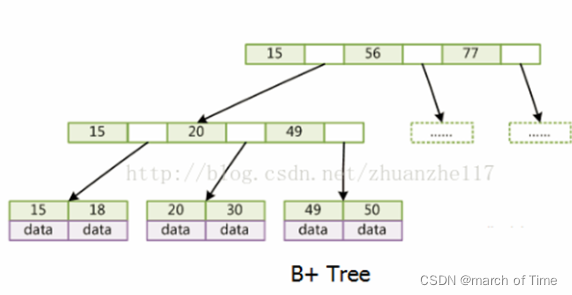
这样做可以减少非叶子结点占用的空间,增大一页所能存储的数据量,最大程度减少树的层级。
仍然是以上假设,假如树的高度为 3 ,那么就有两层存储关键字+指针,一层叶子节点来存储实际数据。
一页能存储的关键字为:16 * 1024 / (8 + 8) = 1024
一页能存储的数据量为:16KB / (1KB + 8byte + 8byte) = 16
(这里计算不完全准确,实际情况应该是1页数据中只有一个链表指针指向下一页)
能存储的关键字为:1024 * 1024 = 1048576;
因为端节点又有 1024 个指针,这些指针可以指向一个页,页中存储数据,也就是叶子节点,一页能存储 16 个叶子节点,所以总共能索引的数据量为 1048576 * 16 ≈ 1600万;如果高度为 4 ,则再乘以 1024 约为 17亿……
注意:b+树上有两个头指针,一个指向根节点,一个指向关键字最小的叶子结点,而且所有叶子结点之间是一种链式环结构,因此可以用b+树进行两种查找运算:一种是对于主键的范围查找和分类查找,一种是从根节点开始进行随机查找。
上述推理中,理解终端节点的指针指向一个页,页中存储着关键字 + 数据 + 链表指针是关键。
索引
索引是关系型数据库为了加速对表中行数据检索的(磁盘存储的)数据结构
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往是存储在磁盘上的文件中的(可能存储在单独的索引文件中,也可能和数据一起存储在数据文件中)。
我们通常所说的索引,包括聚集索引、覆盖索引、组合索引、前缀索引、唯一索引等,没有特别说明,默认都是使用B+树结构组织(多路搜索树,并不一定是二叉的)的索引。
索引的基本原理
索引用来快速地寻找那些具有特定值的记录。如果没有索引,一般来说执行查询时遍历整张表。
索引的原理:就是把无序的数据变成有序的查询
- 把创建了索引的列的内容进行排序
- 对排序结果生成倒排表
- 在倒排表内容上拼上数据地址链
- 在查询的时候,先拿到倒排表内容,再取出数据地址链,从而拿到具体数据
索引的常用数据结构?
索引的数据结构和具体存储引擎的实现有关, 在MySQL中使用较多的索引有Hash索引,B+树索引等,而我们经常使用的InnoDB存储引擎的默认索引实现为:B+树索引
什么是聚簇(集)索引?
innodb存储引擎在进行数据插入的时候数据必须要跟某一个索引列存储在一起,这个索引列可以是主键,如果没有主键则选择唯一键,如果没有唯一键选择6字节的rowid来进行存储。
innodb中有聚簇索引也有非聚簇索引,myisam只有非聚簇索引
非聚簇索引的叶子结点存储的数据不再是整行的记录而是聚簇索引的id值
表数据文件本身就是按b+树组织的一个索引结构文件
聚集索引-指叶结点包含了完整的数据记录
在B+树的索引中,叶子节点可能存储了当前的key值**,也可能存储了当前的key值以及整行的数据,这就是聚簇索引和非聚簇索引.** 在InnoDB中,只有主键索引是聚簇索引,如果没有主键,则挑选一个唯一键建立聚簇索引.如果没有唯一键,则隐式的生成一个键来建立聚簇索引.当查询使用聚簇索引时,在对应的叶子节点,可以获取到整行数据,因此不用再次进行回表查询.
对于InnoDB表而言,MySQL的非聚簇索引统称为“辅助索引”(secondary index),辅助索引的“表记录指针”称为“书签”(bookmark),实际上是主键值,如图3-32所示,可以看到,所有的辅助索引都包含主键列,所有的InnoDB表都是通过主键来聚簇的。
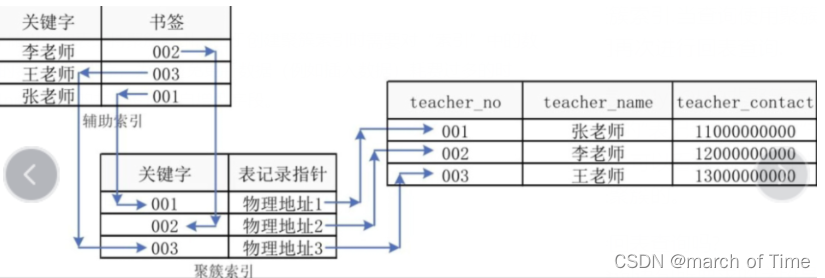
●非聚簇索引一定会回表查询吗?
不一定,这涉及到查询语句所要求的字段是否全部命中了索引,如果全部命中了索引,那么就不必再进行回表查询.
举个简单的例子,假设我们在员工表的年龄上建立了索引,那么当进行select age from employee where age < 20的查询时,在索引的叶子节点上,已经包含了age信息,不会再次进行回表查询.
● InnoDB存储引擎的表支持聚簇索引。由于创建聚簇索引时需要对“索引”中的数据以及表中的数据进行排序,为了避免更新数据(例如插入数据)耗费过多的时间,建议将InnoDB表的主键设置为自增型字段。
为什么非主键索引叶子节点存储的是主键值: 一致性和节省存储空间
mysql聚簇和非聚簇索引的区别
都是B+树的数据结构
聚簇索引:将数据存储与索引放到了一块、并且是按照一定的顺序组织的,找到索引也就找到了数据,数据的物理存放顺序与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是相邻地存放在磁盘上的
非聚簇索引:叶子节点不存储数据、存储的是数据行地址,也就是说根据索引查找到数据行的位置再取磁盘查找数据,这个就有点类似一本树的目录,比如我们要找第三章第一节,那我们先在这个目录里面找,找到对应的页码后再去对应的页码看文章。
优势:
1、查询通过聚簇索引可以直接获取数据,相比非聚簇索引需要第二次查询(非覆盖索引的情况下)效率要高
2、聚簇索引对于范围查询的效率很高,因为其数据是按照大小排列的
3、聚簇索引适合用在排序的场合,非聚簇索引不适合
劣势:
1、维护索引很昂贵,特别是插入新行或者主键被更新导至要分页(page split)的时候。建议在大量插入新行后,选在负载较低的时间段,通过OPTIMIZE TABLE优化表,因为必须被移动的行数据可能造成碎片。使用独享表空间可以弱化碎片
2、表因为使用UUId(随机ID)作为主键,使数据存储稀疏,这就会出现聚簇索引有可能有比全表扫面更慢,所以建议使用int的auto_increment作为主键
3、如果主键比较大的话,那辅助索引将会变的更大,因为辅助索引的叶子存储的是主键值;过长的主键值,会导致非叶子节点占用占用更多的物理空间
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

