
- 1Multi Query Attention和 Group Query Attention的介绍和原理
- 2python中sort()函数的详细使用方法_python sort
- 3第十三届蓝桥杯省赛JavaB组真题(Java题解解析)_13届蓝桥杯java组
- 4el-table 列的动态显示与隐藏_el-table-column隐藏
- 5vscode中用node的终端安装模块
- 6文心一言插件开发(第二篇_基于文心一言的模块功能进行二次开发 csdn
- 7使用git pull文件时和本地文件冲突时…(Please commit your changes or stash them before you merge.)_git pull 放弃本地修改
- 8AutoGPT使用教程_autogpt怎么用
- 9基于Tensorflow2.0的简单人脸识别实验_用keras, tensorflow2.0以上版本做个人脸识别
- 10Flask -- (16)Flask中的上下文及实现原理_flask request 上下文 原理
音视频开发之旅(69)-SD图生图
赞
踩
目录
1. 效果展示
2. ControlNet介绍
3. 图生图流程浅析
4. SDWebui图生图代码流程
5. 参考资料
一、效果展示
图生图的应用场景非常多,比较典型的应用场景有风格转化(真人与二次元)、线稿上色、换装和对图片进行扩图等,下面我们看下几个场景的效果
原图是用上一篇文生图文章中生成的图片
1.1 应用场景1:修改背景

highres,beach seaside,
Controlnet canny +depth
1.2 应用场景2:风格变化 -- 写实转卡通

highres,toon (style),
Anything模型
Controlnet canny +depth
1.3 应用场景3:线稿上色

1oldman,highres,Dark eyes,yellow skin,Chinese,
controlnet canny
需要注意重回尺寸以及Controlnet的Preprocess Reslution要和原图一致

1.4 应用场景4:人物姿态一致

A astronaut wearing a spacesuit in space,
Controlnet openpose

除此之外,还有很多其他的应用场景可以值得我们探索尝试,比如艺术二维码、创意字等
二、ControlNet介绍
2.1 工作原理
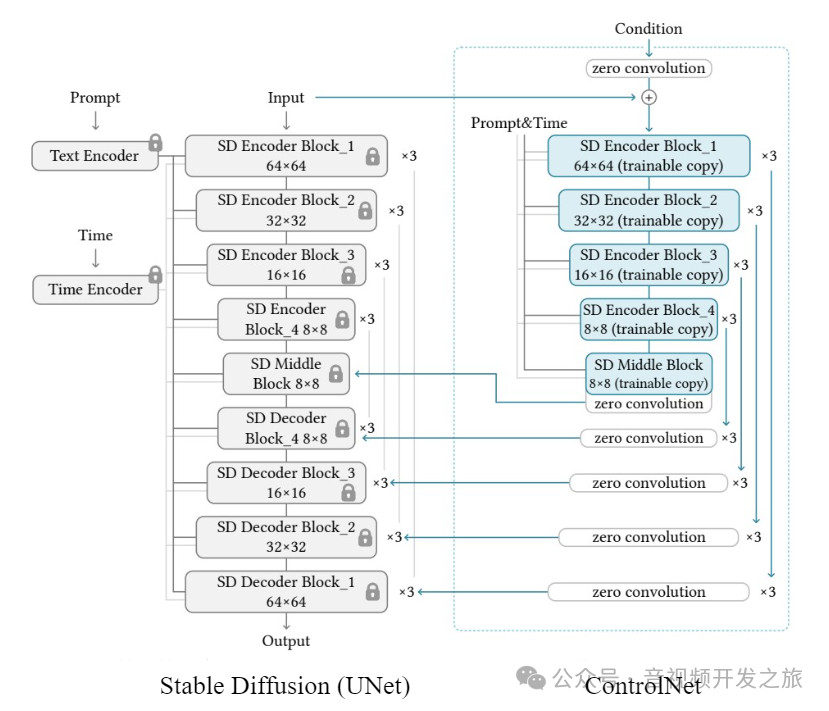
图片来自:StableDiffusion-ControlNet工作原理[译]
SD UNet 中的所有参数被冻结,并克隆一份(trainable copy)到 ControlNet. 这些 trainable copy 通过一个外部条件向量(external condition vector)进行训练.
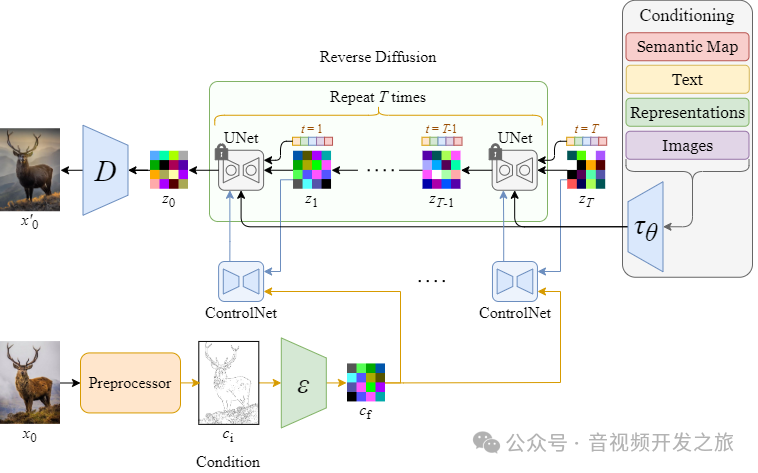
下图从整体上说明了 ControlNet 和 Stable Diffusion 如何在推理过程(采样)中协同工作
2.2 控制类型
为了保证生成图片和原图的画面相关性、一致性,ControlNet是很有必要的,它可以精细的控制图片的主体、背景和风格等,ContNet有多达十几种控制类型
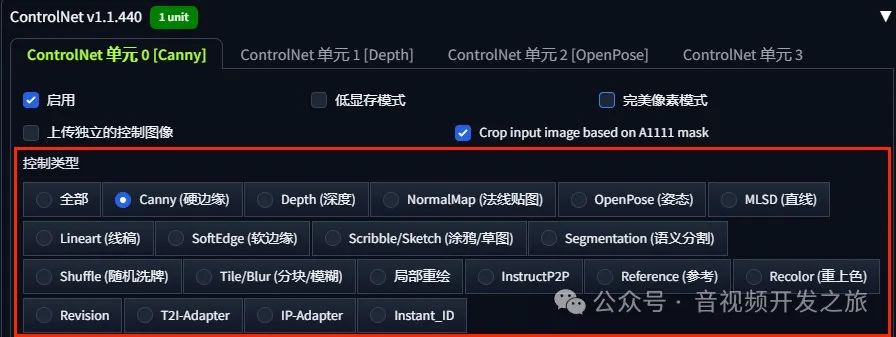
每种控制类型,有个不同的预处理器和模型,另外ControlNet还可以多个叠加组合使用,组合方式可以达到上百种
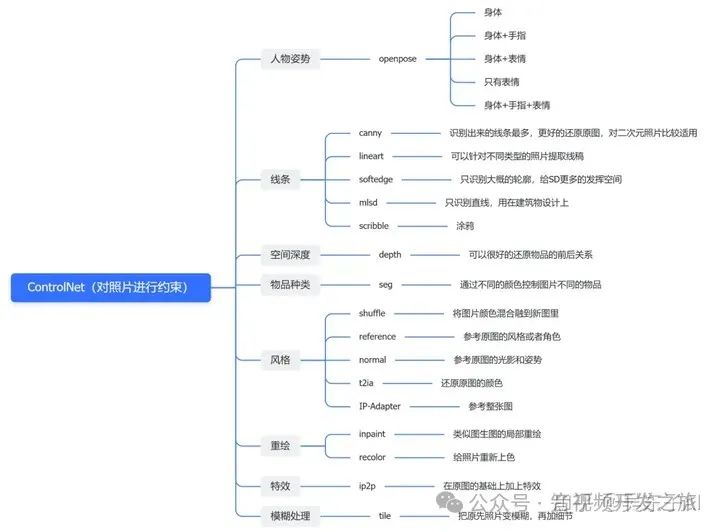
图片来自:从零开始学AI绘画,万字Stable Diffusion终极教程
下面介绍下最常用的几种控制方式: Canny(硬边缘)、Depth(深度图)、OpenPose(人体姿势)
2.2.1 Canny(硬边缘)
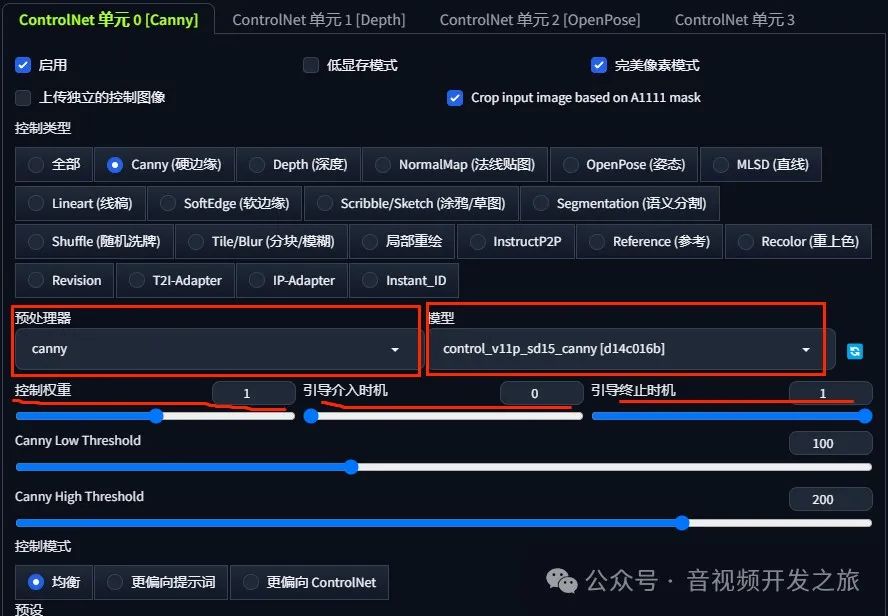

输入的原图

canny边缘图

生成的图
通过Canny提取出图片的边缘,然后使用canny对应的模型,结合prompt控制出图
使用场景:保持人物的风格轮廓不变,通过prompt修改背景的情况
2.2.2 Depth(深度图)

输入的原图

深度图

生成的图片
使用 Depth 原图被灰阶色值区分,程序自动的区分图像中元素区域的远近关系,使用该控制模式生成的图片,保持了同样的深度信息。
2.2.3 OpenPose(人体姿势)
原图
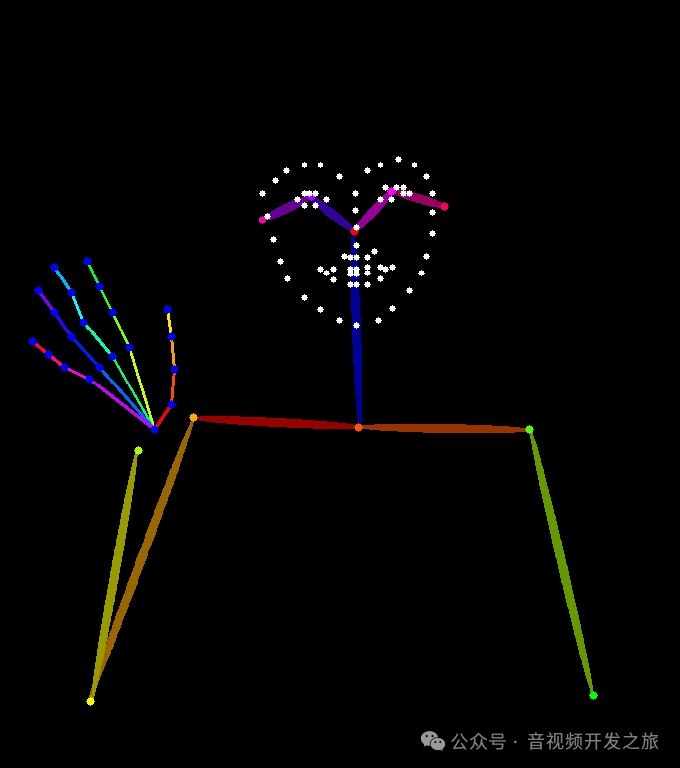
人体姿态图

生成的图片
OpenPose 可生成图像中人物的骨架图,这个骨架图可用于控制生成角色的姿态动作以及手部,OpenPos一定程度上解决了SD饱受诟病的残肢手部问题
三、图生图流程浅析
通过X/Y/Z脚本,来查看下不同生成图生图在不同采样方法的生成过程

可以看到,和文生图的不同是,输入不再以Gaussian noise作为初始化,而是以加噪后的图像特征为初始化。
图生图流程如下:
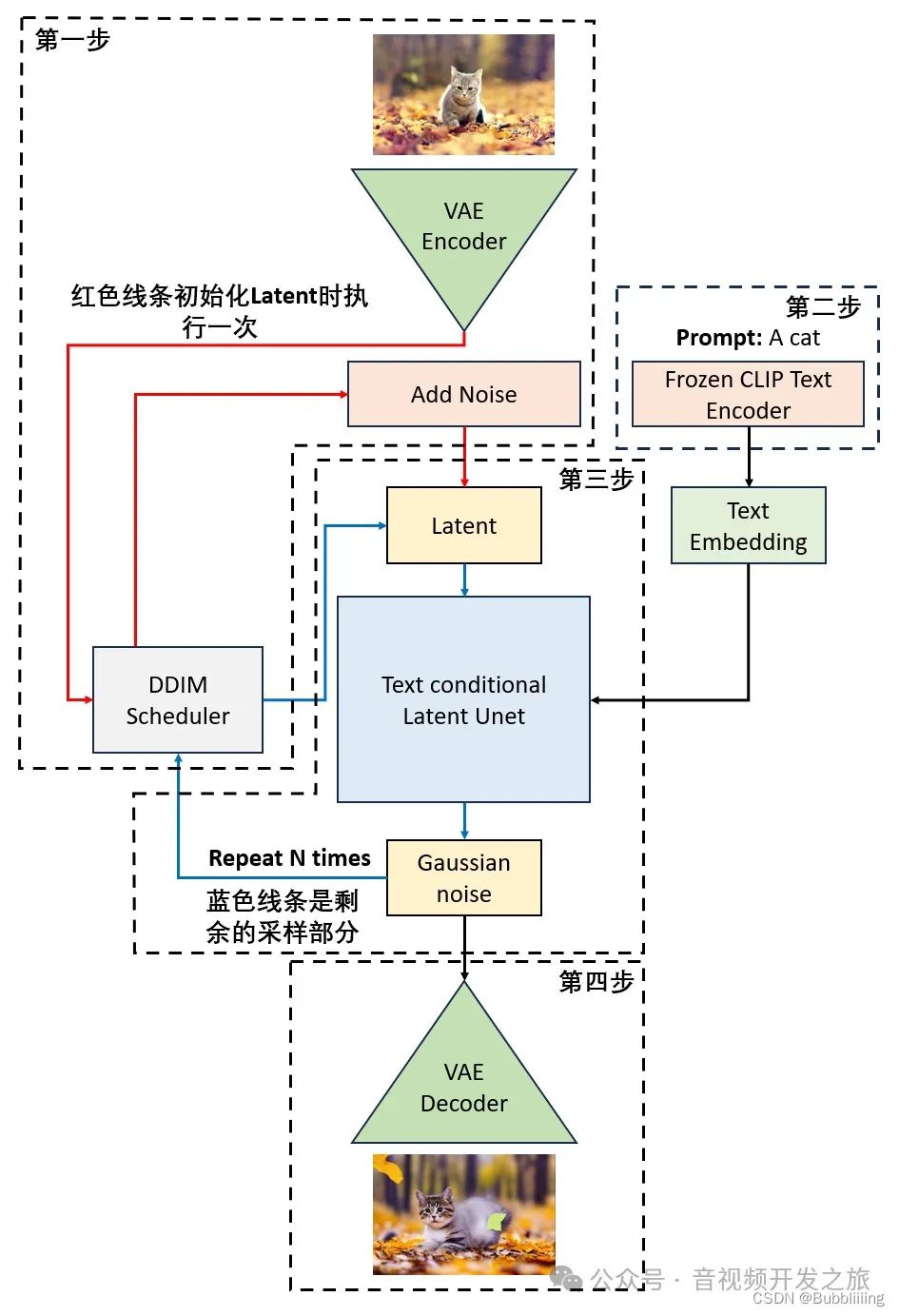
图片来自:AIGC专栏3——Stable Diffusion结构解析-以图像生成图像
第一步:对输入的图像进行VAE编码,获得图像的Latent space特征,然后使用该Latent特征基于DDIM Sampler进行加噪,获得输入图片加噪后的特征;
第二步:对输入的文本进行编码,获得Text Embding;
第三步:对前两步获得的图片加噪后的特征以及Text Embding 进行若干次采样和去噪;
第四步:使用VAE解码
四、SDWebui图生图代码流程
和文生图的流程类似
4.1 入口方法:modules.api.api.Api.img2imgapi
#输入的图片init_images = img2imgreq.init_images#初始化插件 eg:Contronetscript_args = self.init_script_args(img2imgreq, self.default_script_arg_img2img, selectable_scripts, selectable_script_idx, script_runner)
p.init_images = [decode_base64_to_image(x) for x in init_images]p.is_api = Truep.scripts = script_runnerp.outpath_grids = opts.outdir_img2img_gridsp.outpath_samples = opts.outdir_img2img_samples
#如果插件不为空,走插件处理流程,否则直接processif selectable_scripts is not None: p.script_args = script_args processed = scripts.scripts_img2img.run(p, *p.script_args) # Need to pass args as list hereelse: p.script_args = tuple(script_args) # Need to pass args as tuple here processed = process_images(p)4.2 process_images 加载sd基础模型和vae模型
for k, v in p.override_settings.items(): opts.set(k, v, is_api=True, run_callbacks=False)
#加载sd大模型 if k == 'sd_model_checkpoint': sd_models.reload_model_weights() #加载vae模型 if k == 'sd_vae': sd_vae.reload_vae_weights()
#继续调用process生成图片res = process_images_inner(p)4.3 process_images_inner
#获得编码后的promptp.prompts = p.all_prompts[n * p.batch_size:(n + 1) * p.batch_size]p.negative_prompts = p.all_negative_prompts[n * p.batch_size:(n + 1) * p.batch_size]p.seeds = p.all_seeds[n * p.batch_size:(n + 1) * p.batch_size]p.subseeds = p.all_subseeds[n * p.batch_size:(n + 1) * p.batch_size]
#采样samples_ddim = p.sample(conditioning=p.c, unconditional_conditioning=p.uc, seeds=p.seeds, subseeds=p.subseeds, subseed_strength=p.subseed_strength, prompts=p.prompts)
#解码x_samples_ddim = decode_latent_batch(p.sd_model, samples_ddim, target_device=devices.cpu, check_for_nans=True)
#保存生成的图片images.save_image(image, p.outpath_samples, "", p.seeds[i], p.prompts[i], opts.samples_format, info=infotext(i), p=p)五、参考资料
1. High-Resolution Image Synthesis with Latent Diffusion Models https://arxiv.org/abs/2112.10752
2. Denoising Diffusion Probabilistic Models https://arxiv.org/pdf/2006.11239.pdf
3. AIGC专栏3——Stable Diffusion结构解析-以图像生成图像(图生图,img2img)为例 https://blog.csdn.net/weixin_44791964/article/details/131992399
4. 从零开始学AI绘画,万字Stable Diffusion终极教程!https://zhuanlan.zhihu.com/p/659211251
5. 精讲stable diffusion的controlNet插件 https://caovan.com/jingjiangstable-diffusiondecontrolnetchajian/.html/3
6. StableDiffusion-ControlNet工作原理[译] https://www.aiuai.cn/aifarm2097.html
7.Stable Diffusion 超详细讲解 https://jarod.blog.csdn.net/article/details/131018599
感谢你的阅读
接下来我们继续学习输出AIGC相关内容,欢迎关注公众号“音视频开发之旅”,一起学习成长。
欢迎交流


