
- 1《STM32 HAL库》中断相关函数详尽解析——外部中断服务函数
- 2Stable Diffusion——stable diffusion基础原理详解与安装秋叶整合包进行出图测试
- 3第二弹!又来5个Jupyter Notebook使用技巧!
- 4Spring框架中涉及的设计模式_spring 代码设计
- 5探索 StableDiffusion:生成高质量图片学习及应用
- 6前端面试八股文 - 面试必备_前端八股文面试题2023
- 7测试老鸟分享:掌握2项技能,轻松拿到软件测试工程师offer...
- 8缓存相关问题:雪崩、穿透、预热、更新、降级的深度解析
- 9Kimi创始人套现4000万美元疑云|「商汤」大模型一体机可节约80%推理成本,完成云端边全栈布局|中国AI活化石,熬成AIGC第一股| 谁在制造小米汽车?_商汤 kimi
- 10微信小程序 java ssm 17.微信小程序跑腿平台的设计与实现(完整源码+数据库文件+万字文档+保姆级视频部署教程+配套环境)
深度学习实战6-卷积神经网络(Pytorch)+聚类分析实现空气质量与天气预测_pca = pca(n_components=2) new_pca = pd.dataframe(p
赞
踩
文章目录
一、前期工作
- 导入库包
- 导入数据
- 主成分分析(PCA)
- 聚类分析(K-means)
二、神经网络模型建立
三、检验模型
大家好,我是微学AI,今天给大家带来一个利用卷积神经网络(pytorch版)实现空气质量的识别分类与预测。
我们知道雾霾天气是一种大气污染状态,PM2.5被认为是造成雾霾天气的“元凶”,PM2.5日均值越小,空气质量越好.
空气质量评价的主要污染物为细颗粒物(PM2.5)、可吸入颗粒物(PM10)、二氧化硫(SO2)、二氧化氮(NO2)、臭氧(O3)、一氧化碳(CO)等六项。
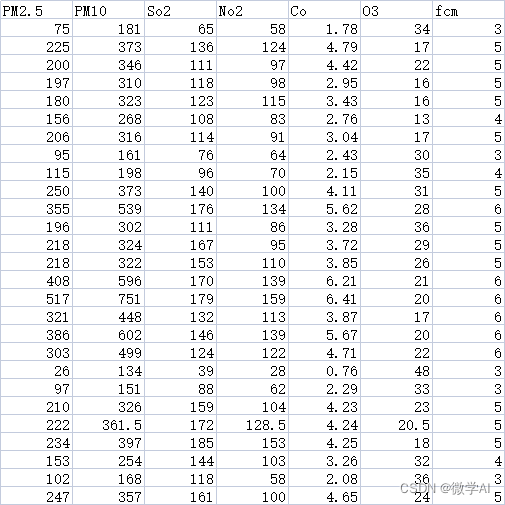
现在我们收集了多个城市的天气指标数据,数据样例如下:
一、前期工作
1. 导入库包
import torch
import torch.nn as nn
import torch.utils.data as Data
import numpy as np
import pymysql
import datetime
import csv
import time
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
2. 导入数据
data =pd.read_csv("weather.csv",encoding='gb18030')
data = data.drop(columns=data.columns[-1])
print(data)
- 1
- 2
- 3
3. 主成分分析(PCA)
天气数据中变量有6个,这增加分析问题的难度与复杂性,而且数据中多个变量之间是具有一定的相关关系的。 因此,我们想到能否在相关分析的基础上,用较少的新变量代替原来较多的旧变量,这里就采用了主成分分析原理(PCA),PCA的基本思想就是降维。下面代码将原理6个变量通过变化映射成两个新变量。
pca = PCA(n_components=2)
new_pca = pd.DataFrame(pca.fit_transform(data))
X = new_pca.values
print(new_pca)
- 1
- 2
- 3
- 4
4. 聚类分析(K-means)
K-means是一种迭代求解的聚类分析算法,主要步骤是:我们将设定分组类K,系统随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。每分配一个样本,聚类的聚类中心会根据聚类中现有的对象重新计算。这个过程将不断重复直到满足某个终止条件。聚类算法这边直接调用sklearn.cluster中的KMeans算法。当数据没有类别标注的时候,我们可以采用无监督学习聚类分析进行标注每条数据的簇类。
kms = KMeans(n_clusters=6) # 6表示聚类的个数
#获取类别标签
Y= kms.fit_predict(data)
data['class'] = Y
data.to_csv("weather_new.csv",index=False) #保存文件
#绘制聚类发布图
d = new_pca[Y == 0]
plt.plot(d[0], d[1], 'r.')
d = new_pca[Y == 1]
plt.plot(d[0], d[1], 'g.')
d = new_pca[Y == 2]
plt.plot(d[0], d[1], 'b.')
d = new_pca[Y == 3]
plt.plot(d[0], d[1], 'y.')
d = new_pca[Y == 4]
plt.plot(d[0], d[1],'c.')
d = new_pca[Y == 5]
plt.plot(d[0], d[1],'k.')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
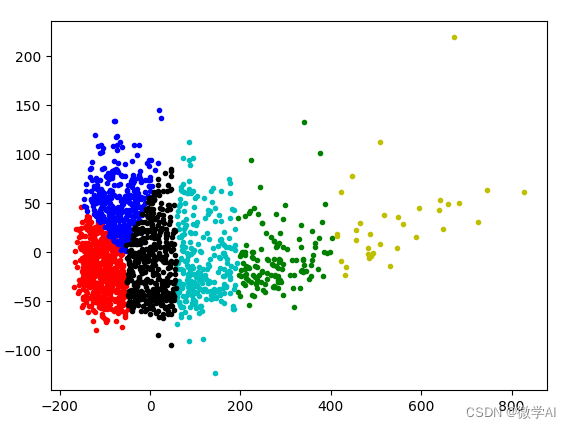
图中将数据用不同颜色分为6类,从图中可直观得看到数据位置相近的分为一类。
二、神经网络模型建立
class MyNet(nn.Module):
def __init__(self):
super(MyNet, self).__init__()
self.con1 = nn.Sequential(
nn.Conv1d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.MaxPool1d(kernel_size=1),
nn.ReLU(),
)
self.con2 = nn.Sequential(
nn.Conv1d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.MaxPool1d(kernel_size=1),
nn.ReLU(),
)
self.fc = nn.Sequential(
# 线性分类器
nn.Linear(128*6*1, 128),
nn.ReLU(),
nn.Linear(128, 6),
# nn.Softmax(dim=1),
)
self.mls = nn.MSELoss()
self.opt = torch.optim.Adam(params=self.parameters(), lr=1e-3)
self.start = datetime.datetime.now()
def forward(self, inputs):
out = self.con1(inputs)
out = self.con2(out)
out = out.view(out.size(0), -1) # 展开成一维
out = self.fc(out)
return out
def train(self, x, y):
out = self.forward(x)
loss = self.mls(out, y)
self.opt.zero_grad()
loss.backward()
self.opt.step()
return loss
def test(self, x):
out = self.forward(x)
return out
def get_data(self):
with open('weather_new.csv', 'r') as f:
results = csv.reader(f)
results = [row for row in results]
results = results[1:1500]
inputs = []
labels = []
for result in results:
# one-hot独热编码
one_hot = [0 for i in range(6)]
index = int(result[6])-1
one_hot[index] = 1
labels.append(one_hot)
input = result[:6]
input = [float(x) for x in input]
inputs.append(input)
inputs = np.array(inputs)
labels = np.array(labels)
inputs = torch.from_numpy(inputs).float()
inputs = torch.unsqueeze(inputs, 1)
labels = torch.from_numpy(labels).float()
return inputs, labels
def get_test_data(self):
with open('weather_new.csv', 'r') as f:
results = csv.reader(f)
results = [row for row in results]
results = results[1500: 1817]
inputs = []
labels = []
for result in results:
label = [result[6]]
input = result[:6]
input = [float(x) for x in input]
label = [float(y) for y in label]
inputs.append(input)
labels.append(label)
inputs = np.array(inputs)
inputs = torch.from_numpy(inputs).float()
inputs = torch.unsqueeze(inputs, 1)
labels = np.array(labels)
labels = torch.from_numpy(labels).float()
return inputs, labels
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
三、训练模型
EPOCH = 100
BATCH_SIZE = 50
net = MyNet()
x_data, y_data = net.get_data()
torch_dataset = Data.TensorDataset(x_data, y_data)
loader = Data.DataLoader(
dataset=torch_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=2,
)
for epoch in range(EPOCH):
for step, (batch_x, batch_y) in enumerate(loader):
# print(step)
# print(step,'batch_x={}; batch_y={}'.format(batch_x, batch_y))
a = net.train(batch_x, batch_y)
print('step:',step,a)
# 保存模型
torch.save(net, 'net.pkl')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
开始训练:
step: 0 tensor(3.6822, grad_fn=<MseLossBackward0>)
step: 1 tensor(61.2186, grad_fn=<MseLossBackward0>)
step: 2 tensor(18.2877, grad_fn=<MseLossBackward0>)
step: 3 tensor(4.3641, grad_fn=<MseLossBackward0>)
step: 4 tensor(6.7846, grad_fn=<MseLossBackward0>)
step: 5 tensor(9.4255, grad_fn=<MseLossBackward0>)
step: 6 tensor(5.4232, grad_fn=<MseLossBackward0>)
step: 7 tensor(4.1342, grad_fn=<MseLossBackward0>)
step: 8 tensor(2.0944, grad_fn=<MseLossBackward0>)
step: 9 tensor(1.4549, grad_fn=<MseLossBackward0>)
step: 10 tensor(0.9372, grad_fn=<MseLossBackward0>)
step: 11 tensor(1.0688, grad_fn=<MseLossBackward0>)
step: 12 tensor(0.6717, grad_fn=<MseLossBackward0>)
step: 13 tensor(0.6158, grad_fn=<MseLossBackward0>)
step: 14 tensor(0.6889, grad_fn=<MseLossBackward0>)
step: 15 tensor(0.5306, grad_fn=<MseLossBackward0>)
step: 16 tensor(0.5781, grad_fn=<MseLossBackward0>)
step: 17 tensor(0.3959, grad_fn=<MseLossBackward0>)
step: 18 tensor(0.4629, grad_fn=<MseLossBackward0>)
step: 19 tensor(0.3646, grad_fn=<MseLossBackward0>)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
四、检验模型
# 加载模型
net = torch.load('net.pkl')
x_data, y_data = net.get_test_data()
torch_dataset = Data.TensorDataset(x_data, y_data)
loader = Data.DataLoader(
dataset=torch_dataset,
batch_size=100,
shuffle=False,
num_workers=1,
)
num_success = 0
num_sum = 317
for step, (batch_x, batch_y) in enumerate(loader):
# print(step)
output = net.test(batch_x)
# output = output.detach().numpy()
y = batch_y.detach().numpy()
for index, i in enumerate(output):
i = i.detach().numpy()
i = i.tolist()
j = i.index(max(i))
print('输出为{}标签为{}'.format(j+1, y[index][0]))
loss = j+1-y[index][0]
if loss == 0.0:
num_success += 1
print('正确率为{}'.format(num_success/num_sum))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
输出结果:
....
输出为3标签为3.0
输出为4标签为4.0
输出为5标签为5.0
输出为1标签为1.0
输出为3标签为3.0
输出为3标签为3.0
输出为3标签为3.0
输出为4标签为4.0
正确率为0.9495268138801262
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
模型预测结果为94.95%;
数据中字段“fcm”分类,表示数据的类别:
数字1表示:空气质量:优;
数字2表示:空气质量:良;
数字3表示:空气质量:轻度污染;
数字4表示:空气质量:中度污染,雾霾
数字5表示:空气质量:重度污染,雾霾
数字6表示:空气质量:严重污染,雾霾
数据集的获取私信我!后期有更精彩和更有深度的实战内容,敬请期待!
往期作品:
深度学习实战项目
3.深度学习实战3-文本卷积神经网络(TextCNN)新闻文本分类
4.深度学习实战4-卷积神经网络(DenseNet)数学图形识别+题目模式识别
5.深度学习实战5-卷积神经网络(CNN)中文OCR识别项目
6.深度学习实战6-卷积神经网络(Pytorch)+聚类分析实现空气质量与天气预测
9.深度学习实战9-文本生成图像-本地电脑实现text2img
10.深度学习实战10-数学公式识别-将图片转换为Latex(img2Latex)
11.深度学习实战11(进阶版)-BERT模型的微调应用-文本分类案例
12.深度学习实战12(进阶版)-利用Dewarp实现文本扭曲矫正
13.深度学习实战13(进阶版)-文本纠错功能,经常写错别字的小伙伴的福星
14.深度学习实战14(进阶版)-手写文字OCR识别,手写笔记也可以识别了
15.深度学习实战15(进阶版)-让机器进行阅读理解+你可以变成出题者提问
16.深度学习实战16(进阶版)-虚拟截图识别文字-可以做纸质合同和表格识别
17.深度学习实战17(进阶版)-智能辅助编辑平台系统的搭建与开发案例
18.深度学习实战18(进阶版)-NLP的15项任务大融合系统,可实现市面上你能想到的NLP任务
19.深度学习实战19(进阶版)-ChatGPT的本地实现部署测试,自己的平台就可以实现ChatGPT
…(待更新)

