
热门标签
热门文章
- 1文本预处理库spaCy的基本使用(快速入门)_spacy库
- 2CVPR2023 I 混合Transformers和CNN的注意力网络用于立体图像超分辨率
- 3设计模式(Design Pattern)详细整理(含思维导图)
- 4Apktool反编译和重新打包
- 5RK3568学习之安卓端无线调试_安卓测试连接rk
- 6三种网络安全行业整合模式深度解读
- 7(CVPR2019)图像语义分割(18) DANet-集成双路注意力机制的场景分割网络_danet双通道自注意网络
- 8<位图(bitset)和布隆过滤器(BloomFilter)>——《C++高阶》_bitset和布隆过滤器
- 9基于51单片机的简易机械臂机械手设计摇杆控制舵机系统DIY135_51单片机机械臂
- 102022.7.26--IDEA(2021.3.1版本,未更新)配置MySQL(5.7.37)JDBC(jar包版本8.0.28)_mysql5.7对应的jar包版本
当前位置: article > 正文
Python爬取某平台付费文档,确定不来薅羊毛吗?_爬取csdn付费资源
作者:笔触狂放9 | 2024-04-17 00:50:16
赞
踩
爬取csdn付费资源
导语:
哈喽,哈喽~当代大学生写作业时,emmmm…先看一眼,ok有点印象。

想翻书时,这是第几页?怎么这么干净,是这里吗…
这时“学小易”就很友好了,但是唯一不足的一点是,只有答案,没有过程。
浏览器也很友好,浏览到关键地方要钱,更别说想下载下来复习了…

今天呢,小编教大家用python如何免费下载付费文档资料,我再也不用担心下载资料要钱啦!也不用担心期末复习啦!

正文:
基本开发环境
Python 3.6
Pycharm
相关模块的使用
import os
import requests
import time import re
import json from docx
import Document from docx.shared
import Cm
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
目标网页分析
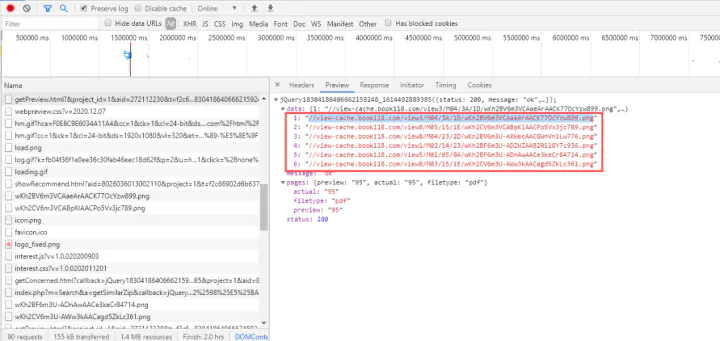
网站的文档内容,都是以图片形式存在的。它有自己的数据接口
接口链接:
https://openapi.book118.com/getPreview.html?&project_id=1&aid=272112230&t=f2c66902d6b63726d8e08b557fef90fb&view_token=SqX7ktrZ_ZakjDI@vcohcCwbn_PLb3C1&page=1&callback=jQuery18304186406662159248_1614492889385&_=1614492889486
- 1
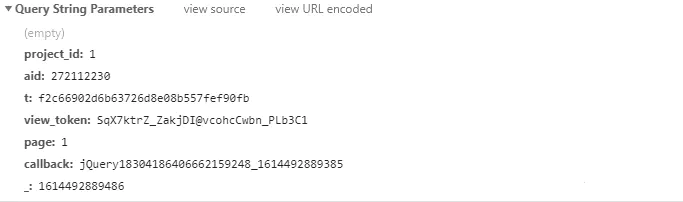
接口的请求参数
第一页:
第二页:
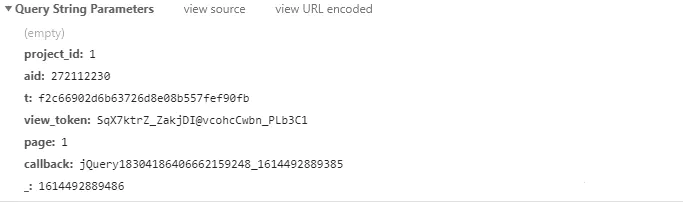
第三页:
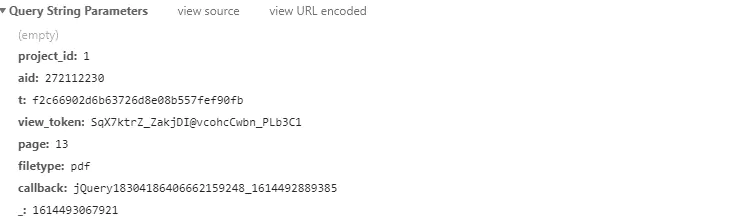
如上图所示,翻页参数改变的是page 每次加6。
整体思路
请求网页返回response数据(字符串)
通过re模块匹配提取中间的数据(列表)索引取0(字符串)
通过json模块是把提取出来的数据转换成json模块
通过遍历获取每张图片的url地址
保存图片到本地文件夹
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
把图片保存到word文档
def download(): content = 0 for page in range(1, 96, 6): # 给定 2秒延时 time.sleep(2) # 获取时间戳 now_time = int(time.time() * 1000) url = 'https://openapi.book118.com/getPreview.html' # 请求参数 params = { 'project_id': '1', 'aid': '272112230', 't': 'f2c66902d6b63726d8e08b557fef90fb', 'view_token': 'SqX7ktrZ_ZakjDI@vcohcCwbn_PLb3C1', 'page': f'{page}', '_': now_time, } # 请求头 headers = { 'Host': 'openapi.book118.com', 'Referer': 'https://max.book118.com/html/2020/0427/8026036013002110.shtm', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36' } response = requests.get(url=url, params=params, headers=headers) # 使用正则表达式提取内容 result = re.findall('jsonpReturn\((.*?)\)', response.text)[0] # 字符串转json数据 json_data = json.loads(result)['data'] # 字典值的遍历 for value in json_data.values(): content += 1 # 拼接图片url img_url = 'http:' + value print(img_url) headers_1 = { 'Host': 'view-cache.book118.com', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36' } # 请求图片url地址 获取content二进制数据 img_content = requests.get(url=img_url, headers=headers_1).content # 文件名 img_name = str(content) + '.jpg' # 保存路径 filename = 'img\\' # 以二进制方式保存 (图片、音频、视频等文件都是以二进制的方式保存) with open(filename + img_name, mode='wb') as f: f.write(img_content)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
爬虫部分的代码还是比较简单的,没有什么特别的难度。
爬取这些文档,都是需要打印或者查询所以要把这些单张的图片都保存到word文档里面。
写入word文档
1、文件夹中所有图片的文件名。
正常的操作大家都是知道使用os模块就可以获取了,但是这里有一个问题
path = './img/'
lis = os.listdir(path)
print(lis)
>>>['1.jpg', '10.jpg', '11.jpg', '12.jpg', '13.jpg', '14.jpg', '15.jpg', '16.jpg', '17.jpg', '18.jpg', '19.jpg', '2.jpg', '20.jpg', '21.jpg', '22.jpg', '23.jpg', '24.jpg', '3.jpg', '4.jpg', '5.jpg', '6.jpg', '7.jpg', '8.jpg', '9.jpg']
- 1
- 2
- 3
- 4
- 5
- 6
- 7

在文件夹中都是有序排列循序的,但是用os模块读取出来的文件名,都是无序的,这样保存的话会导致文档内容循序错乱,这不是我们想要的。
所以需要把文件名都排序输出。
path = './img/' lis = os.listdir(path) c = [] for li in lis: index = li.replace('.jpg', '') c.append(index) c_1 = sorted(list(map(int, c))) new_files = [(str(i) + '.jpg') for i in c_1] print(new_files) >>>['1.jpg', '2.jpg', '3.jpg', '4.jpg', '5.jpg', '6.jpg', '7.jpg', '8.jpg', '9.jpg', '10.jpg', '11.jpg', '12.jpg', '13.jpg', '14.jpg', '15.jpg', '16.jpg', '17.jpg', '18.jpg', '19.jpg', '20.jpg', '21.jpg', '22.jpg', '23.jpg', '24.jpg']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
排序好之后,通过docx模块对其进行写入。
document.add_picture(img_path, width=Cm(17), height=Cm(24))
document.save('tu.doc') # 保存文档
- 1
- 2
- 3
一定要设置写入图片的大小,不然图片太大,排版不好看。
写完之后把图片都删除掉
os.remove(img_path)
- 1
完整实现效果


最后我们下载下来的每一页都是一张图片。
结尾:
文章就写到这里结束啦~大家喜欢的记得点点赞
需要完整的项目源码的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/437334
推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

