
- 1arcgis抽取日期字段里内容_ArcGIS Help 10.2 - 日期字段的基础知识
- 27-6 实验3.6 输出1000到10000以内的所有的素数_编写程序,输出1000到10000以内的所有的素数,且每行输出5个数。输入格式:无输
- 3vue同一浏览器登录不同账号,覆盖token的解决办法_前端单点登录进入一个页面时如果这个页面之前有别的号的token怎么办
- 4xcode安装simulator失败解决方法_xcode 下载ios15 simulator失败
- 52017年终总结,一个不顺心的槛年_第二行代码出版时间
- 6【论文笔记】Attention总结二:Attention本质思想 + Hard/Soft/Global/Local形式Attention_location-based attention
- 7简单调用摄像头进行人脸识别_虚拟摄像头人脸识别教程
- 8如何监控EMC VNX控制器的启动过程_vnx 串口线
- 9灵境矩阵平台x百度---智能体(一)
- 10Logback 日志异步输出数据库(Oracle)_logback oracle
transformer高效训练方法一览
赞
踩
本文翻译整理自 A Survey on Efficient Training of Transformers
来自:无数据不只能
进NLP群—>加入NLP交流群
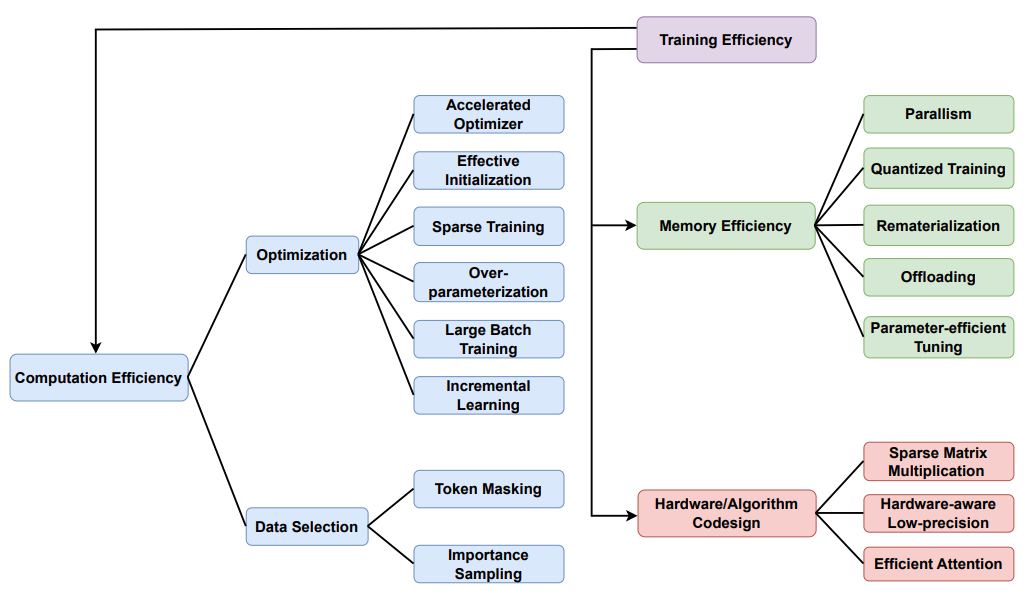
在本文中,将探讨了transformer高效训练方法,从存储效率、硬件算法协同设计和计算效率三个角度进行了阐述。
在计算效率方面,介绍加速优化器、初始化、稀疏训练、过参数化、大批次训练和增量训练等优化策略,以及token掩码和重要性抽样等数据选择方法。
在内存效率方面,介绍并行化、量化训练、再物化、卸载和参数效率微调等策略。
在硬件算法协同设计方面,介绍稀疏矩阵乘法、低精度硬件感知和高效注意力等方法。
计算效率
优化
加速优化器
AdamW是Adam的一个变体,其解耦了正则化2和权重衰减,是transformer中最常用的优化器之一。
Lion只使用一阶梯度跟踪动量,更新只考虑符号方向,对每个参数具有相同的量级,与AdamW等自适应优化器有很大不同。在实践中,Lion一般收敛更快,在各种基准上训练transformer时,Lion的内存效率和准确性都比AdamW更高。
初始化
好的初始化对于稳定训练、加速收敛、提高学习率和泛化能力很重要。
Fixup重新缩放标准初始化以确保梯度范数适当,避免梯度爆炸或消失,从而可在不添加归一化层的情况下使用非常深的网络进行训练。
ReZero和SkipInit只是将每个层初始化为执行恒等操作,其基础是归一化残差块计算出的函数接近于恒等函数。它们在每个残差块的输出上添加一个可学习的缩放乘法器。T-Fixup分析表明,Adam优化器中二阶动量的方差无界,导致部分优化难度。因此,T-Fixup采用一种类似于Fixup对残差块的初始化的缩放方案。以上所有方法都从所有块中删除批/层归一化,并在没有学习率warm up的情况下进行训练。
在训练深度视觉transformer(ViT)时,提出了通道级可学习的缩放因子,并根据经验观察到重新引入预热和层归一化技术可以使训练更加稳定。
稀疏训练
稀疏训练的关键思想是在不牺牲精度的情况下,直接训练稀疏子网络而不是全网络。可靠性首先由彩票假说(LTH)证明,一个密集的、随机初始化的网络包含子网络,这些子网络可以单独训练,以匹配原始网络的精度。然而,LTH需要以交替训练-剪枝-再训练的方式识别中奖彩票,这使得大型模型和数据集的训练成本极其昂贵,限制了实际效益。鉴于此,具有更高训练效率的后续工作可以大致分为三类:
(i) 通过测量连接对损失的重要性,在初始化时一次性找到稀疏网络,消除了对复杂迭代优化调节的需要;(ii) 通过低成本方案在非常早期的训练阶段识别transformer中的中奖彩票,然后仅仅训练这些早期彩票,直到收敛;(iii) 在整个训练过程中使用交替修剪和增长计划来动态更新模型稀疏模式,适用于通用架构。
过参数化
实用的DNN是过于参数化的,其可学习的参数数量远远大于训练样本的数量。过参数化可以在一定程度上提高收敛性和泛化性,虽然不充分,但有理论支持。早期的研究证明在线性神经网络中通过过参数化增加深度可以加速SGD的收敛。进一步探索了两层非线性神经网络,证明了SGD可以在多项式时间内收敛到DNNs的训练目标上的全局最小值,假设训练样本不重复,并且参数数量是多项式级别的。在泛化方面,理论证明了充分过参数化的神经网络可以泛化到种群风险,一个有趣的特性是,在SGD训练轨迹上任意点的近邻域内存在一个精确的网络,具有高概率的随机初始化。需要注意的是,与LTH有很深的关联,因为它部分解释了为什么LTH在稀疏训练中表现良好,因为过度参数化会产生许多低风险的好子网络。在transformer中应用这一理论,可以获得更快的收敛速度和更好的性能。
大批次训练
另一种加速训练的流行方法是使用大批量,减少每个epoch的迭代次数,提高计算资源利用率。从统计学的角度来看,大批量训练降低了随机梯度估计的方差,因此需要调整可靠的步长以获得更好的收敛。在卷积神经网络时代,利用学习率的线性缩放,在ImageNet上以8192的批次大小在1小时内训练ResNet-50。随后提出了更先进的步长估计方法。广泛使用的方法是SGD的LARS和Adam的LAMB,它们建议分别对ResNet和Transformers使用分层自适应学习率。
它配备了一个归一化项,对梯度爆炸和平台提供鲁棒性,缩放项确保更新的参数与参数的范数相同阶次,促进更快的收敛。最近,根据经验,针对大批量训练定制的更强大的优化方法表现良好。例如,表明,将一定数量的最新检查点的权重进行平均,可以促进更快的训练。DeepMind在中训练了400多个具有不同规模的模型大小和训练token的Transformer语言模型,达到了一个实用的假设,即模型大小和训练token的数量应该被均匀缩放以进行计算最优的LLM训练。
增量训练
增量学习的高级概念是将原来具有挑战性的优化问题放松为一系列易于优化的子问题,其中一个子问题的解可以作为后续子问题的良好初始化,以规避训练难度,类似于退火。一些工作提出通过逐步堆叠层来加速BERT预训练,从一个较小的模型适当地初始化一个较大的模型。以相反的方向通过层丢弃来训练具有随机深度的transformer,其中它沿着时间维度和深度维度逐步增加丢弃率。为ViT定制,AutoProg建议在使用神经架构搜索的渐进式学习过程中自动决定模型是否增长、在哪里增长以及应该增长多少。一个关键的观察结果是,逐步增加输入图像的分辨率(减少patch大小)可以显著加快ViT训练,这与众所周知的训练动态一致,即在早期集中于低频结构,在后期集中于高频语义。
数据选择
除了模型效率,数据效率也是高效训练的关键因素。
token掩码
Toke n m asking 是自监督预训练任务中的一种主要方法,例如掩码语言建模和掩码图像建模。标记掩码的精神是随机掩码一些输入标记,并训练模型用可见标记中的上下文信息来预测缺失的内容,例如词汇表ID或像素。由于压缩序列长度以二次方式降低了计算和存储复杂度,跳过处理掩码token为MLM和MIM带来了可观的训练效率增益。对于MLM,提出联合预训练语言生成任务的编码器和解码器,同时删除解码器中的掩码标记,以节省内存和计算成本。对于MIM,代表性工作表明,在视觉中,在编码器之前移除掩码图像块显示出更强的性能,并且比保留掩码token的整体预训练时间和内存消耗低3倍或更多。在中也发现了类似的现象,对于语言-图像预训练,随机掩码并去除掩码图像块显示了比原始剪辑快3.7倍的整体预训练时间。
重要性抽样
在数据上采样的重要性,也称为数据剪枝,理论上可以通过优先考虑信息量大的训练样本来加速监督学习的随机梯度算法,主要受益于方差缩减。对于DNNs来说,估计每个样本重要性的一种主要方法是使用梯度范数,并且使用不同的近似使计算这些规范变得容易进一步加快类似于early-bird LTH的采样过程,但在数据域,在几个权重初始化上的简单平均梯度范数或误差2范数可以用于在训练的非常早期阶段识别重要的示例。最近,展示了一个令人兴奋的分析理论,即测试误差与数据集大小的缩放可以突破幂次缩放定律,如果配备了优越的数据修剪度量,则可以减少到至少指数缩放,并且它采用了使用k-means聚类的自监督度量。它展示了一个有希望的方向,即基于数据重要性采样的更有效的神经缩放定律。
内存效率
除了计算负担之外,大型Transformer模型不断增长的模型大小,例如从BERT 345M参数模型到1.75万亿参数的GPT-3,是训练的一个关键瓶颈,因为它们不适合单个设备的内存。我们首先分析了现有模型训练框架的内存消耗,这些内存消耗由模型状态,包括优化器状态、梯度和参数;以及激活。我们在表1中总结了内存有效的训练方法。在下文中,我们将讨论优化内存使用的主要解决方案。
并行化
跨设备并行训练大型DNN是满足内存需求的常见做法。基本上有两种范式:数据并行(DP),它在不同的设备上分配一个小批量的数据,模型并行(MP),它在多个worker上分配一个模型的子图。对于DP来说,随着可用worker的增加,批处理大小接近线性缩放。第2节中讨论的大批量培训就是针对这种情况开发的。然而,很明显,DP具有较高的通信/计算效率,但内存效率较差。当模型变得很大时,单个设备无法存储模型副本,并且针对梯度的同步通信会阻碍DP的可扩展性。因此,DP本身只适合训练小到中等规模的模型。为了提高DP的可扩展性,Transformer的一种解决方案是参数共享 ,即Albert,但它限制了表征能力。最近,ZeRO将均匀划分策略与DP结合在一起,其中每个数据并行过程仅处理模型状态的一个划分,在混合精度制度下工作。为了处理非常大的DNN,人们总是需要利用模型并行性,以“垂直”的方式在多个加速器上分配不同的层。虽然MP具有良好的存储效率,但由于跨设备的大量数据传输和较差的PE利用率,其通信和计算效率较低。幸运的是,在an中有两种策略可以进一步提高MP的效率
正交的“水平”维度,包括张量并行(TP)和流水线并行(PP)。TP跨worker将张量操作划分在一个层中,以实现更快的计算和更多的内存节省。根据基于transformer的模型定制,Megatron-LM跨GPU对MSA和FFN进行切片,并且在前向和后向传递中只需要一些额外的All-Reduce操作,使他们能够使用512个GPU训练模型多达83亿个参数。在PP方面,它最初是在GPipe中提出的,它将输入的mini-batch分割为多个较小的micro-batch,使不同的加速器(在加速器上划分顺序层)同时在不同的micro-batch上工作,然后对整个mini-batch应用单一的同步梯度更新。然而,它仍然受到管道气泡(加速器空闲时间)的影响,这会降低效率。特别是,PyTorch实现了torchgpipe,它使用检查点执行微批次PP,允许扩展到大量的微批次,以最小化气泡开销。请注意,DP和MP是正交的,因此可以同时使用两者来训练具有更高计算和内存容量的更大模型。例如,Megatron-LM和DeepSpeed组成了张量、管道和数据并行,以将训练扩展到数千个GPU。
量化训练
训练神经网络的标准程序采用全精度(即FP32)。相比之下,量化训练通过将激活值/权重/梯度压缩为低比特值(例如FP16或INT8),以降低的精度从头开始训练神经网络。在之前的工作中已经表明,降低精度的训练可以加速神经网络的训练,并具有良好的性能。对于Transformer来说,采用最广泛的方法是自动混合精度(AMP)训练。具体来说,AMP以全精度存储权重的主副本用于更新,而激活值、梯度和权重则存储在FP16中用于算术。与全精度训练相比,AMP能够实现更快的训练/推理速度,并减少网络训练期间的内存消耗。例如,基于64的批量大小和224×224的图像分辨率,在AMP下的RTX3090上训练DeiT-B比全精度训练快2倍(305张图像vs124张图像/s),同时消耗22%的峰值GPU内存(7.9GBvs10.2GB)。虽然人们普遍认为,至少需要16位才能训练网络而不影响模型精度,但最近在NVIDIA H100上对FP8训练的支持在Transformer训练上显示出了可喜的结果,在FP8下训练DeiT-S和GPT可以与16位训练相媲美。除了同时量化激活/权重/梯度的精度降低训练外,激活压缩训练(ACT)在精确计算前向传递的同时存储低精度的激活近似副本,这有助于减少训练期间的整体内存消耗。然后将保存的激活解量化为向后传递中的原始精度,以计算梯度。最近的工作进一步建议自定义ACT以支持内存高效的Transformer训练。
再物化和卸载
再物化 (R e materialization),也被称为检查点,是一种广泛使用的时空权衡技术。在正向传递时只存储一部分激活/权重,在反向传递时重新计算其余部分。提供了一个在PyTorch3中实现的简单的周期性调度,但它仅适用于同构的顺序网络。更先进的方法,如实现了异构网络4的最优检查点。在卸载方面,它是一种利用CPU内存等外部内存作为GPU内存的扩展,通过GPU和CPU之间的通信,在训练过程中增加内存容量的技术。模型状态和激活,都可以卸载到CPU,但最优选择需要最小化通信成本(即数据移动)到GPU,减少CPU计算和最大化GPU内存节省。一个代表性的工作是ZERO-Offload,它提供了使用Adam优化器定制的混合精度训练的最优卸载策略。它在CPU内存上卸载所有fp32模型状态和fp16梯度,并在CPU上计算fp32参数更新。fp16参数保存在GPU上,前向和后向计算在GPU上。为了两全兼顾,建议联合优化激活卸载和再物化。
参数效率微调
以 HuggingFace 为代表的公共模型动物园包含丰富的预训练模型,可以随时下载和执行,正在为降低训练成本做出显著贡献。对这些现成的模型进行有效调优,正成为一种大幅削减训练成本的流行方式。作为香草全微调的强大替代方案,
参数高效调优(PET)在冻结预训练模型的同时只更新少量额外参数,以显着减少存储负担。它可以随动态部署场景扩展,而不需要为每种情况存储单独的模型实例。一般的PET方法可以分为基于添加的方法和基于重新参数化的方法。前者将额外的可训练参数附加到预训练模型上,并且只调整这些参数。例如,在输入空间中添加可训练参数,在MSA和FFN之后在每个Transformer块中添加两次适配器模块。然而,额外的参数会在推理过程中引入额外的计算和内存开销。为了应对这一挑战,后者建议调整模型中固有的参数或可以重新参数化到模中的新参数,从而不会对推理效率产生牺牲。受观察到大型语言预训练模型具有较低的内在维度的启发,代表性工作LoRA将自注意力权重的更新近似为两个低秩矩阵,可以在推理过程中将其合并到预训练权重中。值得注意的是,在实现LLM民主化方面最受认可的工作之一是Stanford Alpaca,它使用从Chat GPT生成的52K指令遵循数据从开源的LLaMA模型中进行微调。为了廉价有效地对其进行微调,其变体Alpaca-LoRA5进一步采用低秩LoRA来实现在客户硬件上对羊驼进行指令微调,表明可以在单个RTX 4090上在数小时内完成训练。
开源框架
有几个被广泛采用的原型用于大规模训练大型Transformer模型,其中微软DeepSpeed、HPC-AI Tech ColossalAI和Nvidia Megatron是先驱。具体来说,DeepSpeed主要基于和ZERO系列作品实现,Colossal-AI基于构建,Megatron-LM实现。所有这些都支持混合精度的数据和模型并行,以及其他通用实践,如卸载和再物化。更多用于高效分布式训练的库包括但不限于HuggingFace Transformers,MosaicML Composer,百度PaddlePaddle,Bytedance Lightspeed,EleutherAI GPT-NeoX等。
硬件算法协同设计
除了计算和内存负担,设计高效的硬件加速器可以使DNNs更快地训练和推理。具体来说,与中央处理单元(CPU)相比,图形处理单元(GPU)由于高度并行性,在执行矩阵乘法时更加强大。对于专注于特定计算任务的应用,专用集成电路(ASIC)具有低功耗、高训练/推理速度的优势。例如,谷歌设计的张量处理单元(TPU)比当代CPU和GPU提供了30~80倍的性能/瓦特。然而,ASIC不容易重新编程或适应新任务。相比之下,现场可编程门阵列(FPGA)被设计成可以根据需要重新编程以执行不同的功能,在最终确定设计之前也可以作为ASIC的原型。为了进一步优化DNNs特别是Transformer的训练效率,硬件-算法协同设计在设计算法时考虑了硬件的约束和能力,这将在以下小节中介绍。
稀疏矩阵乘法
为了降低 Transformer 的计算开销,涉及将稀疏矩阵与稠密矩阵相乘的稀疏通用矩阵乘法(SpGEMM),利用注意力矩阵的稀疏性来减少计算次数。目前有几个流行的稀疏矩阵计算库,如Intel Math Kernel library CPU和cuSPARSE15、CUSP16和24 GPU上的结构化稀疏性。然而,由于不规则的稀疏性,SpGEMM往往对CPU、GPU等通用处理器的硬件不友好。为了解决这个问题,需要专门的硬件加速器,如FPGA和ASIC,来处理糟糕的数据局部性问题。例如,OuterSPACE 将矩阵乘法转换为外积过程,并通过将乘法与累加解耦来消除冗余内存访问。为了在不引入显著开销的情况下充分利用这一减少,OuterSPACE构建了一个具有可重构存储层次的自定义加速器,相对于运行英特尔数学内核库的CPU实现了7.9倍的平均加速,相对于运行CUSP的GPU实现了14.0倍的平均加速。此外,为了缓解高稀疏性造成的数据移动瓶颈,ViTCoD使用可学习的自编码器将稀疏注意力压缩为更紧凑的表示,并设计编码器和解码器引擎以提高硬件利用率。
低精度硬件感知
降低计算精度会减少内存和计算量,这可以用硬件友好的定点或整数表示来实现,而不是浮点表示。因此,我们可以使用精度较低的乘法器、加法器和内存块,从而在功耗和加速比方面得到显著改善。此外,低精度的算法可以与其他技术相结合,如剪枝和低秩近似,以实现进一步的加速。例如,Sanger使用4位查询和键来计算稀疏注意力矩阵的量化预测。然后,稀疏注意力掩码被重新排列成结构化的块,并由可重构硬件处理。以下工作DOTA使用低秩变换和低精度计算识别注意力中的不重要连接。通过结合token级并行和乱序执行,DOTA实现了GPU上152.6倍的加速。
高效注意力
除了稀疏的矩阵乘法和低精度的计算,几项开创性的工作都专注于在硬件上实现高效和轻量级的注意力。具体来说,一个3只选择那些可能与给定查询具有高相似性的键,以减少注意力的计算量。ELSA根据哈希相似度过滤掉与特定查询无关的键,以节省计算量。借助高效的硬件加速器,ELSA实现了58.1倍的加速,与配备16GB内存的Nvidia V100 GPU相比,在能效方面有三个数量级的提升。值得注意的是,Flash Attention提出利用tiling来减少GPU高带宽内存(HBM)和片上SRAM之间的I/O通信,这正在成为一个默认的快速和内存高效的注意力模块来加速。
进NLP群—>加入NLP交流群

