
- 1华为OD机试 - 最小调整顺序次数、特异性双端队列(Java & JS & Python)_最小调整次数
- 2【Elasticsearch 未授权访问漏洞复现】_elasticsearch未授权访问漏洞复现
- 3小米开源便签Notes-源码研究(1)-导出功能整体思路
- 4从零开始配深度学习服务器2023.04.01_从零开始配一个深度学习服务器
- 5欧科云链研究院:如何降低Web3风险,提升虚拟资产创新的安全合规
- 6TCP 和 UDP的区别
- 7基于chatgpt-on-wechat的微信个人对话机器人搭建
- 8python、C# 写企业微信机器人推送【图文消息】_python 企业微信机器人推送图文
- 9Python 分治法求最大最小元
- 10某城商银行生产容器云平台详细设计方案分享及经验总结_银行容器云平台项目计划书
【机器学习PAI实战】—— 玩转人工智能之美食推荐_美食推荐算法
赞
踩
前言
在生活中,我们经常给朋友推荐一些自己喜欢的东西,也时常接受别人的推荐。怎么能保证推荐的电影或者美食就是朋友喜欢的呢?一般来说,你们两个人经常对同一个电影或者美食感兴趣,那么你喜欢的东西就很大程度上朋友也会比较感兴趣。在大数据的背景下,算法会帮我寻找兴趣相似的那些人,并关注他们喜欢的东西,以此来给我们推荐可能喜欢的事物。
场景描述
某外卖店铺收集了一些用户对本店铺美食的评价和推荐分,并计划为一些新老客户推荐他们未曾尝试的美食。
数据分析
- A B C D E F G H I J K
- 0[0, 0, 0, 0, 0, 4, 0, 0, 0, 0, 5],
-
- 1[0, 0, 0, 3, 0, 4, 0, 0, 0, 0, 3],
-
- 2[0, 0, 0, 0, 4, 0, 0, 1, 0, 4, 0],
-
- 3[5, 4, 5, 0, 0, 0, 0, 5, 5, 0, 0],
-
- 4[0, 0, 0, 0, 5, 0, 1, 0, 0, 5, 0],
-
- 5[4, 3, 4, 0, 0, 0, 0, 5, 5, 0, 1],
-
- 6[0, 0, 0, 4, 0, 4, 0, 0, 0, 0, 4],
-
- 7[0, 0, 0, 2, 0, 2, 5, 0, 0, 1, 2],
-
- 8[0, 0, 0, 0, 5, 0, 0, 0, 0, 4, 0],
-
- 9[1, 0, 0, 0, 0, 0, 0, 1, 2, 0, 0]

横轴为美食品种,分为A--K 11中,竖轴为用户序号,有0-9 10个人。表内值为某个用户对某种美食的推荐分,0表示其未曾吃过,5分为最高的推荐分。以上数据为实验虚构数据。
场景抽象化
给定一个用户i,我们根据上面的数据为其推荐N个推荐分最高的美食。
模型选择
协同过滤简单来说是利用某兴趣相投、拥有共同经验之群体的喜好来推荐用户感兴趣的信息,个人通过合作的机制给予信息相当程度的回应(如评分)并记录下来以达到过滤的目的进而帮助别人筛选信息,回应不一定局限于特别感兴趣的,特别不感兴趣信息的纪录也相当重要。
我们也将采用协同过滤来实现商品推荐,并在下面的章节一步步实现基于协同过滤的商品推荐系统。
数据处理
以上数据,不存在缺失和无意义推荐分,即不超出范围,格式正确。
搭建环境
- 首先进入noteBook建模,链接
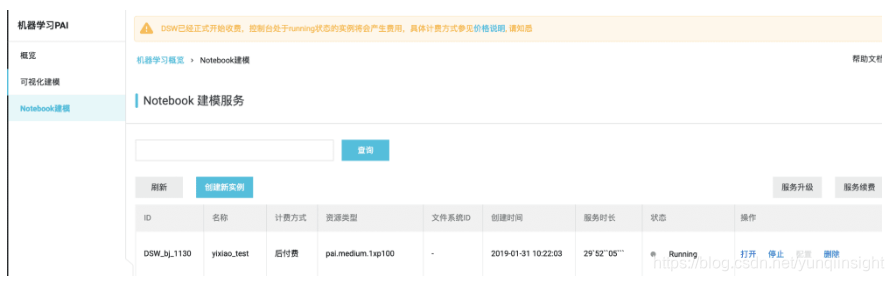
- 然后创建新实例

- 之后打开实例
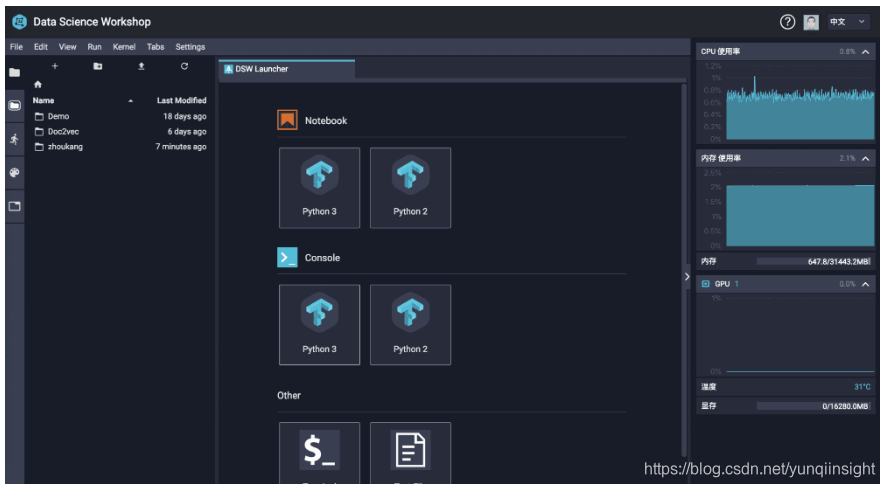
现在基础环境以及搞定了,我们可以用terminal安装自己需要的包环境。同时可以选择python2或者python3的开发环境。而且左侧的文件系统,支持本地文件的上传下载等。
相似度计算
在推荐系统中,我们需要计算两个人或商品的相似度,我们可以采用余弦相似度,皮尔逊相关系数等。
余弦相似性通过测量两个向量的夹角的余弦值来度量它们之间的相似性。0度角的余弦值是1,表示完全一样,而其他任何角度的余弦值都不大于1;并且其最小值是-1,相似度为0。
皮尔逊相关系数( Pearson correlation coefficient),是用于度量两个变量X和Y之间的相关(线性相关),其值介于-1与1之间。
新建文件recom.py,实现相似度计算函数
- def cosSim(inA,inB):
- num = float(inA.T*inB)
- denom = la.norm(inA)*la.norm(inB)
- return 0.5+0.5*(num/denom)
推荐分计算
在文件recom.py,实现推荐分计算
- #dataMat 用户与美食的矩阵
- #user 用户序号
- #simMeas 相似度算法
- #item 美食商品
-
- def standEst(dataMat, user, simMeas, item):
- n = shape(dataMat)[1]#商品数
- simTotal = 0.0; ratSimTotal = 0.0
- for j in range(n):#所有商品,遍历
- userRating = dataMat[user,j]#user对该商品的推荐分
- if userRating == 0: continue#如果user 未推荐该商品则过滤
- #logical_and逻辑与,nonzero非零判断,overLap为均为商品item,j推荐的用户
- overLap = nonzero(logical_and(dataMat[:,item].A>0, \
- dataMat[:,j].A>0))[0]
- if len(overLap) == 0: similarity = 0
- #以此overLap,计算两商品的相似度。
- else: similarity = simMeas(dataMat[overLap,item], \
- dataMat[overLap,j])
- print('the %d and %d similarity is: %f' % (item, j, similarity))
- simTotal += similarity
- ratSimTotal += similarity * userRating
- if simTotal == 0: return 0
- else: return ratSimTotal/simTotal
对于特征向量非常稀疏,或者特征之间关联关系明显,协方差较大则需要对原有维度的特征进行降维。这样既可以节省资源加快运算,也可以避免冗余特征带来的干扰。
- def svdEst(dataMat, user, simMeas, item):
- n = shape(dataMat)[1]
- simTotal = 0.0; ratSimTotal = 0.0
- U,Sigma,VT = la.svd(dataMat) #奇异值分解
- Sig4 = mat(eye(4)*Sigma[:4]) #构建对角矩阵
- xformedItems = dataMat.T * U[:,:4] * Sig4.I #数据维度转换
- for j in range(n):
- userRating = dataMat[user,j]
- if userRating == 0 or j==item: continue
- similarity = simMeas(xformedItems[item,:].T,\
- xformedItems[j,:].T)
- print('the %d and %d similarity is: %f' % (item, j, similarity))
- simTotal += similarity
- ratSimTotal += similarity * userRating
- if simTotal == 0: return 0
- else: return ratSimTotal/simTotal
通过计算待推荐商品与已推荐商品的相似度,并乘以该用户对已推荐商品的推荐分,来计算待推荐商品的推荐分。
在文件recom.py,加入recommend函数
- #dataMat 用户与美食的矩阵
- #user 用户序号
- #N 推荐前N个商品
- #simMeas 相似度计算算法
- #estMethod 推荐分计算算法
-
- def recommend(dataMat, user, N=3, simMeas=cosSim, estMethod=standEst):
- #找出user未评分的商品
- unratedItems = nonzero(dataMat[user,:].A==0)[1]#find unrated items
- if len(unratedItems) == 0: return 'you rated everything'
- itemScores = []
- #依次计算这些商品的推荐分
- for item in unratedItems:
- estimatedScore = estMethod(dataMat, user, simMeas, item)
- itemScores.append((item, estimatedScore))
- #返回前N个较好分的结果
- return sorted(itemScores, key=lambda jj: jj[1], reverse=True)[:N]
算法演示
如果是本地编辑的文件,可以通过文件上传方式上传到服务器。
- 新建noteBook演示
- 加载算法模板

- 数据展示

- 为序号为2的用户推荐商品
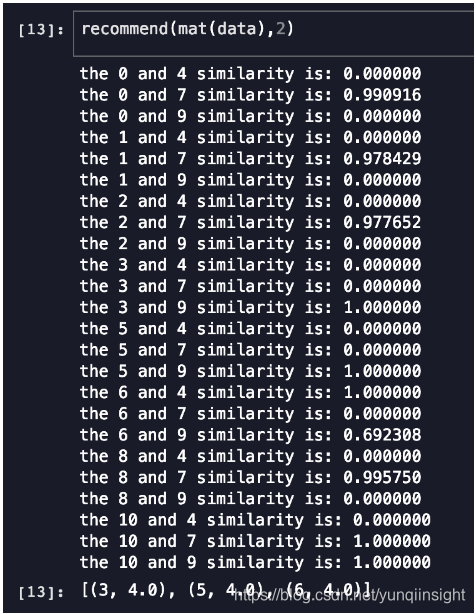
总结
通常在计算相似度之前,我们需要确定是计算基于商品的相似度(上面的方式),还是计算基于用户的相似度。在现实情况下,我们要根据用户和商品的数据决定选择哪种计算方式。同时,在数据量变大时,我们通常需要先降维,在做商品推荐。部分代码参考《机器学习实战》,本篇文章主要介绍如何使用PAI-DSW实现算法实验。
原文链接
本文为云栖社区原创内容,未经允许不得转载。

