
一点就分享系列(实践篇3-上篇)— 修改YOLOV5 之”魔刀小试“+ Trick心得分享+V5精髓部分源码解读_yolov5魔改
赞
踩
一点就分享系列(实践篇3—上篇)—修改YOLOV5 魔刀小试+ Trick心得分享
DL部署大热,而我觉得回归原理和源码更加重要!正如去年,我也提倡部署工程化,眼争上班工作我这里也是以搬砖产出为主。但是今年嘛 我觉得很有必要研究研究,如果你不想被PASS,那就不能只限于工作任务。
检测领域YOLOV5肯定是大家的炼丹必备模型,收敛快,精度高都是其爱不释手的理由,各种魔改基础backbone或者别的trick也层出不穷,这些trick和优化V5的作者也在收集更新,大家只要跟着update就好。
上篇我主要分享下我若干改动中的两个改动,针对V5的head PAN后添加了ASFF自适应的特征融合检测层和注意力机制CBAM的模块,后续还有很多改动 一是我还在作实验,二是代码没整理好git,本篇计划故分为3篇篇幅的内容。
代码以git更新为主,不间断添加改进方法和V5仓库保持合并!该篇只是我初步入门,我和我的博客都会随着时间变强!
阅读本文后,您会收获以下:
1. 具备修改V5模型的能力和了解一些Trick即使具备其解释性,但是仍旧不一定work。
2. 提供你修改模型的trick和分享一些心得经验;
3. 从本质上了解YOLOV5的特点和理解核心源码
4. 结尾会传输一波真气,麻烦关注csdn和fork+star 我的git,后续会一直持续更新产出!!
修改心得闲聊
这里我先唠嗑下,在硬件资源有限前提下,对于检测的trick效果不只取决于数据集,甚至可能是你NMS的阈值,因此还真不可以说什么样的trcik就100% work!
我改了两个版本的ASFF,起初我在Detect函数里直接添加 为了看看效果(以抽烟检测数据集,在第一次的验证训练集的效果并没有什么提升,大概都是0.7+的MAP),不过训练集的在一定程度上的MAP无法决定在测试的数据上表现。实际中我们关注在测试数据中的表现其实就够了,当然基础性的Baseline上我们需要规规矩矩去做实验。
针对YOLOV5的Head层分别进行ASFF和特征注意机制CBAM的改动,适配了V5的代码风格,且希望提高MAP或者在小目标数据集的精度或者其他任务的表现,至于bifpn和别的目前没有尝试,为什么?
- 首先,现在的模型都很SOTA,但是DL特点就是并不一定具备可解释性和理论实验依据就一定能提升性能,比如ghost+senet的组合在V5中效果也是一般,在具备以上两点的情况下,需要通过公开数据集去证明,才能说明其可解释性真正work。所以我自己根据时间精力取舍了下,决定进行ASFF和CBAM的改进尝试。至于CBAM也是在别的模型上证明了其AP涨点有用,后面会详细说。(有兴趣有时间的朋友可以私聊,我这里大概有不少改baseline的方案,无奈分身乏术)
- 其次,是我个人觉得没有必要尝试重复性的特征融合操作,毕竟工作客观环境原因,我无法像科研那样充分证明多次调参和trcik引用,也称不上专业炼丹术士,总之要搬砖的啊太难了。后期也许会多个模块组合,不断尝试中。。。时间允许的话。
- 对于即插即用的模块化在网络机构中的问题:怎么改?哪里改?改多少的问题。以此,按照自己业余的时间顺序去尝试了修改,可能这一篇写不完,因为我现在实验还没做完,先分享一部分工作。
提示:具体可以参考我的v5 git,也可以一起学习探讨my github,持续更新。
一、ASFF是什么?
1.背景简述
众所周知,在检测模型中利用高层特征的语义信息和底层特征结合如FPN,PAN,BIFPN等等,都是如此,那么这里说下Adaptively Spatial Feature Fusion的自适应特征融合,这招在YOLOV3中是大放异彩,论文作者认为这样并不能充分利用不同尺度的特征。所以提出一种新的融合方式来替代concat或element-wise。注意这招原本在V3的FPN下进行了一次ASFF算法层的融合操作,如图所示,
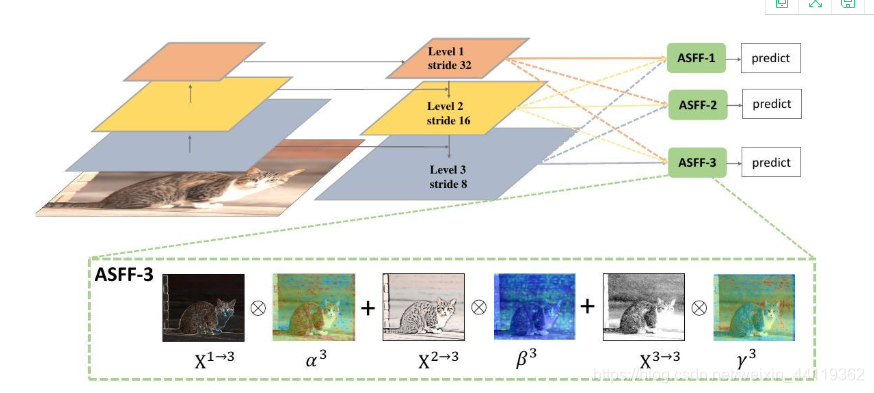
2.ASFF原理简述
以ASFF-3为例,图中的绿色框描述了如何将特征进行融合,其中X1,X2,X3分别为来自level,level2,level3的特征,与为来自不同层的特征乘上权重参数α3,β3和γ3并相加,就能得到新的融合特征ASFF-3,如下面公式所示:
因为采用相加的方式,所以需要相加时的level1~3层输出的特征大小相同,且通道数也要相同,需要对不同层的feature做upsample或downsample并调整通道数。
对于权重参数α,β和γ,分别通过resize后的level1~level3的特征图经过1×1的卷积得到的。并且参数α,β和γ经过concat之后通过softmax使得他们的范围都在[0,1]内并且和为1,如下:
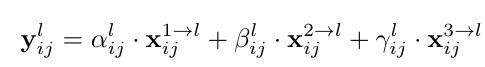
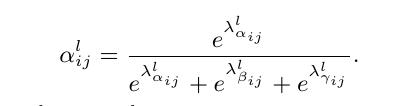
本质: 就是对所有层加权融合;类似注意力机制。
经过降采样后+1*1卷积压缩通道,分别得到三个参数,然后经过Softmax归一化成0~1之间,正好成了权重。
3 动机
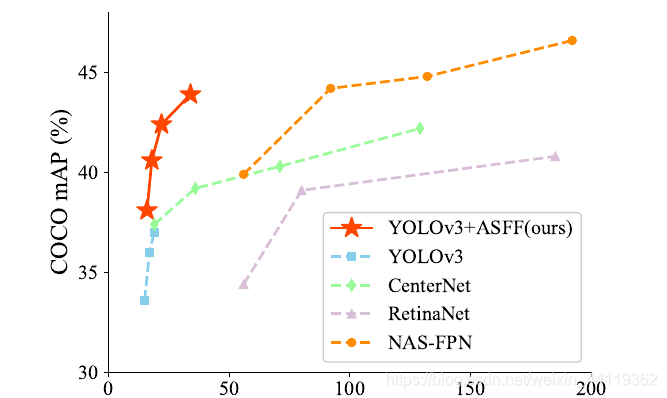
在V3中的成功,不仅让我跃跃欲试且看到自适应这种形式还是让我觉得成功率应该较高,于是就对着V5进行一个ASFF版本的改进填充!
开始下手了,毕竟官方数据摆着了:
二、ASFFV5和CBAM模块添加
1. 修改思路:
在YOLOV5的任意结构中在HEAD末尾也就是PANNET的三个output层添加,且ASFF的每一层生成都是需要PANNET的三个output,这种结构最简单直接和V3的思路一样,区别就是我在PANNET的结构融合后再加一次权重自适应。
说到这里,最后面这个ASFF做了一些验证后还有个小插曲,但是当时我心里算是有预期:这个改法我并不认为会多少提升,甚至放在COCO数据集上也不咋会涨点,但是呢我一定要试试且起码提供个V5的ASFF模块code也行啊。。
2. 修改步骤:(在此基础上,你需要对V5的原理和代码有一个大致了解)
不多啰嗦,直接上以ASFFV5版本的操作步骤举例子来说明:
首先,我在yolov5/modesl/common.py下 ,我们需要添加ASFFV5的代码:
class ASFFV5(nn.Module): def __init__(self, level, multiplier=1, rfb=False, vis=False, act_cfg=True): """ ASFF version for YoloV5 only. Since YoloV5 outputs 3 layer of feature maps with different channels which is different than YoloV3 normally, multiplier should be 1, 0.5 which means, the channel of ASFF can be 512, 256, 128 -> multiplier=1 256, 128, 64 -> multiplier=0.5 For even smaller, you gonna need change code manually. """ super(ASFFV5, self).__init__() self.level = level self.dim = [int(1024*multiplier), int(512*multiplier), int(256*multiplier)] #print("dim:",self.dim) self.inter_dim = self.dim[self.level] if level == 0: self.stride_level_1 = Conv(int(512*multiplier), self.inter_dim, 3, 2) #print(self.dim) self.stride_level_2 = Conv(int(256*multiplier), self.inter_dim, 3, 2) self.expand = Conv(self.inter_dim, int( 1024*multiplier), 3, 1) elif level == 1: self.compress_level_0 = Conv( int(1024*multiplier), self.inter_dim, 1, 1) self.stride_level_2 = Conv( int(256*multiplier), self.inter_dim, 3, 2) self.expand = Conv(self.inter_dim, int(512*multiplier), 3, 1) elif level == 2: self.compress_level_0 = Conv( int(1024*multiplier), self.inter_dim, 1, 1) self.compress_level_1 = Conv( int(512*multiplier), self.inter_dim, 1, 1) self.expand = Conv(self.inter_dim, int( 256*multiplier), 3, 1) # when adding rfb, we use half number of channels to save memory compress_c = 8 if rfb else 16 self.weight_level_0 = Conv( self.inter_dim, compress_c, 1, 1) self.weight_level_1 = Conv( self.inter_dim, compress_c, 1, 1) self.weight_level_2 = Conv( self.inter_dim, compress_c, 1, 1) self.weight_levels = Conv( compress_c*3, 3, 1, 1) self.vis = vis def forward(self, x_level_0, x_level_1, x_level_2): #s,m,l """ # 128, 256, 512 512, 256, 128 from small -> large """ # print('x_level_0: ', x_level_0.shape) # print('x_level_1: ', x_level_1.shape) # print('x_level_2: ', x_level_2.shape) x_level_0=x[2] x_level_1=x[1] x_level_2=x[0] if self.level == 0: level_0_resized = x_level_0 level_1_resized = self.stride_level_1(x_level_1) level_2_downsampled_inter = F.max_pool2d( x_level_2, 3, stride=2, padding=1) level_2_resized = self.stride_level_2(level_2_downsampled_inter) #print('X——level_0: ', level_2_downsampled_inter.shape) elif self.level == 1: level_0_compressed = self.compress_level_0(x_level_0) level_0_resized = F.interpolate( level_0_compressed, scale_factor=2, mode='nearest') level_1_resized = x_level_1 level_2_resized = self.stride_level_2(x_level_2) elif self.level == 2: level_0_compressed = self.compress_level_0(x_level_0) level_0_resized = F.interpolate( level_0_compressed, scale_factor=4, mode='nearest') x_level_1_compressed = self.compress_level_1(x_level_1) level_1_resized = F.interpolate( x_level_1_compressed, scale_factor=2, mode='nearest') level_2_resized = x_level_2 # print('level: {}, l1_resized: {}, l2_resized: {}'.format(self.level, # level_1_resized.shape, level_2_resized.shape)) level_0_weight_v = self.weight_level_0(level_0_resized) level_1_weight_v = self.weight_level_1(level_1_resized) level_2_weight_v = self.weight_level_2(level_2_resized) # print('level_0_weight_v: ', level_0_weight_v.shape) # print('level_1_weight_v: ', level_1_weight_v.shape) # print('level_2_weight_v: ', level_2_weight_v.shape) levels_weight_v = torch.cat( (level_0_weight_v, level_1_weight_v, level_2_weight_v), 1) levels_weight = self.weight_levels(levels_weight_v) levels_weight = F.softmax(levels_weight, dim=1) fused_out_reduced = level_0_resized * levels_weight[:, 0:1, :, :] +\ level_1_resized * levels_weight[:, 1:2, :, :] +\ level_2_resized * levels_weight[:, 2:, :, :] out = self.expand(fused_out_reduced) if self.vis: return out, levels_weight, fused_out_reduced.sum(dim=1) else: return out

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
注意:
1. 这里和原版V3的ASFF并不同,是源于YOLOV3在三个特征层输出顺序和YOLOV5经过了PANNET双向融合后正好相反,所以容易出错;只需要把输入维度调换下即可,我在ASFF的函数开头已经做过处理;
2. 其次在参数中,你可以通过开启参数,启动RFB模块去降低计算开销且一定程度上或许能提升。至于RFBNET,这里简单介绍下,对应于上述代码由于封装了,可能没那么清楚。在代码中,ASFF最后填加了一层简单的RFB:
3.这里我们再说细致点,这个ASFF其实本质就是每一层都对FPN的三层进行了加权融合,那么有朋友会问:这个权重参数如何得到?
首先,参数实际来自前面卷积特征层的输出,所以名字叫自适应,因为这些权重参数同样经过梯度反向传播变为了可学习的,这是整个trick的一个特点。
其次,这个方法的好处就是,这里我们说下原始版本V3,在反向传播中,每一层都包含正负样本的梯度传播,这样导致梯度不够连续稳定,并且收敛变慢。而加入ASFF有了权重融合,就会让正样本和负样本的权重比例不同,通过参数去控制,降低干扰。
但是在V5中为什么不如V3work?这点我有些个人思考,我会写在文末最后总结。
引入Receptive Field Block (RFB)
,引入RFB模拟人类视觉的感受野加强网络的特征提取能力,在结构上RFB借鉴了Inception的思想,主要是在Inception的基础上加入了dilated卷积层(dilatedconvolution),也叫空洞卷积层,从而有效增大了感受野。关键确实没什么计算消耗。

接着,我们需要将这个特征融合方法注册在YOLOV5的yolo.py中,这样我们可以通过model/*.yaml ,去自己设计网络模型!在代码中找到parse_model 这个函数,进行以下添加,由于作者对打包方式提了建议,我也是这么认为,毕竟ASFF是特征融合,又需要满足任何人都可以替换的方式,所以另外打包了一个ASFF_Detect()层,听大哥的就好了,所以我在models/yolo.py中打包了特征融合层,这样就不需要你自己在YAML上自己写了,具体可以参考我git的改动。
class ASFF_Detect(nn.Module): #add ASFFV5 layer and Rfb stride = None # strides computed during build export = False # onnx export def __init__(self, nc=80, anchors=(), multiplier=0.5,rfb=False,ch=()): # detection layer super(ASFF_Detect, self).__init__() self.nc = nc # number of classes self.no = nc + 5 # number of outputs per anchor self.nl = len(anchors) # number of detection layers self.na = len(anchors[0]) // 2 # number of anchors self.grid = [torch.zeros(1)] * self.nl # init grid self.l0_fusion = ASFFV5(level=0, multiplier=multiplier,rfb=rfb) self.l1_fusion = ASFFV5(level=1, multiplier=multiplier,rfb=rfb) self.l2_fusion = ASFFV5(level=2, multiplier=multiplier,rfb=rfb) a = torch.tensor(anchors).float().view(self.nl, -1, 2) self.register_buffer('anchors', a) # shape(nl,na,2) self.register_buffer('anchor_grid', a.clone().view(self.nl, 1, -1, 1, 1, 2)) # shape(nl,1,na,1,1,2) self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
接下来把函数注册到到解析模型的代码里:
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP,CBAM,ResBlock_CBAM, C3]: c1, c2 = ch[f], args[0] if c2 != no: # if not output c2 = make_divisible(c2 * gw, 8) args = [c1, c2, *args[1:]] if m in [BottleneckCSP, C3]: args.insert(2, n) # number of repeats n = 1 elif m is nn.BatchNorm2d: args = [ch[f]] elif m is Concat: c2 = sum([ch[x] for x in f]) elif m is ASFF_Detect: args.append([ch[x] for x in f]) if isinstance(args[1], int): # number of anchors args[1] = [list(range(args[1] * 2))] * len(f) elif m is Contract: c2 = ch[f] * args[0] ** 2 elif m is Expand: c2 = ch[f] // args[0] ** 2 elif m is ASFFV5: c2=args[1] else: c2 = ch[f]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
简单说下参数,这下我们主要关注args,他是我们定义的模块参数表,c1是输入通道数,c2是输出通道数,就围绕这个修改。同时我将CBAM放入了代码的模块列表中。
3.注册CBAM模块
CBAM 这个可以在模型中即插即用的小模块.
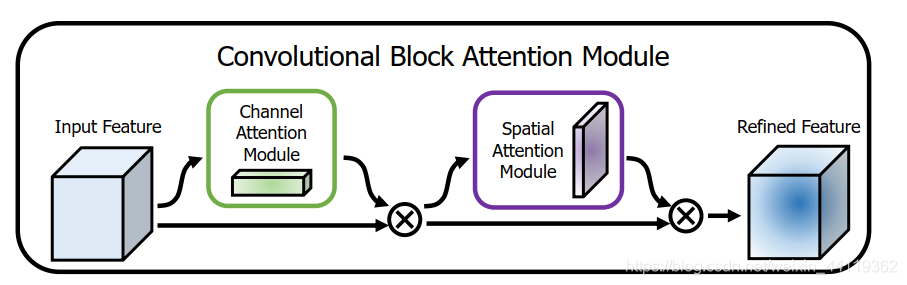
通过 channel 和 spatial 增强特征图中的有用特征, 并且抑制无用特征, 从而告诉模型应该注意哪个区域. 人在第一眼接触图像时, 视觉系统并不会马上处理全局的信息, 而是会选择性地关注一些突出的局部信息.这个attention 的设计理论上很合理,且弥补了SE模型只关注通道权重分配的不足。
代码如下(示例):还是在commo.py中添加类,然后yolo.py中添加模块,和其入参调整。
关于这个代码太简单,直接给出来,作者发现将 channel attention 和 spatial attention 级联的性能会比并行的好, 且在级联时把 channel attention 放在前面效果会更好.
```python class ChannelAttentionModule(nn.Module): def __init__(self, c1, reduction=16): super(ChannelAttentionModule, self).__init__() mid_channel = c1 // reduction self.avg_pool = nn.AdaptiveAvgPool2d(1) self.max_pool = nn.AdaptiveMaxPool2d(1) self.shared_MLP = nn.Sequential( nn.Linear(in_features=c1, out_features=mid_channel), nn.ReLU(), nn.Linear(in_features=mid_channel, out_features=c1) ) self.sigmoid = nn.Sigmoid() #self.act=SiLU() def forward(self, x): avgout = self.shared_MLP(self.avg_pool(x).view(x.size(0),-1)).unsqueeze(2).unsqueeze(3) maxout = self.shared_MLP(self.max_pool(x).view(x.size(0),-1)).unsqueeze(2).unsqueeze(3) return self.sigmoid(avgout + maxout) class SpatialAttentionModule(nn.Module): def __init__(self): super(SpatialAttentionModule, self).__init__() self.conv2d = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3) #self.act=SiLU() self.sigmoid = nn.Sigmoid() def forward(self, x): avgout = torch.mean(x, dim=1, keepdim=True) maxout, _ = torch.max(x, dim=1, keepdim=True) out = torch.cat([avgout, maxout], dim=1) out = self.sigmoid(self.conv2d(out)) return out class CBAM(nn.Module): def __init__(self, c1,c2): super(CBAM, self).__init__() self.channel_attention = ChannelAttentionModule(c1) self.spatial_attention = SpatialAttentionModule() def forward(self, x): out = self.channel_attention(x) * x out = self.spatial_attention(out) * out return out
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
不难看出,就是利用了通道注意力机制和空间注意力机制:
1. 先对输入input分别进行评价池化和最大池化—》分别放入MLP——》相加后用激活函数输出channel attention 和input输入相乘得到channel attention (为什么要相乘?这里就意味着给输入的每一个通道作权重分配)表示特征图的各个 channel 之间的内在关系, 哪些 channel 是值得关注的, 哪些 channel 是应该忽略的.
2. 拿到通道模块的channel attention map后,分别进行一次平均池化和最大池化—》cat拼接——》一次卷积+激活函数得到输入,至于为什么是7*7卷积,因为论文实验的最优结果就是这个。
3. 拿到spital attention map后,再和channel attention map相乘,得到OUT,这里相乘相当于给input作了通道注意力权重和空间注意力权重分配。
最后在YAML中,可以使用,这里注意的是层数序号不要接错,且depth_multiple和width_multiple这两个是模型的宽度和深度因子,我简单写了点解释,这个结构非常的好,不需要写入输入的channerls,因为每一层的输入都是来自上一层的输出!自己跑过V5的大概都了解,我不做赘述。(如果你真看不懂,那说明你根本没有了解过V5且这只是个功夫活,慢慢肝把) ,这里随意举一个例子:
# parameters nc: 80 # number of classes depth_multiple: 0.33 # model depth multiple width_multiple: 0.50 # layer channel multiple # anchors anchors: #- [5,6, 7,9, 12,10] # P2/4 - [10,13, 16,30, 33,23] # P3/8 - [30,61, 62,45, 59,119] # P4/16 - [116,90, 156,198, 373,326] # P5/32 # YOLOv5 backbone backbone: # [from, number, module, args] # [c=channels,module,kernlsize,strides]- 1代表来自上一层输出 [[-1, 1, Focus, [64, 3]], # 0-P1/2 [c=3,64*0.5=32,3] 举例,输出通道数*width_multiple:=64*0.5 [-1, 1, Conv, [128, 3, 2]], # 1-P2/4 [-1, 3, C3, [128]], [-1, 3, CBAM, [128]], # 举例,3*width_multiple:=3*0.33=1 [-1, 1, Conv, [256, 3, 2]], # 3-P3/8 [-1, 9, C3, [256]], [-1, 3, CBAM, [256]] , [-1, 1, Conv, [512, 3, 2]], # 5-P4/16 [-1, 9, C3, [512]], [-1, 3, CBAM, [512]], [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 [-1, 1, SPP, [1024, [5, 9, 13]]], [-1, 3, C3, [1024, False]], # 9 [-1, 3, CBAM, [1024]], #13 ] # YOLOv5 head head: [[-1, 1, Conv, [512, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 7], 1, Concat, [1]], # cat backbone P4 [-1, 3, C3, [512, False]], # 13 [-1, 1, Conv, [256, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 4], 1, Concat, [1]], # cat backbone P3 [-1, 3, C3, [256, False]], # 19 (P3/8-small) [-1, 3, CBAM, [256]], #[-1, 3, C3, [256]], [-1, 1, Conv, [256, 3, 2]], [[-1, 18], 1, Concat, [1]], # cat head P4 [-1, 3, C3, [512, False]], # 23 (P4/16-medium) [256, 256, 1, False] [-1, 3, CBAM, [512]], #[-1, 3, C3, [512]], [-1, 1, Conv, [512, 3, 2]], #[256, 256, 3, 2] [[-1, 14], 1, Concat, [1]], # cat head P5 [-1, 3, C3, [1024, False]], # 27 (P5/32-large) [512, 512, 1, False] [-1, 3, CBAM, [1024]], #[-1, 3, C3, [1024]], [[22, 26, 30], 1, ASFF_Detect, [nc, anchors,0.5,True]], # ASFF_Detect(P3, P4, P5,mult,rfb) ]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
最后的最后,run:
python models/yolo.py --cfg models/你的yaml
- 1
去验证下结构有无低级错误。
读到这里赠送1个trick
分享一个mosica的改进思路,在V5中我也看到过聚合更多的图像(原本是4张按照比例顺时针拼一起),这里裁剪的话从每张需要裁剪的地方保留一个图像的两边,这样图像的任意两边是原始的边缘,可以保证增加概率保证你的裁剪目标不被切割,导致样本难分,如下图,这样的每两个个边缘拼在一起的是原始图像的边缘,这里小目标我建议随机抽取额外5张拼在一起,也就是6张拼接。这个我后续会自己实现一下。
总结+小插曲+真气传输
小插曲:
- 起初在ASFF特征融合计算,我直接在YOLOV5的PAN输出后三层进行了添加,改动很简单,但在小数据集上进行加载权重进行训练,batch=32 or 16,至于结果不怕说啥map嘛哈哈,几乎没什么提升且我并没有用V5默认以外的任何trcik,除了foccal loss修改启用过,而就在第一次实验后的一天,git上一个热心朋友也给了建议 ,意思是V4的作者all in了所有trcik加上ASFF,也就提升了0.5AP,没什么卵用。其实我也认同,但是我一顿操作猛如虎,再看MAP不见涨,我难受啊我还强调也许还没有去调参tricK,但就目前和相关人探讨的结论,确实还没有能够让ASFF在V4和V5上涨点。不过作者介意我从新在COCO(时间太长)或者VOC上进行验证,想想我的显存实在尴尬,网络也不好。但是这个ASFF的结论,确实也没有什么特别的建议。我只能说也许是我用的不好,有兴趣的直接fork下我的git YOLOV5大家一起研究,当然我也会继续验证。
- 关于CBAM这个,在动手加之前我就是高期望,因为这个轻量化的模型能提供空间和通道互补的注意力机制且没什么计算代价,那就太香了,关键在于backbone里你怎么加,我的思路就是在每次卷积之间添加CBAM。这个涨点神器我在V5上目前遇到了不少问题,就是不好训练,极难收敛,我后续会进行一些调整。
先说下自己实验的ASFF作用的个人思考+真气传输:
1.首先V3中的成功和V5的暂时性失败是否源于V3和V5本质的一些区别,我在上述ASFF的介绍中,介绍了ASFF的2点重要原理,让我联想到了V3和V5的一个本质区别,首先在训练GT的匹配上:
yolov3基于IOU匹配,且V3严格执行当前BOX仅和三个尺度下的某一尺度的anchor匹配,即一夫一妻制;
但是V5不同,基于shape匹配,当前的Box宽和匹配的anchor宽高比>阈值就被认为是背景,即一夫多妻制;
2.那么符合要求的BOX中心点,这里开始YOLOV5真正的特色和精髓:
BOX中心点就在属于自己的网格内,找出最近的两个网格,那么有三个网格都认为是负责预测该bbox的,这样是不是起码就将现有的正样本扩大了原来的3倍!为什么这么做?因为 V5这么做的原则就是作者应该认为增加正样本,可以加快收敛,这个操作叫做跨网格预测!
V5的gt box在多个预测层都算正样本这和V3“一心一意”截然相反,现实也正是如此,所以V5的‘效率快’!
我们可以具体再进一步观察,上源码!为方便阅读,我写了些注释在上面,刷一遍V5的训练核心代码:
V5 GT匹配代码:
def build_targets(self, p, targets): # Build targets for compute_loss(), input targets(image,class,x,y,w,h) na, nt = self.na, targets.shape[0] # number of anchors, targets labesl 包含image,class,x,y,w,h tcls, tbox, indices, anch = [], [], [], [] #out #利用gain来计算目标在某一个特征图上的位置信息,初始化为1 gain = torch.ones(7, device=targets.device) # normalized to gridspace gain # 因为有na=3层, 复制三份, ai = torch.arange(na, device=targets.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt) #将每个BOX复制了三份,然后和三个anchor匹配 targets = torch.cat((targets.repeat(na, 1, 1), ai[:, :, None]), 2) # append anchor indices g = 0.5 # bias 中心偏移 #以周围附近的网格4个为网格+自己是(0,0)=5个 off = torch.tensor([[0, 0], [1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m # [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm ], device=targets.device).float() * g # offsets for i in range(self.nl): #遍历三个输出尺度 anchors = self.anchors[i] #当前第i个尺度层 gain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gain 特征图的对应输出尺寸 # Match targets to anchors t = targets * gain #将归一化的GT尺度*对应尺寸=映射到特征图的尺度,此时t就是我们的GT targets if nt:#开始匹配 # Matches r = t[:, :, 4:6] / anchors[:, None] # wh ratio 取宽高比 j = torch.max(r, 1. / r).max(2)[0] < self.hyp['anchor_t'] # compare:保留小于超参文件中设置的阈值,如果比例过大,则说明匹配度不高,则过滤掉在当前尺度层 # j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2)) t = t[j] # filter # Offsets,寻找最邻近的2个网格 gxy = t[:, 2:4] # grid xy 取XY 就是BOX中心点 默认是相对左上角的坐标值 gxi = gain[[2, 3]] - gxy # inverse 拿到相对右边的坐标 # 求反后,通过下面的判断求出中心点偏移的方向,沿着此方向找到临近的2个网格 #目的就是判断中心点是否更偏向左和上 j, k = ((gxy % 1. < g) & (gxy > 1.)).T #%1的含义就是求得坐标xy后的小数点,也就是相对每个网格单位是1的偏移量要求小于g=0.5, #目的就是判断相对右上角的中心点是否更偏向右和下 l, m = ((gxi % 1. < g) & (gxi > 1.)).T #[5=上面的off网格数量, 包括target中心点和他的四个相邻网格,j,k,l,m] j = torch.stack((torch.ones_like(j), j, k, l, m))#有五种情况,网格本身,上下左右, t = t.repeat((5, 1, 1))[j] # t 的labels *3 ,7 offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j] #选出最近的3个网格(包含自己所以是3个) else: t = targets[0] offsets = 0 # Define 分配结果 #(xy预测输出不再是0-1,而是-1~1,加上offset=0.5偏移,则为-0.5-1.5;并且由于shape比规则,wh预测输出是0-4。因为宽和高设定的比例阈值就是4,self.hyp['anchor_t']=4,最大就是4,能到这里的都是满足阈值的。) b, c = t[:, :2].long().T #b: image索引, c:class gxy = t[:, 2:4] # grid xy 取XY值 gwh = t[:, 4:6] # grid wh 取WH值 gij = (gxy - offsets).long() #long()后可以当前targets lable 落到哪个网格上 gi, gj = gij.T # grid xy indices #转置拿到 网络indice 表示哪个网格是选好的正样本 # Append a = t[:, 6].long() # anchor indices a:当前box和当前层的第几个anchor匹配上 拿到索引 indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid indices tbox.append(torch.cat((gxy - gij, gwh), 1)) # box 添加真实框的中心点坐标相对于所在网格的偏移量,宽高,中心点减去网格索引坐标=实际偏移量 anch.append(anchors[a]) # anchors 加入anchor tcls.append(c) # class 加入类别ID return tcls, tbox, indices, anch
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
V5的代码极其简洁,这样的策略使得其gt box的匹配范围从3到9个,增加很多正样本提高了收敛速度和召回率,那么是不是正因为此?所以这样做是否有利有弊,因为同时可能引进了一些低质量的正样本,是否降低了性能,(事实就是,MUTILI-POSitive的策略是非常好实用的暴力美学)ASFF在有限的数据集下,很难拟合去提升性能.如果需要大量数据的补充,那么我觉得这个改动是毫无意义的,后面的BIFPN也许会更好!这里留下一个疑问。还有就是该篇有点上头,死磕骨干的改进,其实还有一个比较明显的问题就是分类和回归的低相关性也是检测的老大难问题,彼此独立又彼此干扰!这个先不细说,后面我会进行head和损失改进再分享 。**
还有,包含类似Botnet的transformer替换Bottleneck我也是打算尝试以及小目标在data 上的改进trick 等等。但是目前,还是将以上方法改动还需要做更深入的研究和实验。
可以参考我的yolov5 git改动,一起研究哈
目前介绍的这两个改动目前来看并没有做到提升,我还需要一定时间在大数据集上训练,也许是我用的不对也许是需要更多的trick,即使我昨天用了最新的ECA 模块,(还没正式实验),明明理论支持的东西我使用起来,达不到效果,这点确实难受,就是当你准备好了具备其原理和可解释性的东西,再组合的时候并没有如某开源某顶会的效果,那么就反手打脸,到底是理论不行还是没用对?(也许不见得,比如增多探测头再实验)特别对于一个工作了的人,花费时间和精力去尝试,且不属于自己的工作任务也不是跳槽要刷的编程题,费力不讨好的事情为什么?也许就是兴趣使然,自从工作以后,学习CV的热情只增不减!后面我还做了不少改动和trick修改的思路设计,逐一实现验证。最后,我觉得即使没有99%的功劳,也没有1%的功劳,但是我也有1%的苦劳啊~后续持续更新!!!!!!!!!!!!!!!!


