
- 1LLM之RAG实战(十四)| 利用LongContextRetriver克服RAG中的中间丢失现象_langchain long-context reorder
- 2${pageContext.request.contextPath}不生效的问题_pagecontext.request.contextpath路径失效
- 3Docker(2):利用Docker搭建移动安全测试平台MobSF_mobile-security-framework-mobsf:latest docker
- 4手机端无线投屏技术及方案推荐_无线投屏器方案
- 5Spark机器学习——逻辑回归分类算法_逻辑回归 spark
- 6Credential Provider_credential provider 眼睛
- 7jsp+springboot+java二手车交易管理系统258u6
- 8Android Studio配置阿里云镜像地址,加速依赖资源下载_安卓sdk里面配置镜像加速
- 9Stable Diffusion本地部署报错解决:RuntimeError: Couldn‘t determine Stable Diffusion‘s hash: xxxxxxx_runtimeerror: couldn't fetch stable diffusion.
- 10matlab vgg图像风格迁移,GitHub - AaronJny/nerual_style_change: 使用VGG19迁移学习实现图像风格迁移。...
数据库管理-第179期 分库分表vs分布式(20240430
赞
踩
数据库管理-第179期 分库分表vs分布式(20240430)
作者:胖头鱼的鱼缸(尹海文)
Oracle ACE Associate: Database(Oracle与MySQL)
PostgreSQL ACE Partner
10年数据库行业经验,现主要从事数据库服务工作
拥有OCM 11g/12c/19c、MySQL 8.0 OCP、Exadata、CDP等认证
墨天轮MVP、认证技术专家、年度墨力之星,ITPUB认证专家、专家百人团成员,OCM讲师,PolarDB开源社区技术顾问,OceanBase观察团成员
圈内拥有“总监”、“保安”、“国产数据库最大敌人”等称号,非著名社恐(社交恐怖分子)
公众号:胖头鱼的鱼缸;CSDN:胖头鱼的鱼缸(尹海文);墨天轮:胖头鱼的鱼缸;ITPUB:yhw1809。
除授权转载并标明出处外,均为“非法”抄袭
趁着4月最后一天,再写一篇文章吧,给4月收个尾,顺便提前祝大家五一劳动节快乐,但还是要在这里批斗一下调休补班。
其实这篇文章的启发,来自于前几天一个去了某大厂做数据库的兄弟来电,和我讨论分库分表和分布式区别,以及分布式高可用方面的一些探讨,想着还是总结一下。
1 分库分表
其实在我看来吧,分库分表和分布式的界限挺模糊的,但二者的目的其实是差不多,即当数据量达到一定规模,业务并发无法由单机数据库承载,需要将数据与负载打散至若干数据库/服务器,以求用更小的个体在整体层面支撑更大的业务并发和数据量。
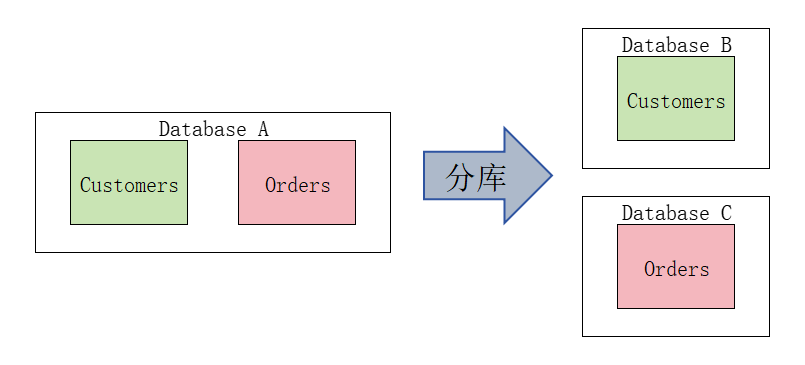
1.1 分库
其实分库很好理解,就是将不同的业务分在不同的数据库上:
1.2 分表
分表其实和分区表类似,把一张大表拆分成若干小表,这些小表既可以分散在一个数据库中,也可以分散在不同数据库中:
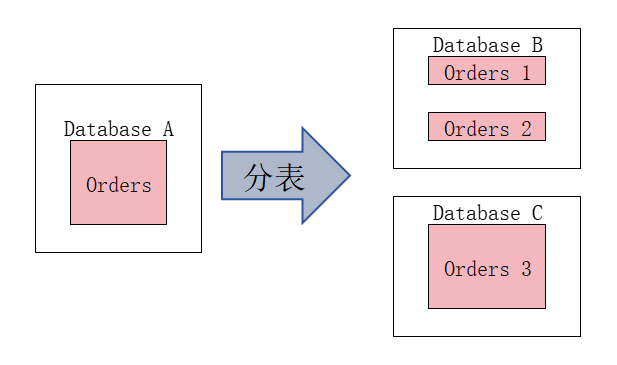
分表同样需要业务侧去阻止数据在不同数据库之间的分布,并根据业务需求到指定地方查询需要的数据。
1.3 组合
分库分表一般通过业务应用程序配置或使用数据库中间件(比如MyCAT)来实现,为了尽可能提高关联数据查询效能,可以将打散后不同业务的关联数据以某种约定的关联方式(主外键、表父子关系等)存放在同一数据库节点(或多个)内。
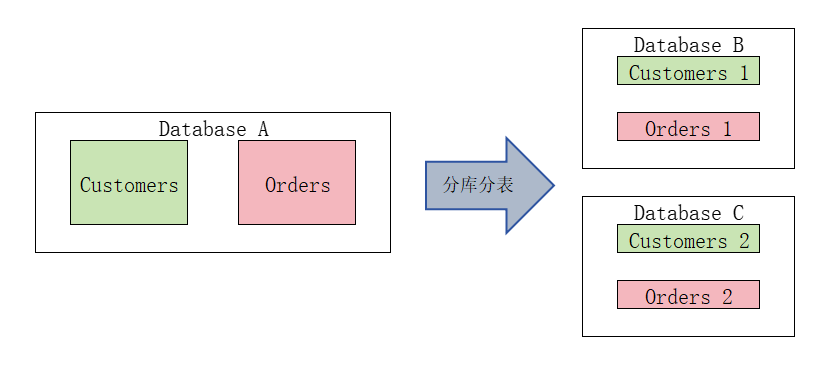
为何要这么做,其实无论是分库分表还是分布式,数据拆分之后,部分涉及跨数据分组或全局的查询,其实就是将传统数据库中放在内存中的计算部分通过网络去实现,而现在IT架构中网络是最不稳定的因素之一,同时高性能(高带宽、低延迟)的网络环境又是相对比较贵的。因此要尽可能将关联数据查询放在一块内存中实现;很多使用分库分表/分布式的地方,也要求业务逻辑简单,尽可能以点查为主。其余全局查询则使用搜索引擎或列存实现。
1.4 问题
- 对于数据库分散情况的元数据,往往需要在业务程序中或者数据库中间件之中配置好,不便于动态扩展或变更
- 其实仍为多个独立数据库运行,无法实现全局负载均衡、并行等功能
- 每个数据库需要自己维护高可用,使用主从或者多副本实现
- 备份困难
- 多模、HTAP依托使用的数据库本身,难以独立实现
- …
2 分布式
其实分布式,或者说叫原生分布式,其实和分库分表要实现的目标类似,但是又实现了其他一些由数据库本身实现的一些功能:
- 维护数据分散,包括元数据和路由等
- 实现部分与全局的高可用
- 实现全局执行计划生成
- 实现全局负载均衡、并行等功能
- 实现多模、HTAP等高级功能
3 常见分布式数据库
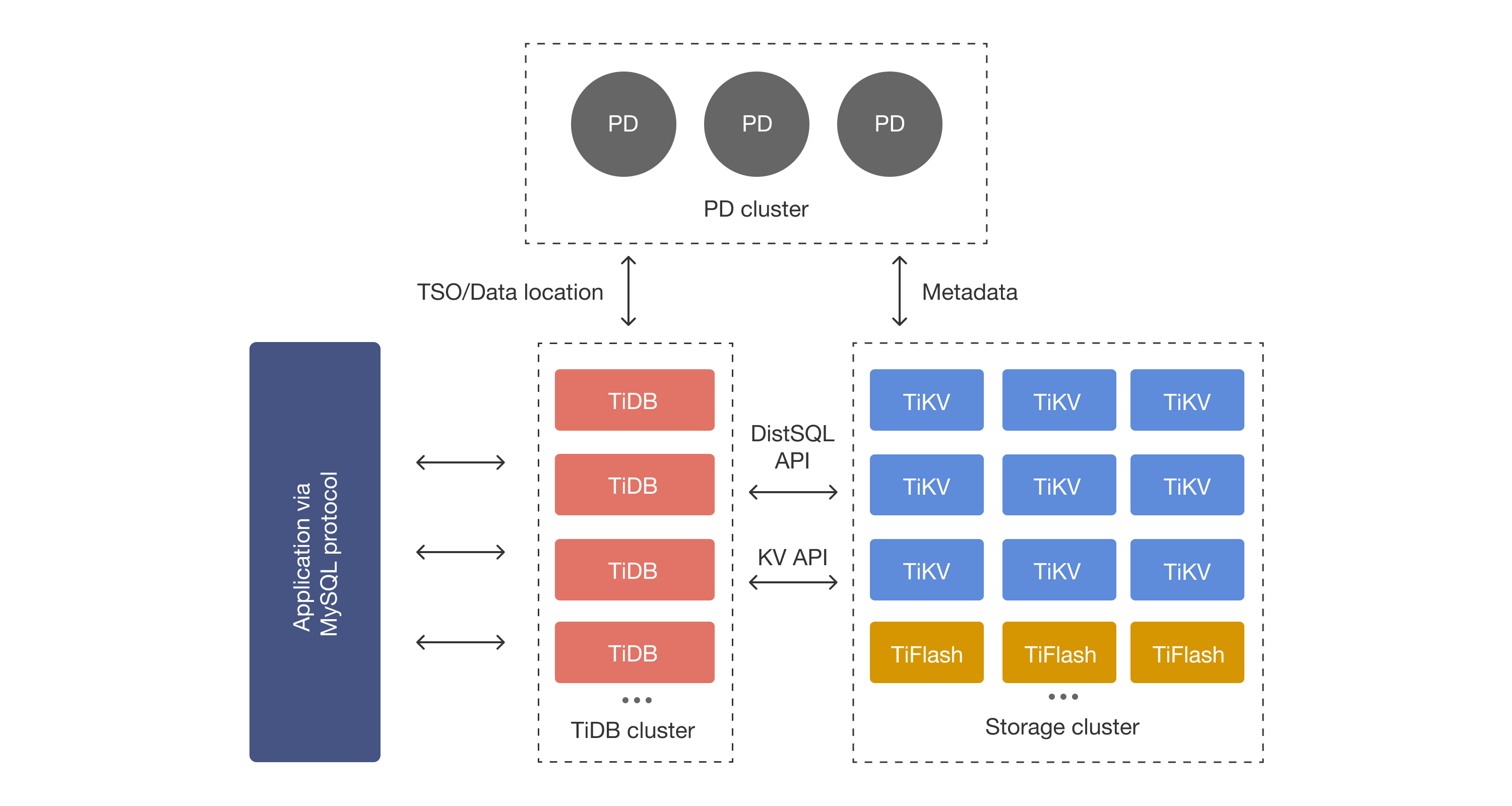
TiDB的架构倾向于存算分离架构,数据以分布式方式存放,通过PD维护元数据和数据路由,整体维护两套数据副本:TiKV用于OLTP,TiFlash实现OLAP(Online),整体实现HTAP(如果资源有限可以只上TiKV,TiFlash比较吃CPU资源,按需配置使用,TiFlash的数据由TiKV同步,相当于TiKV的列存只读副本-感谢严少安同学补充)。Storage Cluster本身维护自己的高可用,同时TiDB Cluster和PD Cluster都以多节点实现高可用。而计算层面从使用方式更倾向于集中式。
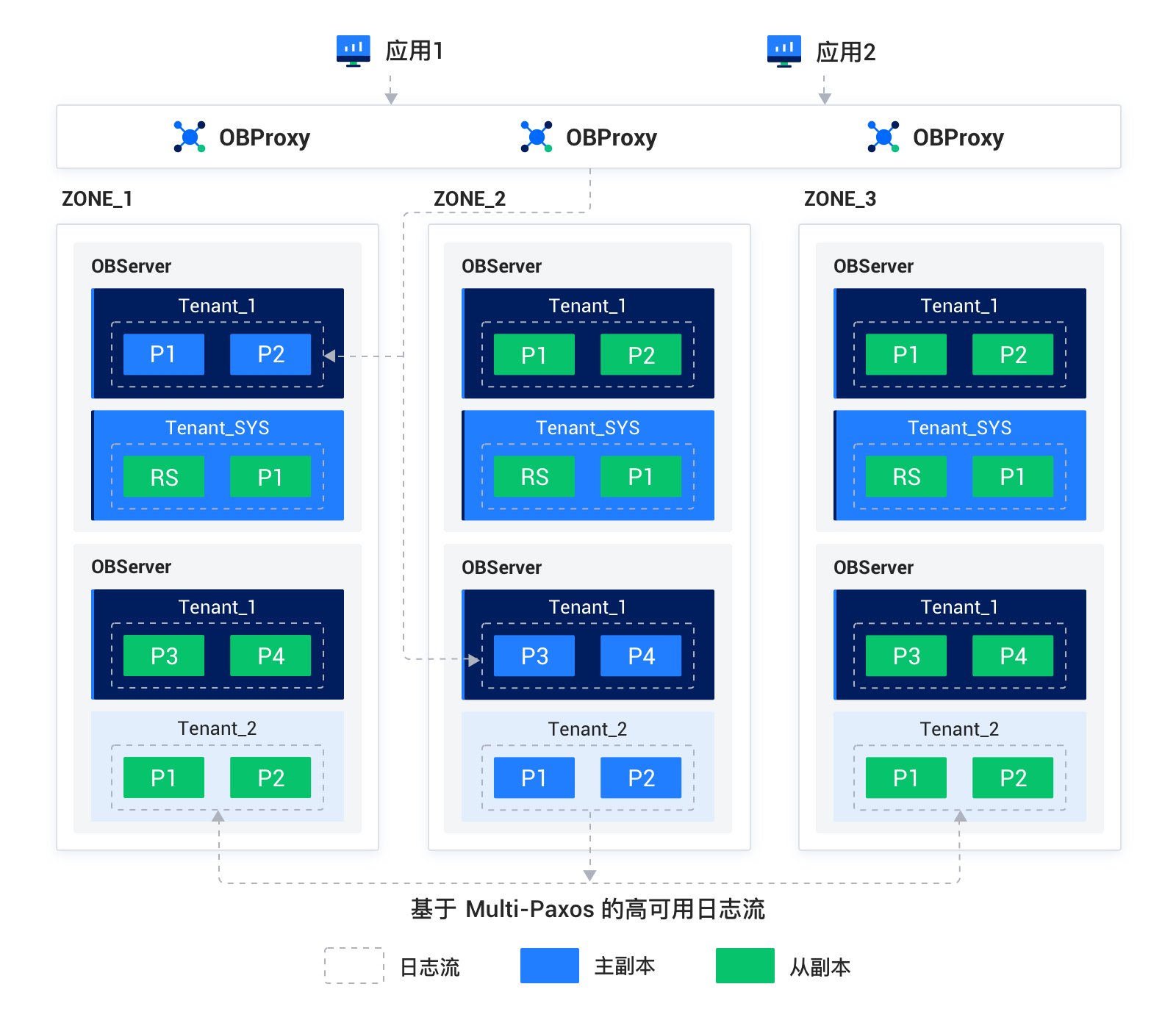
Oceanbase 4.3的架构则倾向于存算一体架构,数据库元数据存放在数据库的系统租户中。在每个OBServer中通过数据库内核实现行列混存、多模等功能,以实现HTAP和多模联查等功能。OBProxy则作为无状态服务,提供SQL分发能力。多个OBProxy节点通过网络负载均衡对应用提供统一的网络地址。租户的全局多副本实现了数据库的高可用。Oceanbase还通过引入租户模式,可以实现业务的拆分与隔离,通过对租户主可用区的规划,可以做到不同副本承载不同业务的负载。
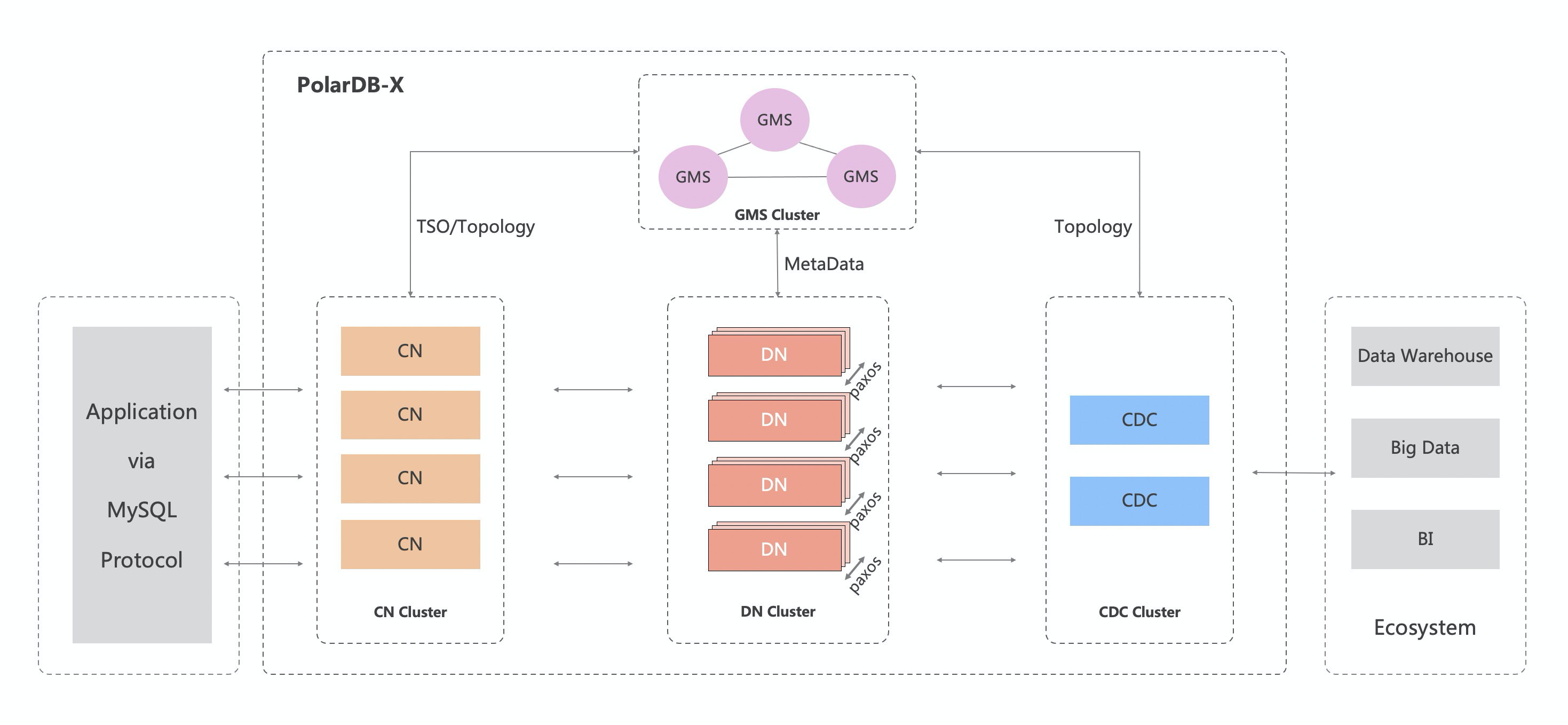
PolarDB-X则和TiDB的架构类似,但是相较于TiDB和Oceanbase使用的LSM Tree存储,PolarDB仍然以B-Tree存储。
4 期望
我希望在以后的分布式数据库能提供节点降级的能力:
- 当某节点磁盘故障:该节点的CPU、内存与网络资源仍能为集群提供相应能力;或者仅在本节点屏蔽损坏磁盘的相关数据使用
- 使用多链路网络的节点部分网卡故障:减少该节点的网络流量
- 节点部分CPU、内存故障:降低该节点负载分担
- …
我希望能通过这个功能,降低硬件异常对全局性能的影响,减少性能波动。
总结
本期简单讲了下分库分表和分布式的一些异同,也扩展了一下自己对分布式数据库的一些期望。
老规矩,知道写了些啥。

