
- 1FPGA实现简易电梯控制系统设计_fpga电梯控制器的设计
- 2idea配置本地maven
- 3云账户实际业务SQL对比测试ClickHouse、TiDB和StarRocks_starrocks tidb
- 4django crud_Django Crud应用程序PostgreSQL
- 57-10 星际探险(SPFA_c++星际探险家在其最新的宇宙探险中遭遇了一系列新的挑战。此次探险中,探险家的飞
- 6hihocoder#1589 : 回文子串的数量(manacher)_manacher hash 回文数
- 7高精度语音识别框架——ASR_Theory
- 8ollama 使用,以及指定模型下载地址_ollama 模型下载
- 9C++语法08:链表算法:优势、应用、实现与示例_链表c++
- 10C# WinForm中控件与背景透明+c# linklabel 去掉下划线的方法
ChatGLM3-6B大语言模型部署与微调_chatglm3-6b 部署
赞
踩
在 modelscope 平台部署 ChatGLM3-6B 模型。
1、登录ModelScope领取免费资源
ModelScope网址:https://www.modelscope.cn/home
领取免费配套云计算资源,启动 CPU 服务器

启动成功后点击查看Notebook
2、模型下载
打开终端,克隆 ChatGLM3 仓库并打开该文件
- git clone https://github.com/THUDM/ChatGLM3
- cd ChatGLM3
pip安装依赖
pip install -r requirements.txtgit 下载本地模型
- git lfs install
- git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
3、修改变量路径
打开 chatglm3-6b 的 config.json 文件(右键选择 open with editor 进行修改),修改为 chatglm3-6b 文件的地址:
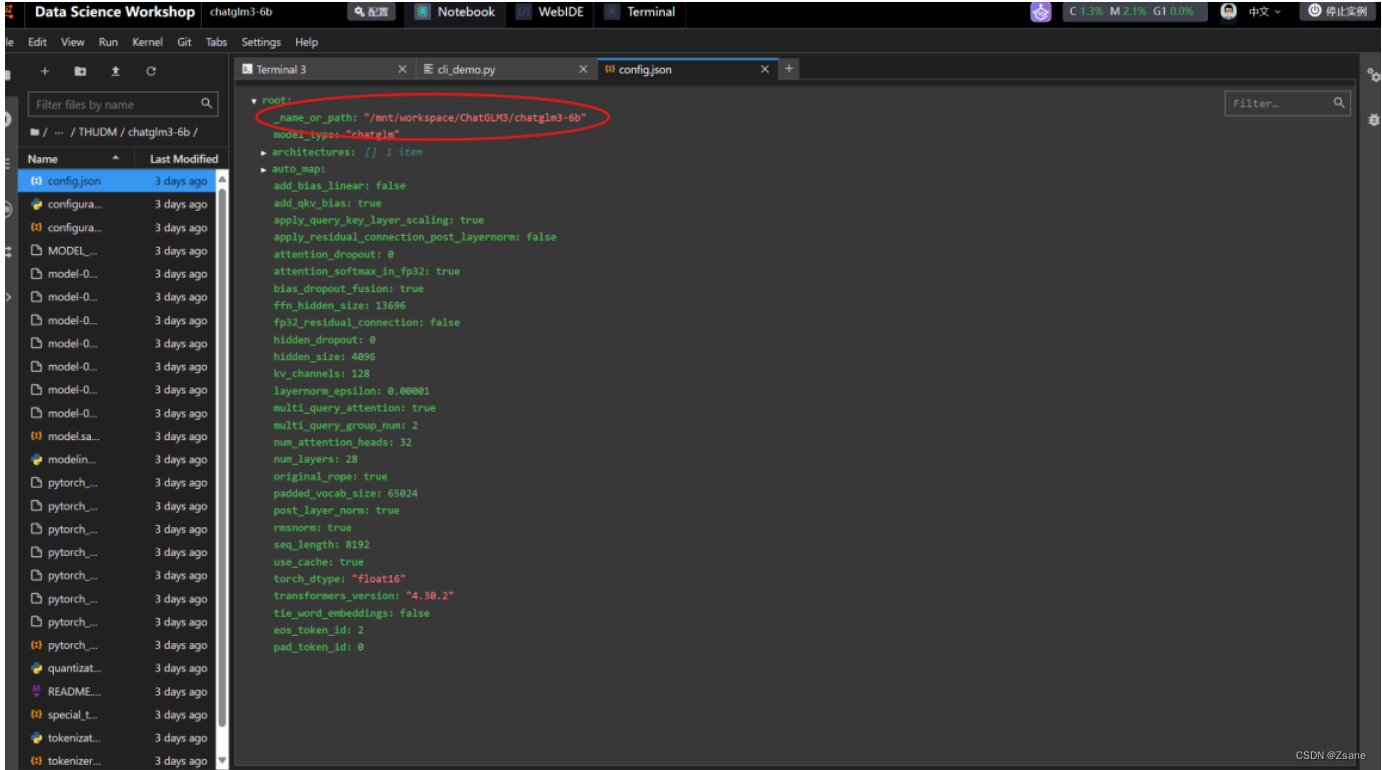
4、克隆 OpenVINO GLM3 推理仓库并安装依赖
继续输入命令
- git clone https://github.com/OpenVINO-dev-contest/chatglm3.openvino.git
- cd chatglm3.openvino
按照以下安装依赖:
- python3 -m venv openvino_env
- source openvino_env/bin/activate
- python3 -m pip install --upgrade pip
- pip install wheel setuptools
- pip install -r requirements.txt
5、转换模型
输入命令
- python3 convert.py --model_id /mnt/workspace/ChatGLM3/chatglm3-6b --output
- /mnt/workspace/ChatGLM3/chatglm3.openvino/chatglm3-6b
6、运行模型
- python3 chat.py --model_path /mnt/workspace/ChatGLM3/chatglm3.openvino/chatglm3-6b
- --max_sequence_length 4096 --device CPU
至此,模型部署完成
在阿里云上部署ChatGLM3-6B
阿里云平台提供了3个月的免费的GPU资源为我们进行大语言模型的部署和微调,具体的部署步骤如下:
1、登录阿里云网站领取免费资源
免费试用活动页:https://free.aliyun.com/
注册登录后领取交互式建模 PAI-DSW,如下图

未领取时显示的是立即试用,由于本人已经领取过所以显示的是已试用。
之后需要进行相关信息的授权。
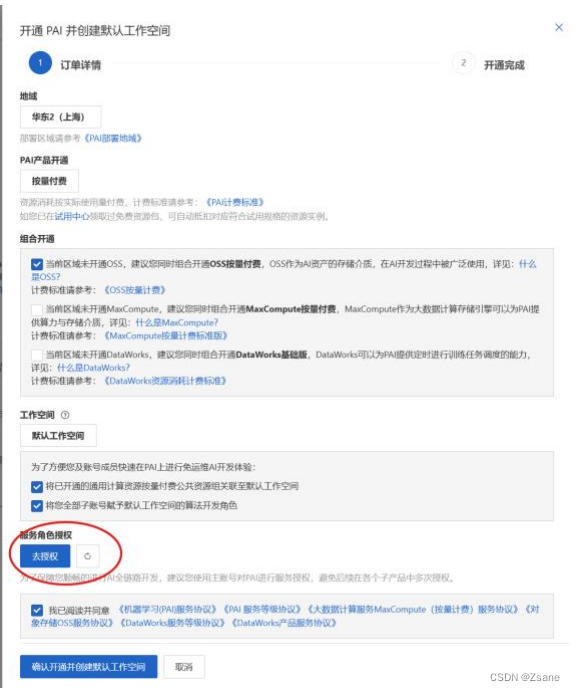
2、建立实例
授权完成后,前往默认工作空间,选择交互式建模(DSW)并建立实例

3、下载ChatGLM3-6B模型
实例创建完成后,点击打开。这里需要等待一定的时间。
1)、获取GLM3仓库
打开成功后,打开终端Terminal,如下图

输入以下代码,用来获取GLM3仓库并打开文件
- git clone https://github.com/THUDM/ChatGLM3
- cd ChatGLM3
然后使用pip安装依赖
pip install -r requirements.txt
2)、下载本地模型
在ChatGLM3终端下继续输入以下代码
- git lfs install
- git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
这样就会在 ChatGLM3 文件夹下多出一个 chatglm3-6b 的文件夹
3)、修改变量路径
移动chatglm3-6b文件夹
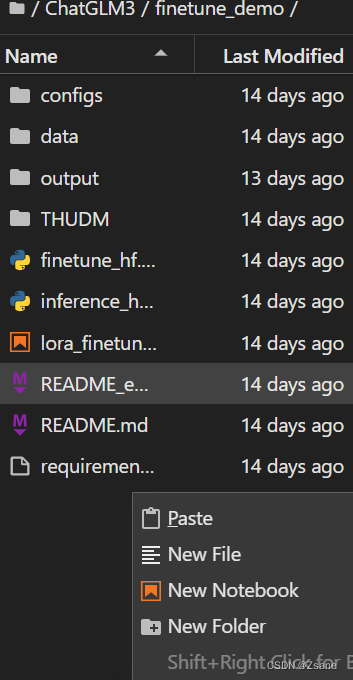
为了方便之后的微调,我们首先需要在 ChatGLM3 文件下的 finetune_demo 文件夹中新建一个 THUDM 文件夹,并将 chatglm3-6b 放到该文件夹下。
右键空白处,点击New Folder以创建新的文件夹
修改chatglm3-6b 的 config.json 文件
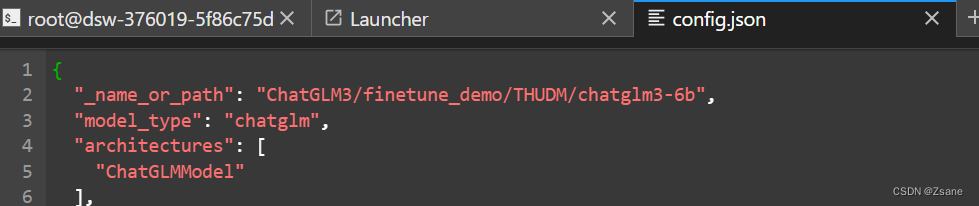
找到chatglm3-6b 的 config.json 文件,右键选择open with editor 进行修改
对于第一行 "_name_or_path",将后面的参数修改为chatglm3-6b 文件所在的位置
只需要找到 chatglm3-6b 文件夹,右键点击Copy Path即可复制位置
ChatGLM3 文件中 basic_demo 文件夹下的 cli_demo.py 文件
打开该文件,将文件代码的第一行修改如下
MODEL_PATH = os.environ.get('MODEL_PATH', 'finetune_demo/THUDM/chatglm3-6b')其中'finetune_demo/THUDM/chatglm3-6b'为chatglm3-6b 文件所在的位置。
4、测试ChatGLM3-6B模型
在变量路径修改完成后,在ChatGLM3终端下运行如下代码:
python basic_demo/cli_demo.py等待一段时间后,会出现如下界面
 此时表示部署完成,可以向ChatGLM3-6B模型进行提问
此时表示部署完成,可以向ChatGLM3-6B模型进行提问
微调ChatGLM3-6B模型
1、pip 安装依赖
需要在finetune_demo文件夹下打开终端
- cd finetune_demo
- pip install -r requirements.txt
该安装过程需要用大量时间,慢慢等待即可
安装完成后用以下指令查看已经安装的依赖
pip list对比一下里面有没有requirements.txt中要求的依赖已经版本是否符合,如果没有或安装失败就需要对着requirements.txt中的依赖单独安装即可,例如
pip install jieba==0.42.12、数据集介绍
在数据集方面,我们使用了 Movielen-1M 这个电影推荐领域中最流行的数据集,Movielen-1M 数据集包含了 6036 个用户以及他们对 2445 部电影的评分数据;其中包含三个.dat文件,ratings.dat是用户对电影的评分,uesrs.dat是用户的信息,movies.dat是电影的信息。用户对影片的评分最低为 1,最高为 5。
Movielen-1M 数据集下载链接如下
https://files.grouplens.org/datasets/movielens/
3、数据集预处理
ChatGLM3-6B处理数据集的格式为:
{"conversations": [{"role": "user", "content": "类型#裙*裙长#半身裙"}, {"role": "assistant", "content": "这款百搭时尚的仙女半身裙,整体设计非常的飘 逸随性,穿上之后每个女孩子都能瞬间变成小仙女啦。料子非常的轻盈,透气性也很好,穿 到夏天也很舒适。"}]}
为此,我们需要修改Movielen-1M数据集的格式,让其能够符合ChatGLM3-6B读取格式,我们先用python对其进行预处理。代码如下:
- import pandas as pd
- import json
- import os
- from sklearn.model_selection import train_test_split
-
- #抽取样本数量
- sample_num=1000
- # 读取数据文件,指定编码为latin-1
- ratings = pd.read_csv('ratings.dat', sep='::', header=None, names=['UserID', 'MovieID', 'Rating', 'Timestamp'], engine='python', encoding='latin-1')
- movies = pd.read_csv('movies.dat', sep='::', header=None, names=['MovieID', 'Title', 'Genres'], engine='python', encoding='latin-1')
-
- # 合并数据
- data = pd.merge(ratings, movies, on='MovieID')
-
- # 删除缺失值行
- data = data.dropna(subset=['UserID', 'MovieID', 'Rating', 'Title'])
-
- # 准备存储对话的列表
- conversations = []
-
- # 随机抽样生成对话数据
- sample_data = data.sample(n=sample_num, random_state=40)
- ave_input_len=0;
- ave_output_len=0;
- max_input_len=0;
- max_output_len=0;
- for index, row in sample_data.iterrows():
- # 用户对电影的评价
- user_preference = f"我喜欢看《{row['Title']}》,你推荐什么其他电影?"
- if len(user_preference)>max_input_len:
- max_input_len=len(user_preference)
- if ave_input_len==0:
- ave_input_len=len(user_preference)
- else:
- ave_input_len=(len(user_preference)+ave_input_len)/2
- # 推荐同一用户其他电影
- user_group = data[(data['UserID'] == row['UserID']) & (data['Title'] != row['Title'])]
- recommended_movies = user_group['Title'].tolist()
-
- # 确保推荐电影列表中不包含 None
- recommended_movies = [title for title in recommended_movies if isinstance(title, str) and not pd.isna(title)]
-
- if recommended_movies:
- assistant_response = f"我推荐你看{', '.join([f'《{title}》' for title in recommended_movies[:3]])}。"
-
- if len(assistant_response)>max_output_len:
- max_output_len=len(assistant_response)
- if ave_output_len==0:
- ave_output_len=len(assistant_response)
- else:
- ave_output_len=(len(assistant_response)+ave_output_len)/2
-
- conversation = [
- {"role": "user", "content": user_preference},
- {"role": "assistant", "content": assistant_response}
- ]
- conversations.append({"conversations": conversation})
-
- # 定义训练集和验证集的大小
- train_size = int(sample_num*0.8)
- val_size = sample_num-train_size
-
- # 划分训练集和验证集
- train_conversations, val_conversations = train_test_split(conversations, train_size=train_size, test_size=val_size, random_state=42)
-
- train_data = train_conversations
- val_data = val_conversations
- #train_data = {"conversations": train_conversations}
- #val_data = {"conversations": val_conversations}
- # 创建目录
- os.makedirs('data/Movielen', exist_ok=True)
-
- # 保存为train.json文件
- with open('data/Movielen/train.json', 'w', encoding='utf-8') as f:
- json.dump(train_data, f, ensure_ascii=False, indent=4)
-
- # 保存为dev.json文件
- with open('data/Movielen/dev.json', 'w', encoding='utf-8') as f:
- json.dump(val_data, f, ensure_ascii=False, indent=4)
-
- print("数据处理和保存完成")
- print(f"平均输入长度{ave_input_len}")
- print(f"最大输入长度{max_input_len}")
- print(f"平均输出长度{ave_output_len}")
- print(f"最大输出长度{max_output_len}")
-

通过这段python代码,将原来Movielen-1M数据集修改为如下:
[{"conversations": [ {"role": "user","content": "我喜欢看《Immortal Beloved (1994)》,你推荐什么其他电影?"},{"role": "assistant","content": "我推荐你看《Bug's Life, A (1998)》, 《Princess Bride, The (1987)》, 《Christmas Story, A (1983)》。" }]},
{"conversations": [{"role": "user","content": "我喜欢看《Shawshank Redemption, The (1994)》,你推荐什么其他电影?"},{"role": "assistant", "content": "我推荐你看《Princess Bride, The (1987)》, 《Airplane! (1980)》, 《Big (1988)》。"}]},……]
源代码仅抽取并划分了1000个数据集,可以通过修改sample_num的值获取更多数据集,其中训练集和验证集大小比为8:2
4、数据集传入
在 finetune_demo 下创建一个文件夹 data,同时在 data 下再创建一个文件夹 AdvertiseGen 用来存储数据集,将文件 train.json 和 dev.json 上传到 AdvertiseGen 文件夹中(其中 train 为训练集,dev 为验证集)
同时需要修改finetune_demo 中 config 文件夹下 lora.yaml 文件内的部分参数
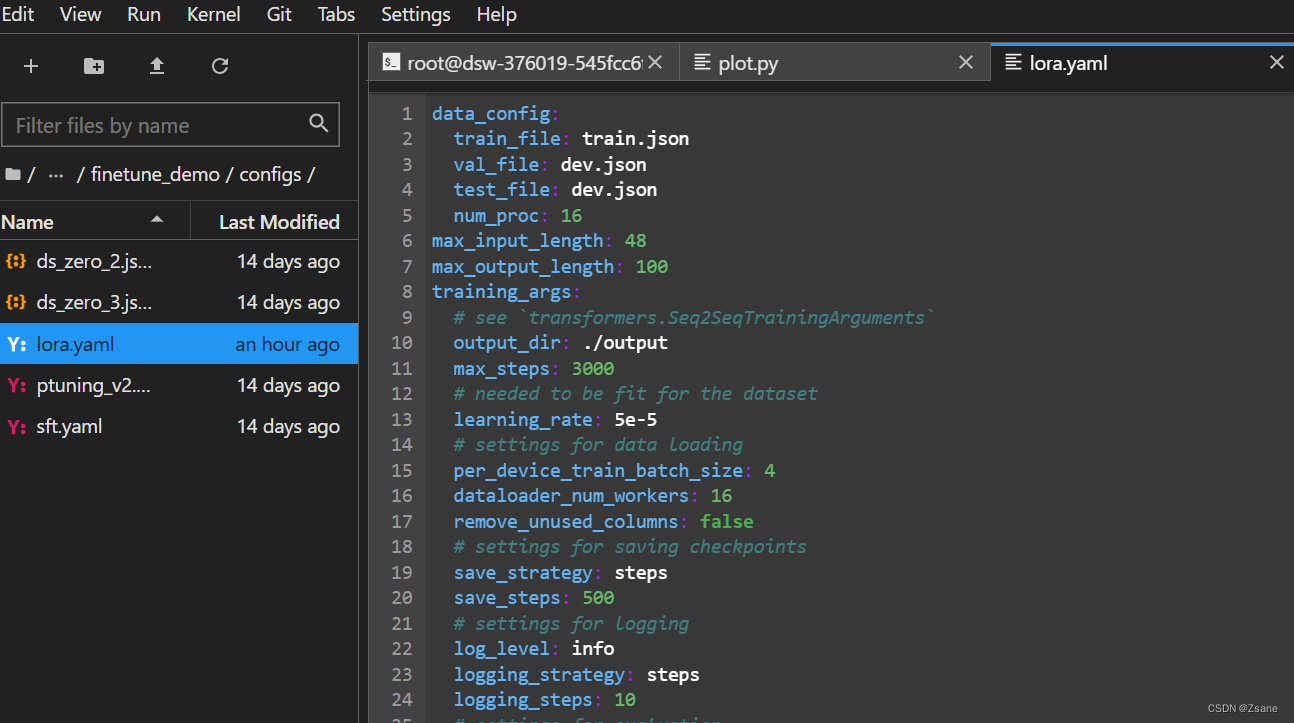
train_file为训练集路径,val_file和test_file为验证集路径,由于我们上传的文件命名为train.json和dev.json故不需要进行修改
max_input_length为最大输入字长,max_output_length为最大输出字长,这两个数据要尽量和平均输入输出数据长度相接近,不能差太多,否则会出现大量的空白冗余,非常浪费空间,并且会 导致训练时间变长、模型训练效果变差。
在之前的python代码中,我们已经求出了平均输入长度、最大输入长度、平均输出长度、最大输出长度,因此,这里我根据之前代码求出的平均长度,选取max_input_length为48,max_output_length为100
output_dir为微调后的模型地址,在微调下程中会自动生成一个 output 文件夹,里面保存微调后的模型文件
max_steps为训练步数,save_steps为保存步数,即每 500 步保存一次
5、模型微调
在finetune_demo文件夹下打开终端,输入代码
python finetune_hf.py data/AdvertiseGen/ THUDM/chatglm3-6b configs/lora.yaml
微调开始进行
在微调下程中会出现下图的情况,loss 表明了拟合度,loss 越小,拟合效果越好, 当 loss 逐渐变大时,说明出现了下拟合, epoch 则是指所有训练样本在模型中正向反向传播一次的次数,即整个数据集被模型学习的次数。
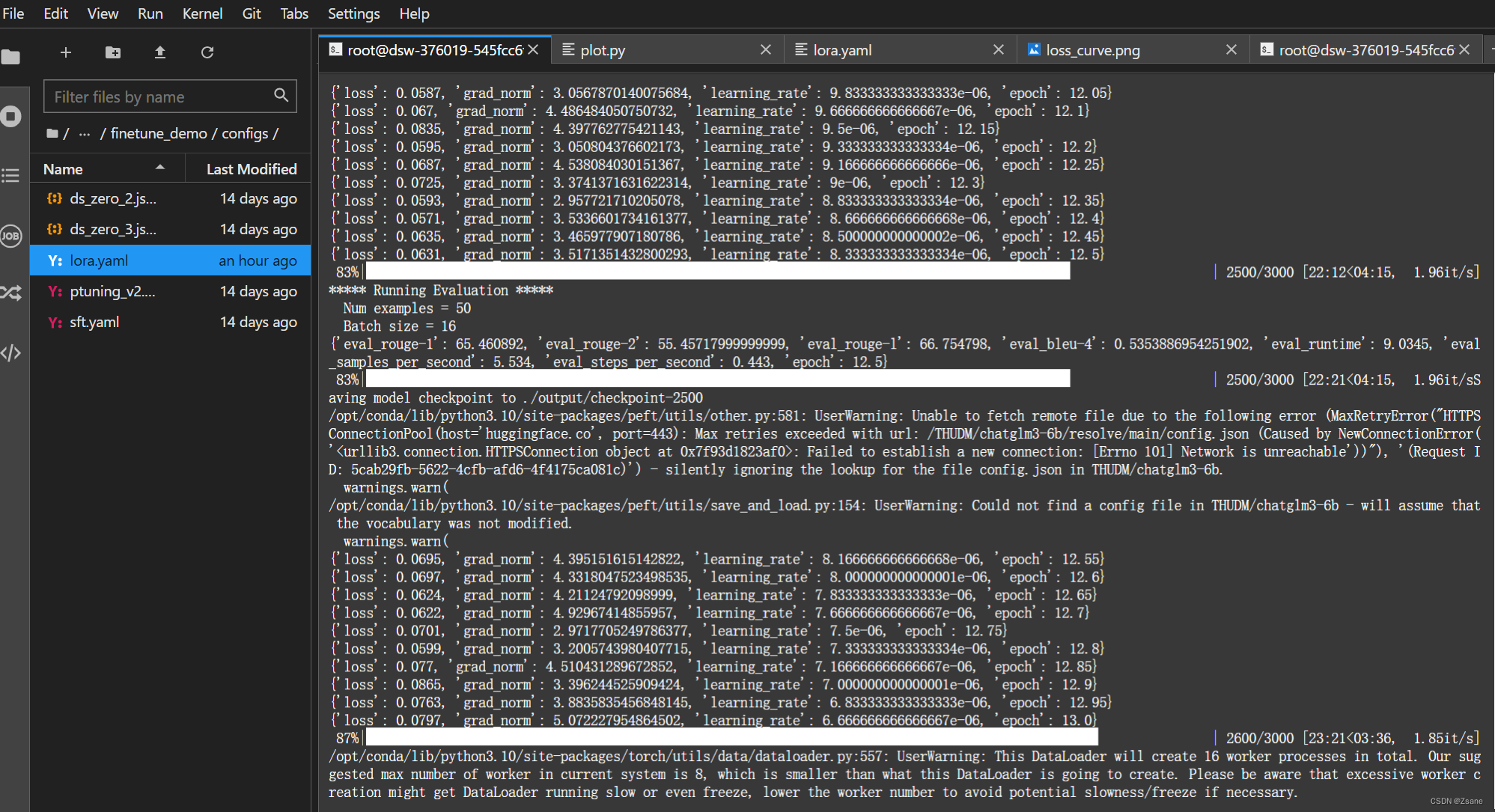
微调完成后,输入代码
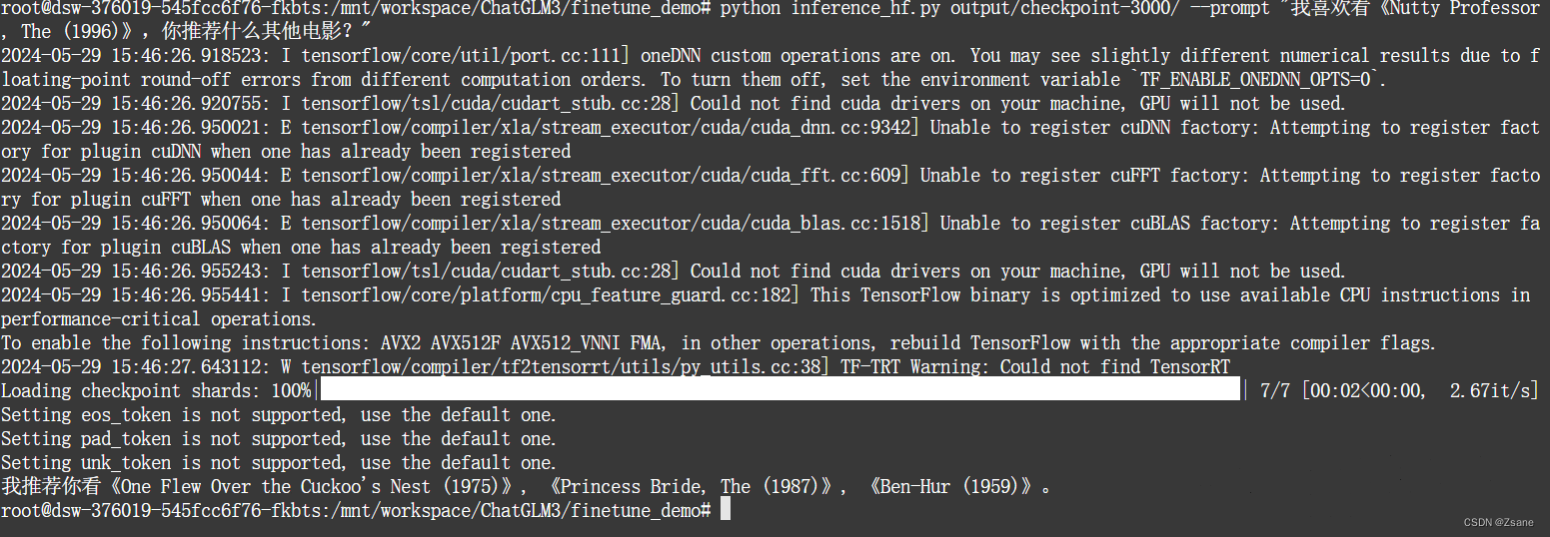
python inference_hf.py output/checkpoint-3000/ --prompt question其中,output/checkpoint-3000/为使用的模型地址,由于之前我们设置的训练步数为3000,每隔500步保存,故一共有6个模型地址可以选择,这里我们选择最后一个
--prompt question中,question替换为相关问题,之后模型会给出相关回复,例如:
对于微调过程中loss的变化,被存储在trainer_state.json的训练日志,我们可以使用这个绘制loss曲线,在output/checkpoint-3000/中创建名为plot.py的文件
- import json
- import matplotlib.pyplot as plt
-
- # 读取JSON文件
- def read_json(filename):
- with open(filename, 'r') as f:
- data = json.load(f)
- return data
-
- # 提取loss值
- def extract_loss(json_data):
- log_history = json_data.get('log_history', [])
- losses = []
- for entry in log_history:
- if 'loss' in entry:
- losses.append(entry['loss'])
- return losses
-
- # 画loss曲线
- def plot_loss(losses):
- plt.plot(losses)
- plt.title('Loss Curve')
- plt.xlabel('Epoch')
- plt.ylabel('Loss')
- plt.grid(True)
- plt.show()
-
- # 主函数
- def main():
- filename = 'trainer_state.json' # 请替换成你的JSON文件路径
- json_data = read_json(filename)
- losses = extract_loss(json_data)
- plot_loss(losses)
- plt.savefig('loss_curve.png')
-
- if __name__ == "__main__":
- main()
运行代码
python plot.py由此我们可以得出loss曲线


