
热门标签
热门文章
- 1千言数据集:文本相似度——BERT完成NSP任务_bert nsp
- 2Docker基础操作-使用dockerfile、docker-compose操作镜像和容器(常用命令)_docker发布服务获取镜像名
- 3Python框架下的qt设计之JSON格式化转换小程序
- 4【历史上的今天】11 月 7 日:图灵奖女性得主诞生;Twitter 告别 140 字符时代;首位中国 AI 主播_压卡效应是谁发明的
- 5得物AI平台-KubeAI推理训练引擎设计和实践_ai推理引擎
- 6零基础入门Python数据分析,只需要看懂这一张图,附下载链接!_数据分析python零基础
- 7【论文阅读】RSMamba:基于状态空间模型的遥感图像分类
- 8轻松获取CHATGPT API:免费、无验证、带实例_chatgpt api key免费
- 9Java助农农产品销售平台系统设计与实现(Idea+Springboot+mysql)_基于java web技术农产品销售平台的设计与实现
- 10想打游戏/追剧,又放心不下学习,该怎么办?_想玩游戏学习怎么班
当前位置: article > 正文
Hadoop MapReduce
作者:笔触狂放9 | 2024-04-10 16:43:10
赞
踩
Hadoop MapReduce
MapReduce分为两个阶段,分为Map阶段和Reduce阶段,可以自定义map函数和reduce函数,
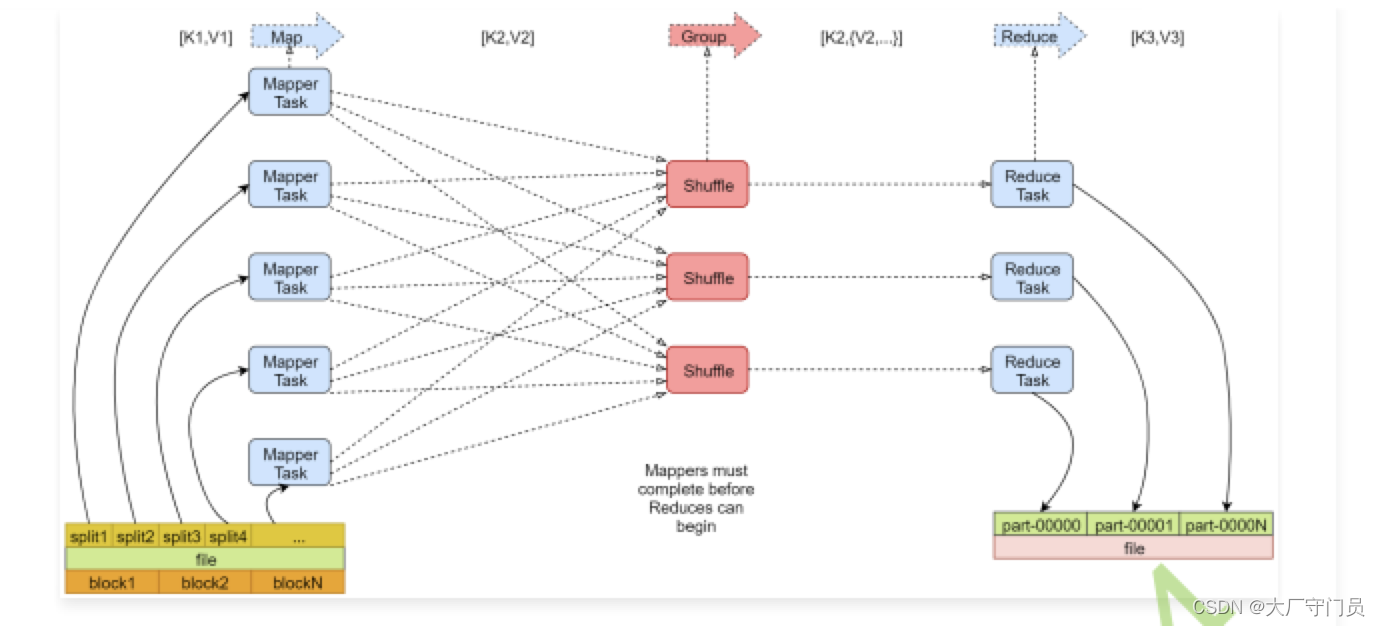
map函数的输入是行在文件的字节偏移量,value是文件的一行数据。
reduce函数的输入是key和对应key的value组,然后reduce函数可以对这一组数据进行处理
再来看mapreduce是如何实现的,因为可以知道reduce阶段的value是一组的,包括mapreduce还发生了文件读取和写入文件的操作,包括一些序列化
当有一个文件时,文件在底层操作系统是很多个数据块,
map是以数据切片逻辑进行处理的,所以当读取文件数据时,会对物理文件进行逻辑切片,然后一个切片就对应一个MapTask,尽量保证切片大小等于数据块大小,让一个MapTask直接本地处理,加快处理速度
Map阶段处理逻辑,map读入文件的每行数据,然后以key-value的方式处理输出到一个分区,输出到哪个分区取决于默认的还是自定义分区处理了,默认是根据键的哈希值确定分区。
分区其实是先保存到一个环形缓存区,当环形缓存区达到一定阈值的时候,就会把缓冲区数据落盘,落盘前会对分区内的数据进行快速排序,如果有多个小文件,会对多个小文件进行归并排序,合成一个大文件,然后分区和reduceTask的数量一样。
reduce阶段,reduce可会读取所有mapTask对应分区的所有文件,如果有多个文件,也会进行归并排序,这样就保证了Reduce函数的输入里的value,是一个相同Key的value集合。然后经过reduceTask函数进行数据处理,最终输出,输出文件数也跟reduceTask的个数相关,reduceTask的数目不能大于分区数目
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/399896?site
推荐阅读
相关标签

