
- 1注意力机制——Non-local Networks(NLNet)_非局部注意力模块
- 2git命令的学习_git命令学习 csdn
- 3Elasticsearch:Painless scripting 语言(一)_elasticsearch painless
- 4什么是NoSQL?随着这次训练就来学习一下_novsql
- 5Spring Boot - 整合Actuator_endpoint.health.show-details: always
- 6jetbrain mps 从2018.1版本升级到升级到2018.3,原项目遇到failed to create cell for node错误_failed to create i3s node while converting
- 7【Git】git将分支合并进master_git合并到master
- 8华为od机试题(js篇)_华为od require("readline").createinterface({ input:
- 9Android Framework——进程间通讯学习(1),2024年最新HarmonyOS鸿蒙编程权威指南第4版
- 10java—抽象类与接口的区别_java抽象方法与非抽象区别
广告推荐学习笔记_transformer与广告结合
赞
踩
注:个人学习用,仅供参考
推荐系统
推荐系统实验方法
离线实验—>用户调查—>在线实验
评测指标
- 用户满意度
- 预测准确度:
1)评分:RMSE,MAE
2)topn推荐:召回与准确率,实际上后者更符合实际需求 - 覆盖率:推荐结果占总物品比率
1)信息熵
2)基尼指数 - 多样性:推荐列表两两不相似性
- 新颖度、惊喜度、信任度等
算法分类
基于用户行为(协同过滤):1)基于邻域 2)隐语义 3)基于图的随机游走
- 基于用户的协同过滤:找到和目标用户相似的用户集,从集合中找目标用户没有的(关键:计算两个用户的兴趣相似度)
- 基于物品的协同过滤:计算物品相似度(并非计算物品内容相似度,通过分析用户行为计算相似度),根据相似度和用户历史行为生成推荐列表
优缺点:两个算法皆适合本身对应数据少的(用户数和物品数),usercf不一定对推荐结果立即变化,需要一段时间,itemcf实时变化
广告理论
广告分类
通过计费模式分类
广告流程:展示—>点击—>后期行动
(以下按流程(某种程度=标价,越到后期越贵,事实上总体价格还需考虑后期行动因素)排序)
CPM:按展示付费,只要展示了广告主的广告内容,广告主就因此付费
CPT:按时长付费,例如广告主向网站付一个月x元
CPC:按点击付费,根据广告被点击的次数付费
CPA:按行为付费,按照广告投放的实际效果计价,按照回应的有效问卷或订单付费
CPS:按销售付费,按照实际销售的产品数量付费
*CPM和CPT在第一步就收取广告费用,CPC在第二步收取费用,CPA和CPS在第三步收取费用
CPM和CPT对网站有利,CPC、CPA、CPS对广告主有利,较流行的计价方式是CPM和CPC
广告其他因子
ADX:ad exchange,广告交易平台,是广告商和媒体之间的桥梁,汇集大量媒体流量,收集处理广告商的数据
(表格资料源:知乎)
| 传统采买 | PDB | PD | RTB | |
|---|---|---|---|---|
| 购买方式 | CPM/CPD固定价格 | CPM/CPD固定价格 | CPM固定价格 | CPM竞价 |
| 是否需要提前下单 | 是 | 是 | 是 | 否 |
| 展现优先级 | 最高 | 最高 | 品牌余量 | 剩余流量 |
| 是否保量 | 是 | 是 | 否 | 否 |
eCPM:千次展示的期望收入,明显越高越好,计算公式: 出价bid * 预估点击率pCTR * 预估转化率pCVR * 1000
广告优化:拆解eCPM,对影响eCPM的因素进行测试优化,以提高eCPM(明显因素是计算公式中的各个项)
抬高报价:实时竞价广告系统RTB(real-time bidding)
预估点击率提高:与广告内容质量有关
预估转化率提高:与商家产品和服务底层功力有关
oCPX:根据单个流量点击率和转化率进行智能动态出价调整,相当于优化出价,使出价符合点击率和转化率的一定关系,包括oCPC、oCPM等
推荐排序模型
推荐系统四个环节:召回—>粗排—>精排—>重排
召回:从海量数据中快速找到一部分用户潜在感兴趣的物品
粗排:召回和精排中的过渡阶段,使用简单模型
精排:使用大量特征,使用较复杂的模型,尽量对物品进行精准个性化排序
重排:加上业务策略等,改进用户体验
后三个环节可以统称为排序环节,使用排序模型
特征工程
一般在搜推系统中,特征可以分为:用户特征、用户行为特征、上下文特征
用户行为特征
-
用户行为属性信息:
1)物品id
2)物品属性:如品牌、店铺、标题
3)行为时间:如点击时间到当前时间的长度
4)行为类型:如点击、购买、收藏
5)详细信息:如停留时长、查看评论等 -
用户的负反馈:
隐式:曝光未点击
显式:用户反馈“不喜欢”
原始特征处理
id特征等,通过hash映射
离散特征直接输入
特征交叉
有两种分类:
- 显示建模和隐式建模,判断依据是模型设计
- 人工特征交叉和自动特征交叉,判断依据是输入项
(表格来源:知乎)
| 排序系统交叉特征建模方式 | 经典模型 |
|---|---|
| 人工设计交叉特征 | LR, Wide&Deep, DMT |
| 自动学习交叉特征 | LR+GBDT |
| 隐式建模bit-wise交叉特征 | DNN, DIN, DIEN, DMT 等神经网络 |
| 显式建模bit-wise交叉特征 | DCN, DCN-V2 等cross结构 |
| 显式建模field-wise交叉特征 | FM, FFM, DeepFM, NFM, xDeepFM 等FM模型 |
经典模型
FM
Factorization Machine(资料来源)
普通的线性模型没有考虑到特征之间的相关性,当只考虑二阶特征交叉时:
y
(
x
)
=
w
0
+
Σ
i
=
1
n
w
i
x
i
+
Σ
i
=
1
n
Σ
j
=
i
+
1
n
w
i
j
x
i
x
j
y(x) = w_0 + \Sigma^n_{i=1}w_ix_i + \Sigma^n_{i=1}\Sigma^n_{j=i+1}w_{ij}x_ix_j
y(x)=w0+Σi=1nwixi+Σi=1nΣj=i+1nwijxixj
只有当
x
i
x_i
xi和
x
j
x_j
xj都不为零时,这个二阶交叉项才有意义(存在),实际任务中,特征可能非常稀疏,二阶项非常少,导致
x
x
x训练不准确。
于是利用矩阵分解,将二阶项矩阵
w
w
w分解成两个隐向量的内积组合,
w
i
j
w_{ij}
wij分解成两个隐向量的内积
y
(
x
)
=
w
0
+
Σ
i
=
1
n
w
i
x
i
+
Σ
i
=
1
n
Σ
j
=
i
+
1
n
<
v
i
,
v
j
>
x
i
x
j
y(x) = w_0 + \Sigma^n_{i=1}w_ix_i + \Sigma^n_{i=1}\Sigma^n_{j=i+1}<v_i,v_j>x_ix_j
y(x)=w0+Σi=1nwixi+Σi=1nΣj=i+1n<vi,vj>xixj
w
0
∈
R
,
w
∈
R
n
,
V
∈
R
n
×
k
<
v
i
,
v
j
>
:
=
Σ
f
=
1
k
v
i
,
f
⋅
v
j
,
f
w_0\in \mathbb{R}, w\in \mathbb{R}^n, V\in \mathbb{R}^{n\times k}\\ <v_i,v_j>:=\Sigma^k_{f=1}v_{i,f}\cdot v_{j,f}
w0∈R,w∈Rn,V∈Rn×k<vi,vj>:=Σf=1kvi,f⋅vj,f
FFM
Field-aware Factorization Machines(资料来源)
对于FM模型引入field概念,把相同性质的特征归入同一field,使模型建模更加准确,但是计算复杂度变高,事实上在原有的基础上增添了f个field特征,做交叉的话就多了
n
f
k
−
n
k
nfk-nk
nfk−nk个参数
y
(
x
)
=
w
0
+
Σ
i
=
1
n
w
i
x
i
+
Σ
i
=
1
n
Σ
j
=
i
+
1
n
<
v
i
,
f
j
,
v
j
,
f
i
>
x
i
x
j
y(x) = w_0 + \Sigma^n_{i=1}w_ix_i + \Sigma^n_{i=1}\Sigma^n_{j=i+1}<v_{i,f_j},v_{j,f_i}>x_ix_j\,
y(x)=w0+Σi=1nwixi+Σi=1nΣj=i+1n<vi,fj,vj,fi>xixj
DNN
就是神经网络,该模型最早由谷歌提出使用在youtube搜推,分为召回模块和排序模块,在模型中使用了average pooling的操作
在召回模块中,使用观看向量、搜索向量,采用crossentropy优化
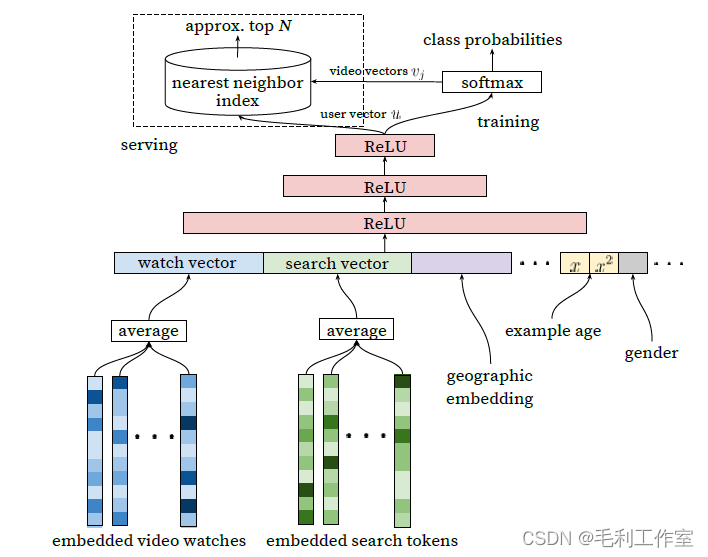
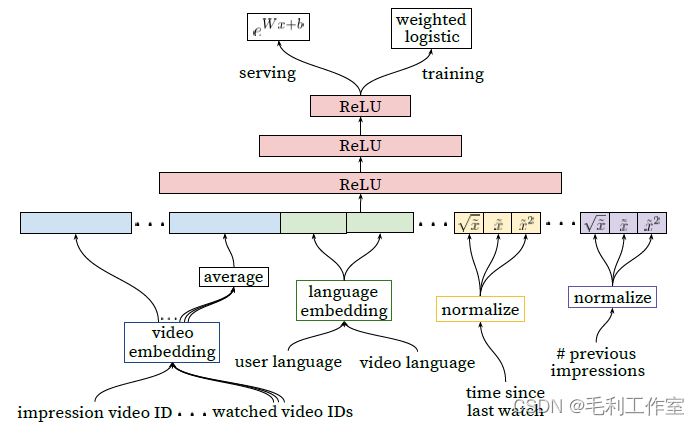
排序模块使用观看向量,使用逻辑回归训练
DCN
Deep Cross Network,通过神经网络做特征交叉,自动学习交叉(图中cross network模块)
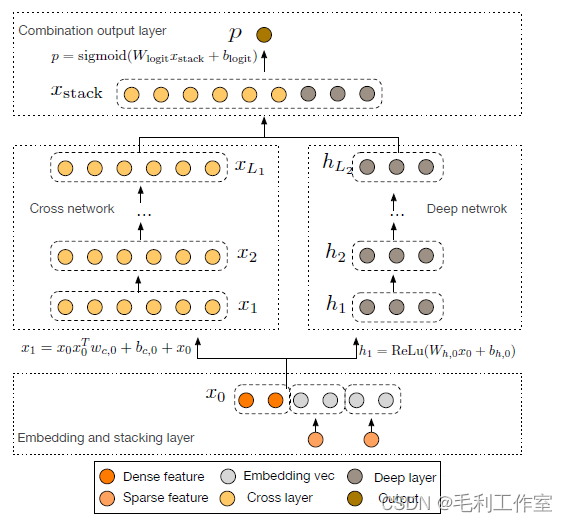
交叉模块:
x
l
+
1
=
x
0
x
l
T
w
l
+
b
l
+
x
l
=
f
(
x
l
,
w
l
,
b
l
)
+
x
l
x_{l+1}=x_0x_l^Tw_l+b_l+x_l=f(x_l,w_l,b_l)+x_l
xl+1=x0xlTwl+bl+xl=f(xl,wl,bl)+xl
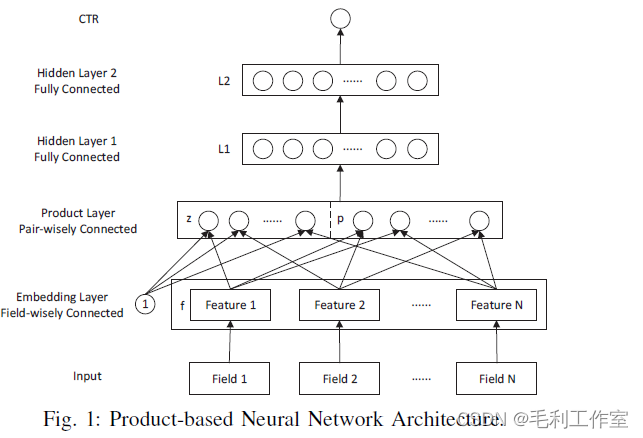
PNN
Product-based neural network,在DNN基础上添加product内积层,做特征交叉
DIN
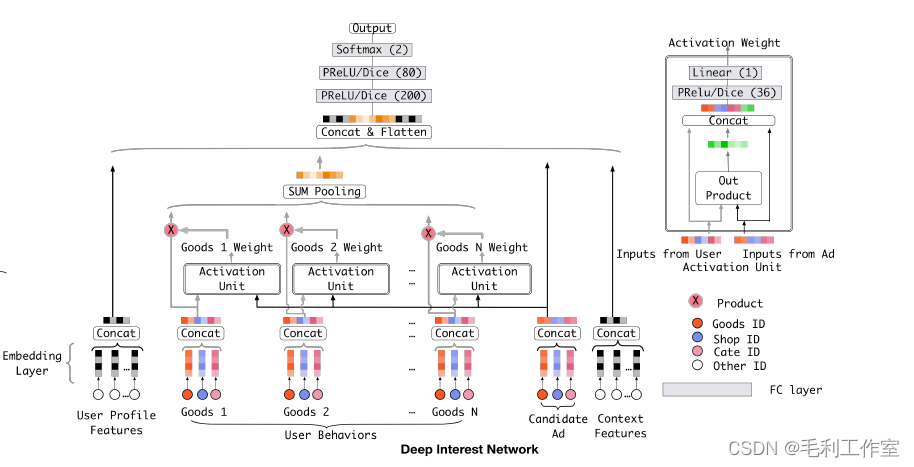
Deep interest network,从DNN基础上引入注意力机制,主要关注到了待排序广告和用户行为特征的关联性,目标函数为交叉熵,输出为是否点击
DMT
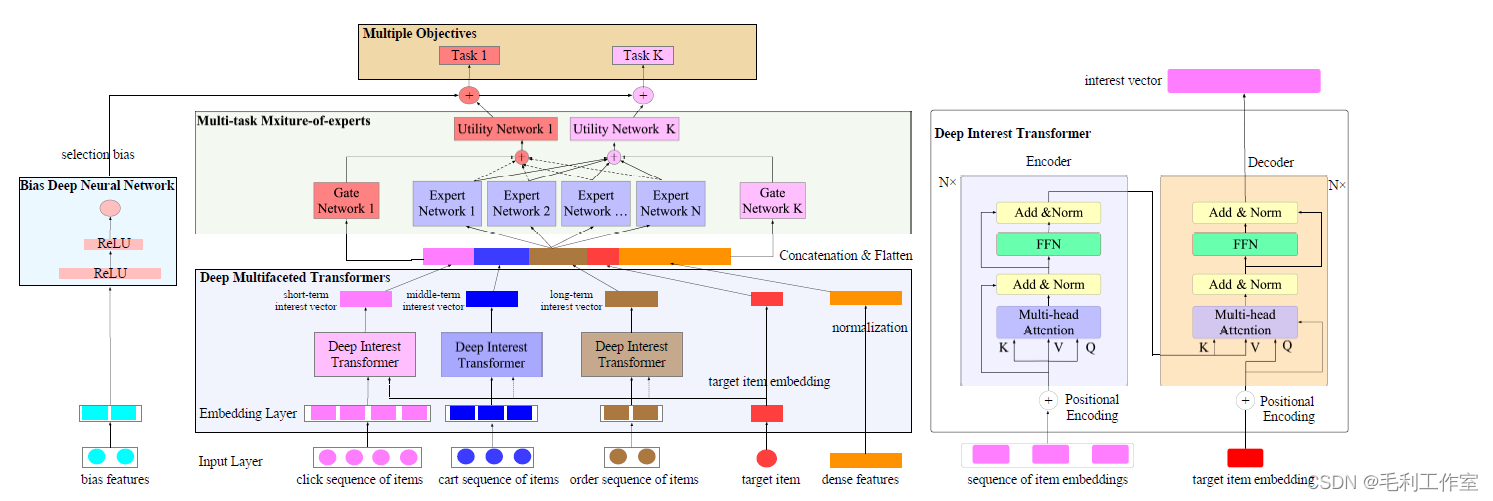
Deep multifaceted transformer,引入transformer模块,其中还添加了多任务学习模块
TDM
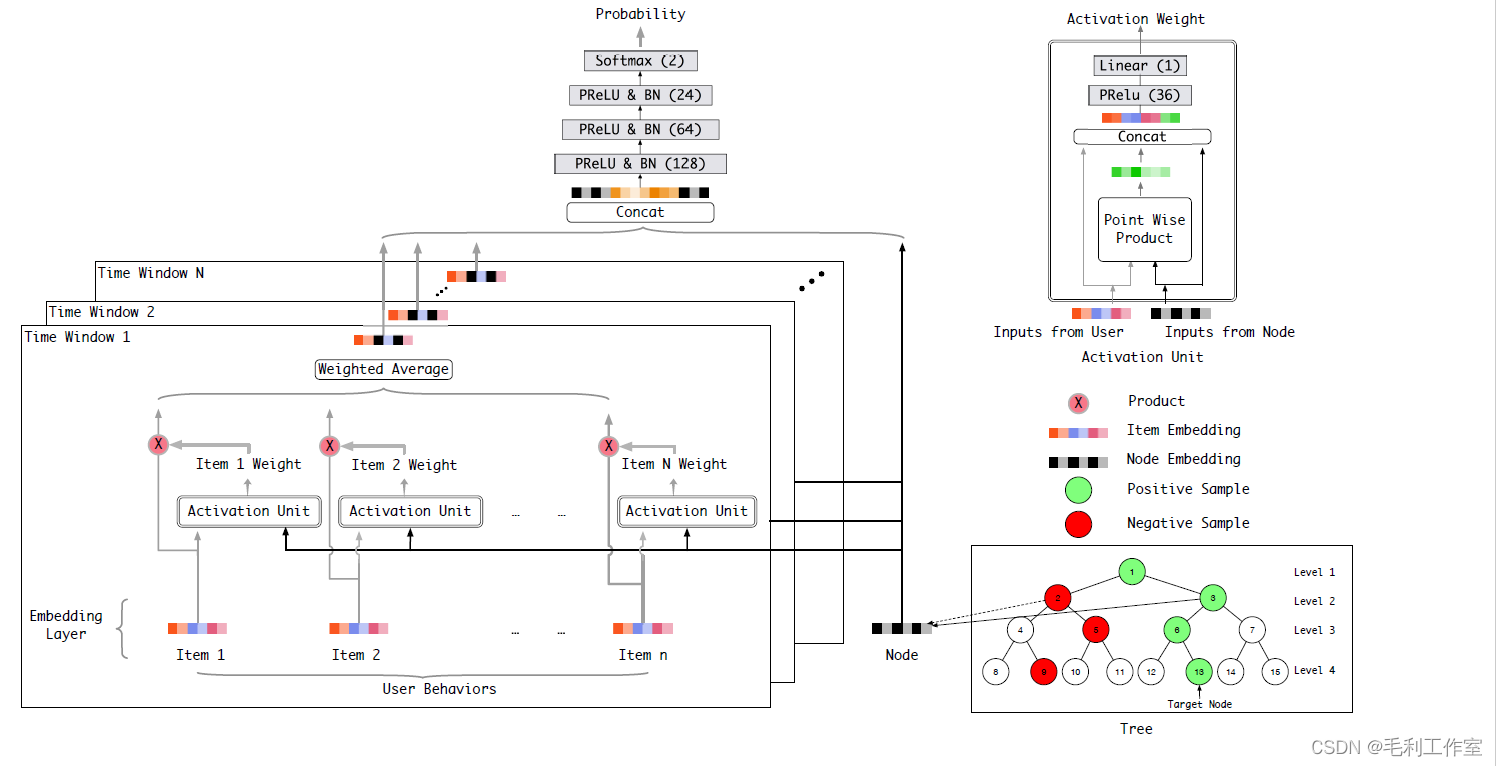
Tree-based deep model,树深度模型
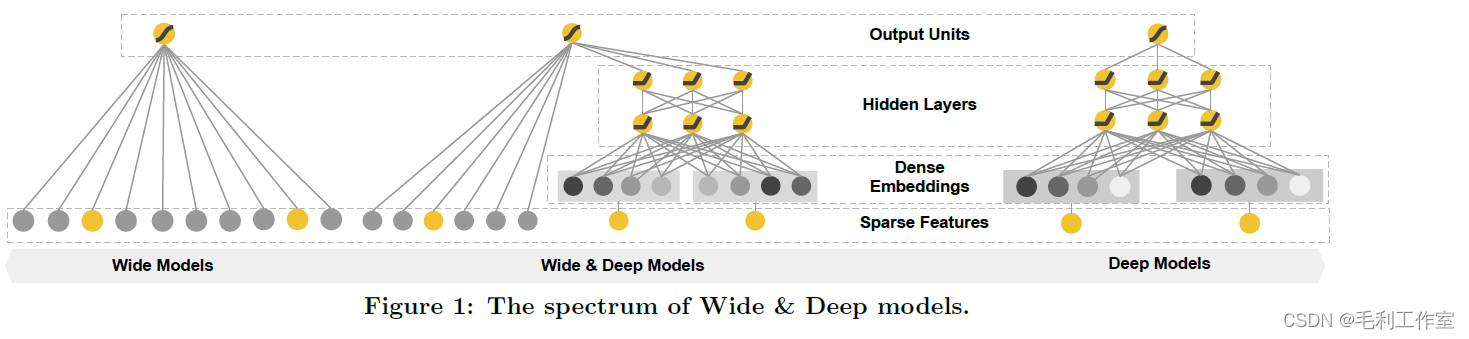
Wide & Deep
Wide部分为LR,输入为onehot离散特征和分桶后的连续特征
Deep部分为MLP,输入为embedding的离散特征和归一化的连续特征
DeepFM
将widedeep的wide部分替换成FM方法,避免了人工特征工程
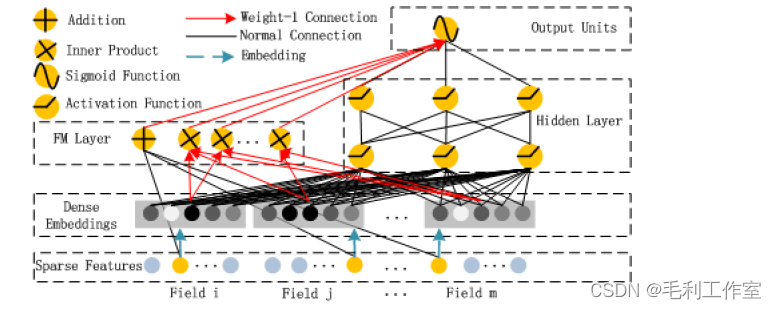
CVR建模
(资料源:知乎)
难点
- 正样本稀疏,模型难以训练
方法:预训练,迁移学习,多任务学习,数据增广 - 训练集与线上数据分布差别大
方法:ctr多任务学习 - 特征与pcvr分布偏移,新活动加入,模型无感知
方法:在线训练 - 正反馈信号延迟严重(delayed feedback),会低估cvr
方法:数据等待窗口
多目标优化
- 多模型加权:分别对每一个目标进行建模(独立),进行打分(可能是ecpm)并加权求和
- 样本赋权:比如曝光并转化为1,曝光并点击为0.1
- 排序学习:只获得顺序pair
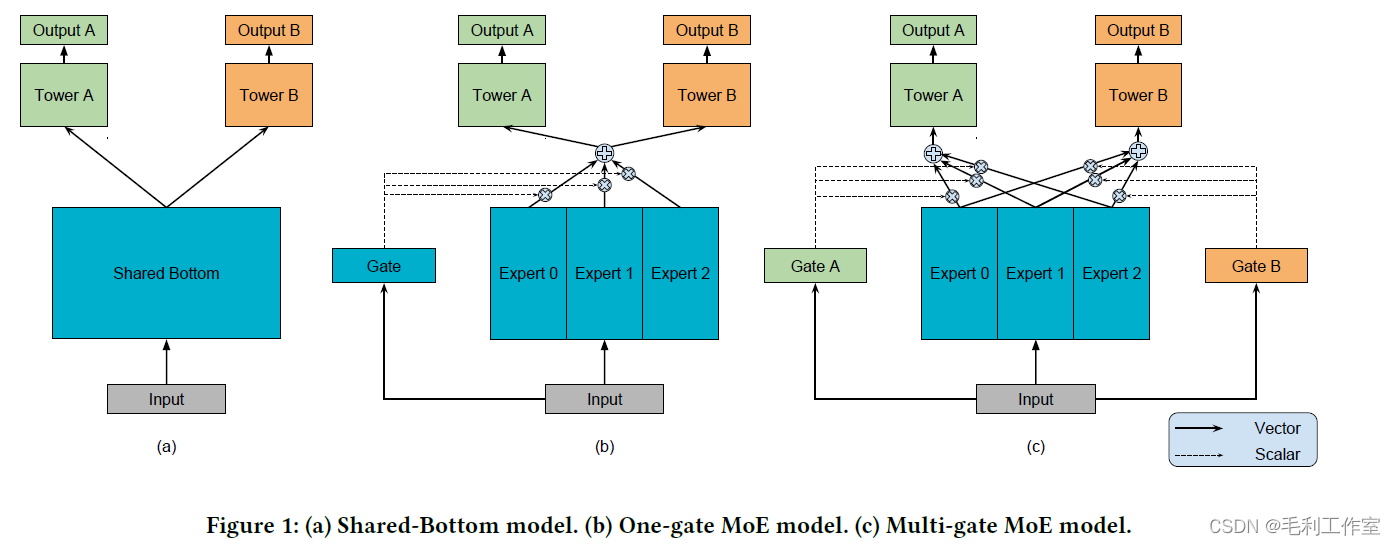
- 多任务学习:迁移学习的分支,共享参数,输出多个结果(通常多个任务之间是有关联性的)
多任务学习工程化
Multi-gate Mixture-of-Experts:多门多专家结构
延迟反馈(Delayed feedback)
负样本------>正样本需要一段时间(点击未转化------>点击转化)
数据分布层面
未转化样本未来可能转化,观测样本与真实分布有偏差
方法:
- importance sampling,对观测样本进行校正
- inverse propensity weighting,对样本分配不同权重缓解样本偏差
- PU(正样本和无标签)分类,计算p(s|x)推出p(s|y)
模型层面(DFM)
定义{X, Y, C, D, E}
X:特征
Y:label,是否已经转化
C:是否会转化(隐变量)
D:转化与点击的时间间隔
E:距点击的时间长度
*Y = 0 ------> C = 0 or (C = 1 and E < D)
Y = 1 ------> C = 1
主要思想:使用多任务学习,将模型拆分为转化模块(预估是否转化)和延迟模块(预估延迟时间),实际运用时只使用转化模块
模型设计:
- 转化模块:逻辑回归(二分类)
P
r
(
C
=
1
∣
X
=
x
)
=
1
1
+
exp
(
−
w
c
⋅
x
)
Pr(C=1|X=x) = \frac{1}{1+\exp(-w_c\cdot x)}
Pr(C=1∣X=x)=1+exp(−wc⋅x)1
2. 延迟模块:可以设延迟时间服从指数分布(可以使用其他方法,如对其建模自动优化分布)
P r ( D = d ∣ X = x , C = 1 ) = λ ( x ) exp ( − λ ( x ) d ) λ ( x ) = exp ( w d ⋅ x ) Pr(D = d|X=x,C=1) = \lambda(x)\exp(-\lambda(x)d)\\ \lambda(x) = \exp(w_d\cdot x) Pr(D=d∣X=x,C=1)=λ(x)exp(−λ(x)d)λ(x)=exp(wd⋅x)
训练:最大似然,EM算法或梯度下降
模型指标
(资料源:知乎1)
AUC计算
-
方法1
M个正样本和N个负样本,在M*N个样本对中,对正样本大于负样本的样本对个数求和,相等计0.5
Σ I ( P p o s i t i v e , P n e g t i v e ) M ∗ N I ( P p o s i t i v e , P n e g t i v e ) = { 1 , P p o s i t i v e > P n e g t i v e 0.5 , P p o s i t i v e = P n e g t i v e 0 , P p o s i t i v e < P n e g t i v e \frac{\Sigma I(P_{positive},P_{negtive})}{M*N}\\ I(P_{positive},P_{negtive})=\left\{\right. M∗NΣI(Ppositive,Pnegtive)I(Ppositive,Pnegtive)=⎩⎪⎨⎪⎧1,Ppositive>Pnegtive0.5,Ppositive=Pnegtive0,Ppositive<Pnegtive1,Ppositive>Pnegtive0.5,Ppositive=Pnegtive0,Ppositive<Pnegtive -
方法2
对score从小到大排序,给每个样本rank(数字1开始),将所有正样本rank求和
A U C = Σ i ∈ p o s i t i v e C l a s s r a n k i − M ( 1 + M ) 2 M ∗ N AUC = \frac{\Sigma_{i\in positiveClass}rank_i-\frac{M(1+M)}{2}}{M*N} AUC=M∗NΣi∈positiveClassranki−2M(1+M)
GAUC计算
广告推荐系统中,需要计算每个用户的auc加权平均,因为用户和用户之间差异较大
权重可以设置为每个用户的点击次数
G
A
U
C
=
Σ
(
u
,
p
)
w
(
u
,
p
)
∗
A
U
C
(
u
,
p
)
Σ
(
u
,
p
)
w
(
u
,
p
)
GAUC=\frac{\Sigma_{(u,p)}w_{(u,p)}*AUC_{(u,p)}}{\Sigma_{(u,p)}w_{(u,p)}}\,
GAUC=Σ(u,p)w(u,p)Σ(u,p)w(u,p)∗AUC(u,p)
参考文献
(只列出模型的论文,网络资料在正文中有超链接)
[1] Rendle S. Factorization machines[C]//2010 IEEE International conference on data mining. IEEE, 2010: 995-1000.
[2] Juan Y, Lefortier D, Chapelle O. Field-aware factorization machines in a real-world online advertising system[C]//Proceedings of the 26th International Conference on World Wide Web Companion. 2017: 680-688.
[3] Covington P, Adams J, Sargin E. Deep neural networks for youtube recommendations[C]//Proceedings of the 10th ACM conference on recommender systems. 2016: 191-198.
[4] Wang R, Fu B, Fu G, et al. Deep & cross network for ad click predictions[M]//Proceedings of the ADKDD’17. 2017: 1-7.
[5] Qu Y, Cai H, Ren K, et al. Product-based neural networks for user response prediction[C]//2016 IEEE 16th International Conference on Data Mining (ICDM). IEEE, 2016: 1149-1154.
[6] Zhou G, Zhu X, Song C, et al. Deep interest network for click-through rate prediction[C]//Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 2018: 1059-1068.
[7] Gu Y, Ding Z, Wang S, et al. Deep multifaceted transformers for multi-objective ranking in large-scale e-commerce recommender systems[C]//Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 2020: 2493-2500.
[8] Zhu H, Li X, Zhang P, et al. Learning tree-based deep model for recommender systems[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018: 1079-1088.
[9] Cheng H T, Koc L, Harmsen J, et al. Wide & deep learning for recommender systems[C]//Proceedings of the 1st workshop on deep learning for recommender systems. 2016: 7-10.
[10] Guo H, Tang R, Ye Y, et al. DeepFM: a factorization-machine based neural network for CTR prediction[J]. arXiv preprint arXiv:1703.04247, 2017.
[11] Ma J, Zhao Z, Yi X, et al. Modeling task relationships in multi-task learning with multi-gate mixture-of-experts[C]//Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 2018: 1930-1939.

