
计算机视觉与音乐,Transformer又又来了,生成配有音乐的丝滑3D舞蹈,开放最大规模数据集AIST++...
赞
踩

出自论文:
Learn to Dance with AIST++: Music Conditioned 3D Dance Generation
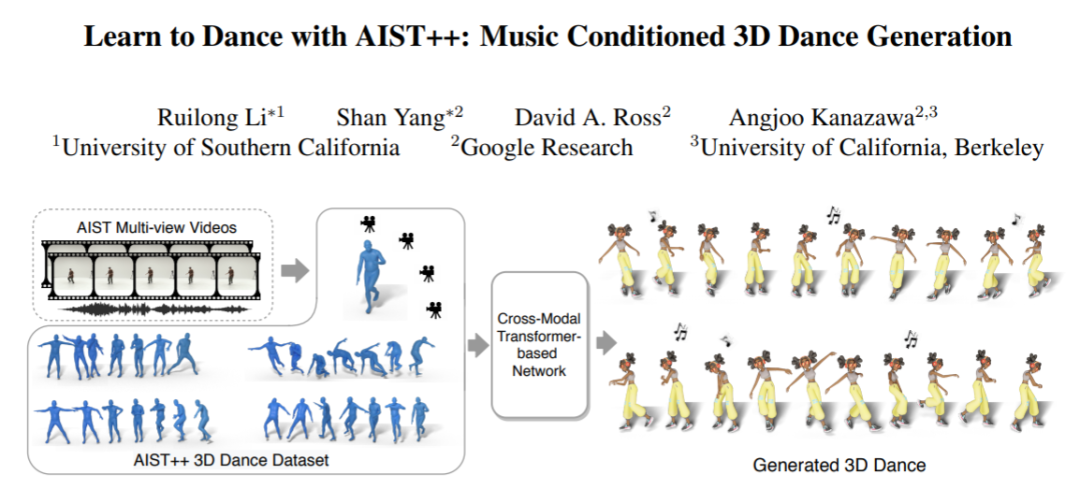
来自谷歌等单位的学者提出一个基于 transformer 的学习框架,用于以音乐为条件的3D舞蹈生成。设计了一个全新的网络框架,并验证得出获得高质量结果的关键。其中组件之一是深度跨模态 transformer,可以很好地学习音乐和舞蹈运动之间的相关性,并且具有 future-N 机制的全注意力在产生长距离 non-freezing 运动中至关重要。
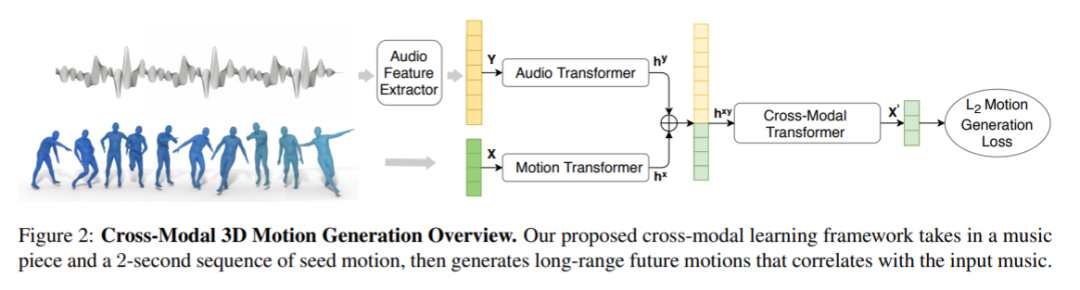
合成 demo:
AIST++ 数据集
AIST++ 舞蹈运动数据集是从 AIST Dance Video DB 构建的。对于多视角视频,设计一个完美的 pipeline 来估计摄像机参数、3D人体关键点和3D人体舞蹈运动序列。
提供了 10.1M 张图像的 3D 人体关键点标注和相机参数,涵盖 9 个视角的 30 个不同主体。以此成为现有的最大、最丰富的三维人体关键点标注数据集。
还包含了 1408 个三维人体舞蹈运动序列,以 joint rotations 和 root trajectories 一起的形式表示。舞蹈动作平均分布在 10 个舞蹈流派和数百个编排中。动作持续时间从7.4秒到48.0秒不等。所有的舞蹈动作都有相应的音乐。
通过以上的标注,AIST++ 支持以下任务。
多视角人体关键点估计
人体运动预测/生成
人体运动和音乐之间的跨模态分析
数据集以不同的方式被分割成训练/验证/测试集,用于不同的目的。
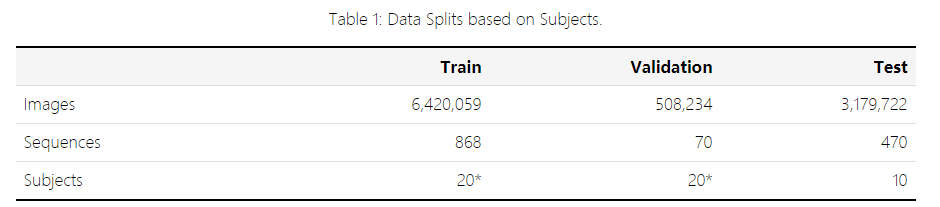
对于人类姿势估计和人类运动预测等任务,作者建议使用表 1 中描述的数据分割。
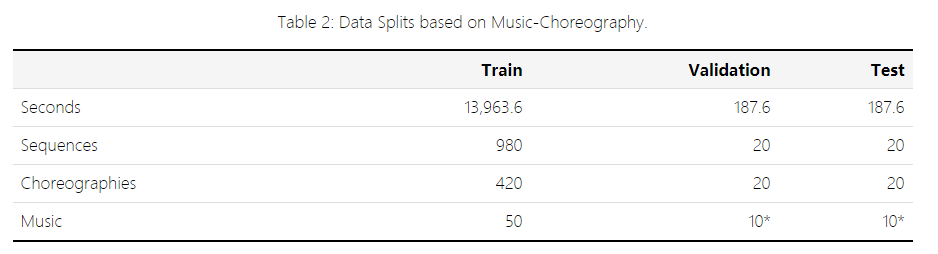
对于处理运动和音乐的任务,如音乐条件运动生成,建议使用表 2 中描述的数据分割。
作者 | Ruilong Li, Shan Yang, David A. Ross, Angjoo Kanazawa
单位 | 南加利福尼亚大学;谷歌;伯克利
论文 | https://arxiv.org/abs/2101.08779
数据集 | https://google.github.io/aistplusplus_dataset/
主页 | https://google.github.io/aichoreographer/
END

备注:TFM
Transformer交流群
讨论Transformer在CV领域的应用。
我爱计算机视觉
微信号:aicvml
QQ群:805388940
微博知乎:@我爱计算机视觉
投稿:amos@52cv.net
网站:www.52cv.net
在看,让更多人看到


