
- 1代谢组数据分析四:功能分析
- 2一文读懂 Jmeter - 你以为Jmeter只能用来做压力测试?,2024最新腾讯软件测试面试分享
- 3使用VSCode快速提交Gitee_vscode提交gitee在com
- 4数据库管理-第179期 分库分表vs分布式(20240430
- 5windows下的qt配置ffmpeg6.0_ffmpeg6 qt
- 6【移动安全】MobSF联动安卓模拟器配置动态分析教程_开启system.vmdk可写入
- 7PyQt5 画图板_pyqt 绘图板
- 8flutter面试点(持续更新)_flutter 面试技术点
- 9数据结构------栈的介绍和实现
- 10gunicorn shell启动_sh脚本 启动gunicorn
最全数据湖Iceberg、Hudi和Paimon比较_数据湖框架对比(1),2024年最新Jetpack-MVVM高频提问和解答_paimon hudi
赞
踩

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
Paimon支持有限的schema变更。目前,框架无法删除列,因此 DROP 的行为将被忽略,RENAME 将添加新列,列类型只支持从短到长或范围更广的类型。
Self-defined schema objec:指数据湖是否自定义schema接口,以期跟计算引擎的schema解耦。这里iceberg是做的比较好的,抽象了自己的schema,不绑定任何计算引擎层面的schema。
在Hudi 0.11.0版本中,针对Spark 3.1、Spark 3.2版本增加了schema功能的演进。如果启用 set hoodie.schema.on.read.enable=true以后,我们可以对表列和对表进行一系列的操作。列的变更(增加、删除、重命名、修改位置、修改属性),表的变更(重命名、修改属性) 等。
5.其它功能
| 对比项 | Apache Iceberg | Apache Hudi | Apache Paimon |
|---|---|---|---|
| One line demo | Not Good | Medium | Good |
| Python Support | YES | NO | NO(不确定) |
| File Encryption | YES | NO | NO |
| Cli Command | NO | YES | YES |
One line demo:指的是,示例demo是否足够简单,体现了方案的易用性,Iceberg稍微复杂一点(我认为主要是Iceberg自己抽象出了schema,所以操作前需要定义好表的schema)。做得最好的其实是delta,因为它深度跟随spark易用性的脚步。
Python Support:Python支持,很多基于数据湖之上做机器学习的开发者会考虑的问题,Iceberg比较做的好。
File Encryption:出于数据安全的考虑,Iceberg还提供了文件级别的加密解密功能,这是其他方案未曾考虑到的一个比较重要的点。
Cli Command:命令行
6.商业公司支持
Apache Iceberg
Iceberg 在国内的厂商非常多,腾讯一马当先,是贡献者数量最多的团队,国内的字节 、网易也紧随其后,相比腾讯 Iceberg 和 Hudi 通吃的战略,阿里在 Iceberg 的投入就少了非常多,国外的贡献者也非常多,包括 Netflix、Apple 等等
Apache Hudi
Hudi 在国内的应用很广,包括国内的大厂阿里巴巴、腾讯、字节跳动和华为,国外的话主要是 Uber 和 Amazon。
Apache Paimon
2023 年 3 月 12 日,Flink Table Store 项目顺利通过投票,正式进入 Apache 软件基金会 (ASF) 的孵化器,改名为 Apache Paimon (incubating)。进入孵化器后,Paimon 得到了众多的关注,包括 阿里云、字节跳动、Bilibili、汽车之家、蚂蚁 等多家公司参与到 Apache Paimon 的贡献,也得到了广大用户的使用。
7.性能比较
7.1 Iceberg和Hudi比较
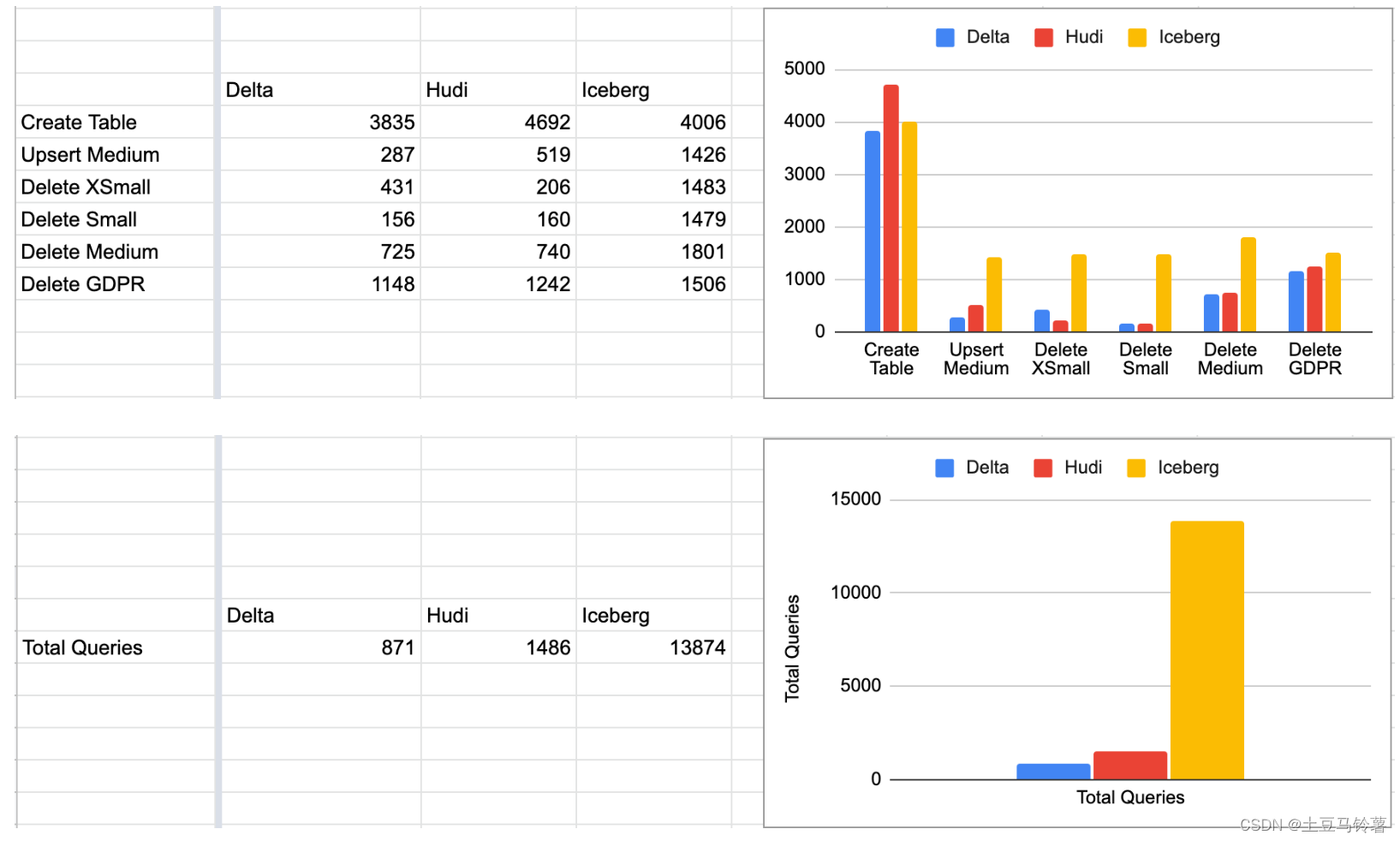
Brooklyn Data在 2022 年 11 月发布 Delta 与 Iceberg 的基准测试结果:Setting the Table: Benchmarking Open Table Formats
Onehouse 添加了 Apache Hudi,并在Brooklyn Github 代码库中发布了代码:https://github.com/brooklyn-data/delta/pull/2
测试结果见上图所示,Delta 和 Hudi 不相上下,Iceberg 落后并且还有一定的差距。
注意:在运行 TPC-DS 基准比较 Hudi、Delta 和 Iceberg 时,需要记住的一个关键点是,默认情况下 Delta + Iceberg 是针对仅追加的工作负载进行优化的,而 Hudi 默认情况下是针对可变工作负载进行优化的。默认情况下,Hudi 使用 "upsert "写模式,与插入相比,这种写模式自然会产生写开销。benchmarks 这个东西还是要以实际的业务场景测试为好,benchmarks 只能作为参考。
7.2 Hudi和Paimin比较
(1) Flink中文社区对Hudi和Paimon进行了性能比较,详细过程见:构建 Streaming Lakehouse:使用 Paimon 和 Hudi 的性能对比
直接说结论:
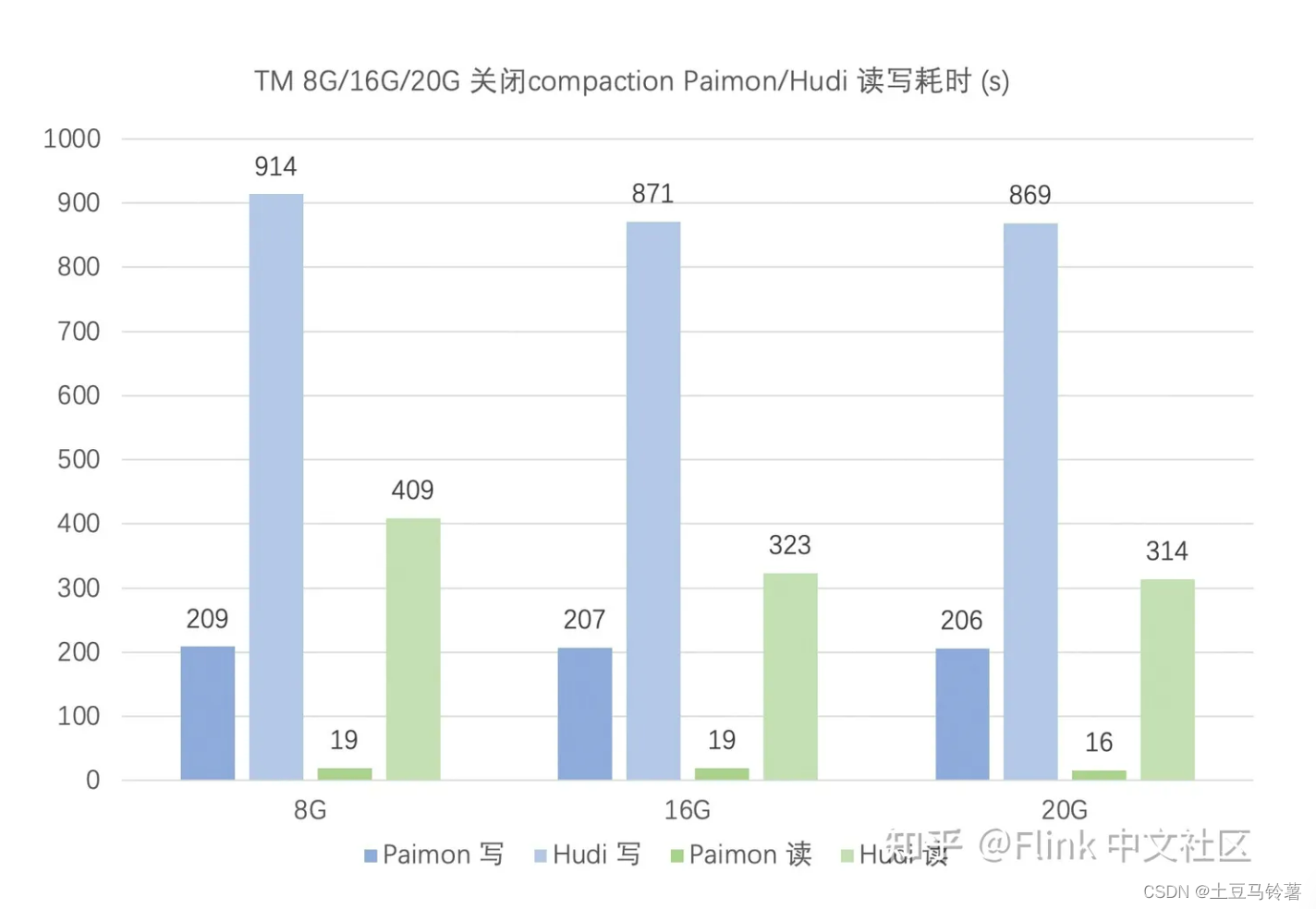
在 upsert 场景,关闭 compaction 时,Paimon 读写性能均优于 Hudi,且 Hudi 对 TM 的内存要求更高。
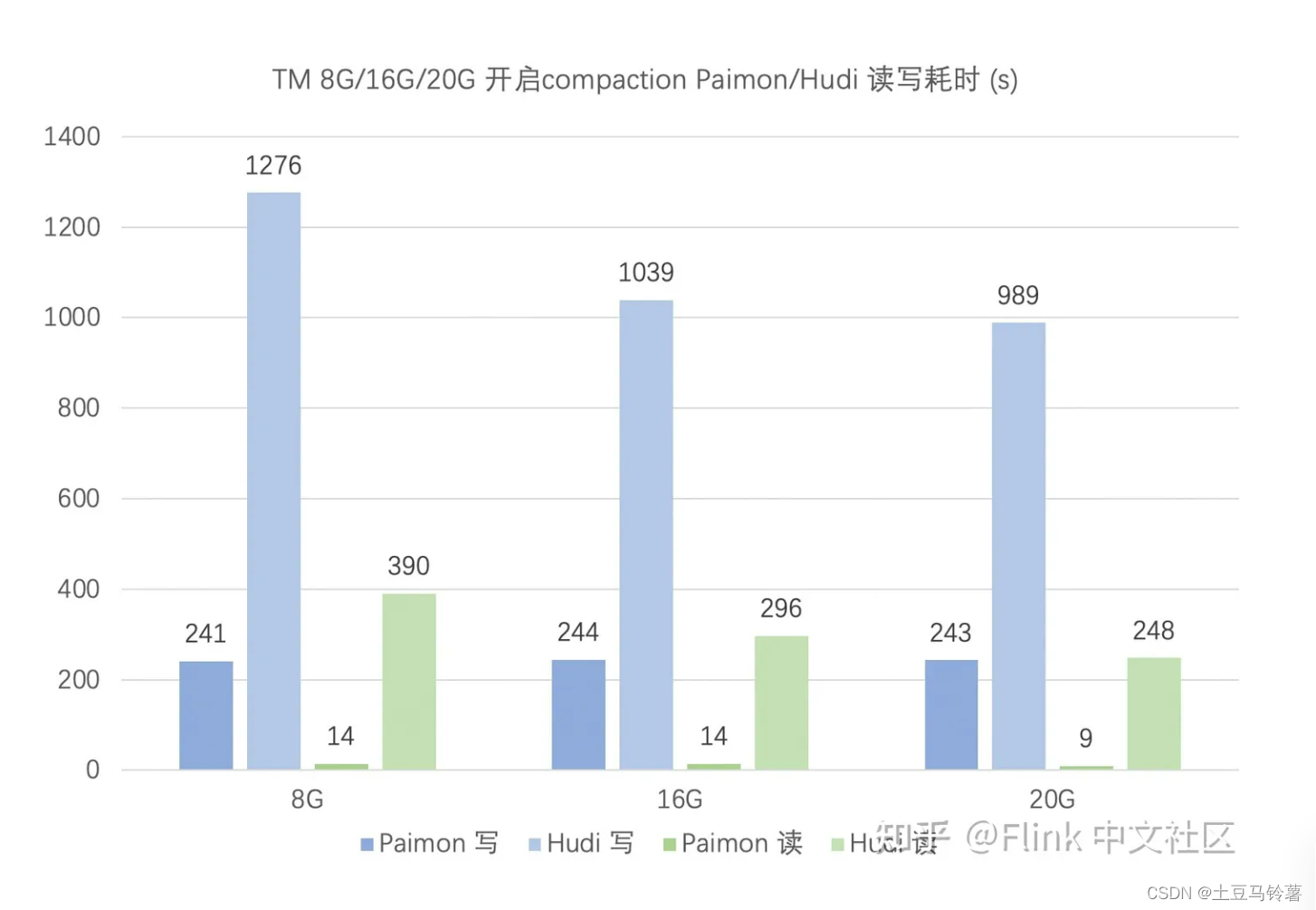
在 upsert 场景,开启 compaction 时,Paimon 读写性能均优于 Hudi。对比前面的关闭 compaction 测试,Paimon 和 Hudi 的写性能均有所下降,但读性能得到提升。
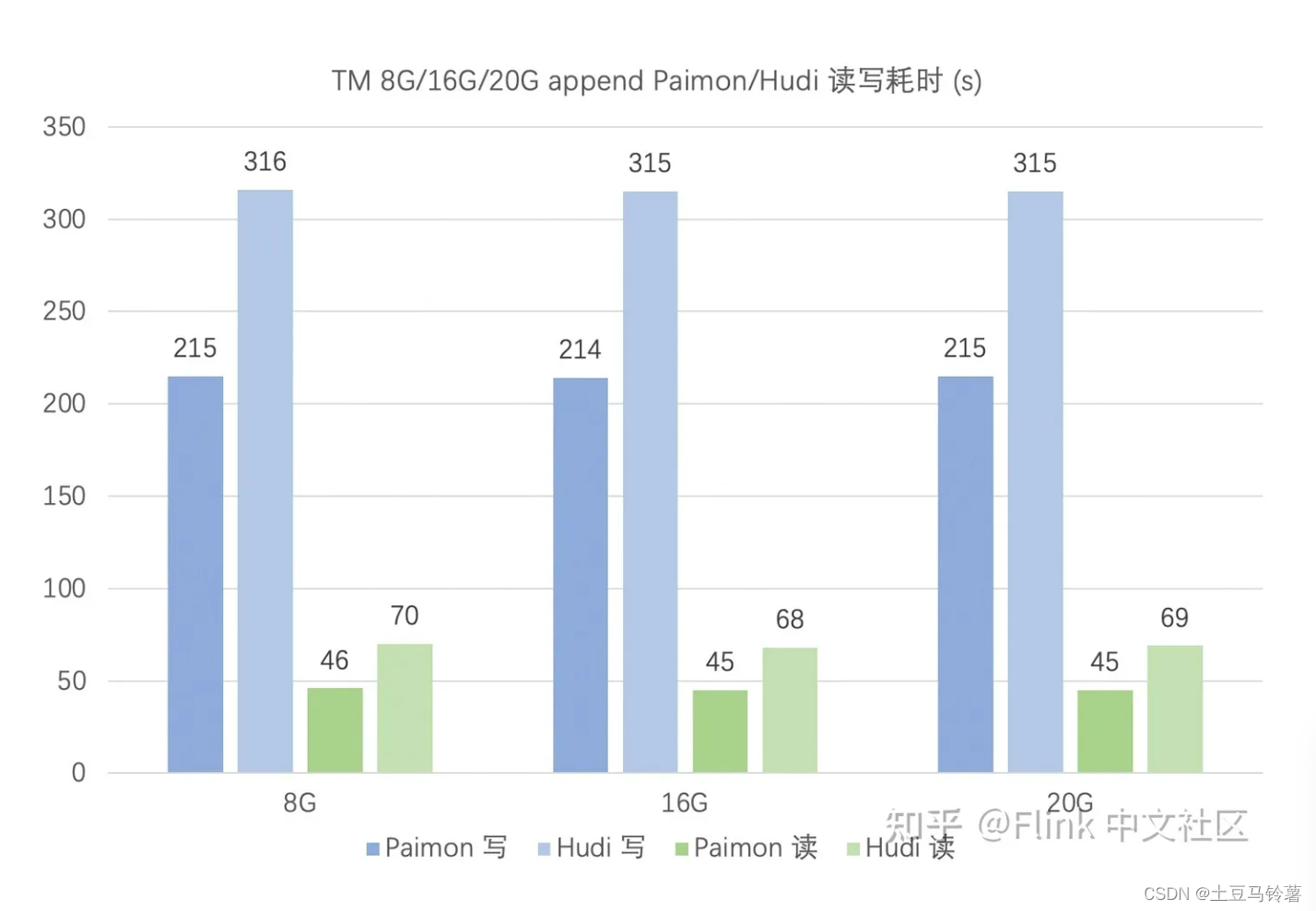
在 append 场景,Paimon 读写性能优于 Hudi,且二者都对 TM 内存要求均不高。
(2) 同程也对Hudi和Paimon进行了性能测试,详细内容见:Apache Paimon 在同程旅行的实践进展
同程在实践过程中,发现在全量+增量写入的场景中,相对 Hudi,Paimon 在相同计算资源的情况下,摄入的速度要优于 Hudi MOR 的摄入,大概有 3 倍左右的差距。查询场景下会更明显,在同样数据量的情况下,Paimon 的查询速度要优于 Hudi,大概有 7 倍左右的差距。
(3) 同时,一些开发人员对Flink 官方测试结果产生疑问,自己对也Hudi和Paimon进行了性能测试,具体过程见:Paimon VS Hudi 写入效率大PK
发现Paimon 的写入效率跟写入效果(文件数量),写入速度是 Hudi 的2倍多,而文件数量只有 Hudi数量的一半不到。对比Flink官方测试出来的,比 Hudi COW 表写入效率快12倍的结论,没有完全没有体现出来(测试的数据量不同)
实验测试结论为:Hudi 的MOR 表无论是写入速度,还是生成的文件数量,都要比 Paimon 优秀。而Hudi 的 COW 表,则正好相反,其无论写入速度,还是文件生成数量,则要比 Paimon 差,但这个差距,貌似在随着 checkpoint 时间的增大,逐渐在缩小。
8.总结
Apache Iceberg
Iceberg 社区基本盘还是在离线处理,它在国外的应用场景主要是离线取代 Hive,它也有强力的竞争对手 Delta,很难调整架构去适配 CDC 流更新。同时,Iceberg 扩展性强,对其它计算引擎也暴露的比较多的优化空间,但是这也导致后续的发展难以迅速,涉及到众多已经对接好的引擎。这并没有什么错,后面也证明了 Iceberg 主打离线数据湖和扩展性是有很大的优势,得到了众多国外厂商的支持。
Apache Hudi
Hudi 默认使用 Flink State 来保存 Key 到 FileGroup 的 Index,好处是全自动,想 Scale Up 只用调整并发就行了,坏处是性能差,直接让湖存储变成了实时点查,超过5亿条数据性能更是急剧下降。同时,存储成本也高,RocksDB State 保存所有索引。数据非常容易不一致,甚至再也不能有别的引擎来读写,因为一旦读写就破坏了 State 里面的 Index。
针对 Flink State Index 诸多问题,字节跳动的工程师们在 Hudi 社区提出了 Bucket Index 的方案,该解决方案好处是去除了 Index 带来了诸多性能问题。坏处是需要手动选取非常合适的 Bucket Number,多了小文件操作很多,少了性能不行。这套方案也是目前 Hudi 体量较大的用户的主流方案。
Hudi 当前存在的问题:
- Hudi 众多的模式让用户难以选择。
- 使用 Flink State 还是 Bucket Index?一个易用性好但是性能不行,一个难以使用。
- 使用 CopyOnWrite 还是 Merge On Read?一个写入吞吐很差,一个查询性能很差。
- 更新效率低,1-3 分钟 Checkpoint 容易反压,默认 5 次 Checkpoint 合并,一般业务可接受的查询是查询合并后的数据;全增量一体割裂,难以统一。
- 系统设计复杂,Bugs 难以收敛,工单层出不穷;各引擎之间的兼容性也非常差;参数众多。
Hudi 天然面向 Spark 批处理模式设计而诞生,不断在面向批处理的架构上进行细节改造,无法彻底适配流处理更新场景,在批处理架构上不断强行完善流处理更新能力,导致架构越来越复杂,可维护性越来越差。
Apache Paimon
Apache Paimon 最典型的场景是解决了 CDC (Change Data Capture) 数据的入湖。但是因为发展较晚,当前国内并没有主流的商业平台落地,对于批处理的性能也有待考量,仍需要一定的时间去完善和发展。以下为当前各版本支持情况:
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
很难做到真正的技术提升。**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

