
- 1kali菜单中各工具功能
- 2无线DOS攻击的常用方法
- 3NLP之基本介绍_nlp技术
- 4YoloV5模型的简单使用_yolov5训练好的模型怎么使用
- 5人工智能(网络爬虫)_ai爬虫技术
- 6AlexNet学习笔记_resample2d
- 7ValueError: Cannot load file containing pickled data when allow_pickle=False_使用numpy加载npy文件报错 valueerror: cannot load file cont
- 8SCA(successive convex approximation)学习
- 9bert-create_pretraining_data代码学习_# coding=utf-8 # copyright 2018 the google ai team
- 10Stage模型_import ability from '@ohos.application.ability
MYSQL进阶(索引、百万/千万数据处理)_百万级的索引 结构
赞
踩
涉及到mysql的高级操作–mysql索引
工作中遇到百万、千万级的数据在mysql中可以解决的方式有,索引和分库、分表,这篇文章介绍的是MySQL中的索引的操作。
一、普通索引
普通索引(Normal index)是我们常见的索引形式:可以创建在单列或者多列上:
- 独立索引(Independent Index): 顾名思义,独立索引只能建立在单列上,比较简单的索引类型;
CREATE INDEX index_name ON your_table (column_name);
- 1
index:创建索引的关键字
index_name:索引名字(最好望名生义)
your_table:表名
colunm_name:字段名(要创建上哪个字段上)
- 1
- 2
- 3
- 4
- 复合索引(Composite Index): 复合索引是指包含多个列的索引,即多个字段创建为一个索引的表现形式;
CREATE INDEX index_name ON your_table (column1, column2);
- 1
index:创建索引的关键字
index_name:索引名字(最好望名生义)
your_table:表名
colunm1,colunm2:字段名(复合索引是多个列的独立索引,建立在两个或两个以上的索引)
- 1
- 2
- 3
- 4
- 前缀索引(Prefix Index): 前缀索引是指普通索引中只包含列的一部分值的索引;
CREATE INDEX index_name ON your_table (column_name(10));
- 1
有时候创建索引时候会报错Specified key was too long; max key length is XXXX bytes 意思为:超过索引的最大长度限制,解决方式其实就是前缀索引,给索引设置一个击中长度。
二、全文索引
- 全文索引(Full-Text Index): 全文索引中的一些查询关键字例如:WHERE…MATCH…AGAINST MySQL8.0以下是用不了的;
要创建全文索引还需要满足以下条件:
sql语句
ALTER TABLE table_name ADD FULLTEXT(column_name);
- 1
注意:创建全文索引的时候,创建的最长字段默认是16个,超过16长度会报错
全文索引的搜索和搜索模型
1、自然语言模型(NATURAL LANGUAGE MODE):
自然语言类型:简单来讲就是基于自然语言处理的全文检索模型。他会自动将查询语句分析和匹配。自然语言考虑了单词之间的关系,并且自动分析查询意图(会进行语句拆分)从而达到快速匹配全文内容
2、布尔模型(BOOLEAN MODE):
布尔模型:布尔模型是一种基于布尔逻辑的全文检索模型。他可以使用布尔运算来组合查询条件,运算符包含(AND、OR、NOT、*(转义符));
AND(+):返回同时包含所有查询关键词的数据
OR:返回任意关键词的数据
NOT(-):排除包含指定关键词的文档
布尔类型和自然语言类型的区别在于:布尔类型更容易拓展一些运算,但是自然语言更容易分析使用者的意图
实例:
SELECT * FROM your_table
WHERE MATCH(column_name1, column_name2, column_name3, column_name4) AGAINST('1*' IN BOOLEAN MODE)
- 1
- 2
此查询为:使用布尔模型,在全文中检索以1开头的所有数据(只要这几个字段中开头包含1就会击中返回);
SELECT * FROM your_table
WHERE MATCH(column_name1, column_name2, column_name3, column_name4) AGAINST('+1* +o*' IN BOOLEAN MODE)
- 1
- 2
此sql意思跟上面sql大致一样,相同的是,在全文中检索以1开头的所有数据,不同是的,使用了+,这个符号的意思是同时包含1和字母o的数据
SELECT * FROM your_table
WHERE MATCH(column_name1, column_name2, column_name3, column_name4) AGAINST('+1* -o*' IN BOOLEAN MODE)
- 1
- 2
此sql跟上面的意思大致一样,前面都是一样的,后的 -o 意思是返回没有o开头的数据;
需要注意的是:全文检索中,没有左模糊,只有右模糊(*);
全文索引的一些限制和注意事项
- 默认情况下,只能搜索至少 4 个字符的关键词。可以通过修改 ft_min_word_len 参数来调整最小关键词长度。
- 默认情况下,只会返回包含至少一个关键词的行。可以使用 IN BOOLEAN MODE 来进行布尔全文搜索,以更灵活地控制搜索结果。
谢言:
其实不管是使用索引还是不使用索引,我们遇到大数据量查询,操作的时候第一时间就应该先考虑到用户体验,以及查询效率、服务器承载量。使用最适合我们的才是最好的,在全文检索中,要是使用了模糊,其实会大大提高查询效率的,但是要是遇到没办法的需求,那我们就不得不选择硬上,为了提高用户体验,我们可以在代码或者表上再继续做处理;
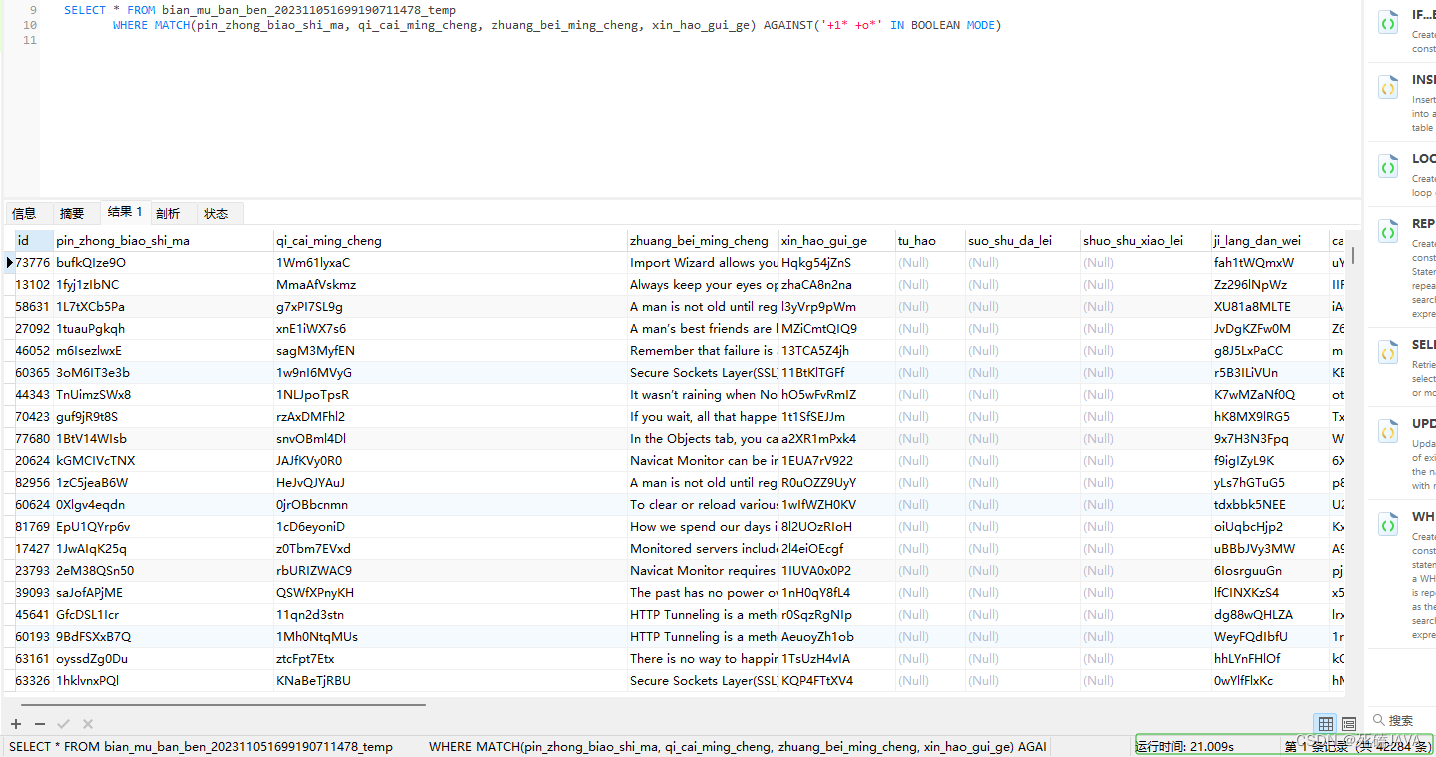
百万级数据,模糊查询没有做别的任何操作查询时间21s其实也就这个上下,但是才百万级就耗费了21秒,肯定会影响用户体验。优化的事就在后面写吧;
最后接受所有人的批评和建议,欢迎来较量;

