
- 1java--新建list 并赋值
- 2Vue3.0+Element-plus项目框架搭建(一):使用 vue-cli 创建项目_python + vue3 + element-plus + vuecli
- 3FastChat(小羊驼模型)部署体验
- 4Linux:vi的插入模式下退格和方向键不能使用的解决方法_linux vim输入模式方向键不能使用
- 5R语言入门笔记_r语言 mtext line
- 6Openstack-Glance镜像服务的基本使用_linux怎么安装上传cirros镜像
- 7Unity3D LOD Group_unity lodgroup.getlods
- 8Elasticsearch搜索辅助功能解析(十)_sourcebuilder.fetchsource
- 9Torch not compiled with CUDA enabled报错的解决办法
- 10分享一个德州扑克的算法
07 目标检测-YOLO的基本原理详解_理解yolo的原理
赞
踩
说明:撰写此篇文章花费了14天实际,同时此篇文章是作为学习和理解后自己整理的一篇内容,并不是专业的论文内容阐述,仅供大家参考和学习使用,在其中可能有部分不足或错误,请各位路过或专业大神进行留言,我们一起探讨研究,并完善此文章。
为了能够更好的理解-YOLO的基本原理讲解过程,建议先将以下内容大概看一下, 对与理解YOLO的基本原理会更有帮助。
目录
1、原始图片resize到448x448,图片分成7x7个网格(grid cell)
01、输入图图像,将输入图像划分为网格形式(例如3 X 3)
一、YOLO的背景及分类模型
1、YOLO的背景
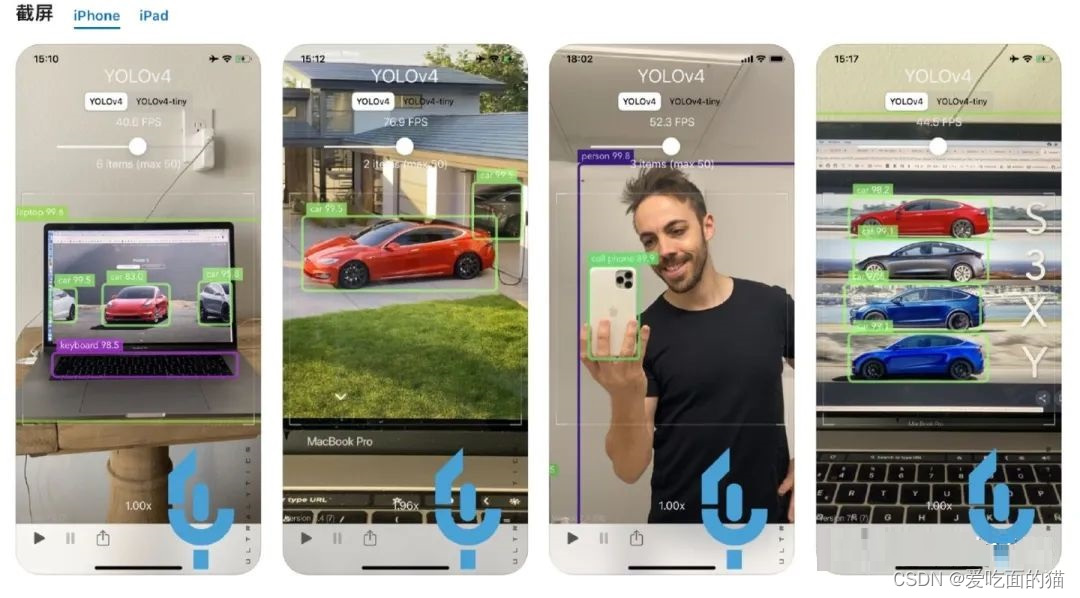
上图中是手机中的一个app,在任何场景下(工业场景,生活场景等等)都可以试试这个app和这个算法,这个app中间还有一个button,来调节app使用的模型的大小,更大的模型实时性差但精度高,更小的模型实时性好但精度差。
而YOLO v5其实一开始是以这一款app进入人们的视野的,就是上图的这个,叫:i detection(图上标的是YOLO v4,但其实算法是YOLO v5),值得一提的是,这款app就是YOLO v5的作者亲自完成的。
读到这里,你觉得YOLO v5的最大特点是什么?
答案就是:一个字:快,应用于移动端,模型小,速度快。
我们再看一张图:
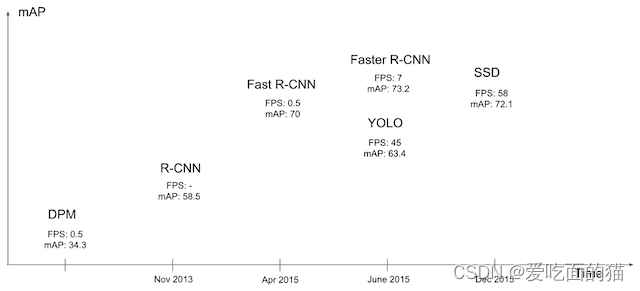
从图中可以看出YOLO的最大特点是速度快。YOLO在精度上仍然落后于目前最先进的检测系统。虽然它可以快速识别图像中的目标,但它在定位某些物体尤其是小的物体上精度不高。进入到真正端到端的目标检测:直接在网络中提取特征来预测物体分类和位置。因此YOLO的主要特点:
- 速度快,能够达到实时的要求。在 Titan X 的 GPU 上 能够达到 45 帧每秒。
- 使用全图作为 Context 信息,背景错误(把背景错认为物体)比较少。
- 泛化能力强。
2、分类模型
在进入目标检测任务之前首先得学会图像分类任务,这个任务的特点是输入一张图片,输出是它的类别。
对于输入图片,我们一般用一个矩阵表示。
对于输出结果,我们一般用一个one-hot vector表示: 【0,0,1,0,0,0】 ,例如我们有6个类别(猫、狗、人、马、鸡、猪),哪一维是1(人这一维是1),就代表图片属于哪一类(人)。
所以,在设计神经网络时,结构大致应该长这样:

这里的cbrp指的是conv,bn,relu,pooling的串联。
由于输入要是one-hot形式,所以最后我们设计了2个fc层(fully connencted layer),我们称之为“分类头”或者“决策层”。
二、YOLO系列思想的雏形:YOLO v0
1、框的表示方式
-
x,y,w,h(如图)
-
p1,p2,p3,p4(4个点坐标)
-
cx,cy,w,h(cx,cy为中心点坐标)
-
x,y,w,h,angle(还有的目标是有角度的,这时叫做Rotated Bounding Box)
-
......

所以框Bounding Box表示的方法很多,但输出的结果一定是一个vector。
2、分类器和检测器
上面我提到了分类器模型用来分类,分类器的输出是一个one-hot vector,而检测器的输出是一个框(Bounding Box),也是一个向量,是我们标注的结果。但二者的共同特点是结果都是向量。因此分类模型可以用来做检测,用分类模型可以把检测的任务当做是遍历性的分类任务,只是输出的结果是一个个one-hot vector而已。
3、遍历性的分类任务
如何遍历?首先我们先预设一个框的大小,然后在图片上用这个框遍历,每遍历1次,都对边框的区域进行二分类:属于脸或者不属于脸。

这种方法其实就是RCNN全家桶的初衷,专业术语叫做:滑动窗口分类方法。
但问题是:检测的耗时非常大。
4、改进思路
既然分类器输出一个one-hot vector:【0,0,1,0,0,0】,那我们把它换成(x,y,w,h,c),c表示confidence置信度,此时输出是Bounding Box的位置(x,y,w,h,c),因此就把检测问题转化成一个回归问题,而分类器也就可以变成了一个检测器。因此分类器变化如下:


此时我们会发现,这种方法比刚才的滑动窗口分类方法简单太多了。这一版的思路我把它叫做YOLO v0,因为它是You Only Look Once最简单的版本。
因此YOLO的核心思想就是利用整张图作为网络的输入,直接在输出层回归bounding box的位置和bounding box所属的类别。
5、YOLO v0的进化(YOLO v1)
5.1、问题分析
YOLO v0只能输出一个目标,那比如下图多个目标怎么办呢?为了保证所有目标都被检测到,我们应该输出尽量多的目标。所以我们的模型需要进行改进。


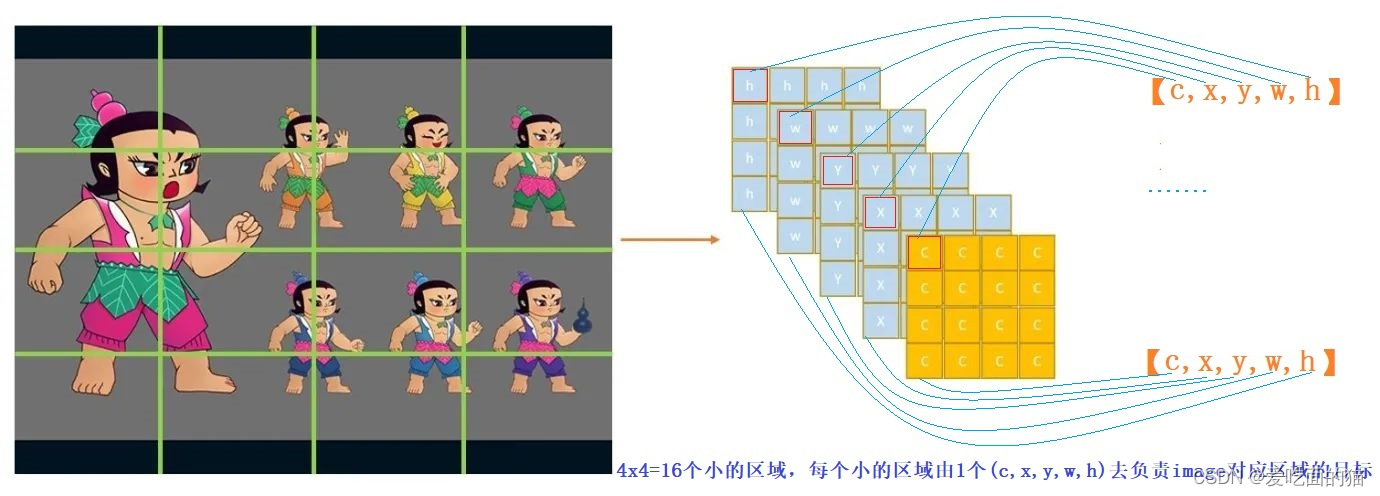
我们进一步的改进,让每个(c,x,y,w,h)去负责image某个区域的目标。因此我们需要对图片进行区域划分,如上图中我们可以将图片划分成4x4=16个小的区域,每个小的区域由1个(c,x,y,w,h)去负责image对应区域的目标。
因为conv操作是位置强相关的,原来的目标在哪里,卷积之后的feature map上还在哪里,所以图片划分为16个区域,结果也应该分布在16个区域上,所以我们的结果(Tensor)的维度size是:(5,4,4)。如下图所示:
5.2、c的真值设置
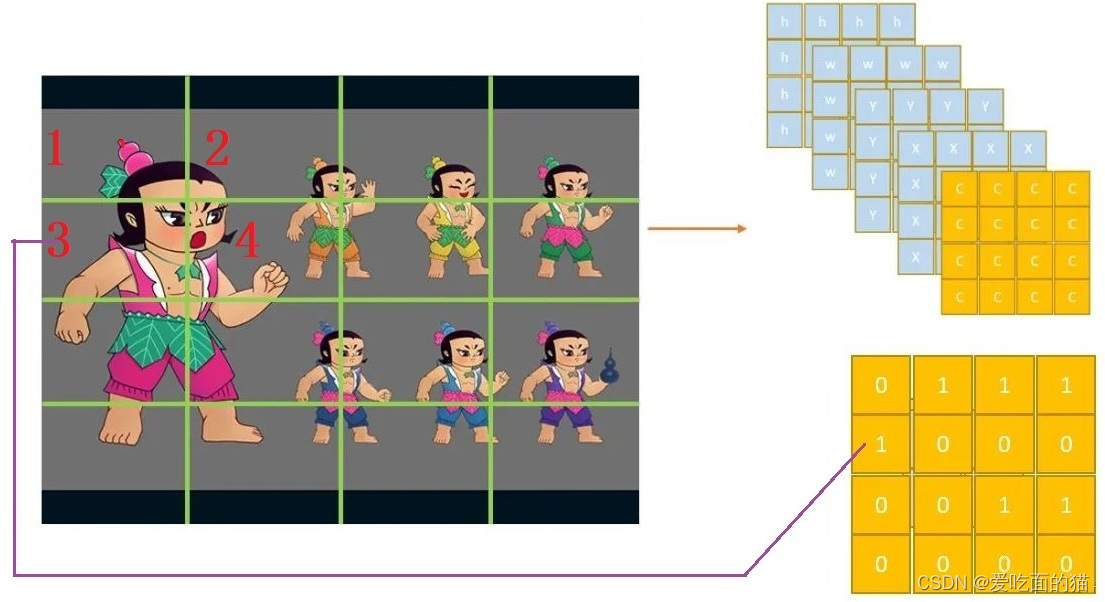
c的真值如何设置呢?c的真值取决于区域的中心点,如大娃脸部跨了4个区域(grid),但4个区域(grid)只能某一个grid的c=1,其他的3个区域c=0。那么该让哪一个grid的c=1呢?就看他的脸的中心落在了哪个grid里面。根据这一原则,c的真值为下图所示:
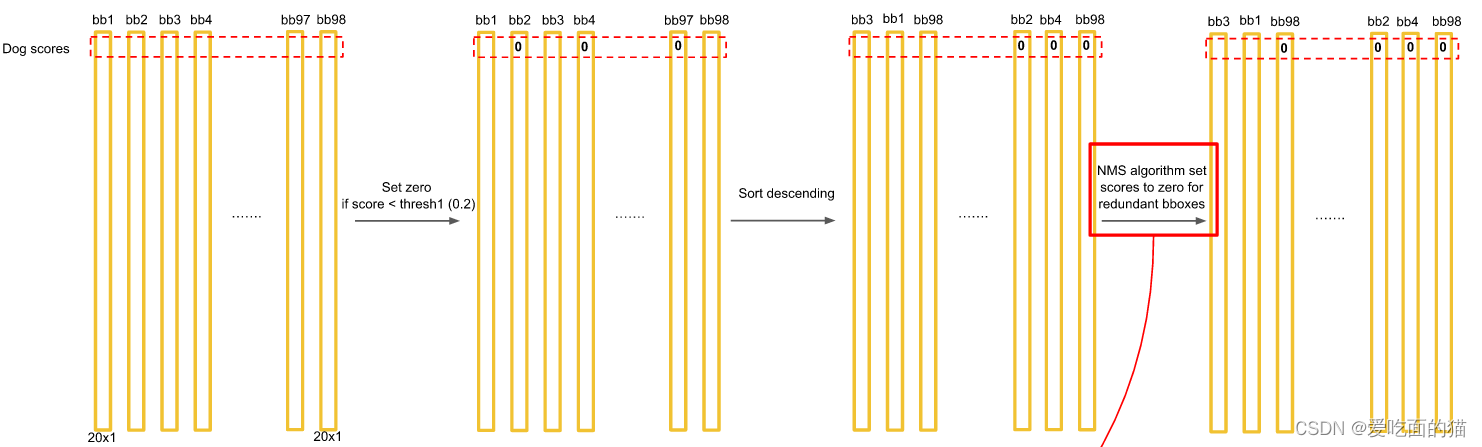
5.3、NMS(非极大值抑制)
上图中会发现7个葫芦娃,c的真值只有6个1,原因是第三行第三列的grid有2个目标。如何解决一个区域有多个目标的情况?
解决方案:
NMS(非极大值抑制)解决多目标检测。2个框重合度很高,大概率是一个目标,那就只取一个框。重合度的计算方法:交并比IOU=两个框的交集面积/两个框的并集面积。(推荐)
或者使用聚类,但聚类容易将2个目标本身比较近聚成了1个类。(不推荐)
或者细化网格:将网格细化,如将 4x4 区域变成 40x40 或者更大,使区域更密集,就可以缓解多个目标的问题,但无法从根本上去解决。(不推荐)
5.4、多类的目标
上面我将一直讲的是单类目标,如检测葫芦娃的脸,如果是多类目标如检测葫芦娃的脸,且检测葫芦,此时我们的设计改变为如下,多个类的问题也解决了。

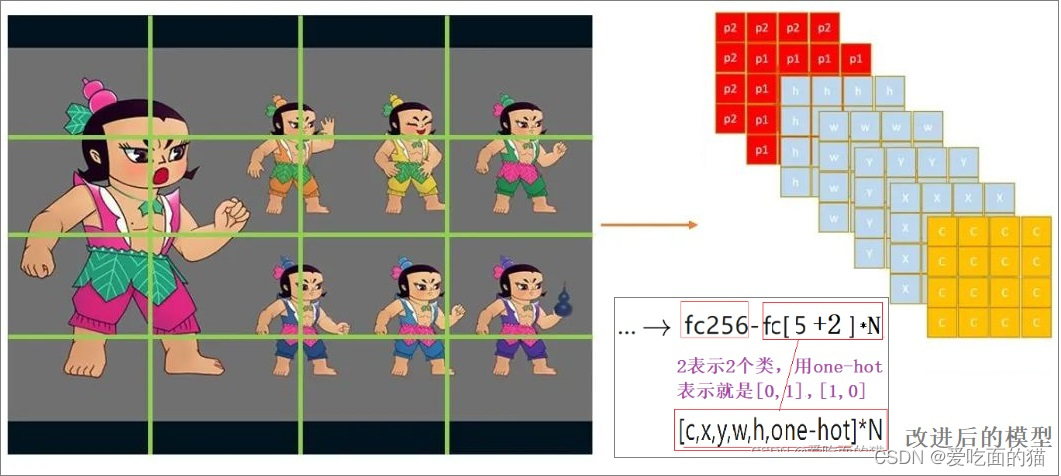
5.5、小目标检测
小目标总是检测不佳,所以我们专门设计神经元去拟合小目标。对于每个区域,我们用2个五元组(c,x,y,w,h),一个负责回归大目标,一个负责回归小目标,同样添加one-hot vector,one-hot就是[0,1],[1,0]这样子,来表示属于哪一类(葫芦娃的头or葫芦娃的葫芦)。此时设计的检测器其实就是YOLO v1思路,只是参数不同。
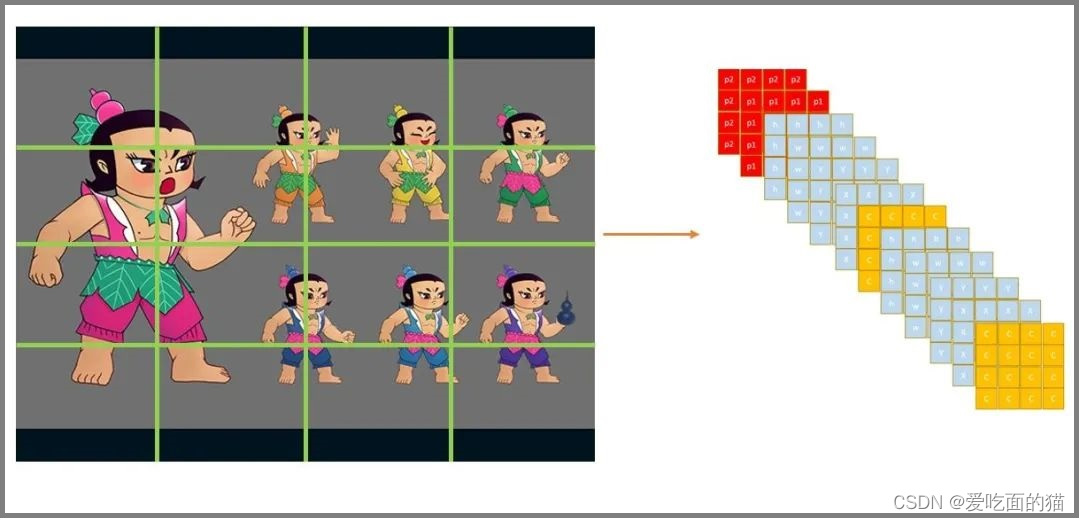
三、YOLO核心思想
YOLO是一种新的目标检测方法。以前的目标检测方法通过重新利用分类器来执行检测。后来使用深度学习算法,从R-CNN到Fast R-CNN一直采用的思路是proposal+分类 (proposal 提供位置信息, 分类提供类别信息)精度已经很高,但是速度还不行。
YOLO提供了另一种更为直接的思路: 直接在输出层回归bounding box的位置和bounding box所属的类别(整张图作为网络的输入,把 Object Detection 的问题转化成一个 Regression 问题)。
YOLO将目标检测看作回归问题,从空间上定位边界框(bounding box)并预测该框的类别概率。使用单个神经网络,在一次评估中直接从完整图像上预测边界框和类别概率。由于整个检测流程仅用一个网络,所以可以直接对检测性能进行端到端的优化。
四、YOLO算法系列的演变过程
YOLO算法系列的演变过程:YOLO->YOLO9000->YOLOv2->YOLOv3

五、YOLO结构
YOLO整体结构就是三部分组成:GoogleNet+4个卷积+2个FC,思路彩用的就是上面YOLO v0的进化思路,只是参数不同而已。
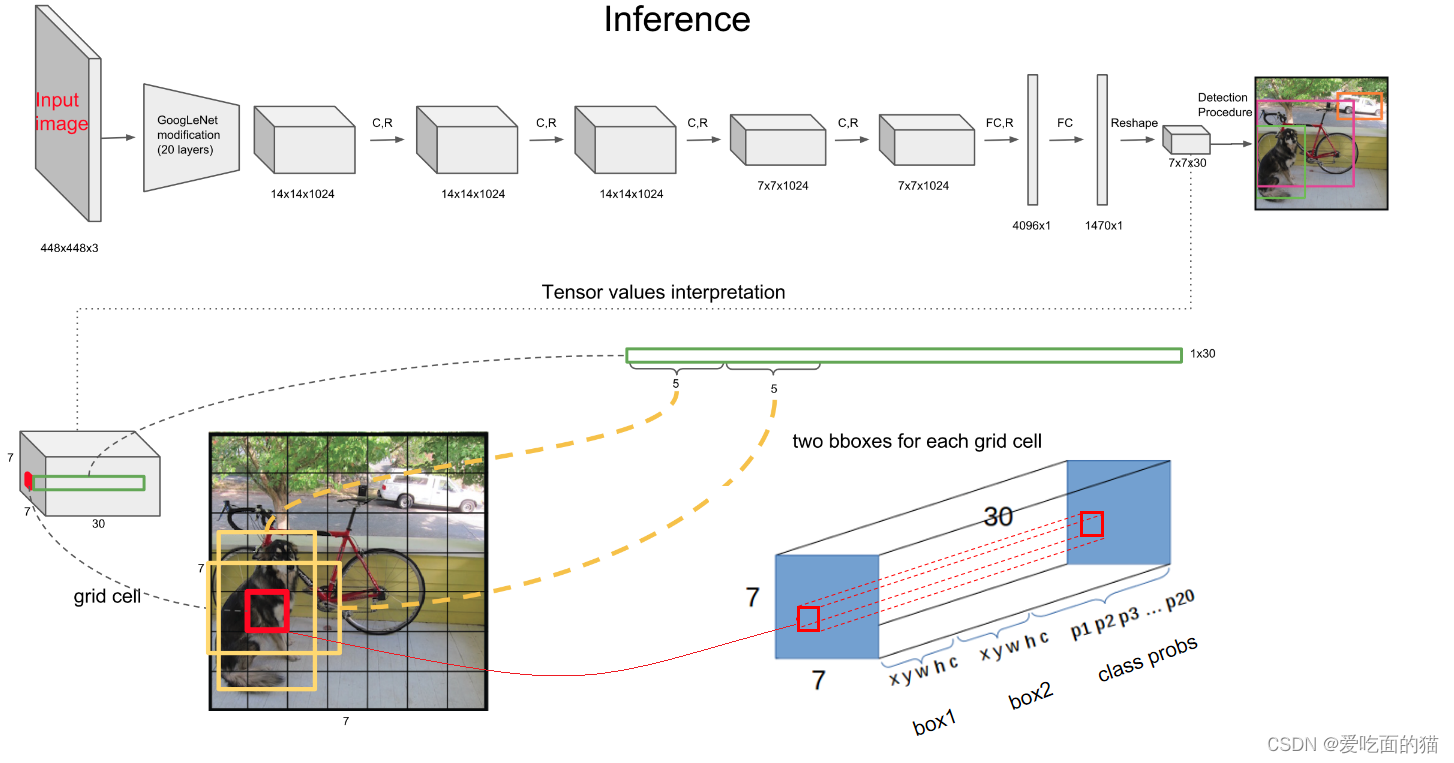

六、YOLO1流程
通过结构图中我们可以看到,输入图片是4448x448,输出结构是7x7x30,YOLO(是很简单直观的图像处理系统)整体流程大体分为三步:
-
1、把图像缩放到448X448,图片分成7x7个网格(grid cell)
-
2、在图上运行卷积网络
-
3、根据模型的置信度对检测结果进行阈值处理
1、原始图片resize到448x448,图片分成7x7个网格(grid cell)
输入图像,将原始图片resize到448x448,图片分成7x7个网格(grid cell),某个目标物体的中心落在这些网格中的一个当中,这个网格就负责预测这个物体。例如狗的中心点就落到这些网格中的红色的框(5,2)位置,那么这个红色的框就负责狗这个物体的检测。

假如我们只检测一个目标狗,此时红框(5,2)这个格子所对应的物体置信度标签为1,而那些没有物体中心点落进来的格子,对应的物体置信度标签为0。这个设定就好比该网络在一开始,就将整个图片上的预测任务进行了分工,一共设定7x7个按照方阵列队的检测人员,每个人员负责检测一个物体,大家的分工界线,就是看被检测物体的中心点落在谁负责的格子里。当然,是7x7还是9x9参数可以自己修改,精度和性能会随之有些变化。
2、在图上运行卷积网络
CNN提取特征和预测,卷积部分负责提特征。全链接部分负责预测。
在CNN提取特征后,我们得到 feature maps ,利用Anchor思想,对 feature maps 中每个锚点(对应原图中的某个区域)都预定义 B 个 boublding box,之后全链接部分负责预测,每个网格单元都会预测B个边界框和这些框的置信度分数(confidence scores)。因此对每个网格应用图像分类和定位处理,获得预测对象的边界框及其对应的类概率。
3、根据模型的置信度对检测结果进行阈值处理
虽然通过CNN提取特征和预测,但还是会有很多 boublding box,但并不是每个都是我们需要的,所以此时需要根据模型的置信度对检测结果进行阈值处理。
4、图示流程及概述
- 首先,输入图像
- 然后,YOLO将输入图像划分为网格形式(例如3 X 3):
- 最后,对每个网格应用图像分类和定位处理,获得预测对象的边界框及其对应的类概率。
01、输入图图像,将输入图像划分为网格形式(例如3 X 3)
为了方便理解,以图示的方式演示,默认7 x 7个单元格,这里用3 x 3的单元格图演示。

02、图像分类和定位处理
每个网格单元都会预测B个(此处让B=2)边界框和这些框的置信度分数(confidence scores)

03、获得预测对象的边界框及其对应的类概率
获得预测对象的边界框及其对应的类概率,进行NMS筛选,筛选概率以及IOU。


5、概念详解
单元格(grid cell)
原始图片resize到448x448,经过前面卷积网络之后,将图片输出成了一个7x7x30的结构。每个网格单元都会预测B个边界框和这些框的置信度分数(confidence scores),这些置信度分数反映了该模型对那个框内是否包含目标的信心,以及它对自己的预测的准确度的估量。
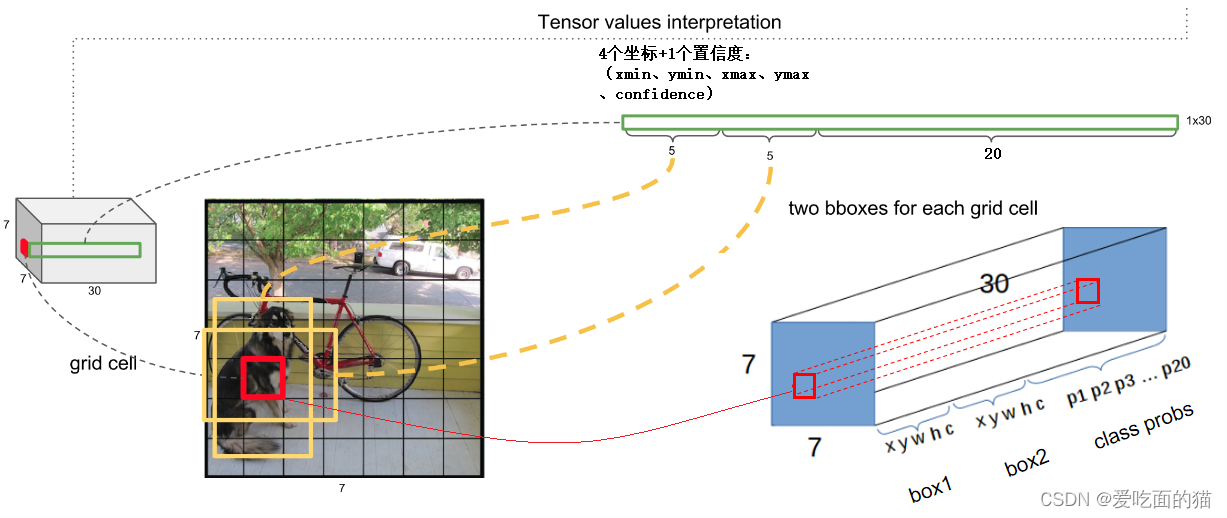
那么网络输出的 7 x 7 x 30 的特征图怎么理解?
7x7x30
7x7=49个像素值,理解成49个单元格,也可以理解成 49个 1*1*30,而每个1*1*30维度包含有类别预测和bbox坐标预测。
单元格需要做的两件事:每个单元格负责预测一个物体的类别,并且直接预测物体的概率值
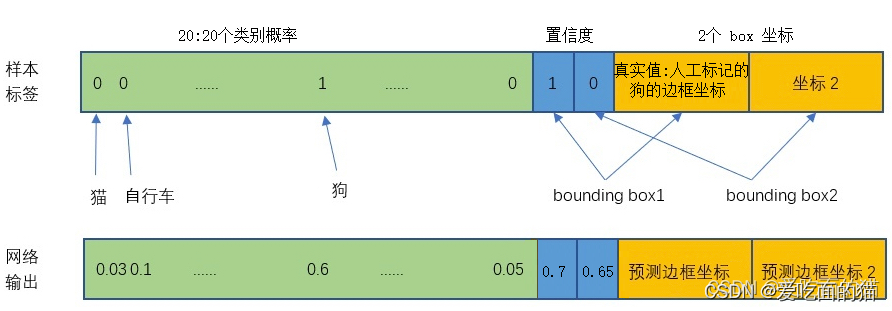
每个单元格预测两个(默认)bbox位置,两个bbox有两个置信度(confidence)30 的组成:
30 = 2个 bbox + 20个类别信息
1个bbox =4个坐标+1个置信度:xmin、ymin、xmax、ymax、confidence
2个bbox:4 + 1 + 4 + 1 = 10(4个位置信息,1个置信度)
30 =(4 + 1 + 4 + 1) + 20个类别信息(预测概率结果)注意:20代表 20类类别的预测概率结果
2个bounding box共10个值,对应 1*1*30维度特征中的前10个。
1个置信度(confidence)代表一个bbox的结果
xmin、ymin相对于对应的网格归一化到0-1之间,xmax、ymax即 w,h用图像的width和height归一化到0-1之间
小结:(7*7)*30的维度。每个 1*1*30的维度对应原图7*7个cell中的一个,1*1*30中含有类别预测和bbox坐标预测。总得来讲就是让网格负责类别信息,bounding box主要负责坐标信息(部分负责类别信息:confidence也算类别信息)。
6、网格输出筛选
- 01 置信度比较
- 02 预测位置大小-回归offset代替直接回归坐标
01、置信度比较
Pascal VOC上评估YOLO,使用最终大小S=7,预测数量B=2。
假如(人工标记的)狗的真实值中心点在 8 的单元格位置对应的特征向量信息,真实值信息如下图所示:

如果我们以每个网格的中心点为中心,每个网格单元都预测 2 个Bouding box,则上图中标注的1-12个单元格会有 24 个 Bouding box,而这个 24 个 Bouding box 中,假如 8 这个框对应的单元格的向量里, Bouding box1 和 Bouding box2 置信度是0.7和0.65,是24 个 Bouding box 中置信度最高的,以置信度高的被认为含有物体。因此目标物体的中心点(人工标记的)正好落在 8 这个单元格中,因此用以 8 这个单元格中心点预测的 2 个 Bouding box 中的一个 Bouding box 负责检测。如下图:
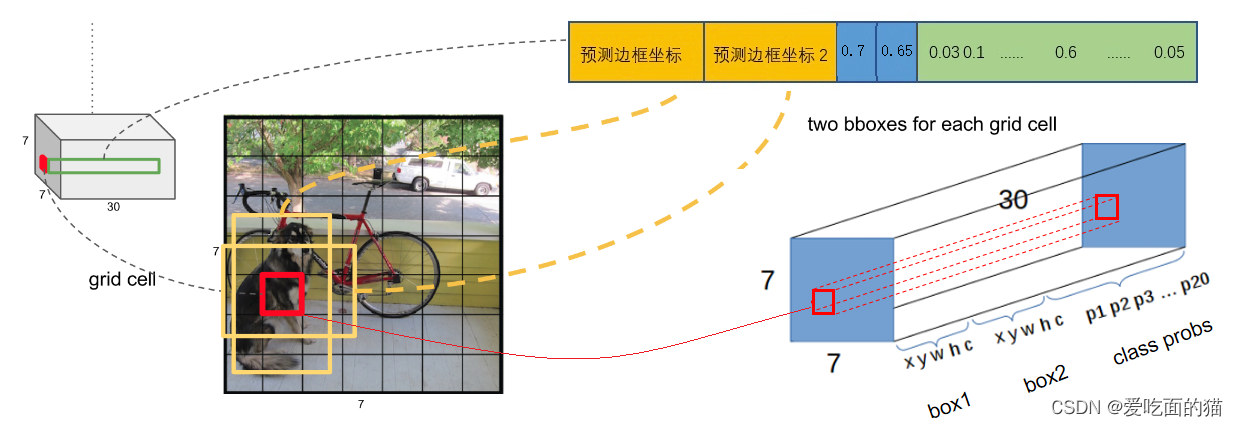
那么有两个 Bouding box ,我们用哪一个 Bouding box 来负责检测呢(最总保留哪个 Bouding box 边框呢)?此时需要通过置信度大小比较来确定。

根据上面定义的置信度公式:
首先 2 个 Bouding box 的4个值(位置坐标)分别与 GT(ground turth)进行IOU计算,哪个结果比较大,就由哪个Bouding box来负责预测该对象是否存在,同时1x1x30中的概率(20个类别)就是对应的 Bouding box 的概率。

例如:例如 Bouding box1 和 Bouding box2 与GT进行IOU计算结果分别是1.2 和1.08,就由哪个Bouding box1 来负责预测该对象是否存在(在图上画框)。1x1x30中的概率(20个类别)就是对应的 Bouding box1 的概率。
其次,使用 Bouding box 的概率 和 计算IOU的结果相乘,就是置信度分数。
例如:Bouding box1 和 Bouding box2 的IOU结果12和1.08 分别与概率相乘,结果置信度分别是0.7 和 0.65,因此也就确定了由 Bouding box1 负责检测(在图上画框)。
因为 Bouding box1 负责检测,则该 Bouding box1 的概率Pr(Object)=1,并将真实Bouding box的位置(x,y,w,h) 也就填入该 Bouding box1,另一个不负责预测的 Bouding box1的 Pr(Object)=0
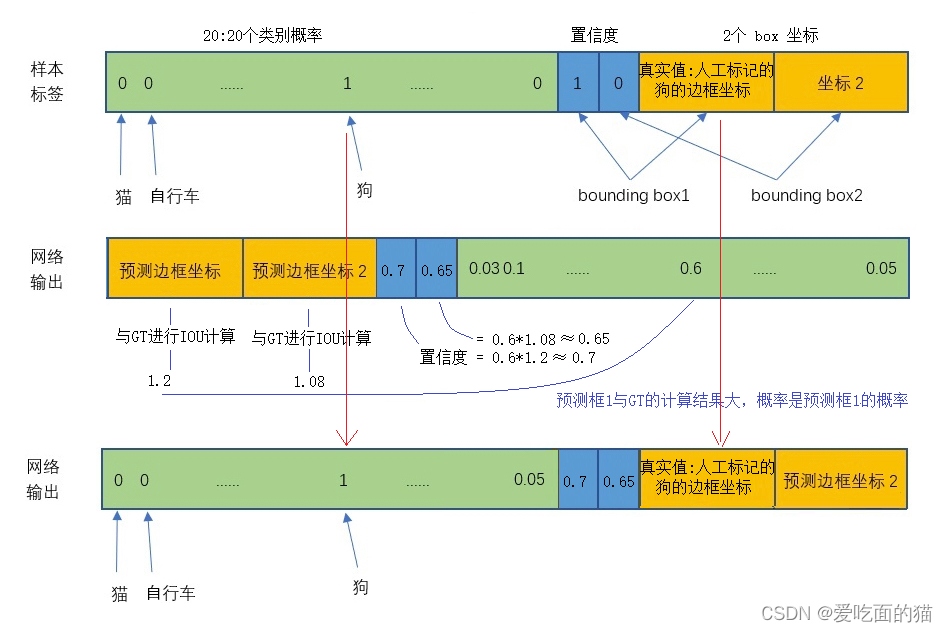
02 预测位置大小-回归offset代替直接回归坐标
另外值得注意的是,YOLO中的每个 bbox 包含5个预测值 (bx,by,bw,bh,bc),这个值并不是中心点坐标值,而是相对于所在网格左上角坐标的偏移量。为了方便训练,x,y,w,h这四个值都是要做标准化处理,它们的取值都是在0~1之间。
为什么这么说呢?我们从头到尾来看。
首先模型训练输入的数据是人工标记的数据,如下图。

假设已将图像划分为大小为3 X 3的网格,且总共只有3个类别,分别是行人(c1)、汽车(c2)和摩托车(c3)。因此,对于1-9的9个单元格来说,每个单元格标签y都是一个八维向量:
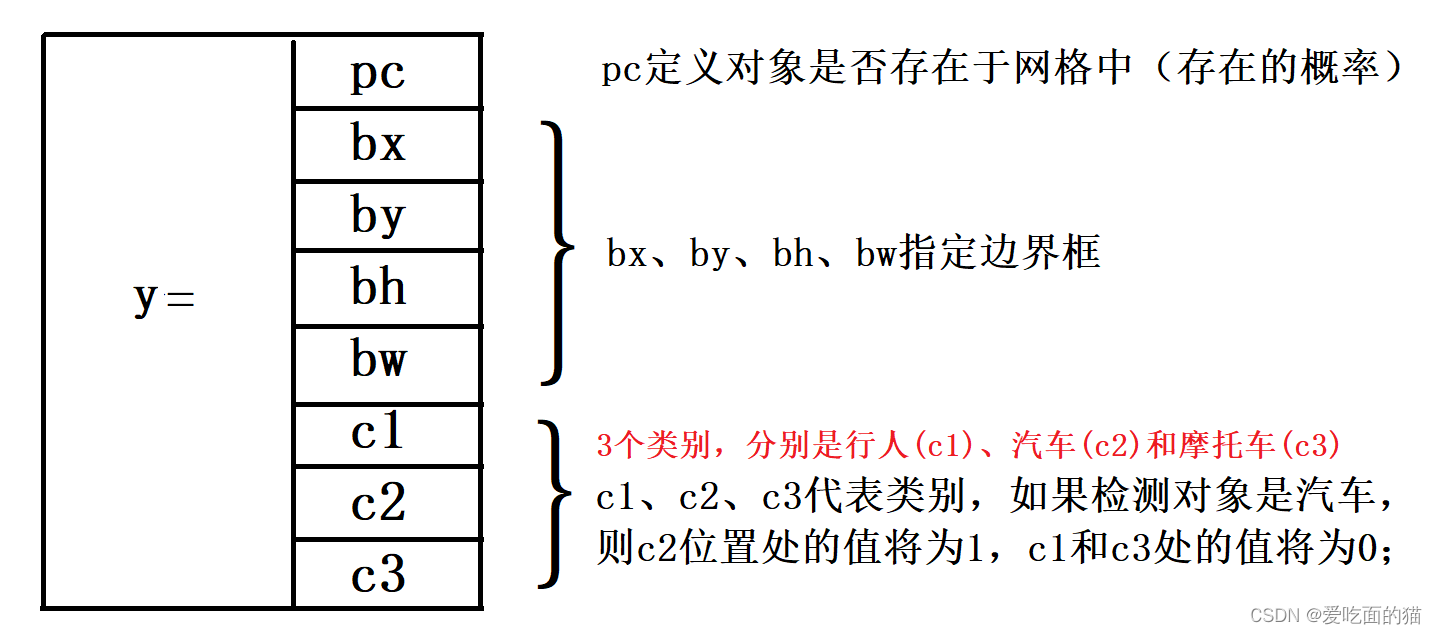
假设从上面的例子中选择第1-3,5-9的8个网格,由于这8个网格中无对象,因此pc将为0,此网格的y标签将为:("?"意味着其它值是什么并不重要,因为网格中没有对象。)

假设从上面的例子中选择第4个网格,由于这个网格中有对象,因此pc将为1,此网格的y标签将为: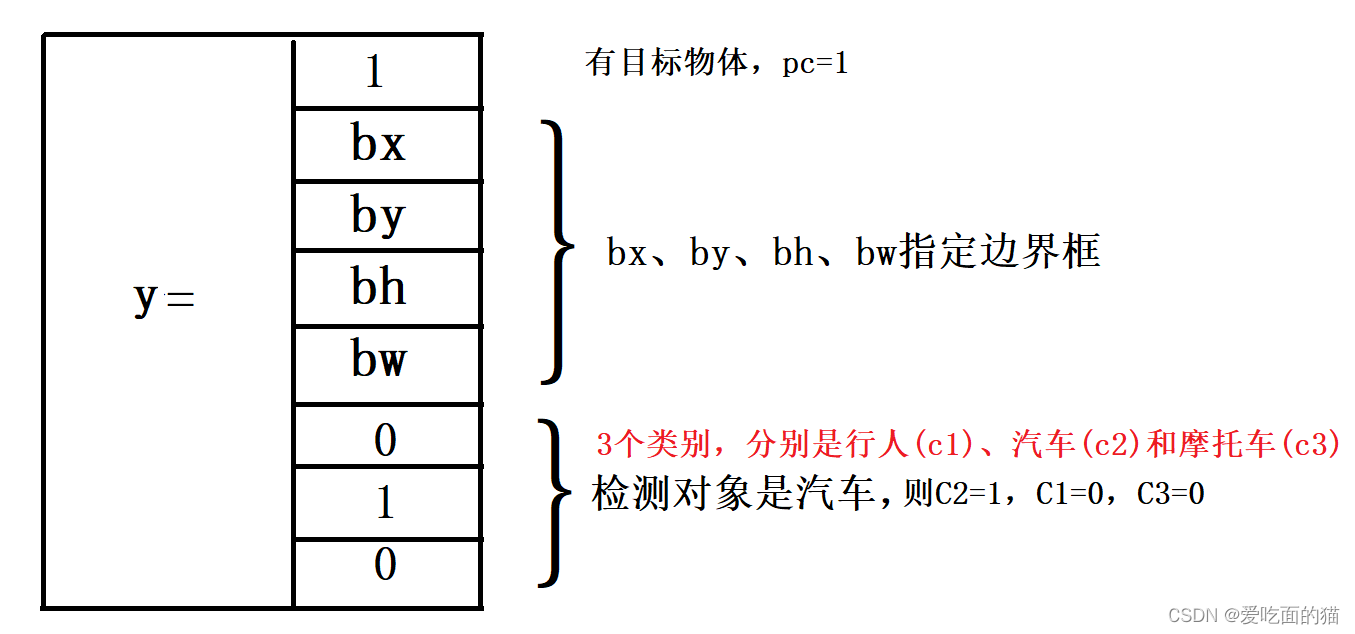
至此,我们人工标记的数据 y 标签 有如上两种形式。
但是为了训练方便,我们需要将这些值进行归一化,映射到0-1之间。
那么如何将原图中的坐标归一化到 0-1 之间的呢?
我们先看( bx,by )
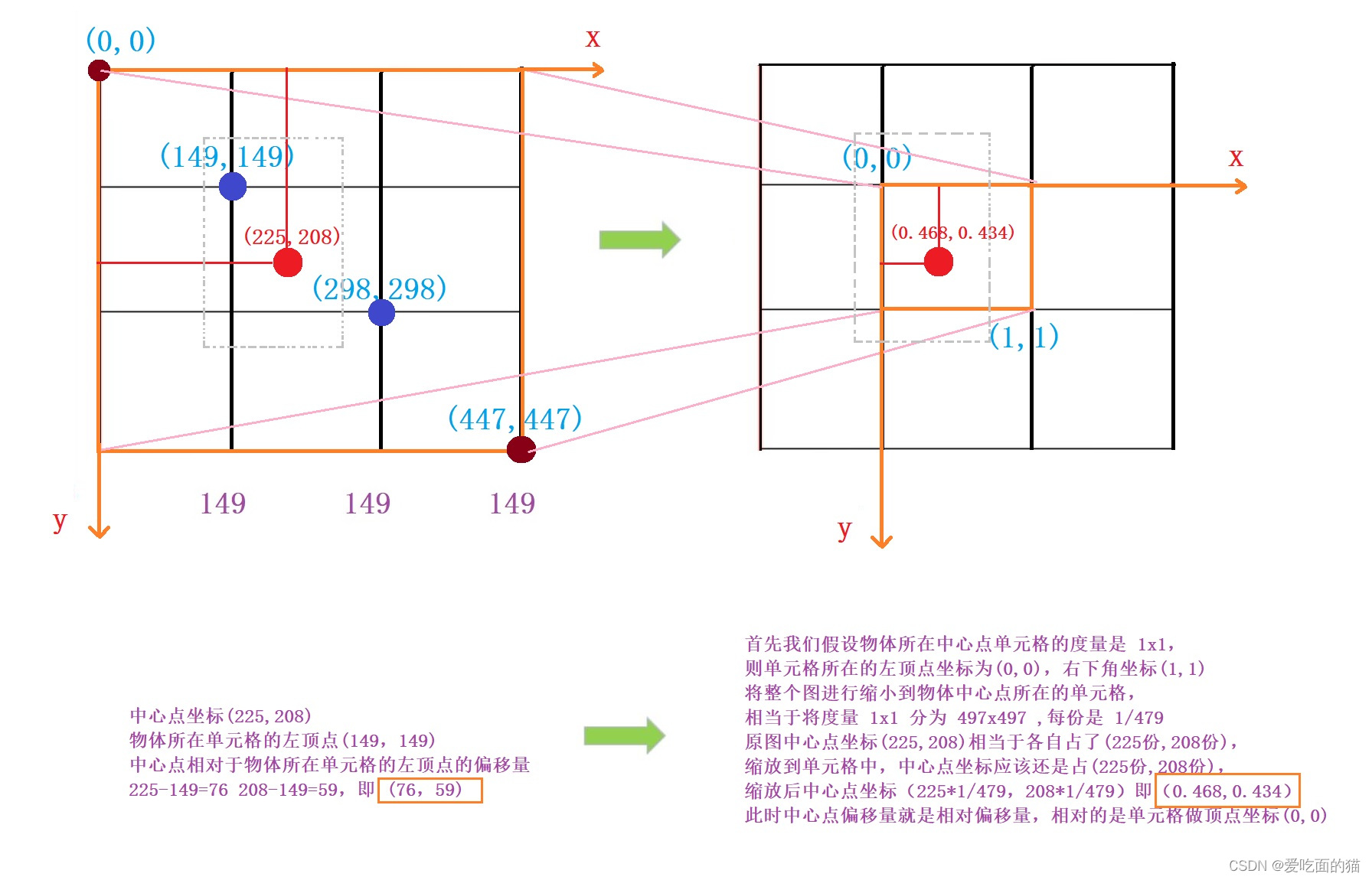
- 首先我们假设物体所在中心点单元格的度量是 1x1,
- 则单元格所在的左顶点坐标为(0,0),右下角坐标(1,1)
- 将整个图进行缩小到物体中心点所在的单元格,
- 相当于将度量 1x1 分为 497x497 ,每份是 1/479
- 原图中心点坐标(225,208)相当于各自占了(225份,208份),
- 缩放到单元格中,中心点坐标应该还是占(225份,208份),
- 缩放后中心点坐标(225*1/479,208*1/479)即(0.468,0.434)
- 此时中心点偏移量就是相对偏移量,相对的是单元格做顶点坐标(0,0)
注意:这里我们使用的是假设的方式是为了方便理解,实际上用的可能是其他函数。
同理:(bw,bh) 是人工标记框的宽高(w,h)与整张图片的宽和高比, 即(146/479,288/479)=*(0.305,0.601)使之取值范围也在(0, 1)之间。
因此是我们人工标记的y标签:

这个是我们人工标记的y标签,而我们模型给出的输出(x,y)也是相对于所在网格左上角坐标的偏移量。

注:bx和by将始终介于0和1之间,因为中心点始终位于网格内,而在边界框的尺寸大于网格尺寸的情况下,bh和bw可以大于1。同时关于 yolo 的预测的 bbox 中心坐标是相对于 grid cell 左上角的偏移值, 不是直接预测而是预测偏移值, 但是, 预测的 x, y 可能为负数啊, 这样 (x, y) 就不在该 cell 中了, yolo v2 通过 (sigmoid(x), sigmoid(y)) 来解决这个问题。
7、测试阶段
yolo 预测的不是类的概率,而是类的条件概率,即条件为:这个 cell 中包含物体(条件),那么这个物体是N 类前景中每一类的概率。即每个框有20个概率值,但是并不会直接使用这个值,这个概率可以理解为不属于任何一个bbox,而是属于这个单元格所预测的值。
最终: 测试的时候,条件类概率和每个框的预测的置信度值相乘得到每个框特定类别的置信度分数,这些分数体现了该类出现在框中的概率以及预测框拟合目标的程度。
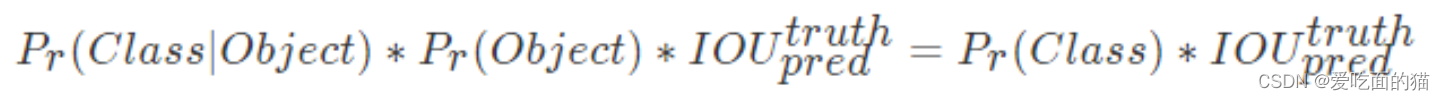
理解:这个乘积即 encode 了预测的 box 属于某一类的概率,也有该 box 准确度的信息。得到每个 box 的 class-specific confidence score 以后,设置阈值,滤掉得分低的 boxes,对保留的 boxes 进行 NMS 处理,就得到最终的检测结果。
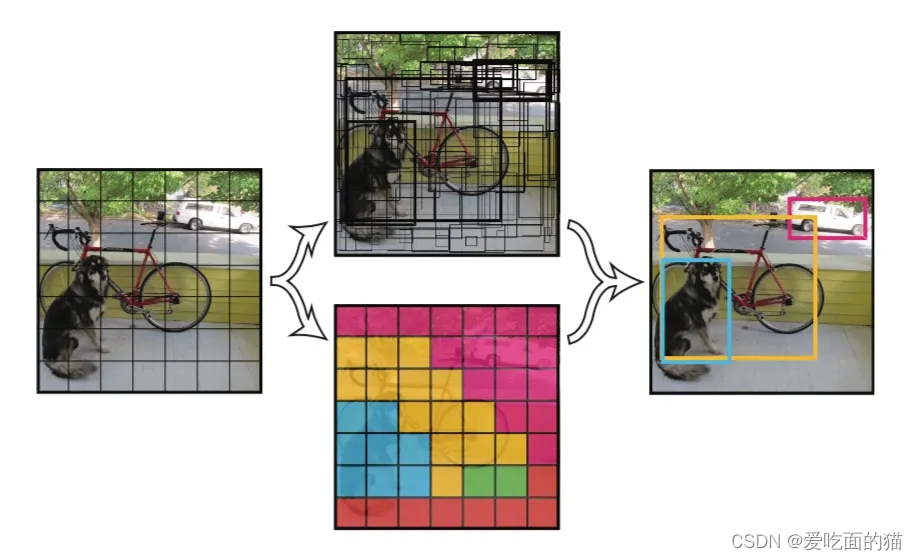
8、损失函数设计
损失就是网络实际输出值与样本标签值之间的偏差。
YOLO1的误差公式如下:
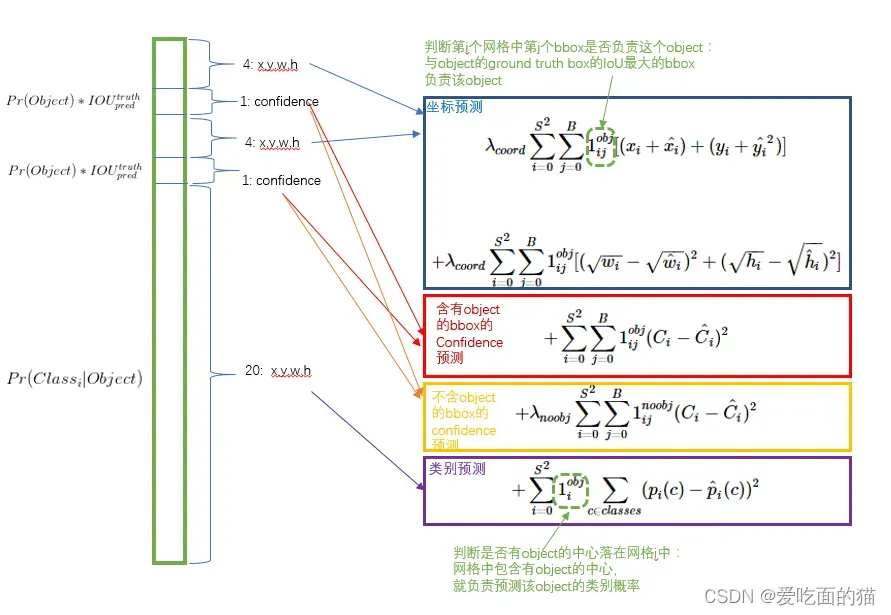
目前,YOLO1的损失函数的设计目标就是让坐标(x,y,w,h),confidence,classification 这个三个方面达到很好的平衡。
问题:
简单的全部采用了均方和误差(包含坐标误差、置信度误差、分类误差)来做这件事会有以下不足:
- a) 8维的位置和20维的类别同等重要显然是不合理的;
- b) 如果一个网格中没有object(一幅图中这种网格很多),那么就会将这些网格中的box的confidence push到0,相比于较少的有object的网格,这种做法是不均衡的,这会导致网络不稳定甚至发散。
解决方案如下
需要考量权重问题。
- 重视8维的坐标预测,给这些损失前面赋予更大的权重, 记为
 ,在pascal VOC训练中取5。(上图蓝色框)
,在pascal VOC训练中取5。(上图蓝色框) - 对没有object的bbox的confidence loss,赋予小的权重,记为
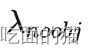 ,在pascal VOC训练中取0.5。(上图橙色框)
,在pascal VOC训练中取0.5。(上图橙色框) - 有object的bbox的置信度 loss (上图红色框) 和类别的loss (上图紫色框)的权重正常取1。

