
- 1Mac M2 本地下载 Xinference_xinference mac
- 2QT拖放事件之三:自定义拖放操作-利用QDrag来拖动完成数据的传输
- 31024程序节特别推荐:程序员的书单
- 4动态规划算法及其在JavaScript中的实现_动态规划js
- 5ROS入门21讲---常用可视化工具的使用及课程总结_ros可视化工具心得
- 6数据结构--单链表(图文)_单链表头节点的目的
- 7python数据分析及可视化(二)离散程度、标准化值、分布形态、描述性统计图表_python 刻画一组数据的离散程度的量是
- 8探索 TS3AudioBot-NetEaseCloudmusic-plugin:将网易云音乐带入 TeamSpeak 3 的创新插件
- 9如何配置node.js环境
- 10通用大模型VS垂直大模型
llm 多模态通用大模型(nlp/cv)知识讲解_cv大模型和llm
赞
踩
模型算法(最难,模型结构与训练方法)
数据(最耗时,数据与模型效果之间的关系)
算力(GPU显卡+模型量化)
模型参数量、训练数据量:
模型参数量决定 整个模型的理论效果
训练数据量决定 整个模型的实际效果
多模态:用于表示某种信息的模式(图片、文字、语音、视频)
通过各种预训练模型将信息的不同模式,用相近的向量进行表示。

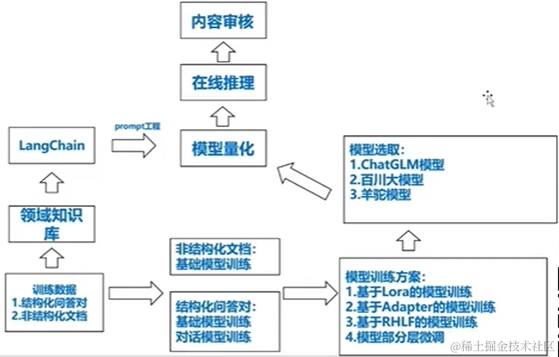
大模型的核心,问答系统(transform 结构)
prompt工程(模型适配)

nlp应用场景:
文本摘要
信息提取
问答
文本分类
对话
代码生成
推理
cv应用领域:
vit(vision transformer),做图像分类
yolo 目标检测------->(置信度,目标,位置)
时间序列问题
文本分类
文本可以一个句子,文档(短文本,若干句子)或篇章(长文本),因此每段文本的长度都不尽相同。在对文本进行分类时,我们一般会指定一个固定的输入序列/文本长度:该长度可以是最长文本/序列的长度,此时其他所有文本/序列都要进行填充以达到该长度;该长度也可以是训练集中所有文本/序列长度的均值,此时对于过长的文本/序列需要进行截断,过短的文本则进行填充。
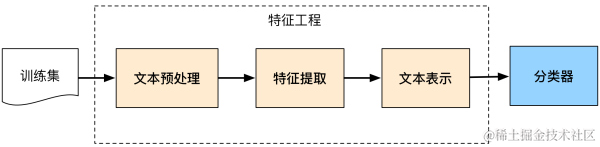
文本预处理:
1.中文分词技术
2.英语可以用空格就可以切分单词
(1)基于词表的分词算法
正向最大匹配法,对于输入的一段文本从左至右、以贪心的方式切分出当前位置上长度最大的词。正向最大匹配法是基于词典的分词方法,其分词原理是:单词的颗粒度越大,所能表示的含义越确切。
- 正向最大匹配算法
- 逆向最大匹配算法
- 双向最大匹配算法
(2)基于统计模型的分词算法
基于统计模型的分词算法的主要核心是词是稳定的组合,在上下文中相邻的字如果同时出现的次数越多,那么就越有可能构成一个词。因此字与字相邻出现的概率或者频率能较好地反映成词的可信度。可以对训练文本中相邻出现的各个字的组合的频度进行计算统计,得出它们之间的互现信息。互现信息体现了汉字之间结合关系的紧密程度。当紧密程度高于某一个阈值时,便可以认为此字组可能构成了一个词。该方法又称为无字典分词。
- 基于N-gram语言模型的分词方法
- 基于HMM的分词方法
- 基于CRF的分词方法
常用分词工具(jieba分词)
jieba分词目前在中文分词中被引用的还是比较多的,jieba分词支持三种模式:
- 精确模式,试图将句子最精确地切开,适合文本分析;
- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快, 但是不能解决歧义;
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回 率,适合用于搜索引擎分词;
自定义Jieba分词词典
开发者可以指定自己自定义的词典,以便包含 jieba 词库里没有的词。虽然 jieba 有新词识别能力,但是自行添加新词可以保证更高的正确率

词集是修改jieba内部的词集,添加业务中经常使用到的词。
文本特征:
- 对文本分词(作为特征),比如把这句话“我是天才”分词为“我”“是”“天才”
- 统计各词在句子中是否出现(词集模型)
- 统计各词在句子中出现次数(词袋模型)
- 统计各词在这个文档的TFIDF值(词袋模型+IDF值)
分词提取后,做向量转换:
词向量(中文分词后,做关键词提取(提取出现次数最多的前n个词),再进行wordTorec,转向量,模型采用1维CNN进行分类,textCNN)
字向量(提取固定前n个字,模型采用RNN进行分类,textRNN)
文本分词后,接下来是文本向量化(Word Embedding,词嵌入) ,即用向量或矩阵的形式表示文本,也可以理解为对文本的数值化处理。 文本向量化从数学角度可以解释为映射,即将单词映射到另一个空间,f : A -> B,生成一个在新空间上的表达。
词向量方法:
One-hot Representation
Word2Vec
Distributed Representation
对于nlp的可变输入,不同框架可以对序列进行压缩或者扩充:
在pytorch中,是用的torch.nn.utils.rnn中的 pack_padded_sequence 和 pad_packed_sequence 来处理变长序列,前者可以理解为对 padded 后的 sequence 做pack(打包/压紧),也就是去掉 padding 位,但会记录每个样本的有效长度信息;
后者是逆操作,对 packed 后的 sequence 做 pad,恢复到相同的长度。
seqToseq(序列到序列)
nlp中不定长输入对应不定长输出
输⼊可以是⼀段不定⻓的英语⽂本序列,输出可以是⼀段不定⻓的法语⽂本序列
当输⼊和输出都是不定⻓序列时,我们可以使⽤编码器—解码器(encoder-decoder)或者seq2seq模型。序列到序列模型,简称seq2seq模型。这两个模型本质上都⽤到了两个循环神经⽹络,分别叫做编码器和解码器。编码器⽤来分析输⼊序列,解码器⽤来⽣成输出序列。两 个循环神经网络是共同训练的。

常说的embedding特征其实包含两个意思(其实本质是一样的):
- 1、基于一些模型比如word2vec、graph embedding方法等产出item、user的embedding作为user维度、item维度的一部分特征传入模型使用。
- 2、深度模型产出的中间结果,比如双塔模型,我们最终算法的user 和 item的余弦相似度,但是会依赖中间产出的user、item embedding;又比如Youtube DNN中会依赖用户的行为序列特征,比如点击序列,但是点击序列是没有办法被网络直接使用的,所以就要借助embedding去实现。
如何系统的去学习AI大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

